基于主题模型和关联规则的专利文本数据挖掘研究
2019-11-22艾楚涵吴建德
艾楚涵,姜 迪,吴建德
(1. 昆明理工大学 知识产权发展研究院,云南 昆明 650500; 2. 昆明理工大学 计算中心,云南 昆明 650500;3. 昆明理工大学 民航与航空学院,云南 昆明 650500)
0 引 言
近年来,我国的专利数量不断增加,截至2018年年底,不计港澳台发明专利数量,我国发明专利拥有量共计160.2万件,每万人口发明专利拥有量达到11.5件,专利文本呈现海量的特征. 为了深度挖掘专利文本中隐含的关联信息,数据挖掘(Data Mining)技术慢慢地被引入到了专利文献中来. 如何通过挖掘海量的数据来获得相关联的专利主题特征,并将挖掘出的关联关系应用到实际中成为了当前研究者要深入研究的课题,而关联规则的兴起,让数据挖掘技术能够真正对数据库中不同数据项之间的关联关系进行有效的利用[1].
目前,我国对于专利的关联规则挖掘应用研究还处于起步阶段,可参考的文献数量很少. 周磊等从专利IPC的规模和前向引用的规模入手,构建了加权的关联规则来挖掘技术的融合规律,能够通过加权的关联规则很好地区分不同技术之间的差别[2]. 陈亮等使用频繁项集之间的关联规则建立起术语层次网络,并创建技术路线图,该方法能够描绘出更贴近真实情况的技术路线图[3]. 许海云等提出了一种基于专利功效矩阵的技术主题关联方法,通过使用关联规则获取领域内技术主题与达成功效主题的关联度,来获取低支持度、 高置信度的关联规则,弥补了低共现-弱关系技术主题的遗漏[4].
主题模型(Topic Model)是一种多项式分布的概率生成模型,是可以通过非监督学习的方式对目标文本集的隐含语义结构进行聚类的一种统计模型,运用主题模型进行挖掘是目前常见的研究手段之一. 在对专利文本进行自动化的聚类处理上,目前大多数针对专利文本内容的研究都是使用由Blei等提出的LDA主题模型来完成对专利的聚类[5]. 范宇等从聚类的效率出发,将LDA主题模型和OPTICS、 K-Means算法相结合,大幅降低了专利信息的维度,并提高了专利聚类的准确率[6]. 孙伟等从词汇的共现关系出发,提出一种基于词加权的有监督的LDA主题模型用于专利的聚类[7],在聚类时能分离出专业词汇和一些普通高频词汇,使主题关联度更高. 王博等在原LDA模型的基础上扩展构建了机构-主题的模型,得到了申请机构和专利主题之间的关系,深度挖掘了专利主体和客体之间的关联性[8].
综合以上关于专利文本数据挖掘的研究,发现大多数现有研究都没有考虑具有相同行业背景和专业术语的同一产业的专利文本中,其主题之间所具有的关联性,没有将关联规则和聚类的结果有效地结合起来,并且在对专利文本进行降维时,没有考虑到“文档-主题”维度对专利信息挖掘的重要性,直接将专利文档以“主题-主题词”的形式表示,从而遗漏了很多隐含的信息. 基于此,本文结合关联规则和主题模型,提出一种基于Apriori和LDA主题模型的专利文本分析方法,对专利文本进行降维,分别从“文档-主题”,“主题-主题词”的维度来对物流产业的专利文本进行深度挖掘,探索各专利文本间隐含的关联规则,以及当前行业内的热点研究领域等潜在的信息. 实验结果表明,该方法能够挖掘出专利文本中的隐含的关联规则和主题细分,实验的方法和结果也能为后续研究提供理论和数据上的支撑.
1 研究思路和方法
1.1 研究思路
本文所使用的研究数据来自于Incopat专利数据库,首先以中国物流产业为研究对象,在专利数据库中检索出相关的专利文本信息,主要是专利的摘要信息. 然后使用Python脚本对数据进行文本分词、 停用词过滤等预处理. 接着,通过Apriori算法设置最小支持度阈值和最小贡献度阈值来找到所有符合要求的强关联规则,并在“文档-主题”的维度下构建物流产业下的共享主题网络. 通过LDA主题模型挖掘专利的主题词信息,在“主题-主题词”的维度下发现当前物流产业专利申请的热门领域. 最后根据共享主题网络并结合专利主题词进行关联规则分析,挖掘出专利之间隐含的关联,同时对未来关联规则在专利文本中的应用给出建议. 具体研究流程如图 1 所示.
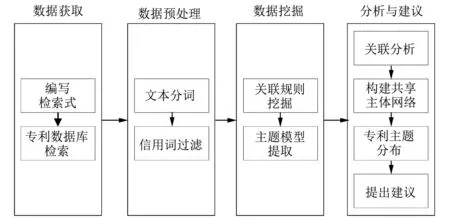
图 1 研究流程图Fig.1 Research flow chart
1.2 数据的预处理
为了保证实验数据的有效性和排除一些无效高频词的干扰,需要对数据进行预处理,预处理分为文本分词和停用词过滤两个步骤[9].
1) 由于中文文本不像英文那样是由空格来将每一个单词分隔开,为了对文本进行挖掘,就必须将其分成粒度更细的词或词组的形式. 关于如何将中文进行分词,现有的技术已经非常成熟,本文使用基于Python第三方库的“jieba”的精确模式来实现中文分词,精确模式可以将句子最精确地切开,是文本分析最适合的模式.
2) 将连接词和高频无意义词整合成停用词表,并在分词后遍历停用词表,将这类词语剔除. 本文实验所使用的停用词表综合了哈工大、 四川大学机器智能实验室和百度的停用词表,并且将专利文本和物流产业常出现的无意义高频词和高频术语等加入到停用词表中,如“专利” “实用新型” “一种” “几种”等词语,以期使分词的结果更加“干净”.
1.3 关联规则和Apriori算法
所谓关联规则,就是在大量数据中挖掘出一个事物与其他事物之间的相互依赖性和关联性,反映出有价值的数据项之间的相关关系,它是数据挖掘中的一个重要技术[10]. 其中,“超市销售分析”作为经典运用已经成为了关联规则挖掘的入门级案例,将关联规则应用到专利文本中时,可以参考该经典案例,将一条专利看作是一个“购物篮”,专利的各主题词看作是购物篮中的“商品”,对整个“交易数据库”进行关联规则挖掘,就可以得到频繁出现的专利主题词. 设D为整个专利数据库事务的集合,I={I1,I2,…,IM}是M条不同专利的集合,将每个IK都视为一个项目,事务T是不同项的集合,使得T⊆I. 对于项集X和项集Y在X⊂I,Y⊂I,X∩Y=ø的条件下有X⟹Y,这就是一条关联规则,表示项集X在某专利中出现时,会导致Y也以某一概率出现在该专利中[11].
通常用支持度(Support)、 置信度(Confidence)和提升度(Lift)来度量关联规则的强度. 对于上述案例,关联规则的支持度表示为交易集合同时包含X和Y的专利数与所有专利事务|D|的比值,即

(1)
支持度是X和Y同时出现的概率,而置信度则表示为同时包含X和Y的专利数与只包含X的专利数之比,即
Confidence(X⟹Y)=P(X|Y)=

(2)
置信度反映了假如某专利中包含X,则也包含Y的概率. 而提升度表示专利在含有Y的情况下同时含有X的概率,与Y总体发生的概率之比,即
(3)
通常把支持度和置信度都高于阈值的关联规则认为是强关联规则,而把提升度当作一种评价指标来看待,一般情况下,提升度>1的关联规则认为是有效的强关联规则,反之,则认为是无效的强关联规则.
Apriori算法是关联规则挖掘中最常用的一个算法,Apriori规定:如果一个项集是频繁项集,那么它的所有非空子集都是频繁项集[12]. 也就是说,如果一个项集不是频繁项集,那么它的所有超集(父集)都不是频繁项集[13]. Apriori采用迭代的方法来找出频繁项集:第一步,将每个项都视为候选1项集C1,对数据库进行扫描,搜索出所有候选1项集及其对应的支持度,而后剪枝掉小于指定支持度的候选1项集,得到频繁1项集L1. 第二步,连接剩余的频繁1项集,则得到候选2项集C2,筛选去掉低于支持度的候选2项集,得到频繁2项集L2. 依此类推,一直进行迭代,直到无法搜索出频繁K+1项为止,那么就得到了频繁K项集LK,也就是算法的输出结果. 通过Apriori算法发现频繁项集的过程如图 2 所示.

图 2 Apriori中频繁项集的发现过程Fig.2 Discovery process of frequent item sets in Apriori
图 2 中,C1,C2,…,CK分别表示候选1项集,候选2项集,…,候选K项集.L1,L2,…,LK分别表示频繁1项集,频繁2项集,…,频繁K项集. Scan表示扫描数据集的函数,起到过滤作用,只有满足最小支持度的项集才被保留,不满足的直接将其舍掉.
1.4 LDA主题模型
LDA(Latent Dirichlet Allocation)是一种无监督的,可抽取文本特征的概率增长模型. LDA不需要事先对模型进行训练,可以通过无监督的学习方法来挖掘出文本中隐含的语义信息,将其应用到专利文本中时,不需要手动对文档添加标签,只需要给出期望生成的主题数K和主题中的TopN关键词N即可[14]. LDA是一种“主题-文档-词汇”的三层贝叶斯模型,把主题视为词汇出现的概率分布,而文档认为是主题出现的概率分布,而构成主题的每一个词汇又都是无序的,那么就降低了文档的维度,大大简化了问题的复杂度[15]. LDA主题模型如图 3 所示,模型的符号解释如表 1 所示.

图 3 LDA主题模型Fig.3 LDA theme model

符号含义K主题个数M文档个数N文档中词汇的总数α每个主题的先验概率β每个词汇的先验概率θm第m个文档的主题的分布概率Zm,n第m个文档的第n个词的主题Wm,n第m个文档中的第n个词Φzm,n第z个主题的词语分布概率
在LDA中,一篇文档的生成要经过以下几个步骤:
1) 从先验狄利克雷分布α中取样生成文档m的主题分布θm.
2) 从主题的多项式分布θm中取样生成文档m第n个词的主题Zm,n.
3) 从词汇的狄利克雷分布β中取样生成主题Zm,n的词语分布Φzm,n.
4) 从词语的多项式分布Φzm,n中采样最终生成词语Wm,n.
2 实验及分析结果
2.1 专利文本的预处理
根据检索式TI=(物流 or 运输 or 仓储 or 库存 or 装卸 or 搬运or流通加工or配送or信息平台or邮政 or 分拣 or 装配 or 保管 or 铁路or公路or水运or航空or管道 or 货运 or 装运 or 空运 or 陆运 or 快递站 or 菜鸟驿站 or 快递 or 菜鸟乡村 or 储存 or 中转 or 货场 or 集装 or 货垛 or 堆码 or 储备 or 散装 or 换装 or 拣选 or 集货 or 冷链 or 承运 or 拆箱 or 拣货 or 直送 or 条板式输送机 or 条板式输送带 or 盘式输送机 or 盘式输送带 or 直送 or 转盘 or 运送 or 货代 or 卸货 or 装货 or 包裹 or 流通加工 or 邮电)and IPC=(B65 or B23P or G06Q or B60P or B25B or B62B or B32B or E04B )在Incopat专利数据库中随机选择发明申请、 发明授权、 实用新型专利各1 000条,将数据保存在专利数据.xls文件下. 采用Python第三方库jieba分词组件进行分词,使用2.2节整理好的文本作为停用词表stopword.txt. 对数据进行预处理后的专利文本示例见表 2.

表 2 预处理后的专利文本数据示例
2.2 专利文本关联规则挖掘
本文专利文本关联规则挖掘的实验在R语言环境下进行,将每篇专利作为一项事务tk,其中tk={w1,w2,…,wi},wi是专利中第i个主题的词项,对应关联规则中的一个项目. 在R语言中安装并加载arules和Matrix包,加载实验数据时将数据格式format设置为“basket”,将每一条专利记录看作是一个购物篮,专利主题词就是购物篮里的商品. 使用apriori()函数进行关联规则挖掘,最小支持度阈值和最小置信度阈值分别为0.006和0.05,将最小规则长度minlen设置为2,避免规则中空项的出现. 共生成规则552条,其中置信度、 支持度和提升度最高的5条规则如表 3~表 5 所示. 在表中,lhs是英文left hand side的缩写,表示规则的前项,rhs是right hand side的缩写,表示规则的后项. 通过对表3和表4进行分析,可以挖掘出以下规则:
1) 有2.9%的专利中同时包含了“保鲜” “存储”和“设备”这三个主题词; 如果一篇专利以“保鲜”和“存储”为主题词,那么该发明人有90%的可能性会对以“设备”为主题的专利感兴趣.
2) 有0.9%的专利中同时包含了“订单” “物流”和“信息”三个主题词; 当一篇专利中同时包含“订单”,“物流”两个主题词时,则该发明人有71.05% 的几率会对物流信息化为主题的专利感兴趣.
3) 有1.4%的专利中同时出现了“减震”和“运输”两个主题词,可以推断,当一篇专利中包含有“减震”这个主题词时,那么该专利有53.84%的可能性是“运输”主题的专利. 依此类推,还可以得到其他相关规则.

表 3 置信度最高的5条规则

表 4 支持度最高的5条规则

表 5 提升度最高的5条规则
通过表 5 可以看出,“节能”⟹“环保”这一条规则的置信度大于56%,提升度更是远大于1,说明该条规则具有很强的关联性,以“节能”为主题词的专利在很大程度上都是与“环保”这一主题相关联,事实上,在Incopat专利数据库中限定“物流”和“节能”两个关键词检索出的专利与“环保”主题有很强的关联性,证实了这一结论.
对所有专利数据进行关联规则挖掘后,规则总体关于置信度、 提升度和支持度的散点图如图 4 所示.

图 4 支持度-置信度散点图Fig.4 Support-confidence scatter plot
图 4 中散点颜色的深浅程度代表着其提升度的大小. 由图可知,大部分规则支持度都分布在0.01以内,置信度都在0.2~0.6之间,提升度都在10左右,说明通过Apriori算法挖掘出来的强关联规则都是有意义的,有一定的参考价值. 根据提升度的大小选取了100条提升度较大的规则生成共享主题网络图,生成的共享主题网络图如图 5 所示.

图 5 共享主题网络图Fig.5 Patent network diagram
图 5 中,源头表示规则的左项,箭头指向的主题词表示规则的右项,圆圈的大小则代表该条规则置信度的大小,圆圈越大则置信度越大; 圆圈颜色的深度表示提升度的高低,圆圈颜色越深则该规则提升度越高. 基于此,可以从图中直观地看到,“环保”和“节能”这条规则的颜色最深,提升度最大. 而剩余的规则被分成了包括关于“物流运输”和“信息控制”的两大主题集,其中“物流运输”方面的主题集置信度都较大,说明以“运输”为主题的专利和以“运输系统” “碰撞” “保鲜” “减震”等为主题的专利有很强的关联性,也可以看出,在“物流运输”的过程中,发明人比较关心运输的安全问题. 而在“信息控制”的主题集下,规则较多,主题为“数据”或“系统”的专利与主题为“服务” “监控” “识别” “管理”等主题的专利关联性较强,说明物流过程的信息化是当前物流产业内研究的热点领域.
2.3 专利文本主题模型挖掘
对预处理后的专利数据在Python环境下使用LDA主题模型进行主题词抽取,在重复实验多次后,发现在将主题数K设置为5,α和β的值分别设置为0.1和0.01,迭代500次后输出的主题分布区分度较高,聚类明显. 使用上述参数对主题模型进行提取,在每个主题中选取出现概率最大的前5个主题词,其主题-主题词分布如表 6 所示.

表 6 物流产业专利的主题-主题词分布
通过表 6 主题词分布结果可以看出,Topic 0是物流产业中的“搬运装卸”环节的内容,Topic 1是“仓储保管”环节的内容,Topic 2是“配送”环节的内容,Topic 3是“包装”环节的内容,Topic 4是“运输”环节的内容. 当前物流产业的热点研究领域集中在“运输”环节上,其专利申请的数量占了整个产业的29.4%,说明发明人对“运输”环节的专利最感兴趣.
结合2.2节的研究进行分析,根据置信度的定义,通过关联规则挖掘出的一篇专利以“箱” “箱盖” “箱体”作为主题词时,该专利的发明人会有75%的可能性会对以“仓储”为主题的专利感兴趣,而通过表6可知,通过主题模型挖掘出“仓储”在物流产业中属于“仓储保管”的环节,所以该发明人也有可能会对“仓储保管”环节下的专利感兴趣. 在接下来将主题模型和关联规则应用在专利文本的研究中,可以将某一类别中主题词出现概率较大的主题的专利推荐给与其关联度较高的主题下的专利发明人,例如,可以根据本文的实验结果,将整个“仓储保管”环节中以排名Top-5主题词,如“保存” “仓储” “储存” “缓冲”和“收集”作为主题的专利推荐给以“箱” “箱盖” “箱体”为主题词的专利的发明人,实现对发明人的专利推荐.
3 结 论
本文研究将关联规则挖掘和LDA主题模型应用在专利文本上,用于挖掘大量文本中隐含的主题关联. 通过设计实验,将专利文本进行离散化处理,使用Apriori算法对数据进行降维,将专利在“文档-主题”维度上进行描述,深度挖掘出专利文本中的强关联规则,所选取的关联规则的提升度都高于2.9,并通过散点图和网络图直观地表示了各规则间的联系,接着将LDA主题模型引入到了专利文本的分类中,将专利在“主题-主题词”维度上进行描述,挖掘出了整个物流领域专利各大环节中出现频次最高的主题词,对领域内的主题实现了细分,不仅挖掘出了当前物流产业内专利申请的热点领域,还将主题模型和关联规则进行结合来对专利文本进一步挖掘,并对未来的工作给出建议. 所使用的方法和挖掘得出的结论都对未来专利数据库基于主题模型和关联规则的个性化推荐功能的研究有积极的意义.
当然,本文只是针对物流领域的专利文本进行了研究,且在数据预处理时也针对物流领域进行了优化,并未使用其他领域的数据. 所以在接下来的研究中,需要在更大数据量的基础上,对不同产业领域内的专利文本使用此方法,进一步对这种基于主题模型和关联规则的专利文本挖掘方法进行提高和改进,取得更精确、 更贴近产业现状的效果.
