基于规则引擎及智能阈值的实时业务风控系统*
2019-12-04张鲁男常宝岗
张鲁男,常宝岗,梅 利
(中国移动通信集团山东有限公司,山东 济南 250001)
0 引 言
随着互联网金融的快速发展,线上支付及其应用逐渐普及,给人们的生活带来了便利。同时,从中牟利的网络黑产的规模也逐渐扩大,带来了交易高风险、信息泄露、欺诈事件增加等现象。企业构建起风控系统,设置风险阈值,进行风险识别、风险评级、风险规避,以保证正常用户的业务平稳开展。但随着业务场景的日益增加和复杂化,基于业务安全领域的防护和黑产的对决愈演愈烈。借助于黑色产业链的日趋完善和发达,黑产不断通过伪基站等方式频繁访问,探测其中的业务漏洞,加以利用、变现。此类漏洞攻击通常是伪装成正常用户进行批量操作,恶意侵占企业资源,但相比于注入漏洞更难被检测到。
1 基于规则引擎的实时业务风控系统
该系统的整体框架示意图如图1所示。整体框架由四个部分组成:存储系统、计算集群、规则引擎和管理平台。
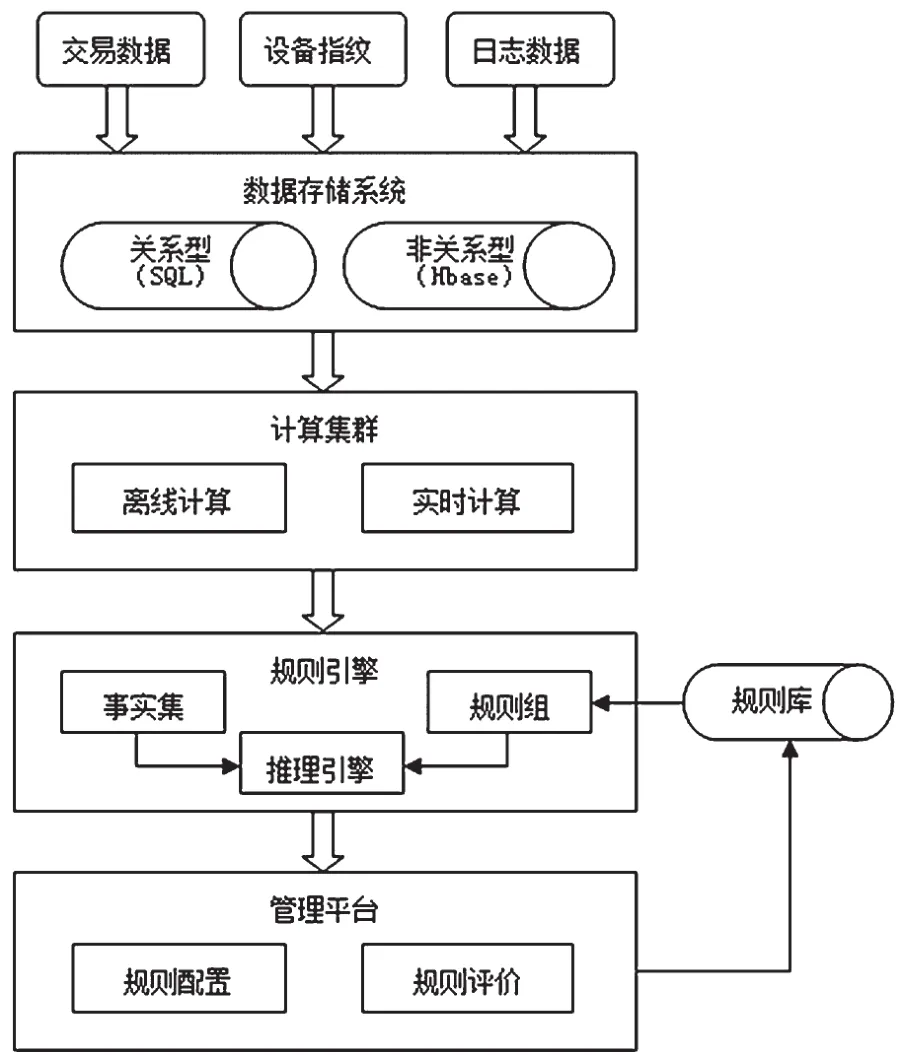
图1 基于规则引擎的实时业务风控系统
上述整体架构的工作流程阐述如下。
(1)数据存储系统为数据层,包含关系型数据库和非关系型数据库。格式化数据存储于关系型数据库,例如:用于离线分析的会员属性数据、历史订单数据等;非关系型数据库用于存储需要频繁更新的数据;实时风控请求数据、设备指纹数据。在构建一个风控系统之前,需要根据企业的业务场景确定数据来源,通常需要解决跨业务系统的数据接入问题。在关键业务节点,需要设置业务埋点、SDK数据采集等配合,实现对风控事件的实时追踪,并将实时数据接入到数据存储模块中。
(2)计算集群包括实时计算集群和离线计算集群。实时计算集群用于实时风控所需的预计算,为后续的规则判断而准备。通常需要借助统计方法,得到所需维度的统计值。离线计算集群用于周期性执行的任务,通常周期时间至少为一天。主要用于满足非实时的大数据分析和模型训练的需求,将原始的风控数据在计算层进行计算处理,形成各个维度的特征数据,例如:频次统计、最大统计、最近统计等[1]。
(3)规则引擎包括事实集、规则库和推理引擎。规则库由规则构成,模拟判断准则。单条规则可以表示为:
IF:条件部分LHS (left-hand side), THEN: 结论RHS (right-hand side).
其中,LHS包括一个或多个组合条件,单个条件原子之间通过AND(与)和OR(或)的逻辑关系进行组合。RHS为满足LHS中的条件后需要执行的动作,又称风控措施。当一个事实满足规则后对其执行风控措施,记为触发一次风控规则。
(4)管理平台为风控系统的应用层,通常封装为前端web界面,以方便业务人员进行规则配置。此外,返回规则评价体系输出的结果,风控人员可基于评价结果改进目前的风控规则。评价体系包括:规则的触发情况、用户对风控措施(RHS)的反馈结果等,有助于现有风控规则的改进。
2 规则引擎设计
规则引擎由推理引擎、事实集、规则库组成。数据层的相关数据作为事实集,加载到工作内存中。
2.1 特征库设计
规则库中所需要的变量通过预处理,可存储为特征因子,提高变量复用率和规则的简洁度。特征库设计示意图如图2所示。
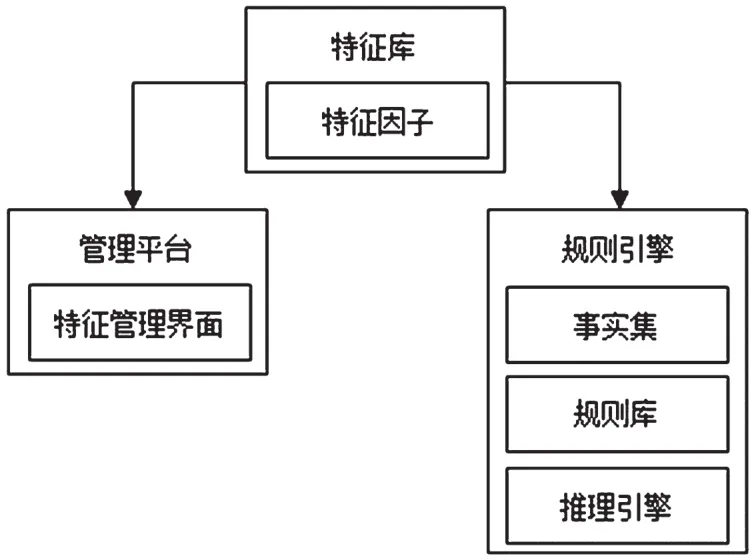
图2 特征库设计
根据全域风控需求,特征库中的特征因子分为用户特征因子和全局特征因子。用户特征因子以账户为主键,聚合用户维度的特征数据。得到的数据是反应用户维度的交易、登录、设备等特征。全局特征因子是从全局数据中抽象所需要的其他维度进行组合、计算[2]。
此外,由于商业规则和业务场景不断变化,规则经常需要根据实际变化做出频繁调整。业务人员在前端的特征管理界面,对特征库中的特征因子进行增删改查的操作,不直接对规则库进行频繁变更,避免了特征因子的重复开发。因此,特征因子的存储具有稳定性、聚合性和可复用性。
2.2 规则匹配优化
在规则的模式匹配中,使用Rate算法提升匹配效率,减少了重复计算造成的时间冗余性。在规则数量和事实样本较多时,每条事实数据都需要与Rete网络中的Aplha节点相匹配[3]。大多数规则所含的条件原子相同,即存在被多个规则同时包含的条件原子,依次与每个Alpha节点匹配就存在了一定时间浪费。因此,一个预匹配模块,将多条规则聚合成少量的规则组。通过规则组筛选,在预匹配阶段过滤掉部分正常数据,减少事实和节点的匹配次数。实现逻辑是将含有多个相同条件原子的规则划分到同一规则组中,规则组中出现次数最多的条件原子作为该规则组的特征条件。全量数据通过预匹配模块中规则组的筛选,即可过滤掉部分数据,对剩余样本执行所在规则组内的规则判断。对于多条规则的规则组划分,需要首先构建一个键值对,存储所有条件原子和该条件在所有规则中出现的次数。也可以从业务角度设计规则组,按照不同的业务线划分规则所属的规则组。但系统的响应速度容易受到业务场景的影响。
2.3 规则评价机制
有效的风控规则体系包括识别风险用户,以及实时的风险拦截措施,防患于未然。同时,风险措施将直接作用于产品终端,影响到用户体验。因此,基于业务的风控系统需要将风险的误报率和漏报率降低到可接受的范围内,提升产品终端的用户体验。本系统基于规则触发次数和风控反馈结果,构建了规则评价体系,以验证规则有效性,并有助于业务人员对风控规则进行监控和优化调整。规则评价机制的作用逻辑如图3所示。
规则评价机制根据两种数据来源进行,一是根据风控分值得到的触发次数分布;二是触发规则后对风控措施进行响应,所得到的最终请求结果[4]。

图3 规则评价机制
(1)规则命中准确率评价
规则引擎输出每条规则的触发次数,基于此计算查准率(p)和召回率(r),如下:
p=TP/(TP+FP)
p=TP/(TP+FN)
其中,TP为触发规则但未通过验证的请求次数,以及来自黑名单中用户的请求;FP为触发规则中通过验证的请求次数;FN为未触发规则中来自黑名单用户的请求次数。查准率反应了该规则识别风险用户的准确率,召回率反应了规则能否识别出尽可能多的风险用户。当上述风险评价机制的性能指标超过了正常范围,系统或自动发送报警邮件,通知策略负责人员核实策略的准确性。
(2)风控措施合理性评价
系统根据每次请求的返回分值,匹配滑动窗口验证、短信验证、禁止访问等实时风控措施。对于验证类措施,请求的验证结果有助于区分该请求是否来源于黑产群体的模拟用户。
3 阈值体系设计
如今网络黑色产业链日渐猖獗,在攻防对抗中,攻击者能够轻易饶过以固定值作为风控阈值制定的风控措施。例如,黑产依托于规模化、批量化的Modem Pool设备,利用虚假号码实现程序化的短信验证码验证和登陆,通过不断尝试,便可以探测出企业对同账号、同ip号规定的单日登录次数的上限。因此,如果将风控阈值仅设定为固定值,即使增加阈值对应变量的维度,也容易被黑产探测出。
本阈值体系主要解决了传统风控系统中阈值一刀切造成的弊端,以评分机制为基础,总共有三个模块。在专家阈值的基础上,增加了用户行为评分机制和时间序列评分机制,从用户、设备、时间三个维度增加阈值的动态调整部分。
3.1 专家阈值
由于每日风控请求量都是海量的,首先利用专家阈值进行初步过滤,基于多维度指标的静态阈值对明显存在风险的账号和行为执行相应的风控措施。专家阈值是基于专家征询法(DelphiMethod)对单个指标的阈值进行一一确定,具有客观性和代表性。
3.2 基于用户行为的动态阈值
用户行为模型是基于用户行为,动态调整阈值的一种综合性方法。该模块的技术路径流程图如图4所示。具体分为以下三个步骤:(1)基于用户行为,以用户为主键,利用设备指纹、历史风控请求等特征,采用聚类分析、随机森林等深度模型进行用户分类和特征挖掘;(2)构建用户的风险评级系统,其实现逻辑是对模型结果进行计算,对各个群体分配不同的风险等级;(3)线上沿用训练好的模型参数对样本进行计算,实现高可用的个性化智能风控。线上采用这样的浅度模型方式进行判断和匹配,减少了运算压力且提高了效率。
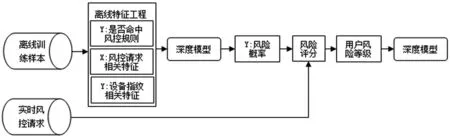
图4 用户风险评级模型的实施流程
特征工程来源于风控系统的离线特征库。深度模型用于离线环境下的模型训练,包含用于特征探索的非监督模型和用于风险概率预测的监督模型,输出结果为预测的风险概率。本系统根据6条业务线进行风控策略设计,因此需要考虑到不同业务之间风险识别的通用性,和使用时的可快速移植性。例如不同业务线,由于业务类型的不同,风险请求频次会有数量级上的差异。因此,分用户群体进行风险评级满足了以上跨业务系统进行统筹性的风险管理的需求。特征体系划分为以下几个大类:
(1)用户身份角度定义的风险:是否为会员,最近两周是否更改过生日
(2)在离线特征工程阶段,利用定性和定量相结合的方法,计算特征向量。分类模型所需要的样本标签,是基于定性的风控规则对样本进行标签标注,形成训练样本的分类标签。在分类模型的训练过程中,为了防止单次抽样抽取测试样本和训练样本,使得模型结果存在误差,采用K折交叉验证(K-CrossValidation),重复进行K次训练,最终取性能指标的均值最佳的模型参数。
3.3 基于时间序列的动态阈值
时间序列(或称动态数列)是指将同一统计指标的数值按其发生的时间先后顺序排列而成的数列。时间序列分析的主要目的是根据已有的历史数据对未来进行预测。
传统的时间序列预测方法有:简单平均法、移动平均法、指数平滑法等。在风控系统的阈值计算中,我们常使用移动平均法(moving average),即:通过对时间序列逐期递移求得平均数加/减标准差作为预测值。
移动平均将最近k期数据加以平均,加/减标准差作为下一期的预测值。设移动平均间隔为k(1<k<t),则t期 的 移 动 平 均 值 为:结果,通过这些平滑值可描述出时间序列的变化形 态 或 趋 势。t期 的 标 准 差 为:期的均值与标准差求和,可得到一个预测区间。
t+1期的移动平均预测上限值为:Ft+1=Y-t+δt2
t+1期的移动平均预测下限值为:Ft+1=Y-t-δt2
即我们可以将最近k分钟/小时/天的数据加以平均,加/减标准差作为当前这一分钟/小时/天的上限/下限阈值。
4 结 语
本文主要阐述了如何构建基于规则引擎的风控系统,详细介绍了风控系统的架构、规则引擎的设计以及规则的评价机制,同时提出了基于专家经验、人工智能算法、时间序列算法的动态阈值功能,使得风控系统的规则更加精确,在应对各类电商业务风险时,能更准确地找到并拦截潜在的威胁。
