区分冗余序列的抽象文本摘要
2019-11-29俞鸿飞殷明明段湘煜
俞鸿飞,王 坤,殷明明,段湘煜,张 民
(苏州大学计算机科学与技术学院,江苏 苏州 215006)
自动摘要主要有两种方法:抽取方法[1]和抽象方法[2].抽取方法主要分析文档信息,提取源句子中的一部分信息并按照顺序连接,生成最终的摘要文本.抽象方法主要是基于源文本的核心思想将源文本概述成短文本摘要.抽象方法能够正确重写源文本的核心思想,并且十分切合人类摘要的方法.随着神经网络发展,序列到序列模型也被运用到了抽象文本摘要领域.其主要结构是通过编码长文本序列,在目标端融入注意力机制解码成短摘要文本.
序列到序列架构主要有3种:递归神经网络[3-4](recurrent neural network,RNN)、卷积神经网络[5](convolutional neural network, CNN)以及自注意力机制的神经网络[6].基于RNN的模型架构被广泛采用和探索,主要方法有融入源端句子信息的RNN模型[7];使用统计语言特征命名实体识别(NER)和词性(POS)标签进一步丰富RNN的编码器信息[8].除了有在RNN框架上的修改,也有将CNN架构运用到摘要文本中.如:Gehring等[5]在编码器和解码器都采用了CNN的模型结构,并将其运用到了抽象摘要任务;Wang等[9]在ConvS2S的基础上融入了主题词的嵌入信息,并结合强化学习训练文本摘要系统.此外,还有通过改进训练方法进一步加强文本摘要系统的训练能力.如:Ayana[10]所提出的最小风险训练;Eduno等[11]提出的训练结构化预测模型;以及Lin等[12]提出全局编码结构.以上实验方法通过改进模型结构,融入多种训练方法等对RNN和CNN模型进行拓展以提升文本摘要系统生成摘要的质量.
虽然序列到序列模型能够得到高质量的摘要文本,但并不能有效地区分源端句子中的冗余信息,而且这种冗余信息对于生成摘要的影响往往是负面的.为了解决这一问题,本文中提出了一种能够区分冗余序列的模型结构以提升抽象文本摘要方法的摘要性能.考虑到基于自注意力机制神经网络的Transformer模型在机器翻译领域取得的卓越性能效果,且抽象文本摘要系统与机器翻译相类似,也符合序列到序列的结构特征,因此本文中将Transformer模型结构应用于抽象文本摘要.在Transformer模型基础上,利用冗余序列区分源端序列中的冗余部分,进而更好地提取摘要信息.以Transformer模型作为强基准系统,在Gigaword和DUC2004英语测试集以及LCSTS中文测试集上进行实验验证.
1 基准系统
Transformer模型是基于注意力机制的序列到序列的结构,采用编码器-解码器的框架,该结构先将源文本编码成隐藏向量,再基于源端信息和目标生成的历史信息解码出摘要文本.与传统的序列到序列模型RNN和CNN不同的是,Transformer模型在编码器和解码器上完全采用了自注意力机制.
1.1 词嵌入以及位置编码
对输入的句子元素进行建模,将源端句子X={x1,x2,…,xn}通过分布空间映射成为词向量h=[h1,h2,…,hi,…,hn],其中hi∈Rd,n表示源端输入序列的单词个数,d为词向量的维度大小.需要注意的是,Transformer模型结构无法表示词与词之间的先后顺序关系.为了解决这一问题,Transformer模型嵌入了输入元素的绝对位置向量p=[p1,p2,…,pi,…,pn],其中pi∈Rd;并将两者组合得到最终的词向量e=[h1+p1,h2+p2,…,hn+pn].与源端类似,目标端获得的词向量为g=[g1,g2,…,gm].位置编码对于神经网络十分重要,这能让神经网络学习到句子的序列信息,了解到当前词在序列中相应位置.
1.2 编码器
如图1左侧所示,编码器堆叠了N层的相同网络层,每层都包含了两个子层:多头的自注意力机制层(本文中简称:自注意力层)以及全连接的前馈神经网络层(本文中简称:前馈子层).并且每个子层的输出都运用了残差网络[13]以及层归一化[14],以便训练更深层次的神经网络.
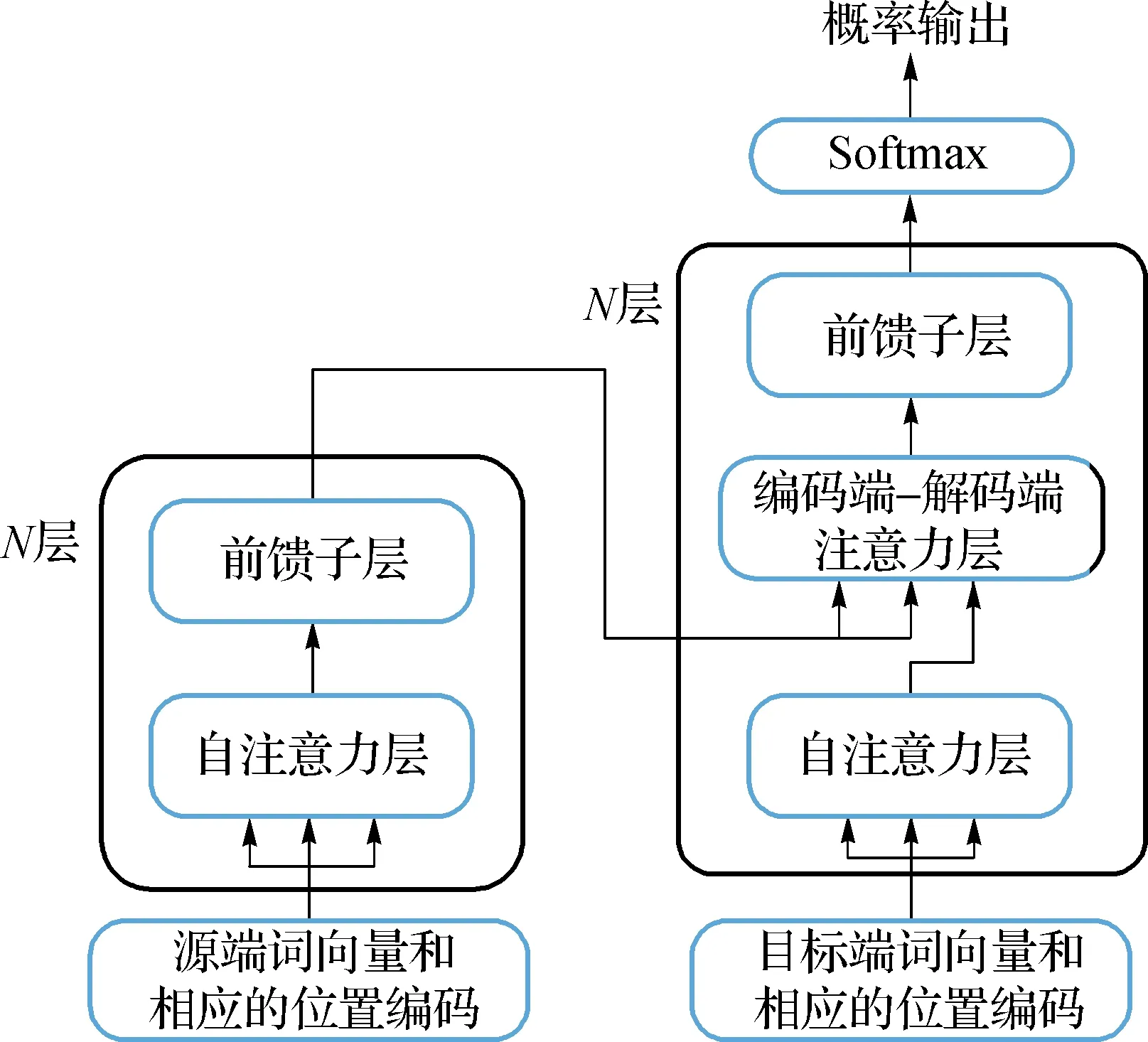
图1 Transformer模型结构Fig.1 The model structure of Transformer
自注意力层主要采用划分成多头的注意力机制以及规范化点乘的注意力机制,具体如式(1)和(2)所示:
(1)
(2)
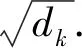
前馈子层主要由两个全连接层以及ReLU激活函数组成,具体公式如(3)所示:
fff(z)=max(0,zW1+b1)W2+b2,
(3)
其中:fff为前馈网络函数;W1∈Rdff×d,W2∈Rdff×d;dff表示前馈子层的内层网络维度;z表示自注意力机制层提取之后的隐藏向量.在通过前馈子层之后,最后的输出会重新输出给后一层的自注意力机制层的,进行更深层次的信息提取,直到N层网络提取特征信息结束再输出给目标端得到相应的概率分布.
1.3 解码器
如图1右侧部分所示,与编码器类似,解码端也堆叠了N层的相同的网络,但是每层由3个子层组成:自注意力层、编码-解码注意力层和前馈子层.目标端的自注意力层的Q,K,V都来自于目标端的词向量g.与源端自注意力层不同的是,目标端需要对当前词的未来信息增加掩码,防止未来单词信息参与隐藏层计算,前馈子层则保持不变.
目标端编码-解码注意力层的主要目的是为了获取更多的源端信息,除了目标端序列的信息,还需要获取当前的目标端词对应源端序列中的某一个词或者某一段的源端序列信息.在编码-解码注意力中,Q来自于解码器的自注意力子层的输出,而K和V则是来自于编码器最后一层的输出.无论是自注意力层还是编码-解码注意力层,依旧采用的是多头的注意力机制并且在每次输出之后仍运用了残差网络和层归一化方法.
2 区分冗余序列的抽象文本摘要
2.1 数据处理
Transformer模型结构最初为机器翻译研究所提出.虽然抽象文本摘要与机器翻译任务都属于序列到序列的任务,但是在数据方面和句子形式上有不同之处.在抽象文本摘要中,目标端的句子相较于源端句子的长度更短,更加精炼.因此在源端句子中有一部分信息是冗余的,不能帮助到目标端摘要的生成,而机器翻译则无冗余信息.
为了解决这一问题,实验分成两个步骤进行:先获取相对应的冗余信息,再将冗余信息运用到Transformer模型结构.获取冗余信息:本文中使用GIZA++工具对平行的摘要数据进行词对齐,获得目标端词对应源端多个词的对齐信息,如图2所示.之后将目标端所对应的源端词用特殊符号
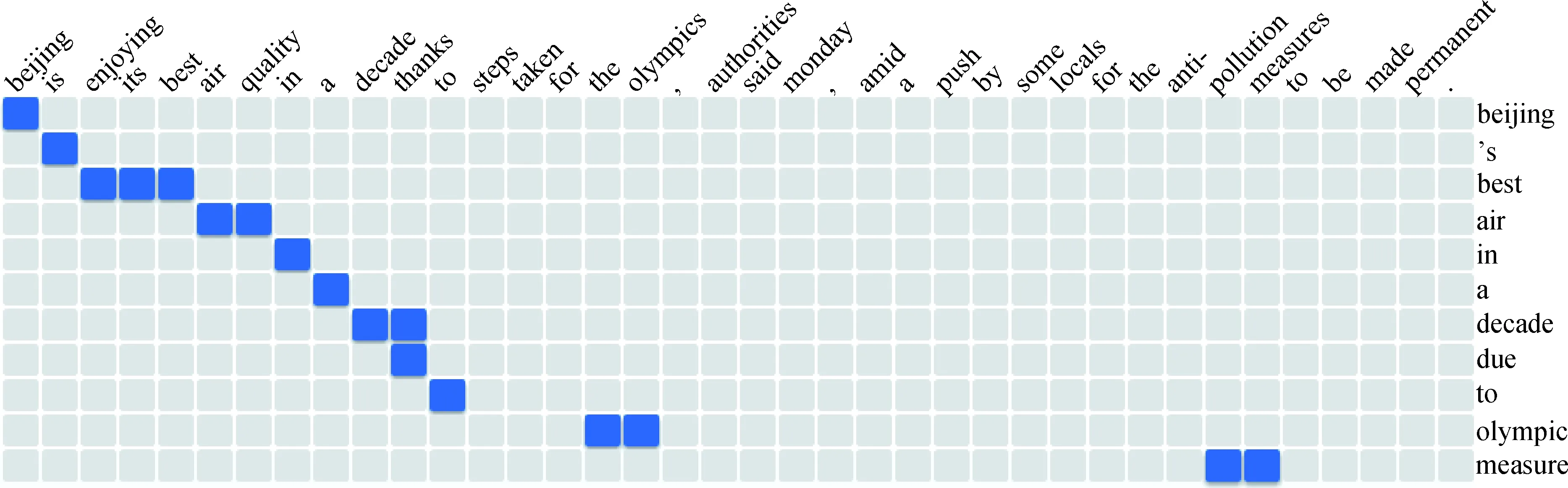
图2 对齐样例Fig.2 Alignment example

Source: Beijing is enjoying its best air quality in a decade thanks to steps taken for the olympics, authorities said monday, amid a push by some locals for the anti- pollution measures to be made permanent.GIZA++: 0-0 1-1 2-2 3-2 4-2 5-3 6-3 7-4 8-5 9-6 10-6 10-7 11-8 15-9 16-9 31-10 32-10Redundancy_Source:
通过上述两个步骤对训练数据和验证集数据进行处理,分别得到了3份数据.第一份是源端文本,第二份是目标端抽象摘要文本,第三份是源端的冗余文本.
2.2 模型搭建
在获得冗余信息之后,本文中对Transformer模型结构做进一步改进.使得Transformer模型能够更好的区分相关信息以及冗余信息.如图3所示,左侧的解码器与基准系统的解码器保持一致,输入摘要序列并输出相对应的摘要序列概率.本文中在原解码器的基础上又增加了一个解码器用于解码冗余特征序列,将GIZA++得到的冗余序列作为输入,通过共享左侧解码器的参数以及经过不同的输出层得到相对应的冗余序列概率.在解码器中所包含的子层都与Transformer中子层保持一致.
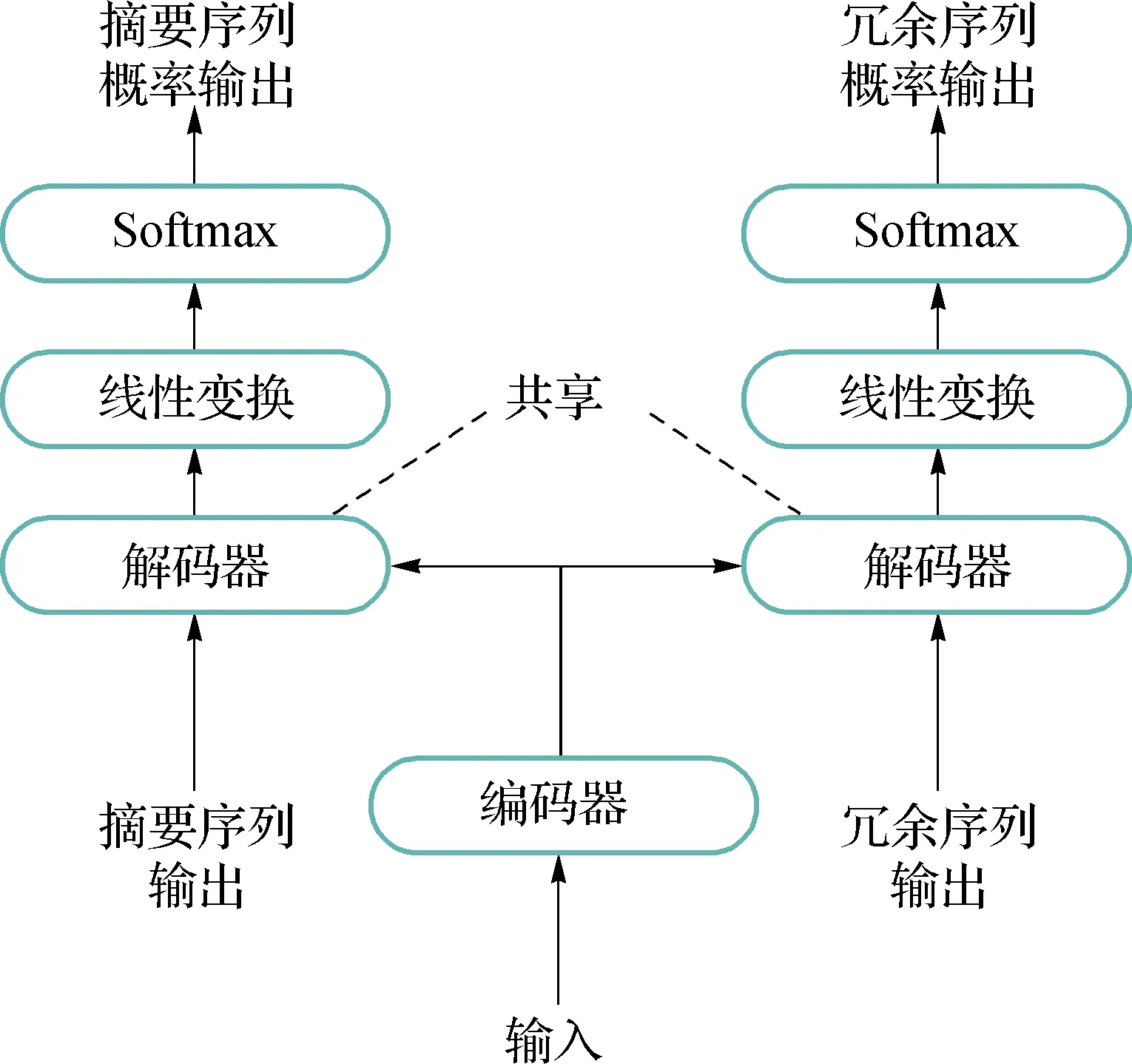
图3 区分冗余序列的模型结构Fig.3 Model structure that distinguishes redundant sequences
本文中通过给定冗余信息的方法,让神经网络能够学习区分源端句子中的相关信息以及冗余信息.摘要序列对应着源端的相关信息,冗余序列则对应着源端的冗余信息.通过反向传播更新神经网络的权值分布,以达到区分冗余序列以及专注源端相关信息的效果.
2.3 损失函数
本文中在原损失函数的基础上融入了冗余损失函数,具体式为:
(4)
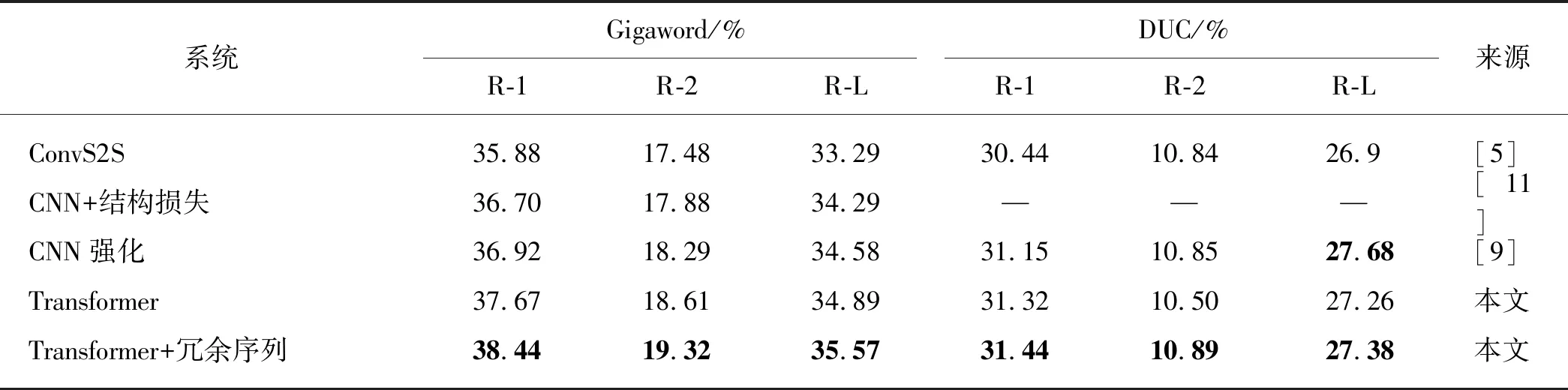
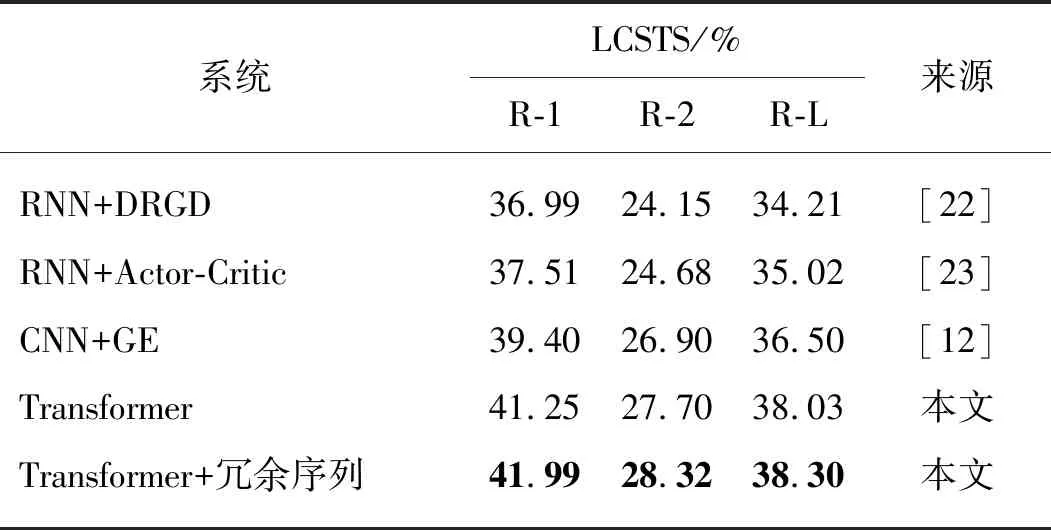
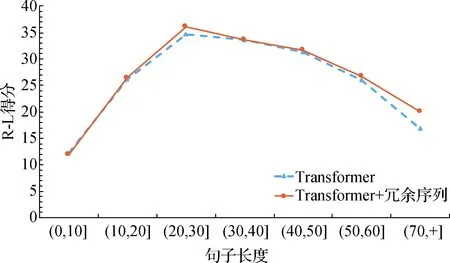
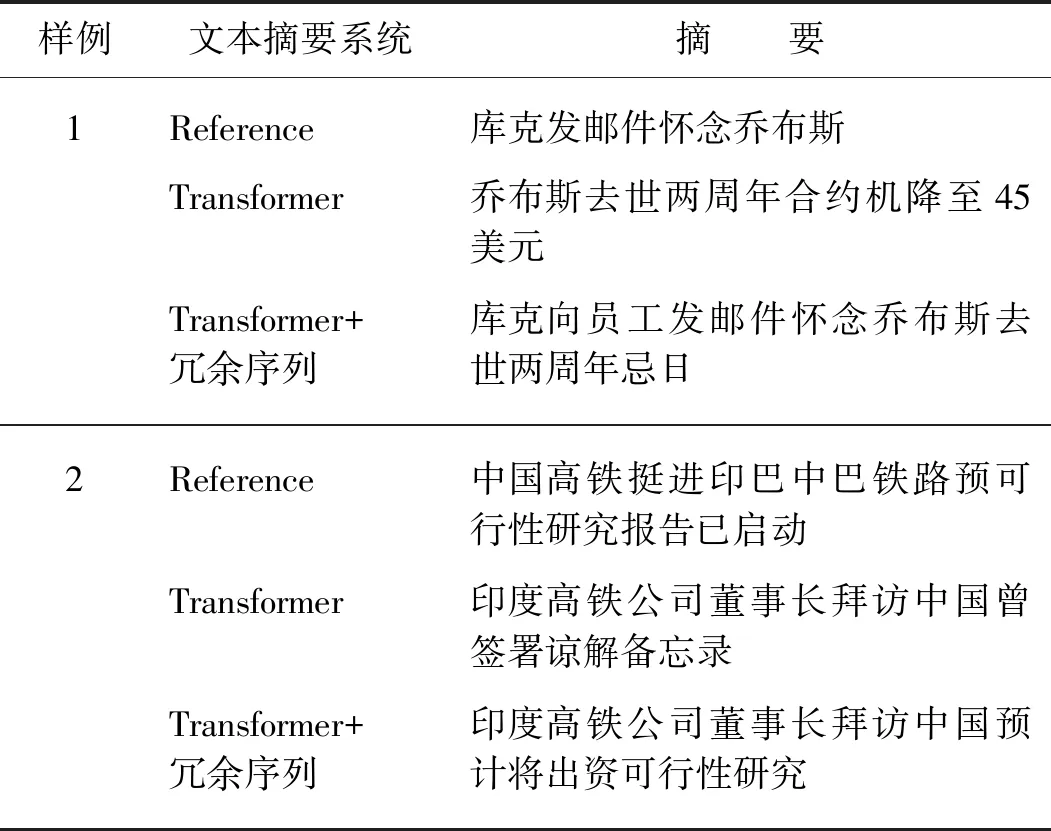
其中:M表示目标端摘要的长度;J表示目标端冗余序列的长度;p(yi|y 本实验在3个抽象文本摘要数据集上评估所提出的方法.首先,将带注释的Gigaword语料采取与Rush等[15]相同的预处理,产生约380万个训练样本、19万个验证样本和1 951个测试样本进行评估.文本到摘要的平行数据对是通过将每篇文章的第一句与其标题配对形成.另外,本文采用DUC-2004[16]作为另一个英文数据集,仅用于实验测试.它包含500个文档,每个文档包含4个人工生成的参考摘要. 本实验使用的最后一个数据集是中文短文本摘要的数据集(LCSTS)[17],该数据集由新浪微博网站收集.遵循原始论文的数据分割,将来自语料库的2 400 000 对文本到摘要的平行数据对用于训练,8 000 对的平行句对用于验证集,并且挑选了高得分的725对平行句对用于测试. 本文中采用Transformer作为基础架构,按图1在编码器和解码器各堆叠6层,嵌入向量和所有隐藏向量的维度设置为512,前馈子层的内层维度为2 048,多头注意力层m=8.在本实验中共享源端、目标端词嵌入层以及目标端的摘要输出层,但并不共享冗余序列的输出层.在英语数据上,本文中运用了字节对编码(byte-pair-encoding,BPE)[18],共享源端到目标端的词汇量并设置为32 000. 本实验在NVDIA 1080 GPU上进行,采用基于深度学习框架PyTorch的Transformer模型为基准框架.在训练期间,调用Adam优化器[19],其中超参数β1=0.9,β2=0.98,ε=10-9,初始学习率为0.000 5.另外,本实验在所有数据集上失活率(dropout)都设置为0.3,标签平滑[20]值设置为0.1.在评估时,本实验采用面向召回替补的摘要评估(recall-oriented understudy for gisting evaluation,ROUGE)[21]作为评估指标.由于标准的ROUGE包只能用于评估英文摘要系统,本文中采用Hu等[17]的方法将中文字映射成的数字ID,以评估中文数据集的性能,在解码的时候,集束搜索(beam search)的大小设置为12. 4.1.1 英文测试集结果 表2给出了近些年神经网络模型在Gizaword和DUC2004上所展现的实验效果以及基准系统Transformer模型和使用了本文中所提出的模型结构的实验结果.需要注意一点,对于Gizaword数据所采用的评估指标是基于F值(正确率(P)与召回率(R)的加权调和平均)的ROUGE-1(R-1)、ROUGE-2(R-2)、ROUGE-L(R-L),而DUC数据的则是基于R.表中列举了3个在抽象文本摘要上的最新成果:Gehring等[5]提出的完全基于卷积构成ConvS2S框架的结果;在此结构的基础上,Edunov等[11]和Wang等[9]分别从结构损失(CNN+结构损失)和强化学习(CNN强化)的角度改进模型的结果.表格中“—”表示文章中并未提及此类数据的实验结果.最后两行分别是Transformer基准系统以及本文方法(Transfomer+冗余序列)的实验结果.从表中可以发现,Transformer基准系统在英文测试集上的表现十分显著.在Gigaword数据上,相较于其他系统,Transformer基准系统的R-1,R-2和R-L得分均最高;并且在添加了冗余序列的信息之后,系统性能得到了进一步地提升.相对于Transformer基准系统,本文中的方法在每种评估指标上的得分均增加了0.7个百分点.在DUC2004数据上,该方法也在基准系统上获得了一定的提升.整体上讲,该方法能够获得更加精准、质量更高的摘要文本. 表2 Gizaword与DUC2004英文测试上的实验结果 4.1.2 中文测试集结果 表3中列出了在LCSTS的中文数据上所尝试的3个最新实验系统以及实验结果:Li等[22]2017年在RNN模型结构的基础上融入深度循环生成解码器(deep recurrent generative decoder, DRGD)的结果;其在2018年提出运用actor-critic框架[23]来增强RNN的训练过程得到的改进结果;Lin等[12]在CNN模型结构上提出全局编码结构(global encoding,GE)的结果.从表3可以看出,基准系统Transformer模型取得了相当高的ROUGE得分,在R-1评估标准下的得分达到了41.25%.在运用了冗余序列信息之后,R-1 得分达到了41.99%,证明本文中的方法能够进一步改善摘要文本的准确度.需要注意的是,以上的实验都是在基于字的数据上所作的尝试. 表3 LCSTS的中文测试集结果 本实验进一步测试了不同长度的Gizaword英文测试集在新模型上的效果.经过调研,Gizaword测试集中的源端句子长度范围主要是从10到90之间.因此,将句子长度以10为单位进行分组,得到了9个组.但是由于第8组和第9组的句子数量过少,将其合并到60+的区间内,整合成为7组.如图3所示的,在大部分区间内,实验模型效果都超过了基准模型的水平.尤其是在(20,30]内,实验结果提升相当明显,R-L得分有超过1.2个百分点的提升.在句子长度超过20的区间上,实验模型都获得了一定的得分提升. 图4 在不同句长上的R-L的得分对比Fig.4 Comparison of R-L scores on different sentence lengths 在表4中,将由本实验方法所生成的摘要文本与基准模型的摘要文本做了对比. 样例文本如下: 样例1:当地时间5日是史蒂夫·乔布斯去世两周年忌日,公司现任CEO库克向全体员工发布邮件怀念这位苹果公司的精神领袖.与此同时,美国三大零售商集体开始对刚刚上市两周的iPhone5C进行优惠促销,两年期的合约机最低售价降至45美元,跌幅过半. 样例2:12月1日,印度高速铁路公司董事长阿格尼霍特里一行来国家铁路局拜访.发言人称,印度铁道部团队目前正在中国,预计会在本周签署协议,中国将出资进行可行性研究并完成报告.中印9月曾签署谅解备忘录. 第一个例子中的主要信息是“库克发邮件怀念乔布斯,同时三大零售商降价合约机”.基准系统关注了“合约机降价”方面,但是源文本的突出重点应该是“怀念乔布斯”,基准系统得到的摘要文本显然没有达到预期的效果,而关注了冗余信息.在使用了本实验中的模型之后,关注点聚焦在“怀念乔布斯”上.在第二个样例中,主要内容是“中国将对中印铁路进行可行性研究”.基准系统还是注意到了“签署谅解备忘录”这个冗余信息,而本实验模型还是着重了“中印铁路的可行性研究”,这样的摘要文本就达到了比较好的水平. 表4 摘要文本样例对比 本文中主要提出了能够区分冗余序列的Transformer的模型结构.该模型结合了抽象文本摘要的特征,在最新的Transformer结构基础上做了进一步的拓展,新增了冗余序列解码器以获取源文本冗余信息.实验结果表明本文中所提出的模型架构有效地提升了抽象文本摘要的水平,并且在中英文测试集上都取得了性能提升. 在目前的实验方法中,本文中仅考虑了冗余信息的抽象文本摘要,并未对相关信息做进一步的研究.在未来的工作中,将考虑如何在模型中更充分地提取与源端相关信息以提升抽象文本摘要的性能.3 实 验
3.1 数据集
3.2 实验设置
4 实验结果和分析
4.1 实验结果
4.2 长度分析
4.3 质量评估分析
5 结 论
