聚类与跟踪相结合的人脸数据集生成方法研究
2019-11-20王畅金璟璇金小峰
王畅, 金璟璇, 金小峰
( 延边大学 工学院, 吉林 延吉 133002 )
0 引言
目前,基于视频监控的人脸识别系统被广泛应用在公共安全、交通管理等领域.但由于监控视频中往往存在大量低质量的人脸图像(模糊、人脸旋转、遮挡、闭眼等),且视频帧间存在很高的冗余度,因此若将这些图像直接用于人脸识别就会降低人脸识别系统的准确率,并增加系统的负担.因此,在进行人脸识别前需要通过人脸图像优选方法去除低质量的人脸图像和降低视频帧间的冗余度[1].人脸图像优选需要为每个人建立人脸数据集.目前,人脸数据集的生成方法主要分为基于人脸跟踪的方法和基于人脸聚类的方法.
在人脸跟踪方法研究中,李蕊岗等[1]提出了一种将Camshift方法与Kalman方法相结合的方法,但该算法在背景复杂或目标被遮挡时,鲁棒性较差; Henriques等[2]提出了KCF算法,该算法引入方向梯度直方图特征和背景信息,使算法的抗遮挡能力得到加强,跟踪更为稳定,但遮挡后目标丢失这一问题仍没有得到很好的解决; Nam等[3]提出了基于CNN的MDNet跟踪算法,该算法由于在追踪过程中需要不断更新模型,使得其追踪效率较低,不适合多目标的追踪.在人脸聚类方法研究中,目前主要使用的方法有K-means聚类算法[4]、凝聚式聚类算法[5]、DBSCAN聚类算法[6]和Chinese whispers聚类算法[7].K-means聚类算法需要事先指定聚类数k, 且聚类结果受离群点的影响较大;凝聚式聚类算法具有较高的稳定性,且聚类数目无需事先指定,但其时间复杂度较高; DBSCAN聚类算法具有较好的抗噪能力,但其时间复杂度较高; Chinese whispers聚类算法不需要事先指定聚类数,算法较为简单,但阈值的选取对聚类结果影响较大.基于上述研究,本文将KCF跟踪算法与Chinese whispers聚类算法相结合来生成人脸数据集,以解决因目标遮挡引起的目标跟踪错误而导致的将不同人脸图像聚为一类的问题,以及单纯使用人脸聚类来获取人脸数据集时时间效率较低的问题,并通过实验验证本文方法的有效性.
1 相关技术
1.1 KCF跟踪算法
KCF跟踪算法是一种基于核岭回归的跟踪器,它通过循环移位来获取大量包含背景信息的训练样本,并根据循环矩阵的特性和离散傅里叶变换技术提升算法对单帧图像的处理速度,以此实现对目标快速、准确的跟踪.KCF算法通过检测器标注视频帧中的待跟踪目标区域(跟踪样本),并将跟踪样本作为基准样本,记为x.为叙述简便,本文以单通道尺度(n×1)的图像为例进行说明,即设x=[x1,x2,x3,…,xn]T.循环矩阵Xn×n通过对基准图像进行循环移位操作来构建,如公式(1)所示:

(1)
式(1)中矩阵X的每一行向量表示一个样本,第1行是基准样本x, 第i+1行向量可由第i行向量的元素向右循环移动一位得到,其数学表达式为:
Xi+1=Pix,i=1,2,…,n-1.
(2)
式(2)中Xi+1是循环矩阵的第i+1行,P为置换矩阵,如公式(3)所示:

(3)
矩阵(1)可以通过离散傅里叶变换实现对角化,如公式(4)所示:
(4)
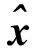
1) 训练分类器.给定训练样本{(x1,y1),(x2,y2),…,(xm,ym)},训练的目的是试图学得一个岭回归模型f(x)=wTx, 使得f(xi)与样本标签yi间的均方误差最小化,即
(5)
式中:λ是防止回归函数过拟合的归一化参数;xi为循环矩阵中第i行所表示的训练样本;yi为样本xi的标签.公式(5)在实数域内的闭合解为w=(XTX+λI)-1XTy, 式中X为循环数据矩阵,y是由yi组成的标签向量,I为单位矩阵.
引入核函数解决非线性分类问题时,需将待求值w定义为在高维空间中训练样本φ(xi)的线性组合,其数学表达式为:
(6)
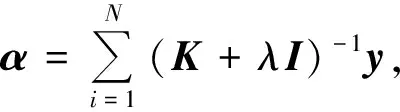
(7)

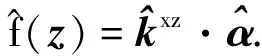
3) 更新模型.将前一帧使用的分类器模型αt-1与新分类器模型α(用新样本训练的模型)进行线性组合即可得到当前t时刻的分类器模型αt.线性组合方式为αt=(1-β)αt-1+βα, 式中β为分类器的自学习率.
1.2 Chinese whispers算法
Chinese whispers算法是一种无监督的聚类算法,它可自动查找类别的个数.Chinese whispers算法的具体步骤如下:
Step 1 无向图初始化.将每个人脸图像都作为无向图的一个节点,每个人脸图像节点为一个类别,不同节点之间根据ResNets[9]提取的特征计算相似度.若两个节点之间的相似度超过设定的阈值,则将两个节点相连形成关联边,边的权重为两个节点间的相似度.
Step 2 随机选取一个未遍历过的人脸图像节点i, 并从该节点开始在其邻居中选取边权重最大者j, 然后将节点i归为节点j所在的类.若邻居中有多个节点属于同一类,则将这些节点的边权重相加之后再进行边权重大小的比较.
Step 3 重复Step 2,直至遍历所有节点.
Step 4 重复Step 2和Step 3,直至满足迭代次数.
2 人脸数据集的生成
2.1 KCF跟踪算法与Chinese whispers聚类算法分析
1) KCF跟踪算法分析.KCF跟踪算法的抗干扰能力和计算速度与其他算法相比虽然得到了提升,但其在目标被遮挡时仍会发生跟踪丢失,并且在初始选定目标区域后其尺度大小无法改变,即在跟踪过程中人脸框的尺度无法实现自适应,因此跟踪会发生漂移现象,如图1—图3所示.观察图1和图2可以看出,随着人脸逐渐靠近镜头,人脸尺度逐渐变大,但人脸框不能自适应人脸尺度的变化.观察图2和图3可看出,遮挡发生后目标出现跟踪丢失现象.

图1 初始化选定框 图2 目标发生遮挡 图3 目标跟踪丢失
2) Chinese whispers聚类算法分析.Chinese whispers聚类算法比传统聚类算法的聚类准确率虽然有了提高,但其特征提取过程较为耗时,如在尺度为120 pixel×120 pixel的人脸图像中提取特征大约需要1 s.此外, Chinese whispers聚类算法对于完全侧脸的人脸图像不能进行正确聚类.
2.2 基于KCF算法和Chinese whispers算法相结合的人脸数据集生成方法
基于人脸聚类和人脸跟踪相结合的人脸数据集生成方法的主要思想为:
1)在没有遮挡情况发生时,采用人脸跟踪算法获取人脸图像集,并对所获得的每一个人脸图像集进行人脸图像优选,优选后对人脸图像进行聚类.因该方法不是对视频帧中的全部人脸图像进行聚类,所以不仅能提高聚类速度,还能提高聚类的准确性.
2)整个生成人脸数据集的过程以人脸跟踪为主,并判断每一帧图像是否存在人脸遮挡,若有遮挡则停止跟踪并启动人脸检测.通过这种方式可有效避免因遮挡引起的跟踪丢失或错误而导致不同的人脸聚集在同一人脸数据集中.
3)每间隔25帧重新初始化跟踪器,以使跟踪器能够及时检测到新出现的人脸和消失的人脸.每个跟踪片段中的人都要单独建立人脸数据集.
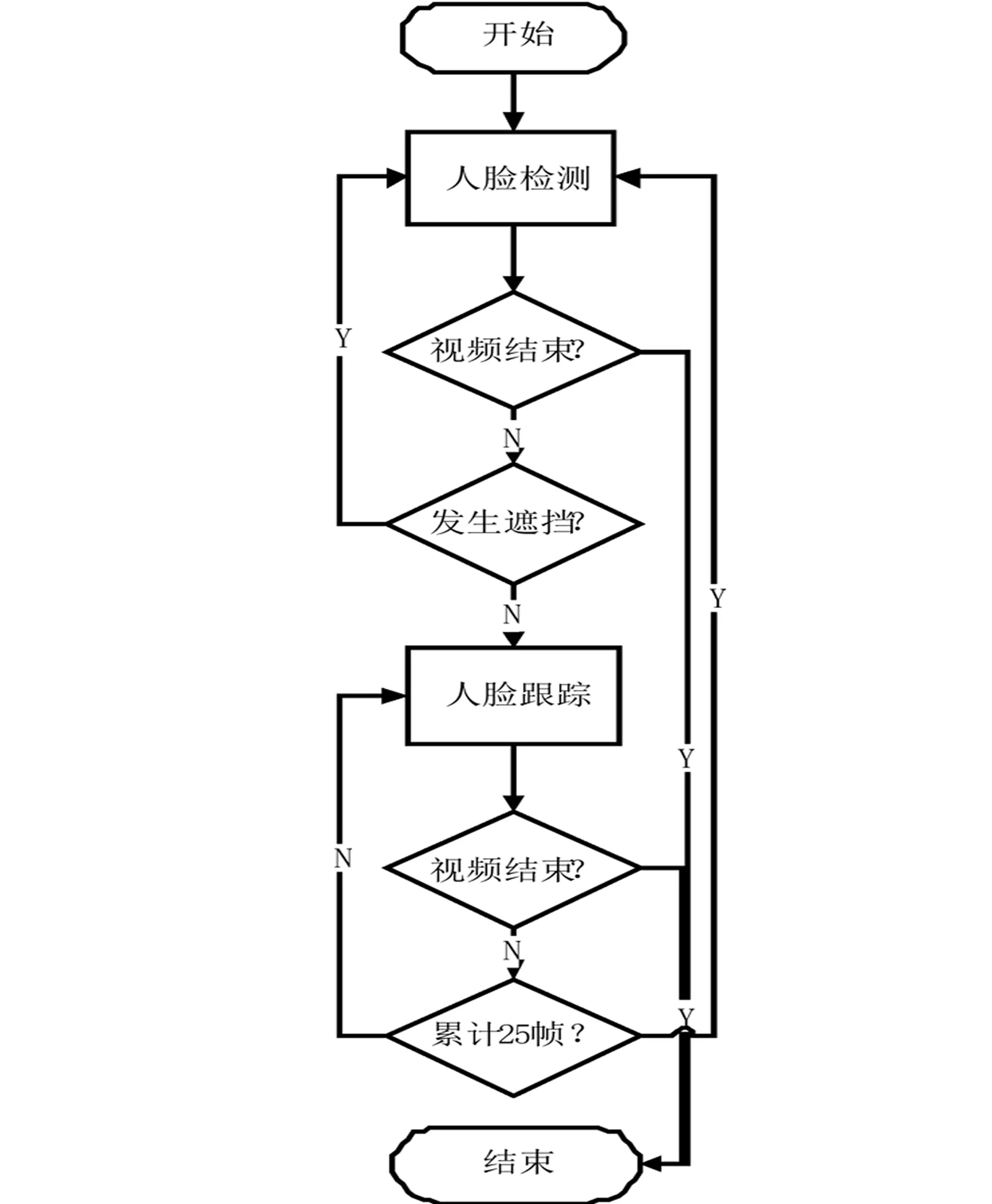
图4 人脸跟踪与人脸聚类相结合的人脸数据集生成流程图
基于人脸跟踪与人脸聚类相结合的人脸数据集生成方法的基本流程如图4所示,实现的具体步骤如下:
Step 1 初始化跟踪器.采用人脸检测算法检测视频中的人脸,并对每个人脸赋予一个跟踪器.
Step 2 开始跟踪.根据人脸框的位置判断每一帧中的人脸是否发生了遮挡,若发生遮挡则执行步骤Step 3,若无遮挡则执行步骤Step 4.
Step 3 启动人脸检测程序.对每一帧进行人脸检测,同时根据人脸框的位置判断遮挡是否仍然存在.若遮挡存在则继续人脸检测; 若遮挡消失,则重新跟踪,即执行步骤Step 1.
Step 4 无遮挡跟踪时,每间隔25帧重新初始化跟踪器,即执行步骤Step 1.
Step 5 在由Step 4得到的每个人脸数据集中通过人脸图像优选算法选出高质量的人脸图像,然后将优选出来的人脸图像进行人脸聚类,以此完成每个人的人脸数据集的生成.
2.3 人脸数据集生成过程中出现的问题及解决方法
1) KCF跟踪算法在判断有无遮挡情况发生时,只有当滤波器与检测目标的响应值有较大变化时,即目标被大面积遮挡时,才能判断为遮挡,如图5所示.若遮挡面积较小, KCF跟踪算法就无法及时做出判断(如图6所示).但由于小面积遮挡的人脸图像在优选过程中也被视为低质量人脸图像,因此需要一种能够及时判断当前帧的人脸间是否发生遮挡的有效方法.目前判断人脸间是否发生遮挡的常用方法是基于计算两个人脸框重叠面积大小的判断方法,该方法对于图5所示的遮挡情况较为有效,但对图6所示的遮挡情况(身高差过大导致人脸框间相交面积为0)则不能正确判断.为此,本论文采用如下方法来进行判断:
将人脸框左上角和右下角的坐标分别设定为(x1,y1)和(x2,y2),在判断过程中只使用2个横坐标x1和x2来判断是否发生人脸遮挡.通过大量的仿真实验发现,横坐标的距离差在0~30范围内均能有效地判断有无遮挡情况的发生,因此本文取距离差20为阈值,即当距离差小于20时判为遮挡.具体描述如下:
if condition then occlusion occurred, 其中 condition:
0<|x1-x1other|<20 or 0<|x1-x2other|<20,
or 0<|x2-x1other|<20 or 0<|x2-x2other|<20.
上式中x1other和x2other是另一个人人脸框的2个横坐标.经实验验证,上述方法对图5及图6所示的人脸间的遮挡均可进行有效判断.

图5 大面积遮挡

图6 初步遮挡
2) 当人脸尺度发生较大变化时,初始设定的人脸框不能提取出完整的人脸.通过观察监控视频可以发现,人脸跟踪的尺度变化与其他目标跟踪的尺度变化有所不同.例如:车、行人等作为跟踪目标时,其尺度的变化可能是放大或缩小;而人脸作为跟踪目标时,因人脸图像的获取只能是人脸面向摄像头并逐渐接近而获得,因此考虑人脸尺度变化时只需考虑尺度放大的情况即可.
由于人脸尺度在25帧里不会有较大变化,因此本文在每一次初始化人脸框时,使人脸框的尺寸略大于检测到的实际目标区域,这样就不需要逐帧对目标尺度进行变换,并且得到的人脸五官及轮廓更为完整,如图7所示.由图7可看出,该方法在25帧后仍能提取出完整的人脸.

(a)初始化区域 (b)改进前的人脸跟踪框 (c)改进后的人脸跟踪框图7 改进前后的人脸跟踪框
2.4 聚类性能的评价指标
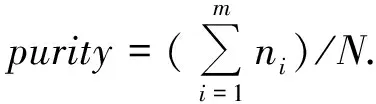
3 实验结果与分析
仿真实验采用3个拍摄于室内的视频(采用Sony高清摄像机),视频数据的具体参数如表1所示.3种人脸数据集生成方法(基于人脸聚类的人脸数据集生成方法、基于人脸跟踪的人脸数据集生成方法、本文提出的人脸聚类和人脸跟踪相结合的人脸数据集生成方法)在视频1—视频3上的实验结果分别如表2—表4所示.各表中的时间为各算法生成人脸数据集与在数据集中选出最优人脸图像所耗费的时间.

表1 视频参数

表2 视频1的实验结果

表3 视频2的实验结果

表4 视频3的实验结果

图8 完全侧脸的人脸图像
从表2—表4可以看出,本文算法在时间效率上比基于人脸聚类的方法提高约50%,在纯度上比基于人脸跟踪的方法有一定的提高.纯度提高幅度的大小与行人遇到遮挡的时间有关:若在视频初始时遇到遮挡,则基于人脸跟踪方法的纯度相对较低,而本文算法的纯度在提高幅度上相对较大,如表4所示;若在视频即将结束时遇到遮挡,则基于人脸跟踪方法的纯度相对较高,而本文算法的纯度在提高幅度上相对较小,如表2所示.实验中,由于完全侧脸的人脸图像(如图8所示)不能和其他偏转角度较小的人脸聚为一类,因而会使人脸集的个数大于实际个数,但相比于人脸聚类方法,本文算法更接近于真实人脸集的个数,并且其纯度也有一定的提升.
4 结论
本文提出的将聚类和跟踪相结合的人脸数据集生成方法,能够很好地解决因遮挡引起的跟踪错误而导致将不同人的人脸图像聚为一类的问题,并且还可以提高获取人脸数据集的时间效率,因此本文方法可被广泛应用在人脸识别、人脸数据库的建立以及人脸搜索等系统中.由于人脸聚类算法中的特征提取阶段较为耗时,使得本文方法的时间效率低于基于人脸跟踪的人脸数据集生成方法.另外,由于本文方法未能对完全侧脸的人脸图像进行正确聚类,导致生成的人脸数据集的个数可能多于实际个数.在今后的研究中,我们将对上述问题进行研究,以完善本文方法.
