基于最小哈希的重复数据清洗方法*
2019-12-04张荃,陈晖
张 荃,陈 晖
(中国人民解放军陆军工程大学,江苏 南京 210007)
0 引 言
当今的互联网时代,“大数据”自提出以来就受到了人们的关注,它指的是一种规模大到在获取、存储、管理、分析方面大大超出了传统数据库软件工具能力范围的数据集合。大数据的价值在于对数据进行专业化处理,深度挖掘其中隐藏的信息,从而帮助对现有的数据进行处理,或者是对未来的工作做出合理预测等等[1]。
在大数据的应用中,数据挖掘是一个有效的方法,它一般分为数据采集、数据预处理、数据挖掘和数据呈现四个部分[2]。每个部分的工作量相关统计如图1所示,可以清晰的看出,数据预处理是数据挖掘中的一个重要环节。从大数据的“低价值密度”这个特点的角度出发,也可以看出,大数据中存在很多无价值的数据,在挖掘大数据价值前,必须对数据进行预处理。

图1 数据挖掘各项工作量占比
重复数据是数据库中影响数据质量的常见问题之一,它的存在破坏了数据的唯一性,占用数据库的空间,降低了运行效率。清除重复数据,是提高数据挖掘有效性,充分发挥数据库作用的重要环节之一。因此,本文主要针对重复数据进行处理,按照先对数据进行编码转换,再计算Jaccard相似度,从而找出重复的数据的思路。现有的方法主要采用了datacleaner[3]的基础模块找出重复数据,由于需要对每个属性单独进行编码,相对繁琐。我们创新性的将数据转换为一段文字,利用最小哈希(minhash)编码方式[4]对该段文字进行统一的编码,再计算Jaccard相似度,从而找出重复的数据。当数据量逐步增大时,minhash算法明显缩短了运算时间,提升了重复数据处理的效率。
1 相关工作
1.1 重复数据定义
重复数据可以简单的理解为具有相同信息的数据,本文主要针对人员数据集进行处理,同一个人的相同属性的数据为重复数据。在现实生活中,一个人的各项信息可能被多次统计,例如在校园生活中,一个学生的信息被辅导员、授课教师、后勤管理者等分别统计过,当整个学校的人员信息汇集在一起后,该学生的信息将多次出现。本文中处理的重复数据主要包含以下几类[5]:
(1)因填写时笔误、录入电脑时识别不清等原因,造成数据的内容存在一定程度的不同,但实际代表的是同一个人的信息。
(2)录入数据时规定的不一样,存在有时候写的是全称,有时候写的是缩写,实际为同一信息的情况。
(3)数据来源于多个数据源,合并时产生的重复数据。
如表1所示,序号1和序号2的两行数据,属于重复数据情况一,因为书写的问题,造成education-num实际为13,被录入为18;序号1和序号3,属于重复数据情况二,国家那栏存在全称和缩写的问题;序号1和序号4,属于重复数据情况三,两者完全相同。

表1 重复数据实例
1.2 重复数据清洗基本思路
处理重复数据的基本思路是:首先对数据进行编码转换,计算两行数据间的相似度,当相似度大于阈值时,认定为重复数据[6]。计算相似度的方法有很多,欧式距离、汉明距离、Jaccard距离等,本文选取Jaccard系数,作为数据间相似程度的度量。
Jaccard系数的定义为,给定两个集合A和B,Jaccard系数定义为集合A和集合B的交集与两者并集的比值,即为:

Jaccard系数可以衡量集合的相似程度,越接近的集合,Jaccard系数值越高。
2 重复数据清洗算法
2.1 基于datacleaner和Jaccard系数的重复数据清洗
这种处理重复数据的思路就是:首先,利用datacleaner对数据进行编码,接着计算出每两行数据之间的Jaccard系数,根据Jaccard系数性质,数值越大,说明两行的数据越接近,当高于阈值时认为该两行数据为重复行,删除其中一行。Datacleaner是具有基础编码功能的模块,可以实现用数值去编码非数值变量,主要工作流程是:
1)数据中是数值变量的列,保留原有的数值,例如本文选用的人员数据中的age、education-num等;
2)数据中非数值变量的列,如workclass、education等,首先计算该列共有几种不同变量记为n,然后将0到(n-1)的整数随机的分配给这n种变量,完成非数值变量的编码。
该方法的优点是通过逐行比较所有数据,能够较好的找出重复数据,算法的查全率和正确率都比较高。但也具有明显的缺点,由于算法需要对每两行数据进行对比,并将两行数据中的每个元素进行对比,因此时间复杂度会很高,算法的效率较低。当数据量达到一定数量的时候,算法的耗时将难以估计。
2.2 基于minhash算法的重复数据清洗
为了解决时间复杂度问题,本文将minhash算法引入处理表格类数据的问题中。minhash算法一般是用于比较两个集合或者两个文档间的相似度,在应用于表格类数据时,本文创新的将数据转换为文档,再利用算法计算相似度。
2.2.1 minhash算法简介
minhash算法是LSH(Locality Sensitive Hashing,局部敏感哈希)中的一种,主要用来判断两个集合之间的相似性,因为这种方式计算的时间复杂度较低,所以适用于数据量大的集合。
主要功能有两个:一是估算两个集合的相似度,minhash可以控制计算值与实际值的误差范围,保证计算值得准确率;二是缩短计算的时间,传统的方法需要逐行逐项比对集合中的值,当数据量很大时,会造成运算时间成几何倍上涨,该算法中通过先提取出相似对,再进行逐项比对的方法,减少了很多工作量,从而缩短了时间。
2.2.2 minhash算法应用
minhash算法的实现流程一般为,将文档划分成子字符串(shingles),再利用哈希(hash)函数构建签名,最后对比签名从而获得相似度[7]。
1)划分shingles
Shingles的定义是文档中的子字符串,k-shingles指的是文档中找到的长度为k的任何子字符串。目的是将文档的长字符串,划分为短字符串,这样在比较字符串是否相等时,保留了文档结构的一部分,而不是仅仅看单个单词,这样当出现单词顺序排列不同但语意相同的情况时,更容易识别出来。本文中设定k=3,即从文档中提取任意连续三个单词的字符串。
2)设定hash函数
取x为整数,则hash函数为:

系数a和系数b是随机选取的小于x最大值的整数。c是一个质数,略大于x最大值。通过选择不同的a、b、c的值,可以得到不同的hash函数。
值得一提的是,调动学生的情绪并非是灵丹妙药。在调动学生情绪时也要注意:忌滥用成灾,要适可而止;忌牵强附会,要恰到好处;忌矫揉造作,要新颖自然。
3)求取minhash签名
生成五个不同hash函数,取第一个hash函数,并将其应用于文档中的所有shingle值,得到的所有值中最小值作为minhash签名的第一个值。现在使用第二个hash函数,再次找到计算得到的最小哈希值,作为签名的第二个值,以此类推,可以得到minhash签名的完整向量,里面有五个值。对数据集中的每个文档使用相同的五个哈希函数,并生成它们的签名,然后可以通过计算相同的签名数量来判断文档间的相似度。
2.3 数据转换
对于表格类数据,对数据进行编码时需要对每个元素分别进行编码,通过逐行比较每列的对应元素,计算两行数据的相似度。这种方法存在很多冗余的计算,时间复杂度很高,为了解决这个问题,本文将使用minhash算法优化编码方式,降低时间复杂度。
由于minhash算法是对集合进行处理,因此需要先对数据进行数据转换,即将表格类数据转换为文档集合。图2展示的是未进行数据转换的数据,图3为通过数据转换后得到的文档集合。

图2 转换前数据展示

图3 转换后数据展示
3 实验验证
3.1 数据来源
本文中使用的数据,来源于UCI公共数据集(UCI Public dataset),这个数据集是一个常用的标准测试数据集,主要用于提供机器学习和数据挖掘的训练数据集。本次选用的数据集,是从1994年人口普查数据中提取的真实数据,主要包括:age(年龄)、workclass(工作种类)、education(教育情况)、education-num(受教育年限)、occupation(职业情况)、marital-status(婚姻状况)、race(种族)、sex(性别)、hours-per-week(每周工作时间)、native-country(国籍等信息)。
人员数据是日常工作生活中常见的数据类别,一个人的信息可能被多个部门多次采集,容易产生重复数据,实现人员数据的清洗,更贴近工作生活的需求,对于现实问题具有借鉴意义。
3.2 基于datacleaner模块的重复数据算法实现
3.2.1 数据编码
通过datacleaner模块,对数据进行编码,编码效果如图4、图5所示。
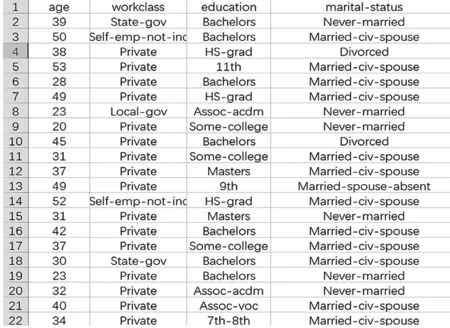
图4 编码前数据展示
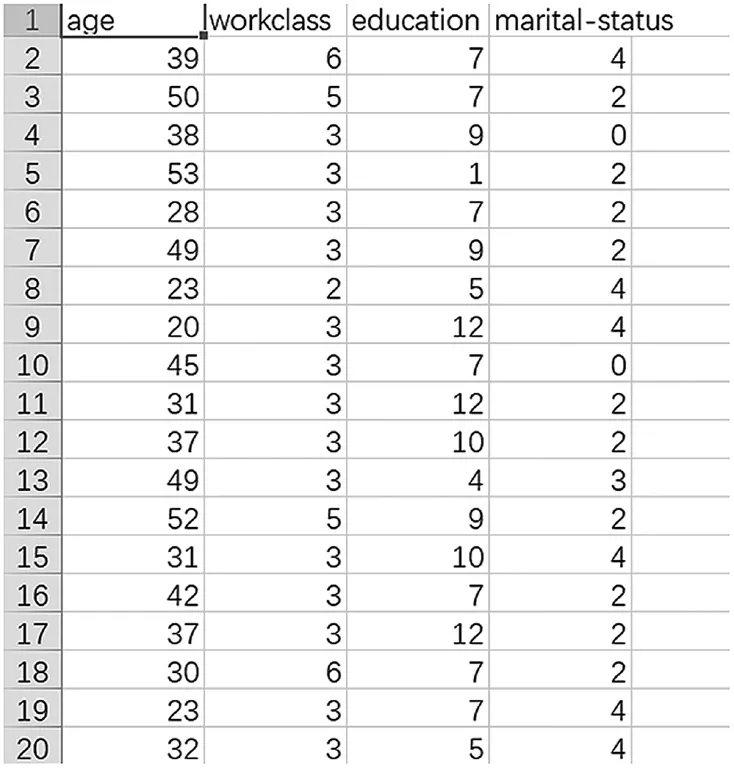
图5 编码后数据展示
3.2.2 数据清洗
重复数据清洗的具体代码实现描述如下:
算法1 基于datacleaner模块的重复数据清洗
输入:
编码后的数据集adult_code_data.csv
输出:
清洗后的数据集adult_clean_data.csv
1:利用列表生成式将adult_code_data写入新列表data_rows中
2:for i 从 1 到 len(data_rows)-1:
3: for j 从 i+1 到 len(data_rows):
4: 在列表list1中存入data_rows[i]
5: 在列表list2中存入data_rows[j]
6: for n 从1到data_rows总列数:
7: if list1[n] == list2[n]
8: 计数值 count+1
9: similarity = count/(列数*2 -count)
10: 将 count清零
11: if similarity>threshold:
12: 在列表repeatnum中存入重复行的序号j
13:清除repeatnum中的重复数字
14:令x = 0
15:for y in repeatnum:
16: 删除data_rows列表中的第(y-x)项
17: x +=1
18:以写入方式打开新文件adult_clean_data.csv
19: for row in data_rows:
20: 写入文件adult_clean_data.csv
3.3 基于minhash的重复数据算法实现
3.3.1 数据转换
我们获得的数据是csv格式的,首先对数据进行转换,主要目的是将数据转换为文档的样式,转换结果已在上文提到,此处不进行赘述。
3.3.2 数据清洗
算法实现描述如下:
算法2 基于minhash算法的重复数据清洗
输入:
创新成文档格式的adult_articles.train
输出:
重复行的行号
1:定义hash函数个数为numHashes,文档行数为numDocs
2:for i 从 1 到 numDocs:
3: 将第i行的每个词存入列表words中
4: docID = words[0]
5: 在列表docNames中存入docID
6: for index 从 0 到 len(words)-2:
7: 三个词为一组形成一个shingle
8:def pickRandomCoeffs(k):
9: while k>0:
10: randIndex =0到maxshingleID中随机选择一个数
11: 在列表randlist中存入randIndex
12: k = k-1
13: return randList
14:coeffA = pickRandom(numHashes)
15:coeffB = pickRandom(numHashes)
16:for docID in docNames:
17: shingleIDSet = 第docID行的shingle
18: for i 从 0 到 numHashes:
19: for shingleID in shingleIDSet:
20: hashCode=(coeffA[i]*
shingleID+coeffB[i])%nextPrime
21: 在列表signature中写入hashCode
22: 在列表signatures中写入signature,得到文档第docID行完整签名
23:for i 从 0 到 numDocs:
24: sig1 = signatures[i]
25: for j 从 i+1 到 numDocs:
26: sig2 = signatures[j]
27: for k 从 0 到 numHashes:
28: count = count +(sig1[k]== sig2[k])
29: estJsim = count/numHashes
30: if estJsim>threshold:
31: 输出 docNames[i]和
docNames[j]
3.4 算法比较
将我们选取的数据集,截取其中一部分人员信息,构成数据量为500、800、1 000、3 000、5 000、10 000的六个数据集,其中重复数据分别为100、200、300、1 000、2 000、3 000,分别用基于datacleaner的算法和基于minhash的算法处理数据集,选取两个评价指标来对比这两种算法。
3.4.1 时间复杂度
这两种算法都按照先将数据转换编码,再计算相似度的方法,从数据编码开始,到完成相似度计算的时间[8],六个数据集通过两种算法运行后的具体时间如图6所示。

图6 算法时间对比图
我们可以看出,当数据量逐步增大的时候,minhash算法的时间明显小于datacleaner算法,说明minhash算法在处理大数据量数据时,具有时间优势。
3.4.2 查全率
将算法消除的重复数据数量与实际的重复数据数量的比例[9,10],定义为该算法的查全率,因为已知数据的重复数量,所以可以较容易的得出这个比例值。公式如下:

Nt表示算法消除的重复数据个数,N表示实际的重复数据个数。
两个算法的比较如图7所示。
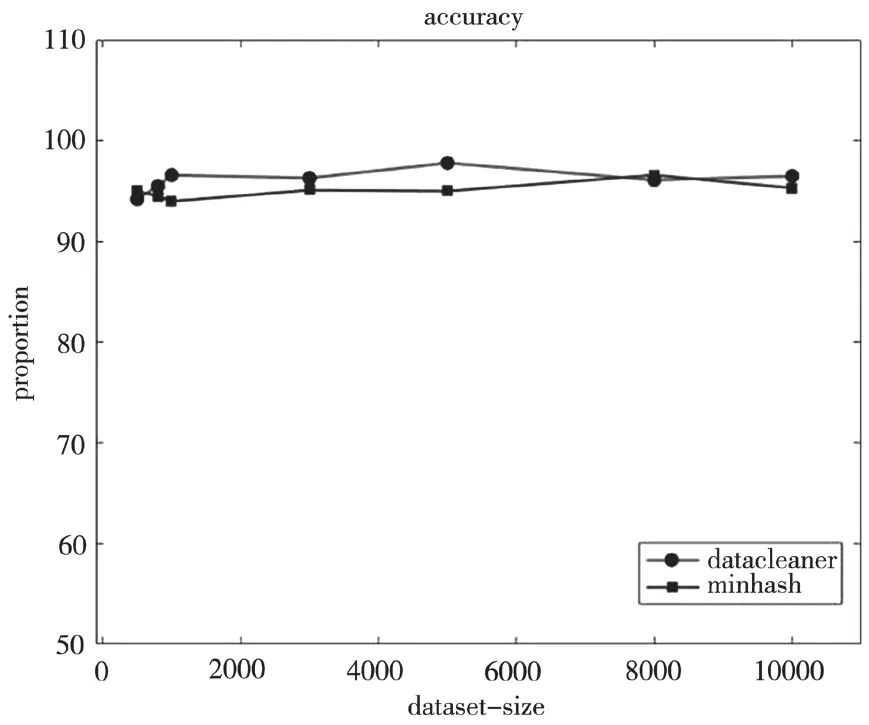
图7 算法查全率对比图
从图7中可以看出,datacleaner算法和minhash算法的查全率基本相同,都能将大部分的重复数据找出。
4 结 语
本文主要是实现了重复数据清洗的工作,主要思路是对数据进行编码后,计算相似度,从而找出重复数据。比较了基于datacleaner算法和基于minhash算法的两种清洗方式,创新的将人员数据转换为文档格式进行编码,基于minhash算法的方式在时间复杂度上进行了优化,得到了明显的效果。如何更好的提高清洗算法的查全率是下步研究的重点。
