基于logistic回归的肺癌危险度评价模型的构建
2019-12-03段书音何霞霞程明超吴拥军
李 迪,段书音,何霞霞,程明超,吴拥军
1)郑州大学公共卫生学院卫生化学教研室 郑州 450001 2)郑州方达医药科技有限公司 郑州 450000
美国癌症协会研究[1]表明,2018年美国男性与女性肺癌死亡率均居主要致死性癌症种类的首位。2016年我国国家癌症中心报告[2]指出,2015年中国有429.2万人患癌症,因癌症导致死亡的有281.4万例,其中肺癌是主要的致死性肿瘤。肺癌严重威胁人类健康,患者5 a生存率仅为4%;然而Ⅰ期肺癌患者术后5 a生存率可高达70%[3-4]。因此,“早发现、早诊断、早医治”是提升肺癌患者5 a生存率、降低肺癌患者死亡率的有效措施。但目前中国早期肺癌筛查技术不够完善,很多患者发现时已是肺癌中晚期[5-6]。基于此,作者根据流行病学资料及临床资料构建肺癌危险度评价模型,评估其用于肺癌早期筛查的价值。
1 对象与方法
1.1研究对象建模选用的样本为2014年10月至2016年10月郑州大学第一附属医院收治的原发性肺癌患者355例和肺良性疾病患者444例;另外收集2016年7月在该院体检的各项检查结果均提示正常的对照组(472例)资料。所有入选对象均由专业人员对其进行流行病学与临床资料询问,包括年龄、性别、咳嗽、痰中带血、胸闷胸痛、直系家族肿瘤史、直系家族肺癌史等。其中病例组年龄46~67(59.3±10.3)岁,对照组年龄44~67(57.3±17.8)岁;病例组与对照组男女性别比例均接近1∶1,二者人口学特征基本一致。
1.2建模方法采用SPSS 21.0。经过无序多分类logistic回归,首先进行似然比检测自变量的显著性,筛选出变量,再进行肺癌危险度评价模型的构建。
1.3肺癌危险因素分析研究的赋值说明肺癌组为A类,肺良性疾病组为B类,正常对照组为C类。年龄分为5组,依次为1组(<40岁);2组(40~岁);3组(55~岁);4组(70~岁);5组(≥85岁)[7]。性别中0代表女,1代表男。抽烟史、肺部良性疾病史、胸闷胸痛、痰中带血、咳痰、咳嗽、发热出汗、饮酒史、肿瘤家族史、肺癌家族史和咯血中0代表无,1代表有。
2 结果
2.1无序多分类logistic回归分析结果模型见表1。
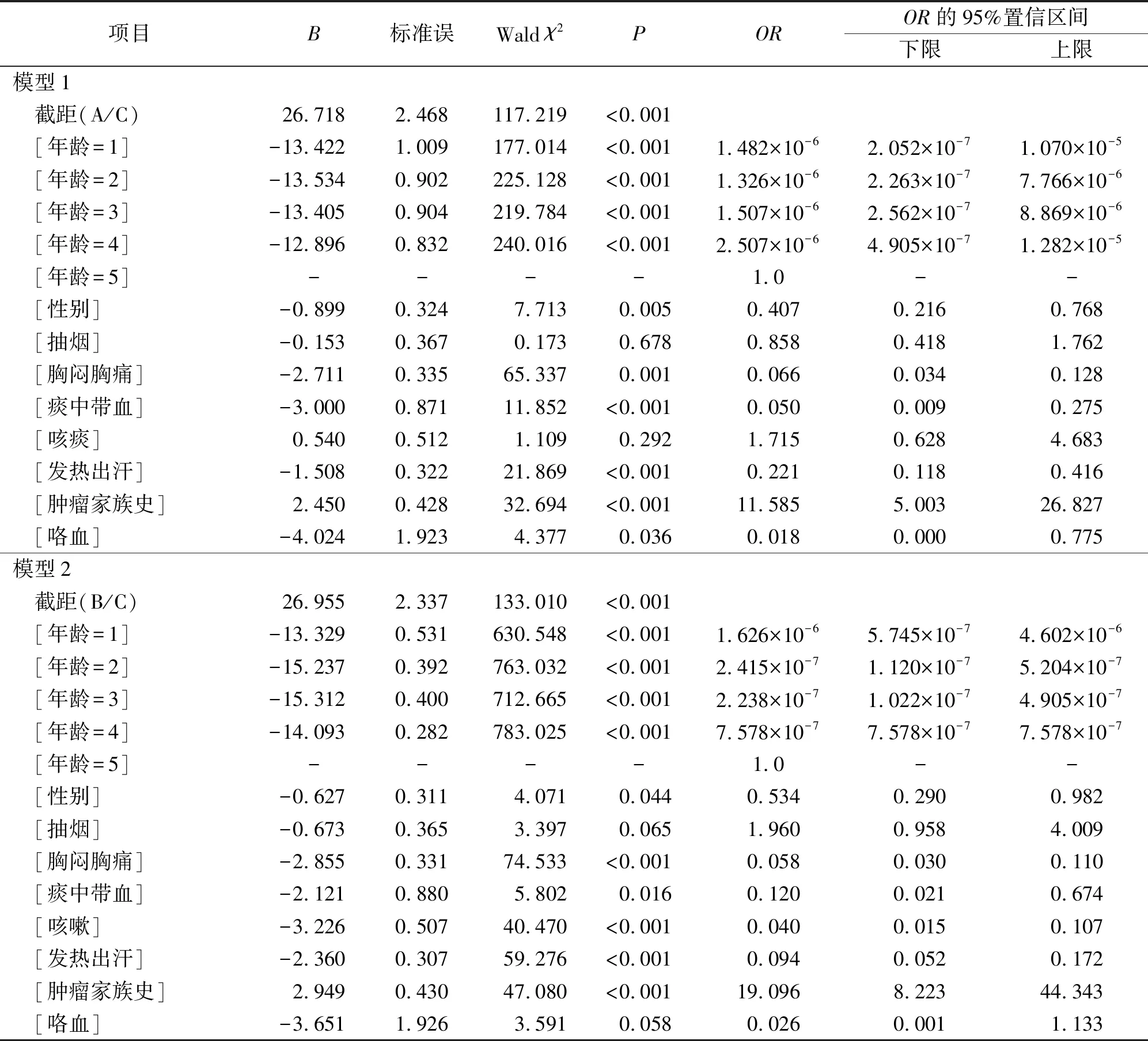
表1 无序多分类logistic回归分析结果
2.1模型样本预测的混淆矩阵结果见表2。由表2可知,实际患肺癌且正确预测的样本量为156,正确率为43.9%;实际为肺良性疾病患者且正确预测的样本量为302,正确率为68.0%;实际上为正常组且正确预测的样本量为437,正确率为92.6%。该模型的总体预测正确率为70.4%。

表2 模型样本预测的混淆矩阵
3 讨论
通过流行病学调查,对一般人群可能罹患肺癌的概率进行风险评估,并在其中筛选出高危人群,然后进行体检,可以极大提高早期诊断率,降低恶性肿瘤的死亡率,这是一种性价比较高的癌症早诊早治模式[8]。
大量临床经验[9-13]表明,肺癌早期筛查项目成功与否关键在于高危人群的筛选,而融合了多种相关危险因素的肺癌危险度评价模型被世界公认是筛查肺癌高危人群的一种有效方法。
本研究通过查阅相关文献,收集样本资料,将肺癌的危险因素及肺癌的临床症状结合起来,经过统计分析,从而构建肺癌危险度评价模型的权重公式,在提高肺癌的早期筛查方面具有较大的实用价值。该研究基于流行病学及临床资料构建肺癌危险度评估模型,其总体预测正确率较高,对于肺癌高危人群的识别有较好的效果,为肺癌早期筛查系统建立奠定了基础。但受限于某些客观条件,本研究样本量相对较少,该模型未能达到理想效果[14];且用于构建肺癌危险度评价模型的危险因素还应包括地理位置[15]、油烟吸入[16]、维生素摄入[17]、精神因素[18]、职业暴露[19]等。
近年来,我国加大了对人群早期肺癌筛查力度,提高了肺癌的诊断率,降低了死亡率,然而当前我国肺癌早期筛查项目仍存在很多的不足[20]。因此,为使该模型取得更好的预测效果,后续研究需扩大样本量,并且纳入更多的相关危险因素做进一步人群研究。
