大数据处理技术在风电机组状态监测中的应用
2019-11-22李燕超杨改文
梁 涛,许 琰,李燕超,杨改文
(河北工业大学人工智能与数据科学学院,天津300131)
为保证风电机组状态监测大数据处理的实时性,本文将大数据处理技术引入数据处理过程,设计了风电机组状态监测模型。该模型依托于风电场SCADA系统,其采样频率为10 s,模型数据来源为SCADA系统关系型数据库和监测流数据,其数据采集方式为软件接口方式。本文采用大数据处理技术,设计了基于Storm实时流处理技术和Spark批处理技术的风电机组状态监测模型,阐述了该计算框架的整体架构以及内部逻辑,突出了其数据实时流处理和分布式计算两大优势[3]。
1 风电机组状态监测模型设计
基于大数据处理技术中的分布式存储和分布式运算,本文设计了基于实时流数据处理和内存批处理的风电机组状态监测模型。模型架构主要由数据来源层、数据传输层、数据存储层、编程模型层、数据分析层5个逻辑层组成。
各个逻辑层描述如下[4]:数据来源层,历史数据来源为SCADA系统的关系型数据库,实时数据来源为SCADA系统实时监测流数据;数据传输层通过数据交互组件完成数据存储层与数据来源层的数据交互;数据存储层的数据存储主要采用HBase,Hive等分布式数据库。编程模型层根据应用场景选择Spark或Storm完成对监测数据的处理;数据分析层在使用数据挖掘算法进行数据处理的过程中,提取风电机组的故障特征、更新特征曲线。
由于本文选取的聚类算法需要进行大规模数据的迭代运算,运算过程中会产生大量的中间数据。Spark基于内存计算[5],迭代产生的中间数据存储在内存当中,避免了中间数据在磁盘上多次的存取操作,能够较大地提升聚类算法的运行效率。Storm不同于Spark的是,Storm更适用于流数据处理,弥补了批处理不能满足的实时性要求。符合大型风电场集控中心对大量风电机组进行实时状态监测的需求[6]。
2 基于大数据技术的风电机组状态监测模型的实现

图2 状态监测模型流程
2.1 状态监测历史数据批处理
2.1.1基于RDD-K-means++聚类算法的设计
为了避免K-means算法初始聚类中心选取随机的缺点,本文采用K-means++算法对风功率曲线进行聚类分析,以得到风速功率曲线的实际参考曲线。借助于Spark平台对迭代算法的高效执行,基于RDD的K-means++算法主要过程是:
(1)读取存储在HDFS上的文件块(Block)到内存中,每个块转化为一个RDD,里面包含监测数据的特征量集合(Vector)。
(2)首先随机选取一个聚类中心c1,对RDD进行映射(Map)操作,计算每个Vector(Point)相对于已有聚类中心的距离(distance),并输出键值对(distance,(point,1)),生成新的RDD。
(3)在归约(Reduce)操作中,对新的RDD进行混合,以概率选择距离最大的样本作为新的聚类中心。
(4)重复映射和归约操作,直到选出k个聚类中心。
(5)RDD进行映射(Map)操作,计算每个Vector(Point)对应的聚类编号(Class),其对应键值对为(Class,(Point,1)),生成为新的RDD。
(6)接着在归约(Reduce)操作中,对每个新的RDD进行混合,相同聚类的数据存放在一起,计算每个聚类中心与属于该类样本之间的距离,并累加每个类的距离均值以得到总体距离Dis,将其作为K-means算法的代价函数。
(7)并在RDD内部计算每个聚类中心点。重新计算它的聚类中心,即属于该类的所有样本的质心。
(8)最后判断中心点与前一个中心点之间的距离,如果满足要求,则结束,否者从第五步开始,直到满足结束条件。最后将输出结果写到HDFS中。
2.1.2多元偏度、多元峰度
偏度(Skewness)、峰度(Kurtosis)是统计学中度量随机变量密度曲线的统计量,主要用来描述数据的分布状态。在本模型中,将功率特性的多元偏度和多元峰度应用到机组的性能状态评估中,根据其偏离参考曲线的程度来判别风电机组运行性能。
2.2 状态监测实时流数据处理
Storm作为一种流处理技术,其提交运行的程序称为拓扑(Topology)。拓扑结构由Spout和Bolt构成。风电机组状态监测模型拓扑结构如图1所示。
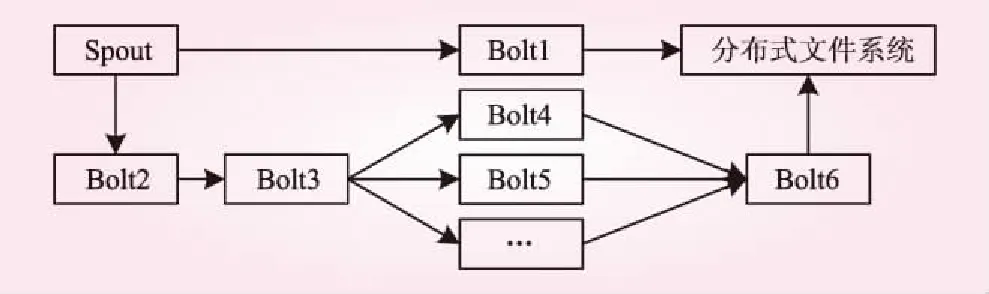
图1 Storm拓扑结构
Spout接收状态监测数据并形成元组,Bolt1接收数据并存储到分布式存储系统中,Bolt2对需要的监测数据进行筛选抽取,Bolt3计算风速功率曲线的峰度和偏度。Blot4与Bolt5计算风机实际功率曲线偏离参考曲线的程度。Bolt6根据偏离程度将风电机组分为正常、异常和故障三类并将结果存入分布式文件系统中。此拓扑结构提取监测流数据中的风速和功率,计算功率的特征参量多元峰度和多元偏度,根据其偏离参考曲线的程度,对风机状态进行评估。
3 模型技术路线
3.1 数据处理整体流程
本文选取风速、功率等数据对风机进行状态监测。选取多元峰度和多元偏度作为功率的特征参量。数据处理流程如图2所示。
历史数据批处理:
(1)通过风电场SCADA系统对各个风场风电机组数据进行采集,汇集到集控中心侧的SCADA关系数据库当中。
(2)使用Sqoop连接器将历史数据从SCADA关系数据库导入到Hadoop平台的分布式文件系统(HDFS)中,供Spark进行数据处理。
(3)在Spark平台上对HDFS中存放的历史数据进行聚类处理。通过计算各个类中数据点与聚类中心的马氏距离,根据其数值大小识别出异常数据点,并进行剔除,得到风电机组的风功率参考曲线。最后计算参考曲线的多元峰度和多元偏度值,作为实时状态监测的参考点。最后将计算结果存放到HDFS中。
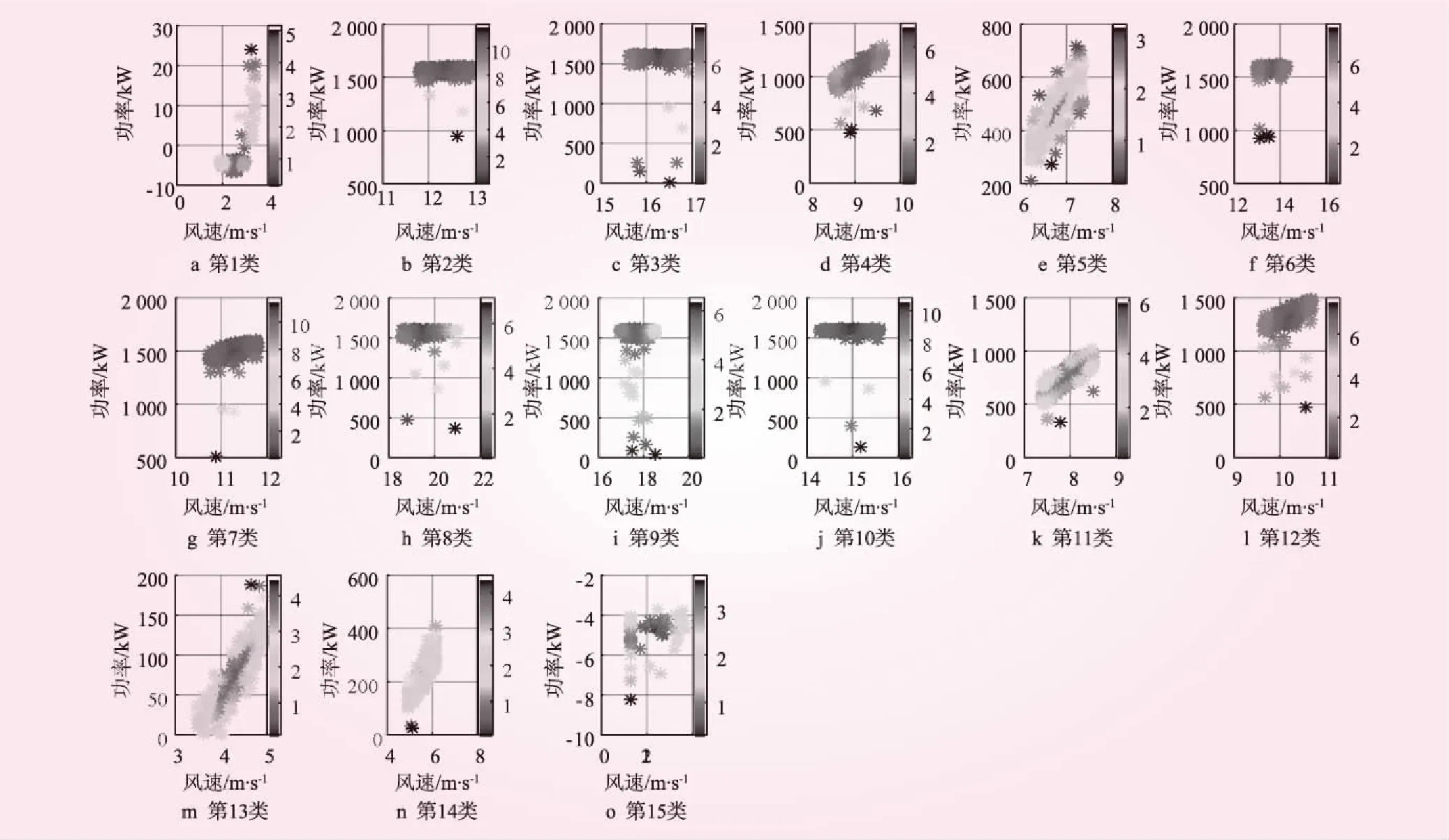
图3 功率曲线各类之间的马氏距离
实时状态监测的实现:
(1)配置kafka消息中间件来获取SCADA系统状态监测流数据,并将其作为Storm拓扑结构中Spout的数据来源。
(2)在Storm的拓扑结构中,对所需数据进行筛选、构建其实际功率曲线,并计算其多元峰度和多元偏度。将其与对应风机的峰度偏度参考点进行对比,根据其偏离程度,将风机状态分为正常、异常、故障。最后将计算结果存放到HDFS中。
(3)由Sqoop连接器将HDFS中的风机状态数据导出到SCADA系统关系数据库中,由SCADA系统读取相应的文件,根据其状态分类进行故障报警。
3.2 参考曲线的获取过程
功率曲线反映的是风电机组在不同风速条件下产生功率的大小,本文选取了某风电场1.6MW风力发电机组自2017年2月1日至2017年3月1日采集的风速(v)、有功功率(P)运行数据。
本文使用K-means++聚类算法对风功率曲线进行聚类,将功率特性曲线分为15类。为了构建风机的参考曲线,需要去除异常样本。在这里选用马氏距离(Mahalanobis Distance)进行计算,不受量纲的影响。马氏距离定义如下
(1)
式中,Dij表示第i个样本和聚类中心j之间的马氏距离;S表示样本的协方差矩阵。
分别计算样本数据点与该聚类中心之间的马氏距离,如图3所示描述了功率曲线各样本点与聚类中心的马氏距离,并用色图矩阵显示距离的大小,数值越大色图矩阵为红色,反之,数值越小色图矩阵则为蓝色。
根据图3剔除异常样本点,修正前后的P-v散点图对比如图4所示。其中,处理前如图4a所示,剔除异常点后的标准曲线如图4b所示。

图4 修正后的功率曲线
为了对大型风电场各个风电机组进行状态监测和状态评估,对风场中不同厂家不同型号的风电机组构建其参考风功率曲线,并计算其参考曲线相应的峰度和偏度值。
4 实验结果与分析
为检测状态监测模型的性能,在实验室中搭建了风电机组状态监测试验平台,实验环境由5台浪潮台式机组成,各个节点硬件配置:CPU型号Intel Core i5-3450,内存 8GB,网络带宽100 Mb/s。其中一个节点作为控制节点,其他四个节点作为工作节点。Hadoop使用的是2.7.3版本,Spark使用的是2.1.0版本,Scala使用的是2.11.8版本,Storm使用的是0.8.2版本,Zeromq使用的是2.1.7版本,Zookeeper使用的是3.4.5版本。
本次实验所用的数据为某风力发电场风机服务器中33台风力发电机的实时运行数据。为验证监测模型的有效性,在收集到的数据中选取了一定数量的故障风机的数据。实验结果如图5所示。
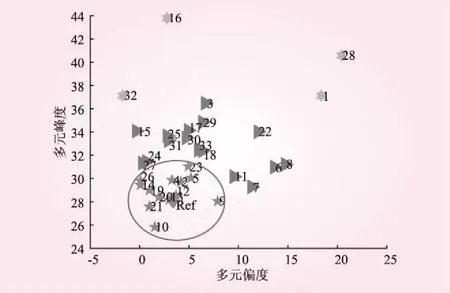
图5 风电机组运行状态
当风机出现异常状况时,实时功率曲线会偏离参考功率曲线,反映在峰度偏度上即为峰度偏度点偏离参考点,根据其偏离程度将风机状态分为正常、异常和故障。图5中,参考点附近的五角星参考点为正常状态,三角形参考点为异常状态、六角星为故障状态。通过本文的监测方法,可以清晰直观地对风机状态进行监测。
数据吞吐量反映了单位时间内成功处理数据的数量。通过不断增加数据量,对比数据集在Storm集群模式和单机模式下的运行时间,以此来验证Storm集群的吞吐能力。为提高实验结果的准确性,各个数据取10次实验的平均值,测试结果如图6所示。
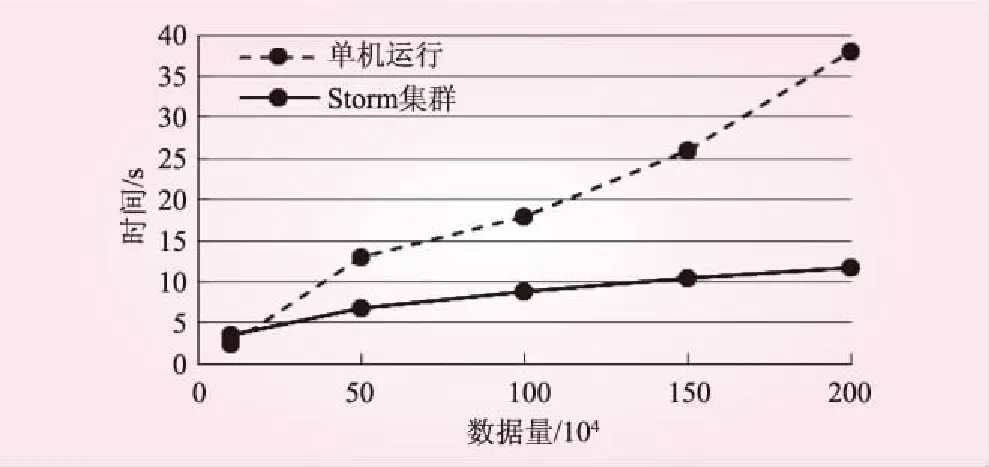
图6 单机运行与Storm集群运行时间对比
由图6可以看出,当数据量较小时,单机运行时间较短。这是由于Storm集群模式采用分布式计算,数据在各个节点之间传输需要一定的时间。随着数据量的增加,Storm集群处理数据所需的时间明显缩短,集群的优势逐渐显现。由于Storm集群有着其拓展性,可以满足大量实时流数据的处理需求。
随机选取某风力发电场GE1.6MW风机2015年1月1日00∶00∶00到2017年6月30日23∶50∶00中的3组数据(分别为1×106、2×106、3×106条记录数)。改变spark集群中节点内存大小,测试在不同数据量,工作节点分配不同内存的情况下集群处理数据所用的时间,进行5次实验,记录时间取平均值,结果统计如表1。
从表1可以看出。当数据量较小时,内存大小对数据处理时间影响较小。随着数据量的增大,分配有较大内存的集群在处理时间上有着较为明显的减少。因此当数据量较大时,可以通过适当增大spark工作节点的内存来提高数据处理效率。
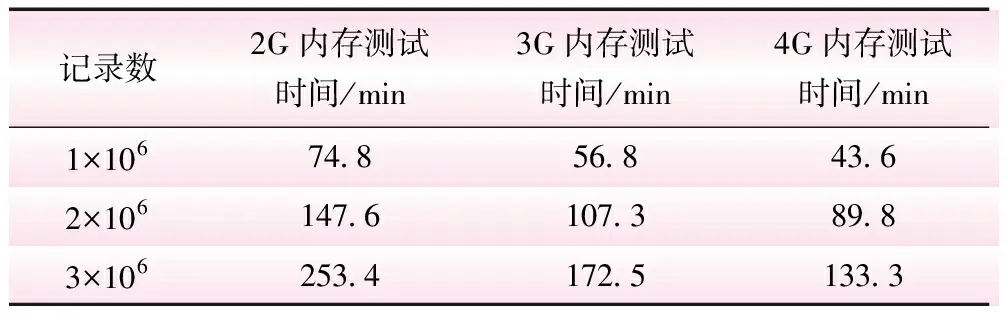
表1 测试时间对比
5 结 语
针对海量风电机组状态监测数据实时处理的需求,引入Spark和Storm,设计了风电机组状态监测模型。基于Spark框架实现了K-means++聚类算法,提高数据处理效率。设计了Storm拓扑结构,保证了状态监测的实时性。实验结果表明,本文提出的模型有着较好的吞吐量和加速比,并且在数据处理的实时性方面有着很大的提升,弥补了单机性能不足的缺陷。
