一种基于生成对抗网络的单幅图像去雾算法
2019-11-18李莎柯文驰李科程鹏
李莎,柯文驰,李科,程鹏
(1.四川大学计算机学院,成都610065;2.四川大学空天科学与工程学院,成都610065)
0 引言
图像去雾作为一种自适应恢复问题,是一项非常具有挑战性的任务。早期的图像去雾方法假设同一场景中有多个图像可用。而在实际情况中,单幅图像的去雾更加真实、流行[1]。因此,本文主要研究单图像去雾问题。已有很多图像去雾方法基于大气散射模型,该模型可以描述为:

其中I(x)表示雾天的成像图像,J(x)表示清晰图像,t(x)表示传播介质透射率,α 为大气光值,其中大气光值反应了全局大气光的散射导致场景颜色的偏移。传播介质透射率描述的是光线通过大气媒介传播到达成像设备的过程中没有被散射的部分,它能反映图像上目标场景的远近层次。当大气同质时,传播介质透射率可以定义为t(x)=e-βd(x),0 ≤t(x)≤1 其中,β 表示散射率,当大气均匀时,在一定时刻对于整幅图像来说散射率是一个定值,d(x)为场景对象到传感器的距离,即场景深度。去雾的关键是估计大气光值α 和传播介质透射率t(x)。除了一些专注于估计大气光[2]的方法,大多数算法更侧重于精确估计传输函数t(x)。Fattal[1]提出了一种场景反射率的估计方法。Tan[3]利用最大化复原图像的局部对比度来去雾,He 等人[4]提出了基于暗原色先验(DCP)去雾算法,Zhu 等人[5]提出了一个可训练的线性模型,称为颜色衰减先验(CAP),在监督的方式下学习模型参数。Berman 等人[12]利用全局像素的雾线来估计透射率图(NCP)。随着深度学习理论的完善和发展,一些研究者将深度学习引入到去雾中,并取得了良好的效果。Cai 等人[6]提出了DehazeNet,从雾天图像中训练预测的介质传输图。Ren W 等人[7]利用多尺度卷积神经网络(MSCNN)生成了粗略的场景透射率。Zhang H 等人[8]提出了DCPDN,能够级联地学习传输图、大气光、去雾图像之间的关系。这些方法已取得了巨大的进步,然而仍有一些因素影响了其去雾效果,一方面,对传输图的估计不准确,另一方面,非端到端的方法无法捕捉到介质传输图,大气光和去雾图像之间的内在关系。Li 等人提出的AOD-Net[9]是第一个可训练的端到端的去雾模型。它基于大气散射模型,做了改进,描述如下:

K(x)为与输入无关的传输函数,其用一个轻量级的卷积网络去评估K(x),然后级联的训练网络以最小化输出图像与清晰图像之间的重构误差。考虑观测到的雾天图像与清晰图像之间的关系为J(x)=Φ(I(x);θ),Φ(*)即是潜在的高度非线性变换函数,θ 为参数,AOD-Net 所代表的关系可以看作是一个具体的关系Φ的通用函数。基于该思想,本文构建了一个完全基于神经网络学习其非线性关系的端到端的算法。并引入判别网络进一步提高所恢复图像的质量。
1 生成对抗网络设计模型图
1.1 生成网络设计模型图
自编码器在数据去噪,和可视化降维方面已得到广泛的应用。文中采用上下文自编码网络学习雾霾图像与清晰图像之间的函数关系。网络结构如图1 所示,参数设置如表1-3。
编码器主要功能是输入雾天图像通过生成网络尽可能恢复出清晰无雾图像,本文先使用了4 个卷积层作为编码部分,提取图像特征信息。由于扩张卷积支持感知域的指数扩展,并且能够不丢失分辨率和覆盖范围。本文使用了扩张卷积模块增加图像的感知域,聚合多尺度上下文信息,增强网络的学习能力。解码器部分使用两个ConvTranspose2d-Average Pooling 结构对图像执行与下采样相反的两次上采样操作,并在其间使用3×3 的卷积恢复图像,加入2 个跳跃连接,将浅层特征信息传递给解码器,加快网络训练过程。

表1 Encoding Layer

图1 生成网络结构
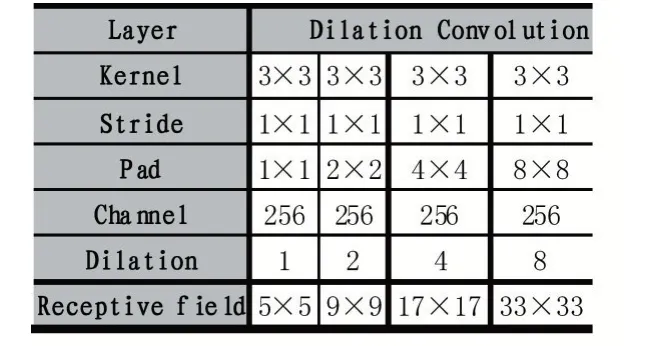
表2 Dilation Convolutions Module

表3 Decoding Layer
1.2 判别网络设计模型图
判别网络为一个全卷积网络,由5 个卷积层构成,网络结构如图2,卷积层参数设置如表4,这里除了最后一个卷积层,每层都采用Conv-Relu 的方式,并在网络最后加入了Sigmoid,将判别结果归一化到[0,1]之间。输入生成器生成的图,判断真假。
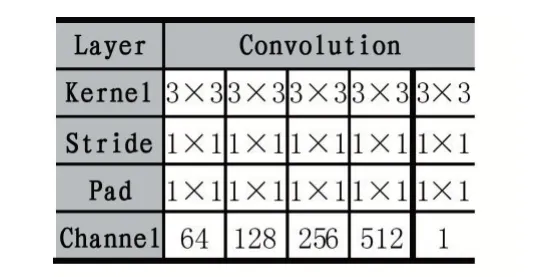
表4 Structure and parameter setting of discriminator
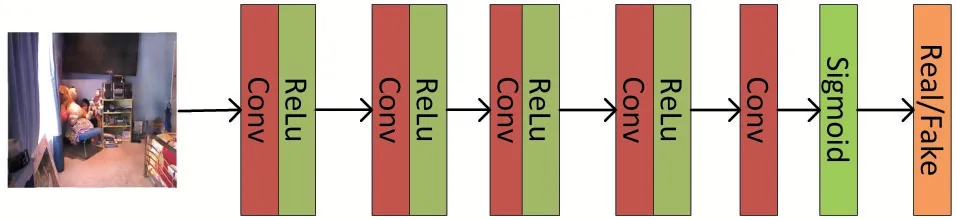
图2 判别网络结构
1.3 损失函数
基于生成对抗网络的思想,给定一个雾天图像,生成器尝试产生尽可能真实的无雾图像,判别器验证生成的图像看起来是否真实。设H 为雾天模糊图像集的一个样本,R 为清晰图像集中相应的清晰图像。文中的生成对抗网络的损失使用原始Gan 的损失,描述如式(3)。其中D 表示判别网络,G 表示生成网络。判别器从全局的角度,验证图像,找到生成效果最好的那个。在生成网络中,使用L2 损失,在像素级别学习生成清晰图像。并引入感知损失的思想,使用在ImageNet 数据集上预训练的VGG16 模型的relu1_1,relu1_2,relu2_1,relu2_1 层提取特征,描述如式(4)。为了利用图像的多尺度信息,在生成网络的解码器中使用卷积块提取不同尺度的特征。描述如式(5),其中Di是解码器提取的不同尺度的特征,Gi是不同尺度的对应清晰图像。αi表示各个尺度代表的权重。从解码器提取的特征分别对应1/4,1/2,1 倍原尺度,越接近原始分辨率的图像,在恢复中所占权重越大。本文的权重取值分别为1/4,1/2,1,通过使用多尺度损失,可以更好地捕获图像特征,恢复图像的细节信息。

2 训练实验
2.1 数据集
由于光照等条件的变化,分别记录雾天图像和其对应的清晰图像,是难以做到的。因此本文选用去雾公开数据集D-HAZY[10],该数据是通过合成复杂场景的真实图像中的雾度而建立的。其包含NYU-Depth和Middelbury 两个部分。NYU-Depth 数据集由1449对相同场景下的合成的有雾图像和对应清晰图像组成。也包含每个场景下的深度图,文中并没有使用深度图。Middelbury 包含23 个相同场景下的清晰和合成的有雾图像。
2.2 数据处理
从NYU-Depth 里取1000 张图片,将其裁取为128×128 尺寸的小块,每隔64 个像素截取一张,并将截取的图像采用随机翻转,旋转90 度的方式,增加训练的数据量,以提高模型的泛化性,裁取后共得到54000对有雾与对应清晰的训练图像。并取与训练集不同的400 张图像作为测试集C。为和其他一些算法相比较,文中分别在NYU-Depth 与Middelbury 数据上做了测试,记为测试集A、测试集B。为了测试算法的实用性,在一些真实雾天图像上也做了测试。
2.3 实验设置
有雾图像作为生成网络的输入,生成网络输出的图像送入判别网络,判断真假。网络学习率使用两个时间尺度更新规则,生成器和判别器的学习率分别设置为0.0001,0.0004,更新比例为1。采用Adam 优化,优化器参数的设置采取默认值,批大小为8。算法运行在GeForce GTX 1080 GPU 计算机的PyTorch 上。
3 分析讨论
3.1 定量分析
本文采用PSNR、SSIM 评估去雾后的图像质量,PSNR 表示峰值信噪比。基于像素点间的误差评价图像质量,能够在像素级别评估图像,显示去雾的有效性。SSIM 表示结构相似性,与人类感知一致,它分别从亮度、对比度、结构三方面度量图像相似性。测试结果如表5。

表5 测试结果
取其中的一张图片,去雾效果如图3。为了证明生成对抗网络结构的有效性,在仅仅使用自编码结构的网络上也做了实验,在相同的训练测试集上,测试结果如表6。可看出,判别网络的引入,显著提高了相关指标的值。实验也比较了损失函数的影响,在相同的参数设置下,加入感知损失可以加快网络的训练,使得网络收敛速度更快。并在结构相似性SSIM 上有细微的提高。

表6 自编码网络上测试结果

图3 测试集B、测试集C、真实雾天图像的去雾效果
3.2 结果比较
为评估本文算法,将其与一些先进的单幅图像去雾算法比较,一方面在PSNR、SSIM 上分析,另一方面在一些真实雾天图像的去雾效果上做了对比。结果见表7-8,图4。

表7 在测试集A 上的量化结果
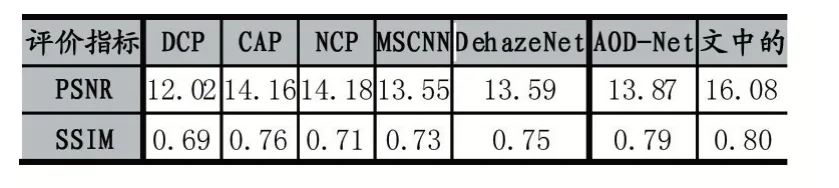
表8 在测试集B 上的量化结果
表7 和表8 的部分数据来源于参考文献[11]。
3.3 结果分析
可以看出本文的算法在PSNR、SSIM 上取得了更高的值,在对真实自然图像去雾上也有一定的效果,对于近处的图,算法恢复的细节,清晰度较好。对于较远处的景色,仍有一定的雾残留。其他算法中,都取得了较好的视觉效果。然而,仔细观察会发现,NCP 恢复的图像细节最清晰,而亮度与色彩上增强了。CAP 有时会模糊图像的纹理,如第2 幅图中绿色树叶部分,DehazeNet 使一些区域变暗,MSCNN 引入了过度增强的图像伪影,如第4 幅图球场场景中。
4 结语
本文提出了一个有效的可训练的端到端的网络,该网络不需要评估大气散射模型里的参数,利用生成对抗网络生成更加清晰逼真的图像,并训练和评估了所提出的算法,取得了较好的效果。虽然算法基于合成室内图像训练的,但在对真实场景下的图像去雾有一定的效果,对于高级计算机视觉任务中的雾天图像预处理有一定的参考作用。然而文中对于场景深度较大,雾浓度较高处,去雾效果不够明显,后续需改进。并且实验在合成数据集上进行,而真实情况可能场景更复杂,应该进一步探索在真实去雾数据集上去雾,使得去雾更加适用,效果更好。
