基于机器学习的风景园林智能化分析应用研究
2019-12-03包瑞清
包瑞清
机器学习是实现人工智能的一个途径,是处理大数据的关键技术。机器学习算法可以自动分析一类或几类数据来获取规律、发现事物的作用机制,并利用规律对未知数据进行预测。目前将机器学习(包含深度学习)应用到风景园林及城市规划和建筑领域,解决人居环境等相关问题已经成为可能。1)基于Python语言的机器学习开源库scikit-learn集成了机器学习领域的主流核心算法,包含分类、回归和聚类算法以及数据预处理方法等;基于Python语言的深度学习开源库TensorFlow则通过计算图(data flow graphs)、自动求导和定制化的方式用于数值计算。因为机器学习开源库的出现与快速成长、大量核心算法的逐步改善,机器学习作为工具已经广泛应用于各类领域,风景园林学科亦在探索阶段。2)应用机器学习需要大量的基础数据,目前风景园林学科相关分析的数据源包括:1)已有地理信息系统中涉及的各类地理信息数据,例如遥感影像(Remote Sensing Image,简称RS)数据、数字高程数据(Digital Elevation Model,简称DEM)、气象数据及其衍生数据等;2)来自网络的大数据,例如各类网络服务行业百度地图兴趣点(Point of Interest,简称POI)业态分布、滴滴出行数据、微博和微信相关信息数据、智能家居数据等;3)自行采集的批量数据,例如通过各类传感器测得的小气候环境监测数据、场地调研影像数据或者无人机航拍数据和相关问卷调查等;4)涉及建筑信息模型(Building Information Modeling,简称BIM)数据和大量规划设计方案及参数化模型数据。
具备了高度整合的机器学习算法开源库和可获取的大量基础数据,应用机器学习方法能够解决规划设计中很多问题,在2017和2018两年间,风景园林领域已经出现一些相关研究,包括游客微博数据主题情感分析[1],基于街景图像与机器学习和深度学习的城市景观研究[2-3],百度街景语义分割计算绿化要素所占比例[4],基于机器学习的南京市旅游地个性及其文化景观表征[5],基于大数据、信息理论和机器学习的中国城市空气质量调查[6]等。
此次机器学习应用于风景园林学科的实验提取于2017年8月—2018年8月间完成的多个实验,尽量涉及机器学习中包含的分类、回归和聚类算法,尝试探索机器学习应用的途径。在数据分析上包括基于调研图像的城市色彩分析(应用到聚类KMeans算法)和视觉景观质量评价方法(应用到KMeans聚类、分类器的极端随机森林算法Extremely Randomized Tree)2个实验。在数字化设计创作上筛选出应用机器学习地形遴选方案的2个实验[应用到Extra Trees、K-nn、Linear Regression和Ridge回归模型,深度学习下的生成对抗网络(Generative Adversarial Networks,简称 GAN)]。
1 基于调研图像色彩聚类分析的城市色彩印象
1.1 实验目的
城市色彩,也称“城市环境色彩”,泛指城市各个构成要素公共空间部分所呈现出的色彩面貌总和。城市色彩包含大量复杂多变的元素,因此必须科学地调查与分析,才能实现有效引导和规划其发展[7]。在城市色彩相关的研究上,主要有:分析城市色彩特征[8],调查与定量分析[9],更新与保护机制研究[10];景观环境色彩构成[11]以及利用MATLAB计算插值与应用回归算法,实现城市色彩主色调意向图的自动填充,得到城市色彩主色调理想色彩地图的研究[12]。部分传统的研究由于受到数据分析技术的限制,对于批量的城市影像提取主题色时偏重手工提取,不仅增加时间成本,也影响分析的精度,同时在数据分析方法和数据信息表达上亦受到限制。因此有必要借助机器学习中的聚类等方法,自主聚类主题色,并通过Python的Matplotlib标准库实现数据增强表达。

1 城市色彩印象主题色提取Theme color extraction of urban color impression
1.2 方法与数据
此次实验的数据主要为通过手机实际调研拍摄的带有经纬度和高程信息的图像。分为两组,一组来自杭州虎跑,数量为38张JPG格式的图像,拍摄时间为2017年7月21日;另一组来自北京碧云寺,数量为126张JPG格式的图像,拍摄时间为2017年4月12日。
具体的技术路线(图1)。首先在Python程序语言中批量读取图像,因为所拍摄的图像约为4 200 pixels×2 400 pixels大小,而色彩分析不需要这样的高精度,因此通过压缩图像降低图像大小来节约分析的时间。然后设置色彩主题色聚类的数量为7,即获取每幅图像的7个主题色。采用KMeans聚类算法分类色彩提取主题色(图2~3),提取所有图像的主题色之后汇总于一个数组中。在数据增强可视化方面设计了2种形式。1)散点形式打印主题色,直观反映城市色彩印象。通过城市主题色的提取、色彩印象感官的呈现来研究城市色彩,可以针对不同的城市空间、不同的调研时间,分析色彩的变化。2)试图将两地的调研图像主题色投射到三维空间中,观察两组数据在Red、Green和Blue 3个方向上的变化情况。
1.3 结果与讨论
杭州虎跑和北京碧云寺调研图像聚类结果,以散点形式打印主题色后的色彩印象(图4~5)。虎跑主题色偏灰偏暗(建筑的色调),掺杂植被的绿色和天空的蓝色,朴实素雅。碧云寺因为建筑本身多为红色,穿插植被和天空后,整体感觉斑斓绚烂。通过此种数据的可视化方法,能够较为直观反映研究区域的城市色彩特征。如果调研区域的数量激增,根据建立的模型可以实现自动化批量处理,例如研究城市不同区域的色彩特征及其分布关系等。包含色彩信息(RGB)的数据投射到三维空间中(图6),可以通过判断2个区域色彩在三维空间域中的分布情况来把握Red、Green和Blue色彩分量的变化情况。北京碧云寺的色彩倾向较高的是Red值,而杭州虎跑色彩的3个分量趋于较低值。在分析中也可以把色彩转换为HSV(Hue,Saturation,Value)投射到三维空间域中,分析色相、饱和度和明度的关系。
在机器学习聚类中,sklearn整合了众多聚类算法,通过程序的实际运行比较不同聚类算法对不同数据类型的效应。除了应用调研照片来分析研究城市色彩环境,亦可以使用录制的影片,将其按照指定的帧提取图像之后进行同样的分析。在具体的数据分析中,也可以把每一图像的主题色落在其经纬度的坐标点上,在空间中再次应用聚类算法聚类具有相近色彩值的区域,从而能够分类城市色彩特征区域,并与反映城市功能的POI数据,反映城市社交关系的微博、微信等数据相结合分析,找到城市色彩空间分布特征的内在机制。

2 杭州虎跑调研图像、聚类结果和主题色提取Investigation image, clustering results and theme color extraction of Hupao Park, Hangzhou

3 北京碧云寺调研图像、聚类结果和主题色提取Investigation image, clustering results and theme color extraction of Biyun Temple, Beijing
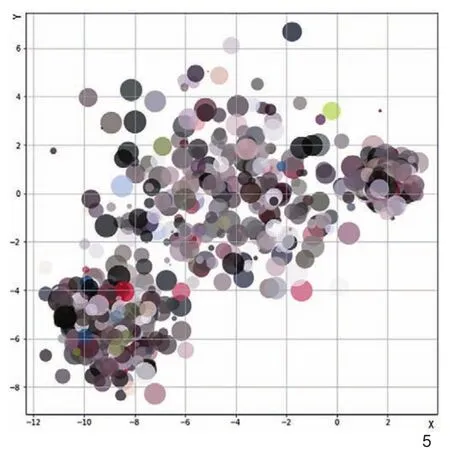
5 北京碧云寺色彩印象Color impression of Biyun Temple, Beijing
2 图像识别技术下景观视觉质量评估与网络应用平台部署实验
2.1 实验目的
在大数据分析技术及机器学习算法成熟之前,视觉景观评估的研究通常制定用于评估景观可视化的标准分类:准确度、代表性、清晰度、兴趣度、合法性、视觉信息获取及编制和演示[13],以专家评估和公众参与的方式来达到评估视觉景观的目的。随着科学技术的发展,也出现应用最新技术来研究景观视觉质量的方法,例如基于VR全景图技术的乡村景观视觉评价偏好研究[14],基于眼动的景观视觉质量评价[15-16]等。景观视觉质量评价是基于人对美的追求,在美学意义上表现为在景观观赏中获得主观的满足。实际上好的景观可以愉悦身心、减轻人们的日常压力,因此出现不少研究景观视觉质量评估的方法。但是主观定义的一些指标,例如可见度、连续度、视域面积占比、相对坡度和相对距离景观视觉敏感度等指标[17]来评价景观视觉质量与人们对美的衡量会在一定程度上存在难以避免的差异。机器学习则试图从大量历史数据中挖掘其中隐含的规律,用于预测或者分类:因此对于以人意识为基本的景观视觉质量评价可以借助机器学习的方法,学习大量含有标签的样本来建立模型,进而利用模型来预测景观视觉价值,这也是本实验的目的所在。
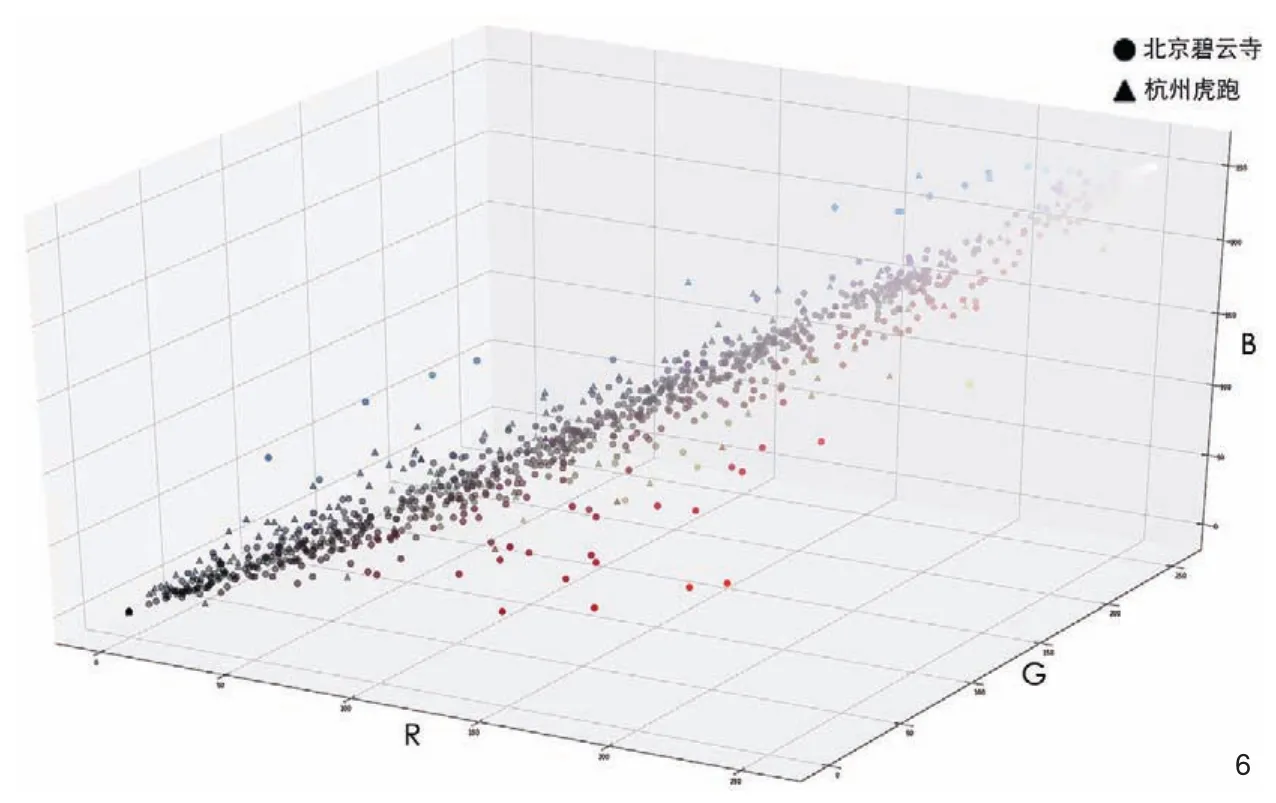
6 色彩数据的三维空间投射分布Three-dimensional spatial projection distribution of color data
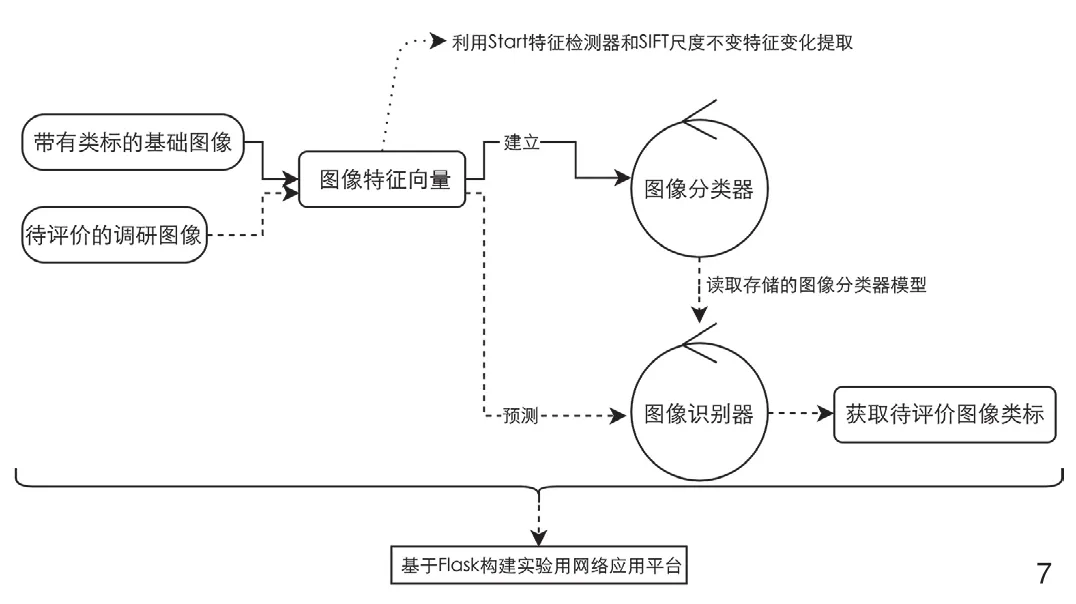
7 景观视觉质量评估与网络应用平台部署Visual quality evaluation of landscape and network application platform deployment
2.2 方法与数据
因为目前缺少评价景观视觉质量带有标签(类标)的图像数据源,因此实验小组通过自建的网络平台自行对准格尔旗薛大快速路城市公园道项目调研中的图像进行评价,用于模型的训练。具体的技术路线如图7,首先建立基于图像视觉的基础评价类标库,用好、中和差3个类标。在构建的网络平台上发布大量不同城市或者自然景观的图像,以便更多公众参与评价。每一幅图像对应多人评价统计的结果,计算多数为对应的类标,这样就构建了一个基于人类纯粹视觉感知的数据库,参与评价的人越多,越容易反映大多数人共同的感知结果。同时利用Start特征检测器和SIFT尺度不变特征变换提取图像特征向量,构建视觉词袋模型(Bag-of-Words Model,简称BoW),聚类所有图像特征向量。本实验采用极端随机森林算法[18],每一个聚类即为一个视觉词汇,这些视觉词汇的频数作为图像分类器的解释变量部分,对应建立的图像类标构建机器模型。最后创建图像识别器,调取图像分类器建立的分类模型,以及计算待预测图像的特征向量,获取待评价图像的类标。当要对新调研区域的图像进行评价时,解析其图像特征向量后,直接作为图像分类器的解释变量,预测的类标即为该图像的一个视觉景观质量的评价。为了更好地收集评价信息,基于Flask构建实验用网络应用平台,建立不断自行优化参数的模型,以及根据该模型实时预测图像视觉评价结果。
2.3 结果与讨论
图8为参与图像打分建立基础图像视觉评价具有类标的图像样本库,图9为基于图像分类器模型预测图像分数,预测的结果反映了人们对自然景观的偏好,其中对于穿越于自然景观的道路、人工建造的挡土墙的视觉感知并不好。通过机器学习分类器、聚类器算法的综合应用来建立模型,并建立用于模型训练的具有类标的图像数据集训练模型,应用训练好的模型预测待评价图像的类标即实现对该图像的视觉景观评价,因此可以依赖于人感官应用机器学习实现景观视觉美的评估。基于机器学习,尤其深度学习需要大量相关的样本数据集,数据集的建立相当耗费人工,例如手写数字数据集MNIST包含一个含6万个样本的训练集和一个含1万个样本的测试集,可以用于图像分割的MS-COCO图像数据集的图像样本则超过33万张,有大于20万张的图像已被标记。大的数据集通常依赖全球贡献者的标识得以实现。本次实验的样本数量受人工标识成本的限制,只有约500张图像标识,这是进一步实验需要重点调整的部分。
因为预测结果与最初的基础评价,即类标的设定有关,如果基础评价的是景观的视觉质量,则对应输出视觉评价结果。如果基础评价类标库是为区分人工建筑还是自然景观,则预测结果为该图像是人工建筑还是自然景观的分类。在风景园林领域,基于图像识别器与图像分类器相结合的图像分析机制,可以用于与视觉相关的分析研究上。
3 用于设计方案遴选的地形生成方法
3.1 实验目的
数字设计迅猛发展,形成了丰富的理论与方法,许多研究者尝试运用数字设计方法来开发由计算机自动生成设计方案的参数化模型,减少建筑师将设计构思转化为设计方案的工作负担和时间延迟;提出简化的模拟算法快速计算设计方案的性能指标,减少获得技术性能评价的时间延迟;以某些性能指标作为目标,利用遗传算法等对设计方案进行自动寻优,找到设定目标下的“最优方案”等[19]。其中大部分的研究都或多或少的使用参数化设计工具(往往以Grasshopper节点式编程为主)来实现,并扩展有大量设计师可用的组件。基于参数化的设计生成方法已经成熟,在进一步的研究中试图从人工智能下的机器学习途径找到一些设计生成的新方法,并以探索设计方案遴选的地形生成方法为切入点,亦为本次实验的目的。
3.2 方法与数据
根据应用机器学习方法的不同,此次实验包含2个子项目:1)基于深度学习生成对抗网络的地形生成,学习给定区域自然地形特征来自主创作地形的过程;2)建立遮罩,预测未知区域的高程,试图学习已有地形设计,来弥补地形缺失的部分。
8 参与图像打分页面Page of participating in image scoring
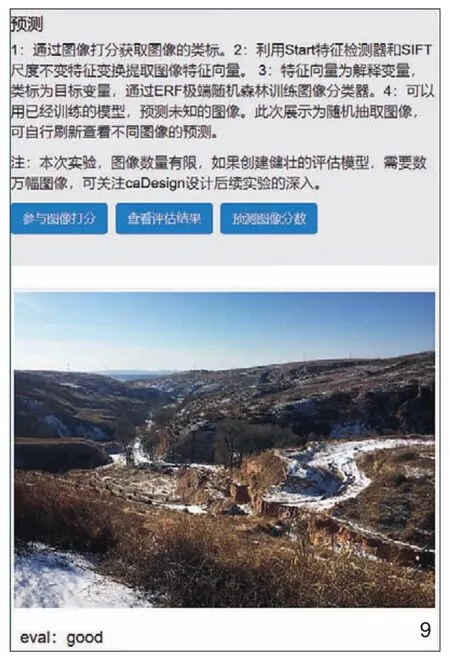
9 预测图像分数页面Page of predicting image score

10 基于深度学习GAN的地形生成过程Terrain generation based on the GAN of deep learning
3.2.1 深度学习生成对抗网络的地形生成的方法与数据
图10为该实验的技术路线,核心的算法为生成对抗网络(GAN)。GAN包括2个模型:生成模型(Generative Model)和判别模型(Discriminative Model)。通过移植WGANGP生成对抗网络建立地形生成模型。因为学习地形设计需要海量的样本,获取海量高程数据可以使用全球数字高程模型(Global Digital Elevation Model,简称GDEM)30 m高空分辨率的高程数据。DEM分辨率为30 m,设置单元大小为64 m×64 m时,所实验的高程数据实际单元覆盖范围为1 920 m×1 920 m的区域,总共切分的样本量为135 192个。通过学习样本,生成模型可以将随机的输入值转换成具有样本特征的高程数据,图10中给出了训练阶段为0~300时生成的4个地形,因为迭代次数较少,模型未充分学习样本,生成的地形没有规律,随机性较强。当训练到18~400时,给出了100个生成的地形数据,此时生成的地形基本具有自然山川空间特征,可以用于地形设计模式的研究。
3.2.2 建立遮罩,预测未知区域高程的方法与数据
数据选择圆明园修复之前的地形数据,采用机器学习的回归算法(图11)。此类方法有2个关键点:1)构建遮罩(mask),遮罩嵌套有2层,外层为已知环境,内层为待生成的未知区域。为方便遮罩内外边界的识别,将其处理为数据0和1区分。2)按照遮罩的大小切分地形高程数据,获取多个训练样本。当训练完成后,就可以根据训练的模型,由给定的已知地形高程环境来预测未知区域的地形。由于受到样本量的限制,预测的地形高程与已知环境高程之间的过渡并不平缓,地形空间的营造尚不理想。图11给出了基于Extra Trees、K-nn、Linear Regression和Ridge 4种回归模型所预测的地形,其中Extra Trees预测的地形高程具有一定的空间艺术性。
3.3 结果与讨论
2个实验的结果在一定程度上达到了实验的目的,但也存在一定的差距。实验1的主要目的是学习指定区域的地形特点来创作具有此类特点的地形设计,因为GDEM 30 m高空分辨率的高程数据精度不高,地形的细节无法展现出来。在进一步的实验中可以尝试获取高精度的、具有同一地形特征的大量地形数据来解决这个问题。实验2主要目的是根据已有地形修复受损地形,因为圆明园地形样本量较少,容易造成过拟合使得预测结果较差,解决的方法通常是增加样本量,然而如果增加不符合圆明园营造特征的数据,预测的结果将不具备其自身地形的特征,是进一步实验需要重点解决的问题。
就设计方案遴选地形生成方法的2个子项目。实验1是学习给定区域自然地形特征来自主创作地形的过程,一方面可以用于设计创作灵感的触发、生成方案的直接移植、多种地形空间形式的探索;另一方面可以用于更广阔区域上,不同区域地形地貌的特征提取以及特征的比较分析。实验2学习已有地形设计,来弥补地形缺失的部分,补全的地形设计虽然有所学习地形的特点,但是具有一定的随机性,对于圆明园这样的遗址公园,目前通过简单的机器学习修复地形的方法并不可行。但是,在设计创作层面,设计师可以自主设计部分地形,把控场地边界和地形空间特点,而部分可采用实验2的方法来生成地形,补全设计,或者仅用于方案推演的参考。
4 结语
规划设计学科传统意义的计算机辅助设计主要强调二维制图和三维模型,在相关数据分析中则借助电子表格(通常以Microsoft Excel为主)、统计分析软件(通常以SPSS为主)、科学计算工具(通常以MATLAB和R为主),同时地理信息系统(Geographic Information System,简称GIS,主流平台有ArcGIS和QGIS)中包含有大量完善的算法工具,以及大量重点解决某一领域的专属工具,例如复杂系统多智能体仿真环境NetLogo、量化生境斑块和连通性重要程度的Conefor、时空分析和模拟的复杂空间算法工具Dinamica EGO等。大量集成工具中往往包含机器学习算法,涉及分类、聚类和回归三大主要方向。为了拓展设计的创造性和研究分析中数据处理的能力,目前高校师生和设计师逐渐地开始学习程序设计语言(主要以Python为主,部分涉及C语言及其他程序语言类型),来应对第4次工业革命(以人工智能、清洁能源、机器人技术、量子信息技术、虚拟现实以及生物技术为主)为规划设计学科在设计研究方法上带来的机遇。
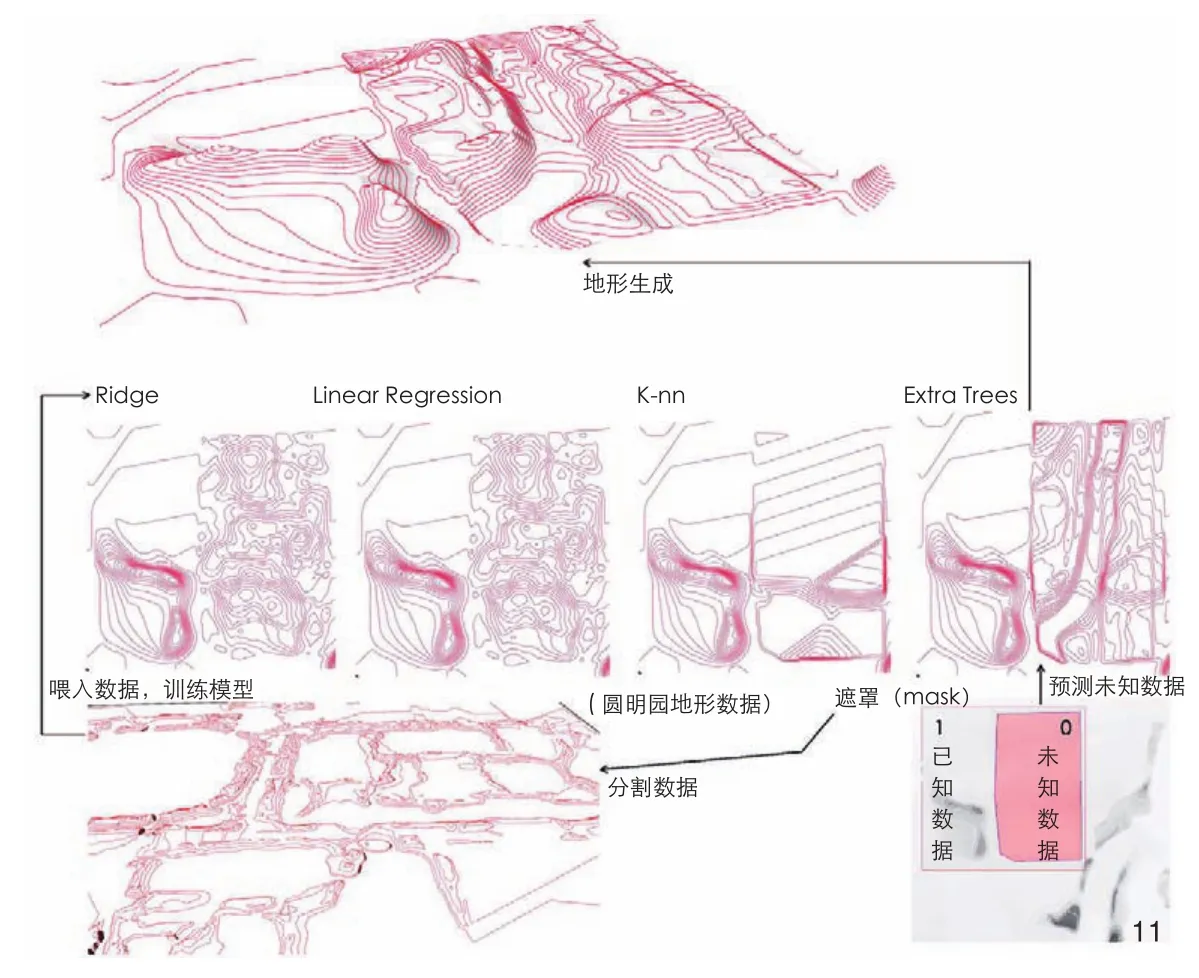
11 建立遮罩,预测未知区域高程的地形生成过程Building a mask and predicting the terrain generation process of elevation in unknown areas
本研究涉及3个实验,前2个偏向于数据分析研究层面,后1个(含2个子项目)偏向于数字设计创作方面。包含机器学习分类(采用了极端随机森林算法)、聚类(采用了KMeans算法)和回归(涉及Extra Trees、K-nn、Linear Regression和Ridge)以及深度学习中的生成对抗网络,试图探索机器学习在风景园林领域下的一些应用模式。因为scikit-learn机器学习和tensorflow深度学习开源库框架的出现,机器学习和深度学习广泛应用于各个领域,成为以智能化的方法解决相关问题的有效工具,是规划设计领域最为前沿,能够引领未来规划设计方向的主要途径之一。
机器学习很难单独去解决问题,只有将其应用结合到规划设计学科中涉及的更为广泛的领域,例如大数据中的数据处理与分析、地理信息系统、复杂系统、参数化技术、建筑信息模型、网络技术以及嵌入式系统实验设备等相关技术,才能更好地发挥作用。3项实验中基本都需要将机器学习结合到地理信息系统,或获取数据,或分析数据;在地形生成中则结合了参数化设计技术,以参数化的方式读取生成的地形数据三维显示地形;而景观视觉质量评价应用网络技术部署平台,收集评价信息和用训练的模型提供服务。当前城乡规划、风景园林和建筑领域都在推动着数字化建设,数字化涉及的内容广泛庞杂,机器学习是数字化技术中的一种智能化解决问题的工具,综合运用多种途径,互相结合,可以有效解决传统中遇到的或者因为新技术而出现的新问题。
注释:
文中图片均由作者绘制。
