面向蜂窝物联网的RB动态预分配调度方案*
2019-11-22金叶奇
金叶奇,郑 敏,谭 冲,刘 洪
(1 中国科学院上海微系统与信息技术研究所, 上海 200050; 2 中国科学院大学, 北京 100049)(2018年5月24日收稿; 2018年7月16日收修改稿)
得益于低功率广域(low power wide area, LPWA)物联网的发展,预计2020年机器类型通信设备(machine type communication device, MTCD)数将达32亿[1]。部署于蜂窝网络的物联网如基于LTE的窄带物联网(narrow band internet of things, NB-IoT)以其广覆盖、大连接优点得到3GPP青睐[2],NB-IoT标准考虑机器到机器(machine to machine, M2M)业务特性降低了峰值速率并简化了空口信令[3],但授权频谱对于大规模MTCD上行业务仍为有限,尤其表现在上行业务信道(physical uplink shared channel, PUSCH)和下行控制信道(physical downlink control channel, PDCCH)。
为更好地分配PUSCH资源,制定相应策略来满足M2M业务对时延、功耗、服务质量(quality of service, QoS)等方面需求的调度已被广泛研究[4-6],此类动态调度方案优异的性能指标建立于频繁的信令交互上,其性能分析较少提到信令开销。
控制信道不足同样制约系统容量的提升,而此方面研究相对较少。PDCCH用于调度大量小数据包(可由1或2个RB容纳)是极大的浪费,这使得控制信道即使饱和业务信道利用率仍很低。文献[7]考虑控制信道有限提出并求解最大化准入MTCD 非线性规划问题;文献[8]则采用动态信道间资源分配缓解大规模MTCD引起的信令风暴;文献[9]指出降低信令开销最具吸引力的方案是数据聚合,但不同场景下方案可行性会发生改变;文献[10]提出一种基于集群的介入管理方案,MTCD集群根据其QoS配置文件定期被调度,该方案仅仅考虑确定性流量模式的静态分配;文献[11]参考LTE标准中的半静态调度提出基于资源复用条件树结构的新型调度方案,然而它仅适用于周期性数据业务。但上述两篇文献研究结果表明“一次授权,周期使用”的思想可用于减小调度开销。
为降低调度信令开销,本文结合LTE蜂窝物联网M2M业务特性和SPS思想提出一种RB动态预分配(dynamic pre-allocation, DPA)上行调度方案。首先根据MTCD测量和流量模式,利用M2M业务时延容忍特性周期性地为设备预分配相应大小RB(即时频资源);然后推导所提方案下的传输时延概率密度函数,为预分配周期建立时延约束;最后采用设备缓冲状态报告(buffer status report, BSR)机制代替传统的授权调度,在低控制信道使用率下完成基于预分配的可变大小RB分配,以适应突发和非固定大小的数据包。仿真结果证实了该方案的有效性。
1 系统模型与约束
1.1 半静态调度(SPS)机制
动态调度(dynamic scheduling, DS)每次传输数据前需等待上行授权(UL grant)。受控制信道数限制动态调度的用户数有限,以VoIP(voice over IP)为例,由于语音业务数据量大,LTE带宽所能支持的用户数是其所能调度用户数的5倍左右[12]。为此LTE利用VoIP数据包大小固定、到达间隔恒为20 ms的特点提出SPS[13],其资源分配如图1所示。

图1 SPS资源使用示意图Fig.1 SPS resource usage diagram
eNB通过PDCCH给UE下达SPS指示后,UE周期性地每隔20 ms就在固定的指定时频资源位置上发送或接受VoIP数据包,有效节省了用于调度的PDCCH信令开销。不同填充的业务信道静态分配给不同用户,无填充块用于动态调度。语音用户获得更大系统容量同时也确保其QoS需求。如有必要,调度程序可重新指示时频资源位置以匹配信道条件。
1.2 动态预分配系统模型
由于SPS仅适用于周期到达且数据包大小固定的业务流,本文针对M2M业务非连续到达与非固定大小数据包,提出RB动态预分配(DPA)模型如图2。模型参数定义在表1中。
如图2(c),一旦设备连接(RRC_CONNECTED)并请求资源,eNB就通过初始授权周期性地为它们预分配静态资源,其大小为Θ,代表着可分配给该设备的最大RB数。稳定通信系统中设备缓冲区队列大小不会无限增长,这要求DPA周期内平均队列长度增加值ΔQ小于最大数量离开值Θ,Θ值可通过流量到达模式分析和MTCD测量获得,符合当前业务负载可能达到的最佳阈值。

表1 DPA模型参数Table 1 DPA model parameters
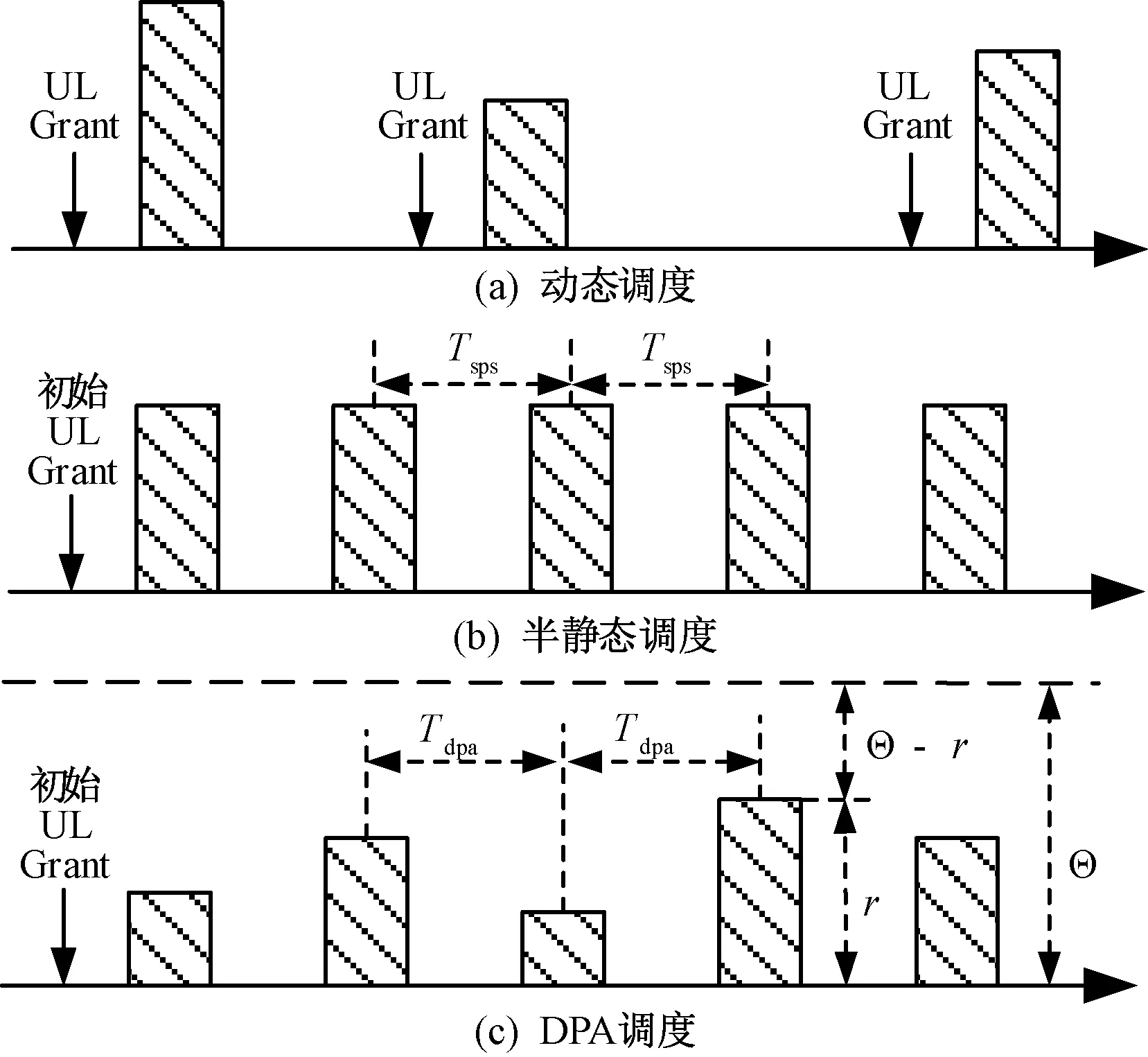
图2 动态预分配(DPA)模型Fig.2 Dynamic pre-allocation (DPA) model
与图2(b)静态分配不同的是,在每个DPA周期中的特定时频位置,为设备分配可变大小的资源块r,而非预分配的固定大小Θ。设备和基站都使用最近队列大小数据Qp作为预先约定的自适应适配功能ξ(Qp,Θ)的输入,以计算下一个传输机会所需的上行链路资源的容量r,r小于等于初始授权时协商分配的最大值Θ。
ξ(Qp,Θ)∈N.
(1)
1≤ξ(Qp,Θ)≤Θ.
(2)
(3)
最近队列大小Qp由eNB根据设备缓冲状态报告即BSR来确定,如LTE标准所定义[14],BSR是设备通过上行数据链路向eNB发送的,因此不占用任何控制信道资源,终端也存储此BSR用于计算RB。由于设备和基站通过ξ(Qp,Θ)独立地计算下一DPA周期会使用哪些特定资源,基站无需通过控制信道下达明确的资源使用授权;同时eNB提前一个周期知道哪些特定的资源r将被使用,如果r<Θ,就可将剩余的Θ-r资源用于动态调度,这意味着DPA方案与SPS相比没有内在的资源浪费。
1.3 模型可行性
75%左右的M2M业务具备一定时延容忍性,此类业务通常有着较为固定的到达模式[15],如周期或泊松到达。紧急型业务占比约为10%,往往由事件驱动,突发到达但发生频率低,模型牺牲数据时延性能换取低控制信道使用是合理的。基于大部分MTCD移动性较低甚至处于静态环境的事实如NB-IoT Rel-13 标准中不支持连接状态的移动性管理[16],调度期间MTCD不太可能与不同的eNB相关联,因此预分配方案可行。
1.4 DPA周期设计
延迟容忍仅代表业务可接受一定程度时延而非无时延约束。本文假设MTCD业务是平均到达为λ的泊松过程,图3为业务的到达与服务过程。
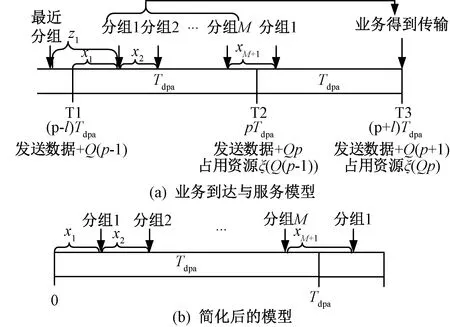
图3 业务到达与发送过程Fig.3 Traffic arrival and delivery process
业务时延容忍时长(delay tolerance time, DTT)为σDTT,DPA周期Tdpa的设计受限于两个预定义服务要求:时延约束与空缓冲区概率。
1)时延约束
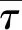
考虑在第(p-1)和p个DPA周期之间有M个分组到达的一般情况,则第m个分组到达时间sm为
(4)
xi是分组i-1和分组i之间的到达间隔,由于所有在[(p-1)Tdpa,pTdpa]到达的数据包都将在pTdpa(T2)时刻由BSR上报,因此分组m的延迟dm为
(5)
分组1和它上一周期最后分组的到达间隔为z1,z1与x2至xm相互独立且服从指数分布。p=1时z1=x1,此外z1≥x1。根据文献[17],x1也遵循指数分布且独立于x2至xm,这意味着dm与p无关,因此本文得到简化的情况如图3(b),式(5)可表达为
(6)
sm遵循Erlang分布。若M=1,则[0,Tpda)内只到达一个分组,X1和S2的联合密度为
fx1s2(x1,s2)=fX1(x1)fX2(s2-x1).
(7)
S2的边缘密度可从联合密度积分X1得到,
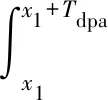
x1+Δx)×fX1(X1=x1+Δx)dx
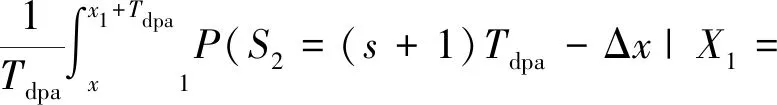
x1+Δx)dx.
(8)
fX1S2(x1,S2)=λ2e-λx1e-λ(S2-x1)=λ2e-λS2,
0≤x1≤S2.
(9)
由式(9)得出联合密度不包含x1,因此对于给定的s2,S2=s2条件下X1的条件密度在0≤x1≤s2范围内均匀分布。M=1时,Tdpa≤s2,因此X1条件密度在0≤x1≤Tdpa范围内也是均匀的,dm也遵循[0,Tpda]上的均匀分布。对于更一般的情况,相似的有:
fS1SM+1(S1,…,SM,SM+1)=λ2e(-λSM+1).
(10)
0≤s1≤…≤sM≤sM+1.
(11)
联合密度中除约束条件(11)外不包含任何到达时间sm,因此该联合密度在满足约束(11)的所有到达时间选择上是恒定的。dm概率密度函数PDF和累积分布函数CDF为:
PDF(dm)=1/Tdpa,CDF(dm)=dm/Tdpa, 0≤dn≤Tdpa.
(12)
由式(12)可得出一个重要结论:BSR上报时延分布与数据包到达时间无关,完全取决于Tpda,因此有
(13)
DPA方案提前一周期确定下一周期的资源分配如图3(a),因此分组到达至开始传输的总时延等于BSR上报时延τd和Tdpa之和,得到DPA周期约束条件为
(14)
tslot为LTE子帧时长,为1 ms,即
(15)
2)空缓冲区概率
需尽量避免一个DPA周期内无新分组到达造成BSR报告为0的情况,否则分配的无线资源可能因为缓冲区无数据而被浪费,尽管通过动态分配已将浪费减为最小。定义一个DPA周期内缓冲区为空的概率为Pempty,根据泊松过程分布得到
(16)
1/λ是业务平均到达时间间隔,为使缓冲区为空的概率尽量小,DPA周期的第2个约束条件为
Tdpa>1/λ.
(17)
2 动态预分配调度算法
基于上述DPA模型,提出一种动态预分配调度 (DPA scheduling, DPAS) 算法。算法对时延容忍类业务采用DPA资源分配;由于紧急业务占比较低不会造成过大信令开销且时延苛刻,因此动态调度紧急业务和混合自动重传(hybrid automatic repeat reQuest, HARQ)。预分配周期被设置为整数个LTE帧长,预分配完成为每个设备分配初始帧偏移v和子帧号w,v代表距离本DPA周期起点的帧数,设备须等待v帧后才可传输数据。给多个设备分配相同的Tdpa值、不同的v和w,它们就可在相互正交的时频资源上各自传输数据。通过式(18)确定动态分配RB数,NRB为传输队列业务所需的RB数,L为编解码器源速率确定的分组长度,与上一周期BSR报告的队列大小有关,NSC为每RB对的子载波数和符号数,NSC×l等于一个RB对中的总资源单元(RE)数,CR和MS分别表示编码速率和调制方案。
(18)
动态预分配调度(DPAS)算法功能描述如下:
步骤1) 识别请求调度的业务类型:若业务属于时延容忍类则符合预分配条件,并在约束(15)和(17)下最大化Tdpa值后依次执行步骤2~6;若业务属于紧急类型、HARQ重传或不符合约束(15)和(17) 的时延容忍类,则采用动态调度并跳过步骤2)~5);
步骤2) eNB基于最新MTCD测量,确定预分配给设备的最大RB数Θ,静态帧偏移v,子帧号w,RB起始索引k和适配函数ξ(.),通过初始授权通知设备预分配参数;
步骤3) 设备依据预分配参数和存储的最近队列大小Qp,利用自适应适配功能ξ(Qp,Θ)确定所使用的r个RB,r值由eNB和设备根独立计算得到;
步骤4) 剩余Θ-r个RB资源eNB用于动态调度紧急业务和HARQ重传;
步骤5) 设备完成当前DPA周期的数据传输同时上报当前缓冲区队列状态,以计算下周期资源分配;
步骤6) 若RRC重新建立连接或需更新预分配参数,则更新eNB预分配数据库,重新激活并通知设备以下预分配参数:DPA周期Tdpa,最大RB值Θ,帧偏移量v,子帧号w,RB起始索引k和适配函数ξ(.)。
3 仿真
OPNET搭建系统级仿真环境,表2为部分仿真参数设置。设备时延期限为101 ms,业务到达过程为平均时间间隔为20 ms的泊松过程,紧急设备占比10%。通过与完全动态调度 (DS) 算法以及LTE中已实现的半静态调度(SPS)算法进行对比来评估所提出动态预分配调度(DPAS)算法性能。
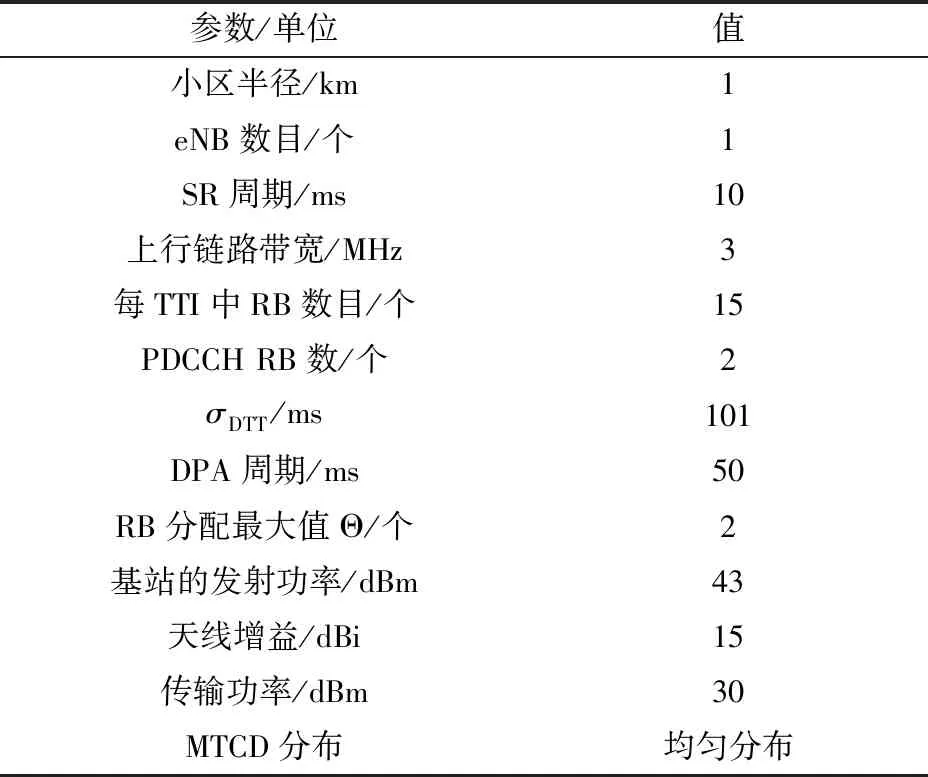
表2 仿真参数Table 2 Simulation parameters
SPS算法为紧急业务动态分配资源,其他业务静态分配固定的2个RB,DS算法则对所有业务进行动态调度,所采用的DS算法为比例公平算法。图4给出DS、SPS和DPAS这3种算法在不同MTCD数时的上行业务时延期限满足情况以及PDCCH和PUSCH负载情况。
从图4(a)可看出随着MTCD数量的增加,DPAS算法在业务时延方面表现最佳,MTCD为3 000时满足时延要求的业务占比高达88%,而另外两种算法在MTCD大于1 500后时延满意度迅速下降。
图4(b)给出相同信道条件下3种算法的PDCCH信道负载情况。DPAS算法控制信道使用率略高于SPS算法,因为可变大小的RB预分配使得系统剩余用于动态调度的RB多余SPS算法。DS算法PDCCH使用率最高,在MTCD为2 000时接近满负荷,这解释了为何DS算法时延满意度较差。
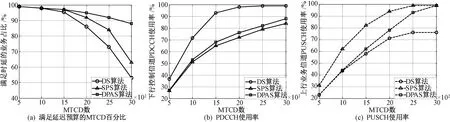
图4 不同MTCD数下3种算法的延迟满意度、PDCCH使用率和PUSCH使用率Fig.4 Delay satisfaction and utilization rates of PDCCH and PUSCH of the three algorithms at different MTCD numbers
图4(c)对比3种算法的业务信道PUSCH使用率,尽管SPS算法控制信道负载优于DPAS算法,但由4(c)可知同等情况下的SPS算法PUSCH使用率更高因此PUSCH更早趋于饱和。SPS静态调度部分的固定大小RB分配是造成SPS使用率偏高的主要原因,它不能适应流量变化导致大RB块可能用于传输小数据而被浪费。DPAS算法改善了SPS的非灵活分配,可以达到高业务信道使用率。DS算法则由于PDCCH限制而出现无法完全利用PUSCH的现象。
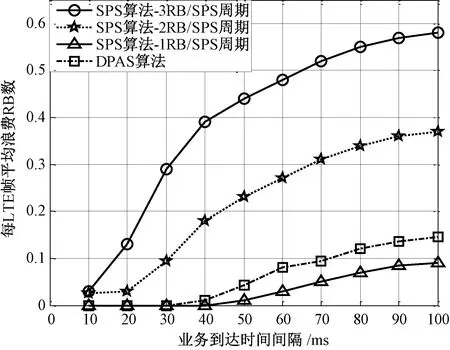
图5 每帧平均浪费的RB数(SPS周期和DPAS周期均为50 ms)Fig.5 The average number of the wasted RBs per frame (50 ms for both the SPS and DPAS periods)
最后,为SPS算法分别分配固定的1、2、3个RB,在不同的业务到达间隔下与DPAS算法进行比较以评估RB浪费情况,图5给出结果。公式(2)表明DPAS算法最小RB分配值为1个,随着业务达到间隔增大若缓冲区无数据则该RB被浪费。由于小RB分配造成了设备缓冲区的增长,因此图5中每周期固定分配1个RB的SPS算法浪费最小。SPS算法RB浪费随着固定分配RB数的增加而增加,DPAS算法优于它们。
4 总结
本文针对蜂窝物联网M2M业务特征提出一种RB预分配下的动态调度模型,引入BSR代替eNB指示的方案,推导方案需满足的约束条件并给出相应的算法流程,旨在降低调度过程中的PDCCH信令开销且适应可变大小的业务数据。仿真结果表明,本文算法时延性能和RB利用率优于动态调度算法和SPS算法,为控制信道有限下的物联网调度提供了一种解决思路。
