基于卷积神经网络的运动行人识别算法的研究
2019-12-03寇海莲
于 闯, 杨 姝, 寇海莲
(1. 沈阳师范大学 计算机与数学基础教学部, 沈阳 110034;2. 沈阳师范大学 教育技术学院, 沈阳 110034)
0 引 言
目前,以定点视频监控为主要模式的视频监控系统,在我国社会生产和人们日常生活中,已经得到广泛的应用[1-2]。对视频监控系统中监控到的各种对象,尤其是对运动行人进行自动检测与识别,有着非常重要的意义[3]。许多研究人员对运动行人检测和识别算法进行了大量的研究。但由于监控视频中,远景区域运动行人的目标过小,对监控视频远景区域中的运动行人的检测存在较明显的漏检和误检的问题。针对这个问题,本文提出了一种对监控视频中远景区域增设辅助变焦摄像头的方法,来解决远景区域中运动行人漏检和误检的问题。具体的方法如下:首先,增设辅助变焦摄像头对系统中的远景区域进行监控,使得位于远景区域中的视频图像分辨率提高至原来的2倍;其次,对监控系统中远景区域和增加的辅助摄像头获得的视频图像分别进行运动目标的检测、去噪和提取,得到运动目标的图像;然后,通过人工方法,对图像中的运动目标进行类别标识,获得训练样本和检验样本,其中,远景区域获得2组视频图像检验样本;最后,利用训练样本训练卷积神经网络,进行运动行人的识别[4]。实验结果表明,使用本文提出的方法,可以有效提高远景区域中运动行人的识别准确率,卷积神经网络准确率达到92.61%,行人目标的相对检出率提高了95.29%,行人分类准确率提高了15.14%,可以满足识别精度的要求。
1 基于卷积神经网络的运动行人识别算法
1.1 监控视频中运动目标的检测和提取
监控视频中运动目标的检测和提取包括对运动目标进行检测、对检测出的运动目标进行去噪处理和对运动目标进行提取3个步骤。
1.1.1 对运动目标进行检测
在视频图像处理领域中,基于运动特征的目标检测算法中比较常见的有帧间差分法[5]、光流法[6]和高斯背景建模法等[7]。帧间差分法适合应用于背景固定的场景,但这种方法在运动检测时容易出现空洞、幻影等问题,这严重影响到运动目标的检测准确率[8]。光流法在使用时,需要满足图像亮度基本不变、物体的运行微小和空间一致性的3个条件。根据光流法对运动目标进行检测的原理,其适合应用在实时性要求不高的场景[9]。混合高斯模型是单高斯模型的推广,它克服了单高斯模型只能对背景建立单一模式的不足[10]。当背景中出现如树枝晃动、水纹波动等多模态时,使用混合高斯模型对背景进行建模具有一定的鲁棒性。
通过对3种不同算法的比对与分析,可以看出本文监控视频的场景不适宜采用帧间差分法和光流法,如背景中树枝晃动造成背景多模态的情况以及行人快速通过监控视频的范围而要求算法要有一定的实时性。而混合高斯模型恰恰符合本文的场景。
混合高斯模型原理为,当视频图像背景为单一模式时,背景像素分布符合高斯密度分布函数,可以用高斯密度分布函数建模;当视频图像背景为多模态时,背景像素分布符合混合高斯密度分布,可以用混合高斯密度函数建模[11]。对于二维图像,高斯密度和混合高斯密度的分布函数分别由公式(1)和(2)表示。
高斯密度分布函数为:
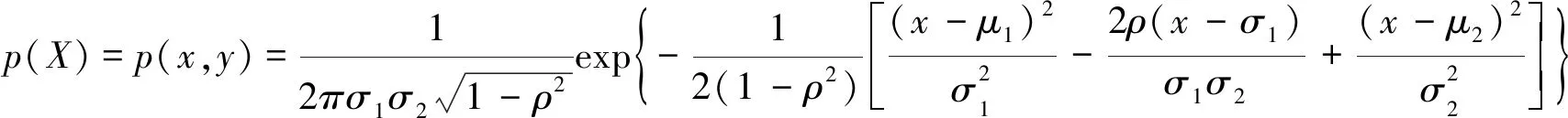
(1)
其中:X=(x,y)为二维随机变量,u1,u2,σ1,σ2分别为变量x,y的均值和方差,ρ为变量x,y的协方差。
混合高斯密度分布函数为:

(2)
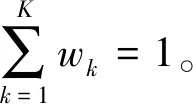
对于二维视频中运动目标检测的高斯模型由式(3)表示。
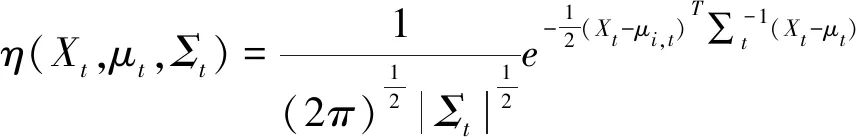
(3)
其中Xt为时刻t的像素值,μt和Σt表示像素点在t时刻的均方差。模型中的均值和方差的更新如下:
其中:ρ为学习率。
在混合高斯背景函数建立之后,背景进行实时更新计算,算法中结合权值、权值均值和实时计算出的背景图像来判断目标像素点是属于前景还是背景。
1.1.2 对检测出的运动目标进行去噪处理
使用高斯建模检测出的运动目标,还存在噪声、目标前景有空洞以及影子影响等问题,本文采取如下方法进行处理。
由于视频画面中的噪声是由监控摄像头本身以及视频压缩存储处理产生的,所以采用处理这些噪声效果较好的中值滤波算法滤除噪声的干扰[12]。
直接使用高斯背景建模法分离出的运动目标,容易产生空洞、边缘缺失以及影子干扰等问题,需要使用不同方法对这些存在的问题进行处理。
对产生的空洞现象及边缘缺失等问题,使用图像膨胀算法来处理。对于影子的存在对运动目标检测造成目标区域划定位置不准确的问题,在高斯背景建模算法中,对隶属于影子的像素点进行标记,可以对影子的不良影响有一定的抑制作用。关于目标头部、足部缺失的问题,使用“目标范围预伸缩方法”来解决,即将位于预先设定好的伸缩范围内并且不隶属于任一运动目标的较小连通域划定到原检测目标范围内,并重新计算目标坐标与范围。
1.1.3 对运动目标进行提取
首先使用1.1.1中介绍的混合高斯模型对运动目标进行检测,得到初步的前景目标集合,再经1.1.2中介绍的去噪等处理,可得到各目标联通区域,对其分别取得最大外接矩形,便得到运动目标的坐标、宽度和高度。然后对目标图片进行截取与保存,将各目标图像及相关原始图像等数据保存起来,供实验分析及后续数据处理过程使用。
1.2 获取训练样本和检验样本
对相同间隔时段内由主、辅摄像头录制出的2组监控视频分别执行运动目标提取算法,来获得训练样本和检验样本。由于采用逐帧检测的方式会产生同一目标反复出现在样本中的问题,使得样本不具备普遍性,因而设计并采用固定间隔时间检测的方法。监控视频文件的帧率预设为25帧/s,设定检测间隔15 s。
对结果进行人工筛查,在主摄像头所录制的视频中选定的远景区域中检测到的完整单个行人目标的数量为743个。在辅助摄像头所录制的视频中检测到的完整单个行人目标的数量为1 451个。采用辅助变焦摄像头进行检测,在运动目标检测算法中,行人目标的相对检出率提高了95.29%。同时,检测到的运动目标的分辨率普遍得到提高,分辨率的提高将有利于特征的提取和分类,鉴于此,辅助监控视频中检测到的目标将作为训练样本。
另选取一组监控视频,运行目标提取程序,分别取得数量各为300的2组行人目标用作检验样本,用于对卷积神经网络的准确率进行检验。
采用辅助摄像头对远景区域进行行人的辅助检测后,行人检测整体算法发生以下变化。未采用辅助摄像头对远景区域进行行人的辅助检测时,直接对视频进行运动检测,得到训练样本。使用样本训练卷积神经网络,得到训练好的卷积神经网络模型用于行人分类;采用辅助摄像头对远景区域进行行人的辅助检测时,将监控画面平均分割为4个区域,上面2个区域对应于远景区域,下面2个区域对应于近景区域。远景区域采用辅助摄像头进行行人的辅助检测,非远景区域直接进行行人检测。本文的研究区域确定为远景区域中的右半部分,对区域中行人检测结果进行比对研究。先对辅助摄像头录制出的视频进行运动检测,得到分辨率较高的运动目标用作训练样本,再训练卷积神经网络,得到训练好的卷积神经网络模型用于主、辅摄像头分别录制出的视频的行人分类。
1.3 AlexNet卷积神经网络
卷积神经网络属于深度学习领域中的网络模型,它在图像目标识别、分类等领域应用广泛,并涌现出很多基于卷积神经网络的深度神经网络模型[13-14]。使用卷积神经网络对目标进行识别,不需要事先对图像进行预处理,不需要预先设计特征提取算法。在卷积神经网络训练过程中,把原始图像直接输入到网络模型中,网络能够自动学习到各层参数,从而实现在应用环境中完成对目标的识别和分类。
卷积神经网络由卷积层和池化层所构成,卷积层内要进行非线性激活、批正则化等计算。卷积神经网络通常的处理单元可以描述为“卷积-激活-池化”,能够实现局部感知、权值共享和降维的目的,并能够自动提取到高维特征[15]。其中,AlexNet卷积神经网络由于具有网络层次清晰、识别精度高、系统硬件资源消耗较低等优点,在图像识别领域里得到广泛应用[16-17]。
AlexNet卷积神经网络共有13层结构。第1层网络数据输入层Data;第2层卷积层conv1,卷积核设定为3×3,步长为4;第3层池化层pool1,池化核设定为3×3,步长为2;第4层卷积层conv2,卷积核设定为5×5,步长为1;第5层池化层pool2,池化核设定为3×3,步长为2;第6层卷积层conv3,卷积核设定为3×3,步长为1;第7层卷积层conv4,卷积核设定为3×3,步长为1;第8层卷积层conv5,卷积核设定为3×3,步长为1;第9层池化层pool5,池化核设定为3×3,步长为2;第10层全连接层fc6;第11层全连接层fc7;第12层全连接层fc8;第13层输出层[15]。
本文以AlexNet结构为基础,使用对监控视频处理后得到的行人数据集对卷积神经网络进行训练,然后对检验样本进行分类与数据统计分析。
2 实验结果与分析
2.1 实验步骤
在实验中,我们在监控系统中录制时长约7.5 h的视频,每隔15 s保存1次目标检测结果,经人工筛选,共获得输入图像正样本1 451幅,输入图像负样本1 085幅。为解决因远景行人目标过小等因素造成行人漏检和误检等问题,增设了辅助摄像头,辅助摄像头录制和截取帧的时间长度与监控系统中主摄像头相同。辅助变焦监控头的视频监控区域为主视频监控远景区域的范围,即右上部分,如图1(a)所示,其中,整幅画面为主摄像头视频监控区域,图中黑色矩形框内为对应于辅助变焦摄像头视频监控区域。通过设置辅助变焦摄像头,使得主视频监控区域中远景区域监控范围视频图像的分辨率放大了2倍,如图1(b) 所示。

(a)—主摄像头中的远景区域; (b)—辅助摄像头放大的远景区域。
使用高斯背景建模法、图像降噪和目标提取算法,分别对主监控视频图像和辅助摄像头录制的视频图像进行检测和提取,一帧的处理结果分别如图2(a)、图2(b)、图2(c)、图2(d)所示。在时长为7.5 h的同一时间段视频图像中,主监控视频在远景区域检测到的完整单个运动行人的个数为743个,而辅助摄像头录制的监控视频中检测出完整的单个行人个数为1 451个,是主监控视频远景区域检测出的1.98倍,行人目标的相对检出率提高了95.29%。这种方法有效地克服了因远景区域行人过小而漏检的问题。

(a)—高斯模型检测运动目标的结果; (b)—运动目标去噪处理的结果;(c)—主摄像头远景区域检测结果; (d)—辅助摄像头检测结果。
其次,在运动目标检测的基础上,将人工标识出的运动行人图像1 451幅和负样本1 085幅作为训练样本,另取一段视频,人工标识运动行人图像各为300幅的2组行人目标作为检测样本。
最后,将2 536个训练样本输入到1.3节构造的卷积神经网络,进行网络训练。根据卷积神经网络的训练常规方法,网络训练初期的学习率应选用较大值,这样可以避免出现收敛于局部最小值的问题。随着训练的逐步进行,分阶段调小学习率。网络开始训练时,设定学习率为0.01,然后分阶段调小学习率使网络训练得到的参数优化,如图3所示。卷积神经网络的训练准确率如图4所示,训练准确率达到95.16%,效果较好[15]。

图3 学习率设置Fig.3 Learning rate setting
2.2 结果分析
使用训练好的卷积神经网络模型对数量各为300的2组行人检验样本进行分类测试,主监控视频远景区域中行人分类准确率为80.43%。采用辅助变焦摄像头进行辅助检测的方法,行人分类准确率为92.61%。行人分类准确率提高了15.14%,取得了较好的检测效果。
通过上述实验结果可以得出,采用辅助变焦摄像头对远景区域内行人检测,可以有效提高检测目标的分辨率,从而有助于提高行人分类的准确率。

图4 网络训练结果Fig.4 Network training results
3 结 论
对于视频监控系统来说,位于主监控摄像头远景区域中的运动目标分辨率较低,清晰度较差,因此容易造成误检和漏检等问题。借助辅助摄像头录制出的监控视频,从中检测到的运动目标分辨率得到提高,可以降低远景区域中行人的检测误差,从而提高行人分类的准确率。对视频监控中远景区域增设辅助变焦摄像头的方法,是一种行之有效的方法。
