供水管网异构数据集成共享关键技术研究
2019-11-22范冬林康传利付波霖高二涛徐雯婷蓝贵文
范冬林,康传利,付波霖,高二涛 ,徐雯婷,蓝贵文
(1.桂林理工大学测绘地理信息学院,广西桂林541004;2.广西空间信息与测绘重点实验室,广西桂林541004;3.东华理工大学测绘工程学院,江西南昌330013)
0 引 言
在信息化、智慧化浪潮的推动下,智慧城市已成为我国城市化发展的新趋势[1]。供水管网作为城市信息基础设施的重要组成部分,是智慧城市建设的重要数据源之一。智慧城市的发展与数字城市的建设一脉相承[2],在数字城市建设进程中,供水管网信息化系统作为GIS平台的一个行业应用,通常仅以现有的数据模型来解决城市管网的特殊应用,未能深入考虑管网运行的行业特性[3],主要表现在:①管网信息资源缺乏语义信息,不能满足智慧城市对重要资源的整合、共享、集成的要求;②供水管网数据多样化,系统建设层次不一。由于管网管理者需求的不同以及系统建设者对城市管网认识的差异,使得现有系统的应用层次各不相同,进而导致了供水管网数据格式多样化且语义一致性差[4]。此类供水信息系统对外提供的WEB服务资源(即共享信息)缺乏统一的语义描述,难以形成具有统一语义与知识表达的信息共享。
为解决上述问题,必须对现行的异构数据进行集成,形成一致的数据语义描述,构建集成数据模型[5]。对GIS空间数据而言,数据集成是消除源数据在数据模式、数据属性和数据结构上的差异和冲突,按照目标数据进行一致化处理,最后为用户提供统一的表现形式[6]。本文从数据集成的层面,实现供水管网异构数据集成研究,为城市其他行业管网数据集成提供参考。
1 供水管网数据异构性分析
对供水管网本身数据而言,不仅存在数据格式的不同,如常见的数据格式有ArcGIS的SHP格式、AutoCAD的DWG格式、MapGIS的W*格式等。而且,即使是同一格式的管网数据,对管网领域概念理解的不同,也会存在对相同实体的数据存储描述的差异,如数据结构冲突、字段命名冲突以及实例的度量单位冲突等。
从数据的语义层面看,供水管网数据异构包括2种类型[7]:实例异构和模式异构。实例异构是指不同的数据源对同一个实体具有不同的描述,对相同的地理实体的描述使用同义字或同形异义字。如系统A中材质为“普通铸铁管”,而系统B中表示为“灰口铸铁管”,由于其表现形式不同,通过精确匹配方式则无法将2个数据描述一一对应起来。模式异构是指不同数据源数据含义相似或有差别,包含2方面异构:一方面是指2个局部模式的属性具有相同的含义,但属性名却不相同,这种异构亦称为命名异构,如在模式A中“材质”字段名和模式B中“管材”指的是同一个概念;另一方面则指不同的数据源对相同实体的属性采取不同的定义方法,这种异构也称为结构异构,如模式A对“地址”的表示在一个属性字段中完成,而在模式B中“地址”由“省”、“市”、“街道”3个属性字段描述。
2 供水管网异构数据集成技术
2.1 集成数据模型
本体技术能够解决数据集成中语义异构问题,最根本的原因在于其定义的共享概念模型使用户和应用程序对概念和术语具有共同的理解[8]。因此,对供水管网领域中核心概念的抽象显得尤为重要。在传统的本体集成技术研究中,核心概念仅仅是对领域内实体和关系的表达[9],而在本文中,核心概念不仅包含供水管网中的实体类型与关系,同时包含实体内属性集合的抽象。为了构建供水管网集成数据模型,本文将属性集合的概念抽象为特性,其逻辑上是对供水管网概念的形式化表述,而物理上则是一组属性的集合。本文将特性分为3类:存储特性、普通特性和标识特性。
(1)存储特性。用于管理数据类型的存储方式,主要功能包括基于类型的数据创建、数据选择、数据读取和修改等。
(2)普通特性。包含一定数量的固有属性字段,并在该固有属性字段的基础上定义了基于特性的基础应用操作,如管材特性中的获取管材信息,规格特性中的获取设备规格信息以及进行设备规格检查等。
(3)标识特性。用于对管线设备标识,这类特性不需要匹配固有的属性字段信息,如针对供水的阀门设备以及燃气的调压站设备都具有的关断特性,当给某一数据类型赋予了关断特性时,说明该数据所存储的设备具有阻断网络流通功能的特性。
按照地下管线探测规程和集成数据模型的需求,建立供水设备类型,并进一步确定每种设备类型的属性。对于集成数据模型而言,类型的属性结构不仅需要考虑异构数据中的相同概念,还需考虑数据源中的特殊属性,以便更大程度兼容异构数据源。上文提到的特性能够很好地解决这一问题。类型通过特性间接决定其属性结构,不直接持有属性,属性的管理由特性完成。
阀门类型-特性-属性关系见图1。阀门类型被指定为点设施存储特性,该阀门类型还具有关断特性和关阀影响2个标识特性。同时,普通特性记录了该类型公共数据属性字段集合。数据类型还可以派生子数据类型,子数据类型继承了父类型的所有特性。派生的子类型只能添加普通特性和标识特性,不能更改存储特性。按照上述原则,本文设计了供水设备集成数据模型,该模型将作为目标本体参与异构源数据的集成。
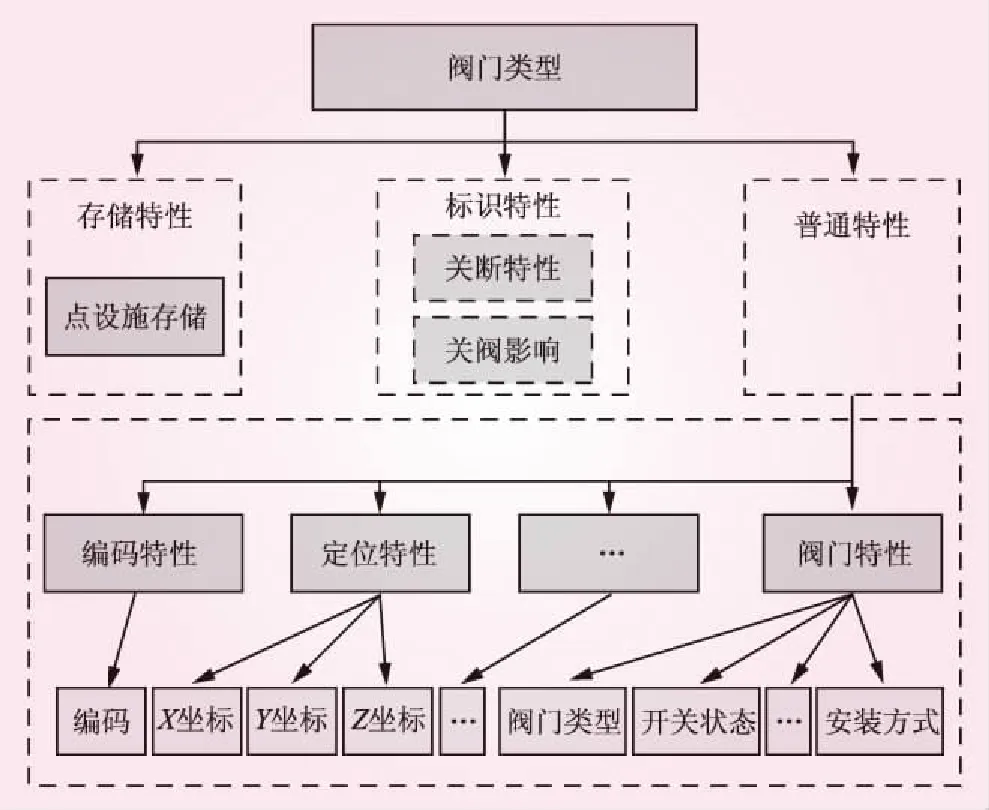
图1 类型-特性-属性关系示意
2.2 数据集成中映射关系的建立
建立映射关系是为了将供水管网集成数据模型与不同的源数据进行关联,消除集成数据模型与源数据的模式和实例异构[10],其关键是概念之间相似度的计算。在研究相似度计算方法的文献[11-13]中,按照不同的标准,将相似度计算方法分为模式级、实例级、元素级和结构级。本文主要考虑模式级和实例级的相似度计算算法,前者指利用本体中的模式信息来计算相似度,该计算方式主要是计算词法层面的语义相似度[14];后者指利用一定量实例来进行相似度的计算,该计算方式主要以数学联合分布概率为基础进行相似度计算。每一种相似度在一定程度上反应了本体概念间的关系,对映射关系的建立都有不同程度的影响,单独使用一种相似度在一些场景亦能取得较为满意的效果。如在文献[15]中提供的数据中,使用基于实例的相似度计算方法可以取得较理想的匹配结果,但当遇到语义上一致,但词义不同的实例便难以胜任。基于上述原因,并结合供水管网中异构数据的特性,本文将应用结合词义、语义和实例的相似度算法进行加权计算的综合相似度计算方法。
假设simw(A,B)、sime(A,B)、simc(A,B)分别表示本体O1中A概念与本体O2中B概念的词义相似度、语义相似度和实例相似度,则综合相似度的计算方法表示为
sim(A,B)=α×simw(A,B)+β×sime(A,B)+
λ×simc(A,B)
(1)
α+β+λ=1.0
(2)
min{simw(A,B),sime(A,B),
simc(A,B)}≤sim(A,B)≤max{simw(A,B),
sime(A,B),simc(A,B)}
(3)
式中,α、β、λ为权重值,依赖于经验值,在实际应用中,α、β、λ的值通过训练确定。在本体与源数据中选取1组训练样本,计算得到的相似分量,变换α、β、λ的取值,得到更多的试验值,从结果中选取映射准确率高的作为经验值。
本文从供水管网数据中选取了1组数据进行综合相似度的计算,计算结果见表1。其中,α、β、λ的值分别取0.3、0.5、0.2。
通过综合相似度计算得到的相似度矩阵,本体中一个概念可能具有多个相似度差别不大的另一本体的概念组,如“高程”对应的“管顶高程”和“管底高程”相似度的值都大于0.7。因此,需要确定选择具体哪个概念与之对应,从而建立本体概念间的映射关系。设定阈值T可以有效减少关联概念的数量,当2个概念的相似度小于T时,便认为概念无相关性;当相似度大于T时,则将被匹配概念作为1个候选概念。如在表1中,当T取0.7时,数据源本体管顶标高、管底标高对应集成本体的候选概念皆为管底高程和管顶高程。
本文选取了106个目标概念和122个源概念,对两者分别使用词义、语义、实例和综合相似度计算方法进行匹配处理,并使用查准率(Precision)、查全率(Recall)和F1-Measure作为评判匹配结果的有效性指标,评判指标见表2。从表2可知,由于实例相似度算法仅就数值型的概念进行匹配处理,故其计算结果相对其他算法准确率稍低;而综合相似度计算方法反应了概念的多个方面的信息,其准确率明显高于其他相似度算法。
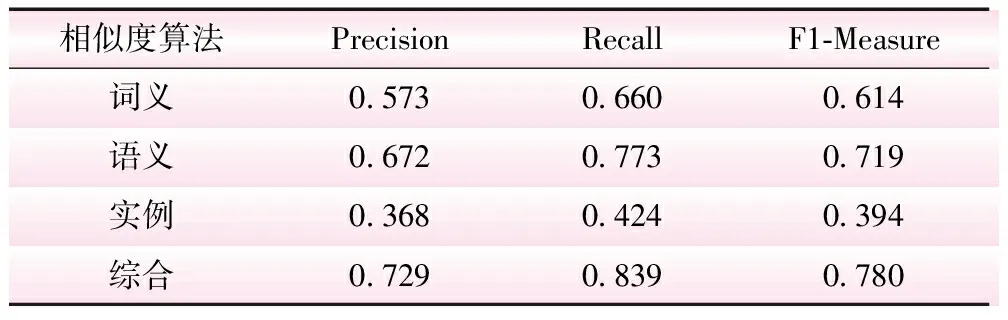
表2 相似度计算算法结果评价
本文中,映射关系的建立包含模式和数值映射关系2个方面。前者指建立集成数据模型和异构源关于类型和属性字段之间的映射关系,后者指建立集成数据模型和异构源属性数值的映射关系。
模式映射可将非标准化的数据转换为标准化的数据,实现模式映射需要经过3个步骤:类型匹配→属性字段匹配→数值匹配。类型匹配通过字符相似度计算可以确定初步的映射关系;属性字段匹配通过综合相似度计算也可确定初步的映射关系,在初步映射关系的基础上,通过人工干预确定最终的映射关系。在计算相似度之前,需经过预定义字典过滤,将在预定义字典中有明确对应关系的概念剔除,以减少计算量。模式映射过程如图2所示。
完成模式映射关系后,还需进一步对数据值进行匹配。本文仅就文本和数值类型的属性值进行考虑。数值匹配处理流程见图3。对属性值进行匹配的原因是存在实例异构,在创建集成本体时,对字段进行过值域约束(范围约束、选项约束)或进行了统一度量单位的约束等。文本类型的数据值可能存在n∶1、1∶1的映射关系以及数值书写格式的统一,这部分的映射关系生成同样需要进行相似度的计算。

图2 模式映射处理流程
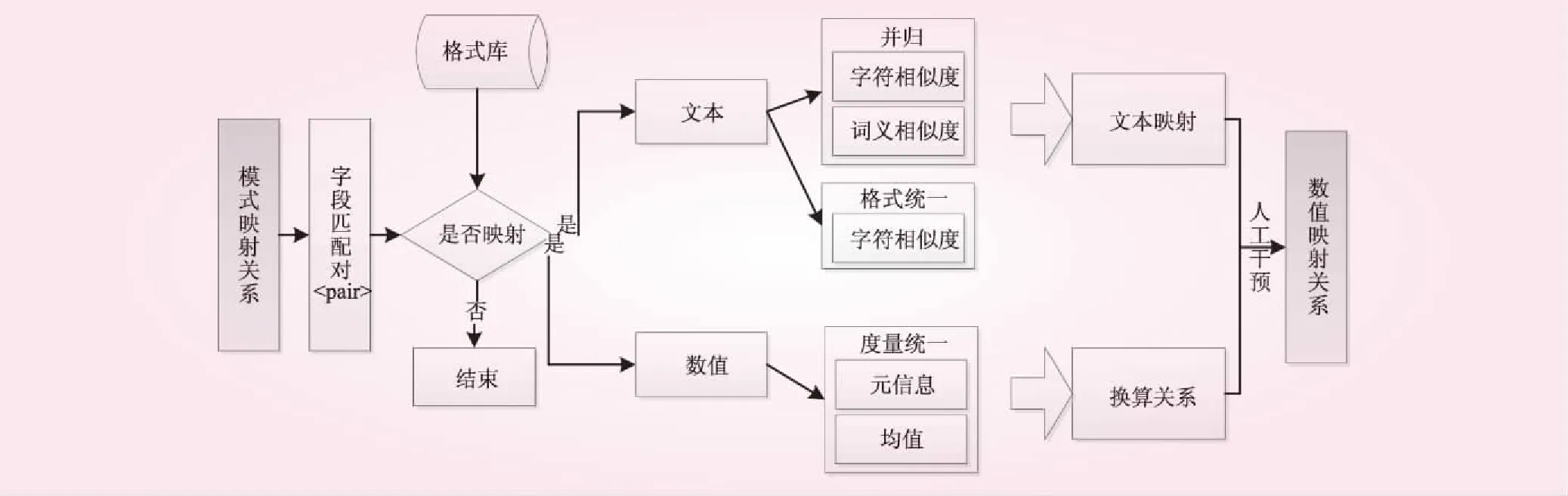
图3 数值匹配处理流程

图4 集成管网数据模板
数值型的数据值仅考虑度量单位的统一,这部分主要通过元信息、均值来判别换算关系。
3 异构数据集成共享平台应用
供水管网异构数据集成与共享平台是在供水集成数据模型和综合相似度计算方法的支撑下,基于MapGIS SDK二次开发的供水管网数据异构的集成共享平台。该平台以特性为基本处理单元而开发的特性工具集合,为上层应用提供了一套完整的数据操作接口。特性工具降低了数据与功能的耦合性,提高了基于集成数据模型开发的供水地理信息系统在异构数据下的复用性和系统的扩展性。平台还提供了数据的统一发布,基于GML格式的数据,可以实现不同系统或平台间的数据共享。由于数据是已经进行过集成化处理的,因此使这类数据的共享是具有相同语义和知识的共享。集成管网数据模板见图4。管网拓扑的统一语义表达见图5。

图5 管网拓扑的统一语义表达
4 结 语
本文针对不同供水管网存在异构性和共享信息语义不一致问题,对其中的关键技术进行了探讨,构建了一个供水管网异构数据集成共享平台应用实例,并使用该平台先后对常州、桂林2个城市的供水管网数据进行异构集成,达到了预期效果。
异构数据集成共享平台在一定程度上解决了供水管网数据语义一致的集成共享,特性的引入也可在一定程度上降低供水应用系统的开发周期,提高应用功能的复用性,可供城市其他管网行业数据集成和共享提供参考。
