基于Char-RNN 的诗歌自动生成方法
2019-11-18刘俊利
刘俊利
(西南科技大学计算机科学与技术学院,绵阳621000)
0 引言
21 世纪,随着中国国力的日渐强大,越来越多的人开始认可、学习中国传统文化。而诗歌作为中国传统文化重要构成之一,在中华文化复兴的今天,也正获得越来越多的关注。近年来,随着自然语言处理的持续火热,在文本自动生成领域,自动生成中国古典诗歌的研究逐渐成为技术热点。由于诗歌生成需要考虑时间先后顺序的问题,而RNN 之所以称为循环神经网络,是因为它具有记忆之前信息并利用记忆影响当前的输出的特点。所以显然RNN 很适合用于解决这一类问题。不过基本RNN 只有一个隐藏状态,在模型迭代优化的过程中,梯度随着传播深度的增加越来越小,最终没有变化,容易造成梯度弥散,对长距离的记忆效果不好。因此在Char-RNN 网络搭建过程中选择采用RNN的变形结构LSTM 作为基本的模型,最终实现诗歌的自动生。
1 LSTM网络
LSTM[3]是一种RNN[4]的变体结构,是RNN 的改进版。从外部结构看,两者的输入和输出都是一样的,从内部结构来看RNN 和LSTM 的结构分别如图1、图2所示。其中,图 1 的内容与 RNN 的公式:ht=f(U xt+Wht-1+b )相对应,激活函数f 采用tanh 函数;图2 结构较为复杂,LSTM 的隐状态相较于RNN 添加了Ct,图中Ct-1到Ct的水平线是LSTM 的主干道,Ct在主干道的无障碍传递解决了在较长序列中梯度失效的问题。此外,图中ft、it、ot分别为遗忘门、记忆门、输出门的输出,两个tanh 层则分别对应记忆单元的输入与输出,向量由第一个tanh 层生成用于更新记忆单元状态,σ 是Sigmoid 激活函数。
1.1 遗忘门
每一条进入LSTM 网络的信息Ct-1,都要经过一个遗忘门来过滤掉Ct-1的部分内容。如果遗忘门输出ft接近0 则遗忘该部分内容,如果接近1 则保留该部分内容,具体公式见(1)。公式中,xt和ht-1是遗忘门的输入。

1.2 记忆门
不仅仅只是遗忘,LSTM 过滤内容的同时还需要记住新的东西。记忆门的输出包括it和,it的值决定了当前输入xt有多少将保存到记忆单元状态Ct中,具体如式(2);由tanh 层生成,用来更新记忆单元状态,具体如式(3)。最后将遗忘门和记忆门的结果组合在一起,形成新的单元状态Ct,如式(4)。
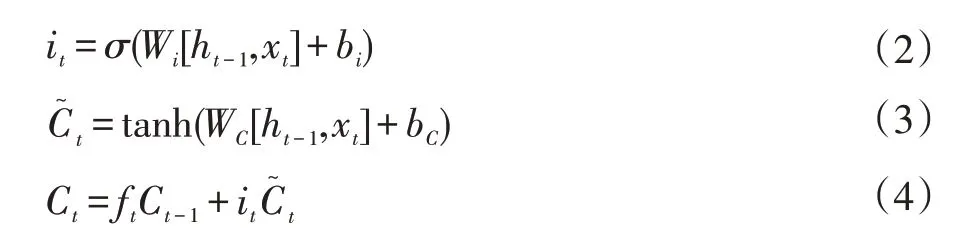

图1 RNN结构

图2 LSTM结构
1.3 输出门
LSTM 的隐状态包括Ct和ht。前面的遗忘门,记忆门完成了Ct的计算,输出门需要完成ht的计算。它首先通过sigmoid 激活函数σ 得到一个数值在0~1 之间的初始输出ot,如式(5),然后再用tanh 层把Ct值推到-1 和1 之间。最终通过ot*tanh(Ct)得到ht,如式(6),LSTM 最终的输出由ht进一步变换得到。

2 Char-RNN原理
Char-RNN[5]是一种字符级循环神经网络,其本质是序列数据的推测,即通过已知的字符,预测下一个字符出现的概率并选取概率最大者为下一个字符。它使用的是RNN 最经典的N vs N 模型,该模型具有输入与输出的序列长度相等的特点,其具体结构如图3 所示。

图3 “N vs N”的经典RNN结构
在使用Char-RNN 测试生成序列时,其具体流程为:首先选择一个x1作为起始字符,然后通过训练好的模型得到下一个字符的概率,最后选取概率最大者为下一个字符并将该字符作为下一步的x2输入模型。这只是一个单元,根据需要生成的文本长度选择循环次数,可以生成任意长度的文字。
3 Python实现
3.1 网络输入
网络的输入包含两部分:self.inputs 和self.lstm_inputs。其中,self.inputs 是外部传入的一个batch 内的输入数据;self.lstm_inputs,是embedding 的具体数值。此外,seIf.targets 是训练目标,是self.inputs 每个字母对应的下一个字母。self.keep_prob 控制了Dropout 层所需要的概率。
def build_inputs(self):
with tf.name_scope('inputs'):
self.inputs=tf.placeholder(tf.int32,shape=(self.num_seqs,self.num_steps))
self.targets = tf.placeholder(tf.int32, shape=(self.num_seqs,self.num_steps))
self.keep_prob = tf.placeholder(tf.float32, name='keep_prob')
#对于中文,需要使用embedding 层
#英文字母没有必要用embedding 层
if self.use_embedding is False:
#对字字符进行onehot 编号
self.lstm_inputs=tf.one_hot(self.inputs,self.num_classes)
else:
with tf.device("/cpu:0"):
#嵌入维度层word2vec 和RNN 连接器;同时训练作为模型的第一层
embedding = tf.get_variable('embedding', [self.num_classes,self.embedding_size])
self.lstm_inputs = tf.nn.embedding_lookup(embedding,self.inputs)
3.2 模型构建
首先,定义了一个多层的BasicLSTMCell 并对每个BasicLSTMCell 加入一层Dropout,减少过拟合。
lstm=tf.nn.rnn_cell.BasicLSTMCell(lstm_size)#state 并不是采用普通rnn 而是lstm。
drop = tf.nn.rnn_cell.DropoutWrapper (lstm, output_keep_prob=keep_prob)#对每个state 的节点数量进dropout
其次,定义了cell 后,使用tf.nn.dynamic_rnn 函数展开时间维度,其输出为self.outputs 和self.final_state。
self.lstm_outputs,self.final_state=tf.nn.dynamic_rnn(cell,self.lstm_inputs,initial_state=self.initial_state)
然后,定义一层Softmax 层得到最后的分类概率。这里经过一次类似于Wx+b 的变换后得到self.logits,再做Softmax 处理,最终输出self.proba_prediction。
#构建一个输出层:softmax
with tf.variable_scope('softmax'):
#初始化输出的权重,共享
softmax_w = tf.Variable(tf.truncated_normal([self.lstm_size,self.num_classes],stddev=0.1))
softmax_b=tf.Variable(tf.zeros(self.num_classes))
#定义输出:softmax 归一化
self.logits=tf.matmul(x,softmax_w)+softmax_b
self.proba_prediction=tf.nn.softmax(self.logits,name='predictions')
3.3 训练模型与生成文字
训练模型就是向构建好的模型里面不断的加入数据,由于是生成五言诗歌,所以选取了大量的唐代五言诗作为数据样本。然后将结果不断保存。
def load(self,checkpoint)
self.session=tf.Session()
self.saver.restore(self.session,checkpoint)
print('Restored from:{}'.format(checkpoint))
完成模型训练后,通过读取保存好的模型即可实现网络生成样本:
def sample(self,n_samples,prime,vocab_size):
samples=[c for c in prime]
sess=self.session
new_state=sess.run(self.initial_state)
preds=np.ones((vocab_size,))#for prime=[]
for c in prime:
x=np.zeros((1,1))
x[0,0]=c#输入单个字符
feed={self.inputs:x,self.keep_prob:1.,self.initial_state:new_state}
preds,new_state=sess.run([self.proba_prediction,self.final_state],feed_dict=feed)
c=pick_top_n(preds,vocab_size)
samples.append(c)#添加字符到samples
for i in range(n_samples):#不断生成字符,直到达到指定数目
x=np.zeros((1,1))
x[0,0]=c
feed={self.inputs:x,
self.keep_prob:1.,
self.initial_state:new_state}
preds,new_state=sess.run([self.proba_prediction,self.final_state],feed_dict=feed)
c=pick_top_n(preds,vocab_size)
samples.append(c)
return np.array(samples)
4 运行结果
利用深度学习框架TensorFlow 搭建多层LSTM 网络,进而完成Char-RNN 模型的创建,最终实现诗歌的自动生,运行效果如图4 所示。运行效果非常直观,利用Char-RNN 模型确实可以完成诗歌的自动生成且生成的诗歌具有一定程度的创作水平。

图4 生成诗歌效果图
5 结语
本文首先介绍了LSTM 网络,之后给出了Char-RNN 模型的基本原理,然后利用TensorFlow[6]搭建多层LSTM 实现Char-RNN 模型,最后利用大量诗歌作为样本训练模型,完成了诗歌的自动生成且生成的诗歌具有一定的艺术水平。目前Char-RNN 由于其序列数据推测的特点在深度学习的“创作”领域应用广泛并也取得了部分成果,不过该模型也存在部分缺陷:需要事先给定一部分数据,然后Char-RNN 才能顺着往下预测。该缺陷容易导致生成文本随机性大、主题模糊等问题。特别地,主题是诗歌的要素之一,所以Char-RNN 模型自动生成诗歌有待改进。Char-RNN 模型向我们展示了人工智能写诗的可能性,虽然只是初级阶段,但是未来,人工智能必将在文本创作领域取得令人满意的成果。
