面向任务服务质量的网络资源需求预测算法*
2019-11-28刘林张东
刘林 张东
(91202部队 葫芦岛 125004)
1 引言
云计算是一个用时付费的模型,用户根据这个模型按需获取各种可配置,可共享的虚拟资源。其中资源映射是云计算中相对复杂且重要的关键技术。当用户提出任务时,并不知道自己的任务需求需要什么以及多少虚拟资源。一般情况下,用户都尽可能地选择更多更好的资源,远远超过他们的需求,因此产生了过度供应问题。此外,用户选择的资源不足的话,也会导致任务失败,其Qos指标没法保障。资源映射的目的是为了实现用户需求到虚拟资源的映射,以此来保证用户所需要的服务质量。如果云平台能自动预测用户任务的网络资源需求,在满足任务的服务质量情况下,并利用网络资源匹配技术选择最合适的网络资源来完成任务,为用户提供性价比高的服务,也提高了网络资源利用率,这是一个很有意义的研究问题。
目前,也有很多基于Qos的任务网络资源需求预测的解决方案。田启华[1]等提出了利用层次分析法(AHP)来构造资源分配矩阵,从而确定资源分配权重系数。但利用层次分析法最后得到的结果是每个任务对总资源需求的占比,不能准确地预测任务需求的资源。
吴世山[2]利用神经网络对程序资源消耗预测,以影响程序运行所需要的各项因素作为神经网络的输入,以程序运行所消耗的资源作为网络输出。预测器不断收集程序运行的历史数据作为神经网络的训练数据,从而实现对新应用进行预测。但该方法前提是历史任务已经分门别类地存储在预测系统里,并且已经知道新任务的类别。这在云计算上是十分困难的,因为云计算任务类型是繁多复杂的,需要在任务预测之前用相应的算法对任务进行分类。
Sarka等[3]采用了混合克隆检测技术预测云计算中的任务资源需求,将历史任务执行过程中的资源消耗存储在数据库里。利用克隆技术寻找与新任务资源消耗模式相似的历史任务。找到相似的历史任务后,根据实际情况选用回归的方法预测新任务的资源需求。但克隆技术多基于源码分析,是不利于在公有云环境上推广应用的。
赵春燕[4]提出了一种分配性正义的伯格模型,用一般期待来约束资源选择。根据任务的Qos指标提供给任务特定的一般期待资源向量去寻找合适的虚拟机资源来完成任务。任务完成后利用公平评判函数来修正期待资源向量。这种算法实现简单,利于推广。该算法的核心是如何根据任务得到合适的一般期待资源向量,期待资源向量的好坏影响着整个预测调度系统的性能,但文献中没有提到怎么获取准确的一般期待资源向量。
目前的研究大都实现了任务服务质量指标到虚拟资源的映射。输入给定任务的关键描述和任务的服务质量需求,通过机器学习等技术预测任务的网络资源需求,但目的只是预测网络资源需求的多少,网络资源利用率提升有限。网络资源需求预测算法性能的好坏取决于找到相似历史任务的网络资源消耗的精确程度和调度框架提供的反馈机制。因此,任务完成后,需要一种反馈机制去判定网络资源分配是否公平合理,从而提高网络资源需求预测的准确程度,提高网络资源的使用率,实现一个最优的面向任务的网络资源调度过程。
综上所述,本文提出了一种面向任务网络资源需求预测的网络资源映射框架。为了解决云计算任务类型众多异构等问题,首先对历史执行和待完成任务服务质量识别后,从历史任务集合中搜索相同类别的任务建模利用强化学习进行预测。在任务完成后,设计了两种反馈信息来提高预测的精确度,更接近实际的任务需求。一种是隐式反馈来表示任务是否完成,另一种是显式反馈来表示任务完成实际用了多少网络资源。若分配的网络资源大于实际所用的网络资源,则更新历史任务消耗网络资源数据库。
2 基于强化学习的网络资源需求预测
2.1 总体方案
我们所提的方案是基于强化学习自动预测任务所需求的网络资源。图1为整个方案的流程。首先,我们根据Qos指标对进行任务分类,本文参考了完成时间,带宽,可靠性,费用四个Qos参数。

图1 预测任务网络资源需求的调度过程
当对待执行任务进行合理的分类后,向网络资源预测器输入待执行的任务。网络资源预测器基于历史执行任务预测该任务所需要的虚拟网络资源。然后,网络资源分配器将这些任务分配给合适的可用网络资源。一旦任务成功完成,预测器收集反馈信息来更新数据库的信息。如果由于网络资源容量不足而导致作业终止失败,则它们将由用户重新提交或由调度系统自动执行。总之,该预测器的主要目标是释放未使用的网络资源,提高网络资源的利用率。
2.2 网络资源需求预测算法
预测任务需求网络资源取决于两种主要因素:一是精确得到历史相似任务需求网络资源的能力;二是调度器里的反馈机制。为了做到准确且自动地预测任务网络资源需求,本算法使用强化学习进行预测。强化学习是一种通过代理探索状态空间来学习行为策略的学习算法,此外代理通过修改其行动政策来最大化自己的累积奖励。强化学习还可以很好地应用反馈信息得到更精准的平均实际网络资源需求。
而当任务完成后,需要收集任务的反馈信息。本算法中反馈信息有两种。一种是隐式反馈信息,一种是显式反馈信息。隐式反馈信息反映了任务是否能完成;显式反馈包含任务终止时使用的实际网络资源量。我们收集并报告此信息给预测器,当隐式反馈认为该任务完成,预测器就根据显式反馈信息来改进预测近似值并更接近实际的工作网络资源需求。
此外,我们提出了分类和回归两种方法,通过使用非线性的感知来估计工作要求。在根据准确的反馈信息下,感知机试图估计实际网络资源要求,之后决定是否使用当前的网络资源完成任务。基于强化学习预测算法的如下:
1)初始化感知机关于任务特征向量x的权重向量ω,p表示目前已经成功执行的任务率,设置其为0.5。
2)逐个分析已经分类好待执行的任务。预测当前分析的任务的网络资源需求量E',如果E'小于可用的网络资源能力E,则就提交任务去执行。否则转到步骤3)。
3)设置一个随机数 rand ,其值范围为[0,1]。若 rand>ep/τ+e(1-p)/τ,则利用当前仅有网络资源执行任务,其中τ为强化学习的衰减常数。否则,返回任务给用户。
4)当任务执行完成后,根据式(1)收集反馈信息:

其中U为实际任务使用的网络资源。
5)设置 z=E',为更新目前任务权重向量ω作准备。
6)根据式(2)计算关于ω的导数:

7)利用以下两个公式更新权重向量ω的值:

8)更新任务成功完成率 p值。
虽然,即使现有的网络资源不能满足估计的网络资源,但我们认为任务也有一定概率能完成的。所以设置一个阈值来决定是否用仅有的网络资源来执行任务。这个阈值决定于任务完成率p。这个过程是强化学习的探索阶段。
根据反馈信息我们可以得到任务执行情况。如果任务成功执行则报告所用的网络资源,否则报告最大的分配网络资源量。最后根据执行结果更新感知机的权重向量和探索阈值,不断近似最小网络资源供给方案。由于云计算每天处理的任务的数量是巨大的,用这种学习方式得到基于Qos的任务需求预测是可行的。
3 实验与仿真
3.1 评估指标
本文中,为了验证本文提出网络资源需求预测模型的性能,选取自回归模型、指数平滑算法以及本文中的考虑反馈的综合预测模型分别进行预测,并选取以下3种不同的评价指标对比各模型的预测性能。
1)平均绝对百分比误差MAPE,用于衡量预测模型对网络资源需求预测误差的情况。计算公式如下:

其中,N为测量次数,xt为真实值,x't为预测值。算法的MAPE越小,说明预测值和真实值的偏差越小。
2)均方根误差RMSE,是预测值和真实值之差的平方和的开方与测量次数N的比值,它表示预测数据与真实数据的偏离程度。

3)节点负载利用率,用来衡量每个节点的负载情况,计算公式如下:
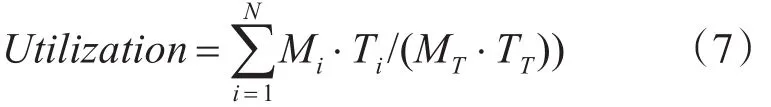
其中,TT为总的运行时间。此外,我们定义任务负载率Task Load来衡量提交任务数量,其值越大,表示调度器中任务的数量越多,计算公式如下:

其中,任务到达时间为 ai(i=1,2,…,N),每一个节点Mi运行时间为Ti秒;MT为运行节点的总数。在开始阶段,系统没到达饱和时候利用率是线性增长的,当系统饱和点处节点利用率越高说明算法性能越好。
3.2 仿真结果
在我们的试验中,我们从一个高性能计算平台上收集数据,构建了一个真实的任务网络资源请求数据集合。选用了其中3/4作为训练集,1/4作为测试集。为了说明本算法的性能,将本算法与自回归预测模型[5],基于径向量神经网络[6]预测模型作对比。
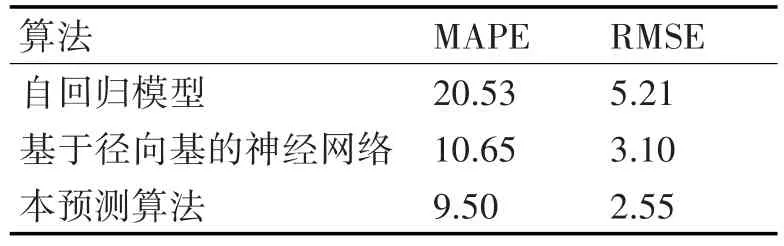
表1 三种网络资源需求预测模型的MAPE和RMSE仿真参数
由表1可知,由于本文的预测算法利用反馈机制不断近似得到实际的网络资源值,使得其预测结果的误差较小,拟合程度也很高。
为了检验各个预测模型的网络资源利用情况,仿真中我们通过改变任务负载率变化节点负载利用率来衡量算法使用网络资源的效率。我们设置了1024个节点,每个节点有不同MB的物理内存,便于简便论证我们方案的性能,我们仅利用节点内存的利用情况进行仿真实验分析。
如图2所示,各个预测模型一开始由于系统的网络资源充足负载利用率都呈线性增长。当任务量到达0.5时候,就慢慢接近饱和。但由于本算法考虑了预测网络资源大于可用网络资源也有可能完成任务的情况,因此负载利用率更高,另一方面也说明预测的精确性更高。
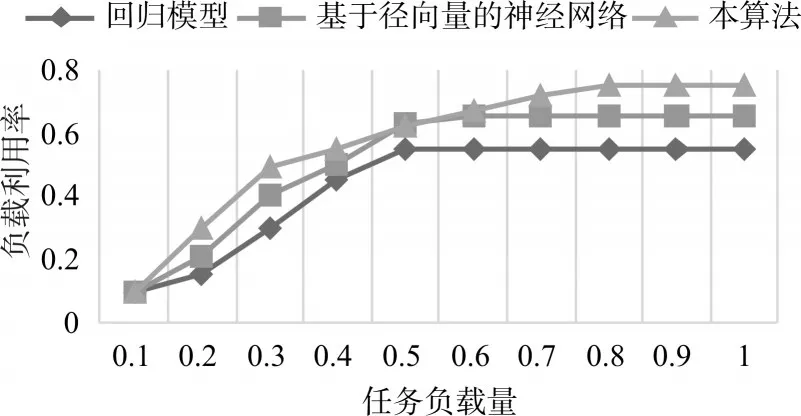
图2 算法负载利用率对比
通过实验结果的比较和分析可知,本文提出的基于强化学习的预测模型在预测的准确性和性能方面表现的更好,与真实值的拟合程度更高。与传统的自回归和神经网络算法相比,本文的算法在预测效果和预测精度方面都有所提高。
4 结语
针对难以实现任务Qos到虚拟网络资源的映射,本文提出了一种自动预测任务资源需求的算法。与目前大部分算法不同的是,我们通过反馈机制提供一个近似最小化的资源供给方案。尽管用户不知道要实现任务需要什么虚拟资源,但可以通过本算法的学习系统自动地精确预测任务需要的实际资源。仿真结果表明,我们算法有很高的预测精准度,提高了资源利用率,降低了服务成本的同时还实现了用户的任务需求。
