基于自动微分的异构网络资源分配算法*
2019-12-04张臻昊
张臻昊,李 辉
(中国科学技术大学 中国科学院无线光电通信重点实验室,安徽 合肥 230026)
0 引 言
随着通信技术的发展,5G时代即将来临。用户的吞吐量迎来爆炸性的增长,接入设备的数量也日益增多,传统的蜂窝网络构架已经无法满足用户的需求。针对这些问题,研究人员提出了异构蜂窝网络[1](Heterogeneous Networks,HetNets)的概念,通过在宏基站覆盖不到、薄弱的区域以及热点区域布置较小功率的基站(如皮小区基站,家庭小区基站以及分布式天线系统等)来提供通信服务,从而为用户提供更高的通信速率。
网络构架的更新带来的是新的网络模型和分析方法,传统的方法已经不再适用于异构蜂窝网络的复杂场景[2]。资源分配以及用户归属问题是异构蜂窝网络中的基本问题。资源分配问题主要关注每个小区的物理资源块该如何分配给各个用户。用户归属问题解决用户应该接入哪个小区基站。将一个用户归属到某个基站,会影响接入该基站的其他用户对资源块的使用,因此用户归属问题应和资源分配方案一起解决[3]。为了提高系统性能,资源分配和用户归属问题的优化应在整个网络层面进行,然而这种优化被证明是NP难题,难以求其精确解[4]。
传统的方法一般采用信噪比或者信号接收强度[5]作为用户接入准则。文献[6]提出用信干噪比作为归属准则。用户选择接入具有最大信干噪比的基站,可以获得比以信号强度为准则的方案更好的系统吞吐量。文献[7]提出了在多小区网络中联合优化部分频率复用和负载均衡的用户归属和资源分配方案。文献[8]用非线性规划方法处理多速率无线局域网中的用户归属问题,目标函数为最大化网络中用户带宽收益之和。文献[9]采用博弈论的方法进行资源分配,但方法较为繁琐。以上这些方案大多基于固定的频率复用方案,并未考虑用户的分布情况,但随着网络异构性的增强,为了得到更高的性能增益,动态的频率复用应该作为资源分配考虑的重要方面。
本文提出了一种基于自动微分的用户归属和资源分配联合算法。自动微分[10](Automatic Differentiation,AD)也称为算法微分,是一种类似于反向传播但比反向传播更通用的技术,近年来被广泛应用于深度学习领域。
本文构建了动态频谱复用下的资源分配和用户接入模型,将该问题转换为动态计算图下的目标函数最小化问题,基于自动微分计算获得可行解。仿真实验表明,所提算法相对于传统的方案能显著提升系统吞吐量、频率复用率以及系统性能。
1 系统模型
异构蜂窝网络的模型如图1所示。该网络由一个宏基站与多个发射功率不同和覆盖面积不同的微基站组成。该系统共有N个基站,K个用户,NB个资源块,小区集合为用户集合为K= { 1,…,K},资源块集合为R= { 1,2,… ,NB}。
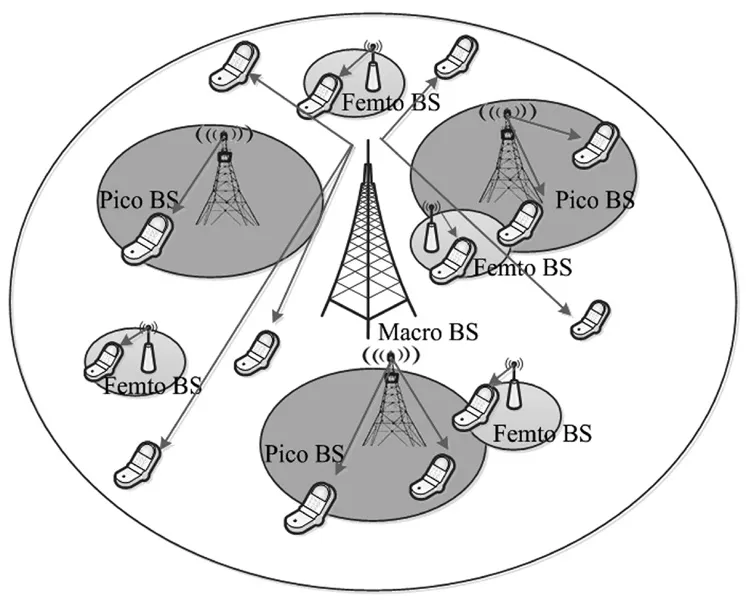
图1 异构蜂窝网络模型
本文研究的是下行链路的资源分配,并做出了如下假设:
(1)区域内系统总资源是固定的,即频谱资源固定,资源集中管理,统一分配,各小区基站资源由系统实时分配,每个基站使用的资源块数目可以不同。
(2)最小的资源单元是物理资源块,单位资源块的带宽为B0。
(3)每个用户只能接入一个基站,即只能接收从一个基站发送来的信号。
(4)系统中K个用户的位置信息和信道增益信息都是已知的。用户的位置可能是均匀分布的,也可能是非均匀分布的。
(5)若给定用户接收到各个基站信号的信干噪比,则可以计算用户从各基站可能获得的速率。
1.1 变量定义
1.1.1 用户归属矩阵
定义用户归属矩阵,其中每个元素表示用户集合中用户k是否归属于基站n,接收从基站n发送来的数据。元素定义如下:

1.1.2 资源块分配矩阵
资源分配矩阵定义为其元素代表资源集合中的资源块i是否被分配给用户k。

1.1.3 联合分配数组
从以上两个指示变量可以得到最终的联合分配数组,其中:

X是一个大小为N×K×NB的三维数组,其代表着资源块、用户、基站三者之间的相互对应关系。
1.2 问题描述
由以上定义的变量可以推出用户k连接到基站n在资源块i上的信干噪比为:
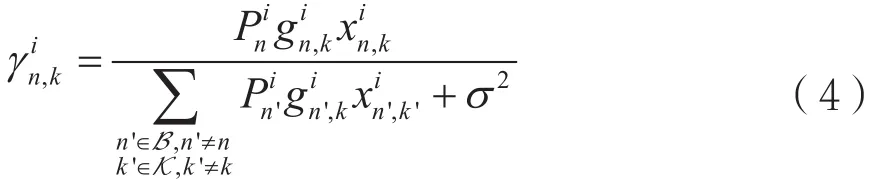
其中代表资源块i在基站n上的功率,表示从基站n到用户k在资源块i上的路径损耗,σ2表示单位资源块上的噪声功率。于是,用户k从基站n处获得的速率可表示为:
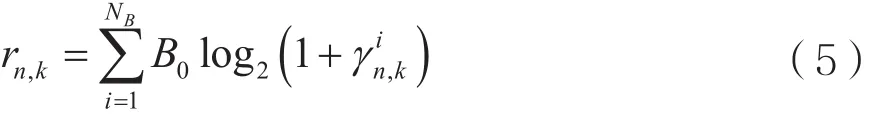
则用户k从所有基站上获得的实际速率为:

为了能在系统吞吐量和用户公平性间取得折中,选择用户速率对数和作为优化目标,以保证用户比例的公平性。同时,从以上的分析可以得到一系列约束条件,因此可以将异构蜂窝网络用户归属和资源分配的优化问题表述如下:
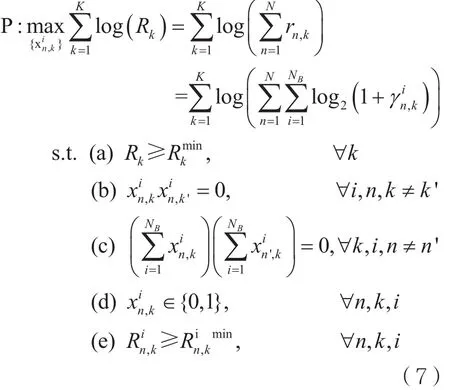
式(7)中(a)为用户最小的速率约束,每个用户进行不同的通信业务需要不同的速率需求;(b)表示每个资源块在同一个基站只能供一个用户使用;(c)为每个用户只能连接一个基站,在该站分配资源块的约束条件,本文暂不考虑同一用户同时接入不同的基站的情况;(e)为单个资源块上速率约束,是为了消除个别信噪比过小的分配方案。以上是整个问题的数学表示。
该优化问题的目标是求得联合分配数组X的解,这样可以同时得到频率复用方案以及用户归属和资源分配方案。然而,该问题被证明是一个NP难问题,难以一步求解。现有的方法大多将其分解为多个子问题,利用变量松弛法进行拉格朗日对偶求解,解法复杂且尚未考虑动态频率复用方案。
2 基于自动微分的资源分配算法
式(7)中的联合资源分配和用户归属是一个混合整数的不等式优化问题,是一个NP难问题,难以用一般的方式进行一步求解。因此,这里引入AD,使用深度学习的相关框架,将其表述为一个计算图下的优化问题,将系统目标函数与约束条件转换成该计算图的目标函数,基于反向传播机制,采用梯度下降算法,对用户接入与资源分配数组X进行迭代优化求解,最终获得该问题的可行解。由于变量之间的关系表达式过于复杂,无法直接求出梯度的数学表达式,此时引入AD能够有效进行梯度的相关计算。
2.1 自动微分
微分求解有4种主要的求解方式:手动求解法、数值微分法、符号微分法以及自动微分法[10-11]。
手动求解法是直接对函数进行导数计算。对于简单的函数,此方法有效可行。但是,对于复杂的函数,手动求解法是个庞杂且易出错的过程。数值微分法是使用有限差分进行近似,简单实用,但可能会存在较大的舍入和截取误差,随变量数的增加计算量激增。符号微分是使用符号计算得到精确的闭合表达式的求导结果,但随着函数的复杂度增加,所产生的符号表达式会呈指数增长,造成表达式爆炸。对于本文复杂的目标函数和规模庞大的变量而言,以上3种方法均存在相应的问题,而自动微分方法则克服以上缺陷,在计算大规模数据导数等方面更高效。
自动微分的原理是通过分析数据的相关性,基于链式求导法,通过中间变量传递输出变量对输入变量的依赖关系,结合计算机程序生成微分程序的方法。它主要分为前向模式和反向模式两种。前向模式是从输入一步步求导到输出,有几个自变量需要求导几次;反向模式则是从输出反向求导到输入。本文使用反向模式。反向模式的AD对应于一个广义的反向传播算法,因为其从给定的输出反向传播导数。
例如,对于函数[10]:

图2为该函数计算图,反向模式即从输出反向求导到输入。假设其初始值(x1,x2)=(3,4),根据表1左边的前向路径推导出y之后,可根据右边的反向路径一次性求出y关于输入变量x1、x2的导数。反向模式的一个重要优点是,对于具有大量输入变量的函数,计算成本明显低于正向模式,可以通过一次反向求导完成整个过程。

图2 示例计算图路径

表1 反向模式的过程示例
2.2 算法设计
本文在Pytorch框架下实现基于自动微分的算法[12-13],将目标函数以及约束条件转化为计算图的损失函数,基于自动微分进行梯度下降算法求解,设计过程如下。
2.2.1 步骤1
首先将分配变量松弛为,使其成为0-1之间的连续变量,方便进行后续梯度的计算。
本文采用Xavier方法初始化三维数组,各元素满足标准正态分布。将该数组的用户维度(定义经过softmax函数得到每个资源块的分配概率值为1,代表资源块在基站n上仅被当前用户k使用。值越小,被使用概率越小,保证变量的取值范围。
2.2.2 步骤2
原优化问题含有不等式约束,考虑引入罚函数,用拉格朗日乘子法将约束条件叠加到目标函数上,从而将有约束的最优化问题转化为无约束条件的问题。合理的罚函数可以在算法搜索到不可行点时,使目标函数值变得很大。离约束条件越远,惩罚越大。因此,得到的增广目标函数如下:

由此将问题(7)转化为求式(9)的最小值,其中各个loss为式(7)中不同的约束条件转化成的数学表达式,具体如下:
(1)loss1为式(7)中有关用户速率的约束(a),将用户从所有基站以及资源块上获得的速率进行求和,与用户的最低速率约束进行比较。

(2)loss2为式(7)中关于单个资源块分配的约束(b),对于每一个xn i,其元素中最多只能有一个值为1,满足单个资源块在一个基站上只能分配给一个用户约束。
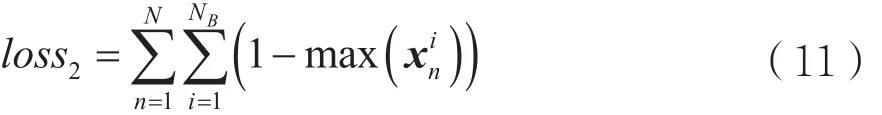
(3)loss3为式(7)中有关用户只能接入一个基站约束(c),定义矩阵同时可以定义一维向量。对X针对资源得到每个用户从每个基站接收到的资源块数目Y。对于矩阵Y,其基站维度只能有一个非零项,softmax函数能够有效将该维度所有元素的和固定为1。令其最大值与1逼近,则保证了该维度只能有一个非零项,满足约束条件。
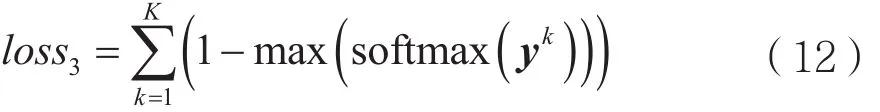
(4)loss4是式(7)中对于单位资源块上的最低速率约束(e),以防止单个资源块上的信噪比过低。
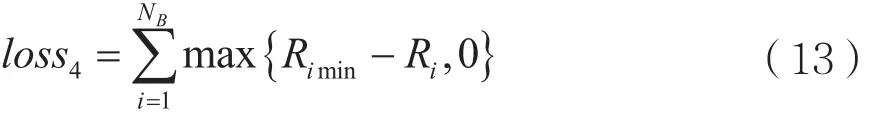
最终,得到增广目标函数也就是计算图的损失函数的表达形式为:

2.2.3 步骤3
对式(14)直接进行梯度下降算法很难求出其梯度的解析形式:

因此,为了将其转化为深度学习框架下的微分优化问题,本文利用自动微分进行程序编写,将步骤2中各loss函数编写为相应程序。
2.2.4 步骤4
求解loss函数关于联合分配数组X的梯度反向传播到输入,采用Adam梯度下降算法更新输入,反复迭代直至收敛,得到问题的可行解。最后,将松弛后的自变量按照四舍五入原则还原成{0,1}的整数变量。
3 仿真分析
假设仿真实验中,异构蜂窝网络中有3种不同小区,分别为宏小区、微小区和家庭小区。用户位置在小区覆盖区域满足均匀分布,基站的分布位置预先固定,信道满足瑞利分布。部分仿真参数如表2所示。
小区的分布如图3所示,本节的对比算法有最大信干噪比法(Max SINR)以及基于偏置的信干噪比法。Max SINR法选择具有最大信干噪比的基站接入作为用户归属准则。基于偏置的方法则定义SINR´nk=Cn·SINRnk,其中 SINRnk代表用户k从基站n处的信干噪比,用户归属准则为接入到具有最大偏置信干噪比SINR´nk的基站,Cn为小区的偏置因子。本节中为3层小区选择的偏置为[0,6,12]dB。对比算法按照固定频率复用方案进行资源分配。

表2 基本仿真参数
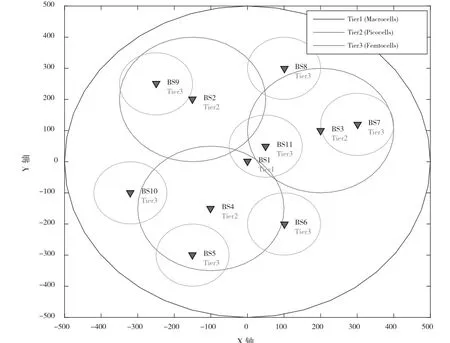
图3 异构网络小区分布图
3.1 算法收敛性
本文的进行了20 000次的迭代实验,研究了算法的收敛性。

图4 算法的收敛性
从图4可以看出,在满足约束的基础上,经过10 000次迭代后,目标函数的值基本不变。随着迭代次数的增加,系统趋于稳定,由此验证了算法的收敛性和有效性。
3.2 频率复用方案
通过迭代求解出联合分配矩阵X之后,可以从X中得到整个系统的频率复用情况,即每个资源块被复用的次数。表3中的结果显示了资源块(Physical Resource Blocks,PRBs)数目为600、用户数为200时每个基站使用的资源块的数目。从表4统计结果可以看出,所有基站使用的资源块数目的总和是实际PRBs数目的近4倍。算法显著提高了频率复用率,扩大了系统容量,提升了用户性能。

表3 200用户时各基站频率复用情况

表4 200用户时频率复用率
3.3 用户平均速率
为了公平,采用用户的平均速率进行比较,分别针对改变用户数和改变资源块数目两种情况进行仿真。从图5可以发现,当总资源块数一定(NB=1 000)的情况下,用户的平均速率随着总用户数的增加随之下降,本文提出方案的速率始终高于其他两种方案。当用户数为300时,SINR bias算法已经无法满足用户速率最低要求进行分配,而Max SINR算法在用户数为250时已经无法进行资源分配。本文的算法仍然可以进行分配,主要是利用了资源块之间的频率复用关系。从两图的右坐标轴可看出,频率复用率随着用户数目增加而自适应增大。

图5 用户平均速率与总用户数的关系
当用户数一定(K=200)的情况下,从图6可以看出,用户平均速率随着资源块数目的提升随之上升,本文提出的算法用户平均速率始终在其余两种算法之上。当资源块数目较少时,Max SINR算法与SINR bias算法分别在数目600与500时无法满足用户需求进行分配,但本文算法仍然可以进行分配,证明了本文算法的优异性。随着资源块数目的减少,频率复用率逐渐增大。

图6 用户平均速率与总资源块数的关系
3.4 用户非均匀分布
本文还对用户非均匀分布情况进行了仿真,如图7所示,用户主要集中在不同微基站周围的热点区域。
仿真结果如图8、图9所示,分别是针对固定资源块数目为1 000改变用户数目以及固定用户数目为200改变资源块数目的情况下的仿真。仿真表明,在用户非均匀分布的情况下,本文算法仍然能够达到比对比算法更高的用户速率,同时能够得到频率复用方案和自适应的频率复用率,证明了本文算法的有效性。
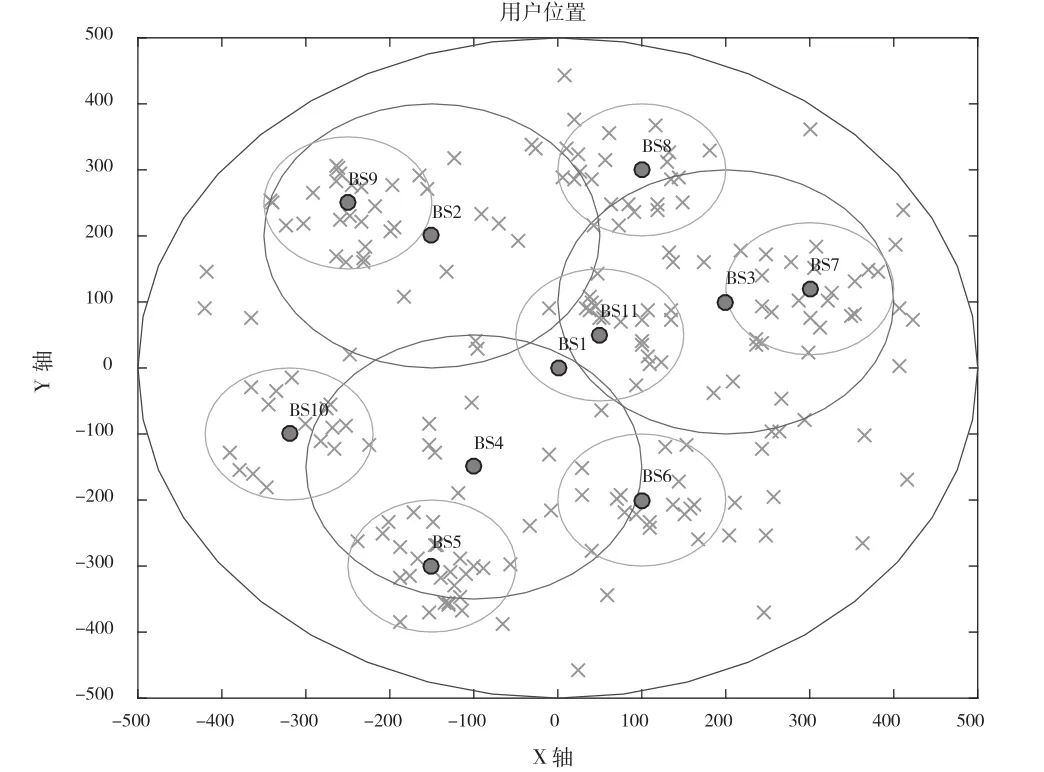
图7 非均匀分布用户
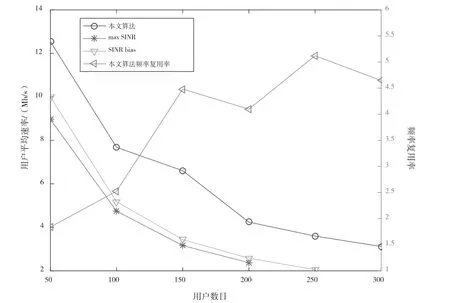
图8 用户平均速率与总用户数的关系

图9 用户平均速率与总资源块数的关系
4 结 语
本文提出了一种异构蜂窝网络的资源分配算法。为了提高系统容量,将资源分配与用户归属问题一同考虑,但该问题被证明为NP-hard问题难以求得精确解。本文基于自动微分方法,对联合分配数组利用梯度下降算法迭代计算出可行解,同时可从联合分配数组中得到动态频率复用方案。最后,利用仿真验证了算法的收敛性和有效性。与最大信噪比和信噪比偏置方案相比,该方法具有更高的系统吞吐量。
