基于改进DRDL 模型的车辆再识别算法
2019-11-18杨飚王雨周
杨飚,王雨周
(北方工业大学城市道路交通智能控制技术北京市重点实验室,北京100144)
0 引言
近几年,我国的汽车保有量爆炸式增长,随之而来的是交通的巨大压力,并且由于车辆的极度相似性也给公共安全系统中车辆的再识别带来了问题[1-3]。每辆车都拥有独一无二的车牌照,并且车牌照的识别已经广泛用于交通及其他车辆身份的识别系统中。但是很多情况下,我们并不能通过车牌照来匹配到某一辆车。第一,在绝大多数的安防摄像头中是没有车牌照的识别系统的,所以很难直接在安防系统中匹配到目标车辆,因此在这种情况下车牌识别的效率会大大降低。第二,很多车主为了逃避法律的制裁,会对车牌采取不正当的手段,例如,故意遮挡车牌、替换成假车牌,甚至摘掉车牌。还有一些车辆发生过碰撞,造成车牌的挤压,不平整,这些情况都能对车牌识别造成困难。因此车辆再识别在交通领域有巨大的价值。但是不同于行人再识别,车辆的相似度极高,对于车辆的精确匹配难度极大。
尽管,车辆再识别的问题提出来多年,但是大部分还是依靠传感器完成再识别的任务[4-6]。近几年,由于深度学习,卷积网络的发展进入研究人员的视野,有人提出通过深度卷积网络提取车辆外部特征进行车辆再识别的任务。
与研究相对成熟的行人再识别相比,车辆再识别的任务极具挑战性,因为上千辆的同一车型相似度非常高[7-8]。对于人来说,两辆相同款式的新车,假如没有车牌,很难分辨他们的不同特征。因此,如果要识别一辆车,需要一些特殊的标记或者符号,例如车身的彩绘,车内前部摆放的饰品,车窗的标志或者是车身由碰撞、刮蹭造成的车痕等。因此,车辆再识别的算法必须尽可能多地提取这些特征。提取越多的车辆细节特征,越能提高识别的准确率。在基于前人提出的DRDL(Deep Relative Distance Learning)的模型的基础上,我们提出基于改进DRDL 的车辆再识别算法,来进一步解决车辆再识别的任务。
1 DRDL模型的改进车辆再识别算法
目前主流再识别领域是针对行人再识别和人脸再识别[8-10],这两个主题都可以归为一类问题:给定一张需要检索的图片,和候选的图片数据库,我们要利用检索的图片在数据库中匹配到与其一样的图片。车辆再识别的大致过程与行人再识别相似,为了更能快速精准地匹配到想要的车,车辆再识别的过程中,需要先对车型进行分类,然后识别,再对车辆进行矩阵距离的计算。鉴于行人再识别与车辆再识别的相似性。研究工作要建立在此基础之上。
北京大学基于行人再识别提出了DRDL 模型用于车辆再识别。DRDL 是专门为车辆再识别设计的一种端到端的框架结构。其本质是三元函数深度卷积网络(Triplet Loss Deep Convolutional Network),因为深度卷积网络在行人再识别问题上能够取得非常不错的效果。通过减小车辆类内距离,增大类间距离,做到车辆的身份识别。通过优化三元损失函数,网络可以将原始车辆图像投影到欧几里德空间,减小类内距离,增大类间距离,为此专门设计了Coupled Cluster Loss 损失函数和能够混合不同网络的结构,结构如图1 所示。

图1 DRDL网络整体框架
本文在DRDL 架构的基础上修改了提取车辆特征的深度卷积网络,使用了效果更好、速度更快的ResNet。将ResNet 提取到的特征,即全连接层的输出,分成了两个分支[1,11],一个分支是车的属性分类,另一个分支是车辆相似度的学习。为了能够学习到更好的特征,在全连接层之后会将属性分类的特征融合到相似度学习分支。融合操作能够指导相似度学习分支聚焦于车辆的特殊特征。并且将相似度学习分支的损失函数设置成人脸识别的ARC Loss(additive angular margin),它能够直接在角度空间中最大化分类界限,如图2 所示。
1.1 ResNet
从经验来看,网络的深度对模型的性能至关重要,当增加网络层数后,网络可以进行更加复杂的特征模式的提取,所以当模型更深时理论上可以取得更好的结果[12-15]。但是随着网络层数的加深,网络的准确度将出现饱和,甚至下降,即网络退化。为了解决上述网络退化的问题,本文采用ResNet 的残差学习结构。残差学习相比原始特征直接学习更容易。残差结构如图3所示。

图2 改进网络整体框架

图3 残差结构
残差表示:

当残差为0 时,此时堆积层仅仅做了恒等映射,至少网络性能不会下降,并且实际上残差不会为0,这也会使得堆积层在输入特征基础上学习到新的特征,从而拥有更好的性能。DRDL 框架使用VGG 网络,远不及本文使用的ResNet-101 网络的深度,所以使用ResNet 在提取特征的阶段比DRDL 原始的VGG 结果更好。ResNet-101 与VGG-19 的网络结构如表1。
1.2 ARC Loss
DRDL 原始损失函数是根据三元损失函数改进而来,不过原先三元损失函数是以“三元组样本点”作为输入数据的,Coupled Cluster Loss(CCL)由两组图像集取代:一组是正样本集,另一组是负样本集。距离测度由原先的随机选择锚点,再计算正样本与锚点之间距离,负样本与锚点之间距离,改为:先计算所有正样本的中心点,再计算正样本到中心点的距离。这个改变的前提是基于一个假设:即正样本应该特征相近,形成一个“聚集簇”,负样本相对较远。改进之后的Coupled Clusters Loss 由多个样本来定义,而不止原先的3 个。

表1 ResNet-101 与VGG-19 的网络结构比较

正负样本相对距离如公式(3):

Coupled Clusters Loss 函数如公式(4):

CCL 是欧氏距离的演变而来,欧氏距离更能体现数值上的相对差异,而再识别需要能在方向上的相对差异表现更好的函数。针对上述CCL 的缺陷,本文采用人脸识别的ARC Loss 损失函数:additive angular margin loss。ARC loss 是在AmSoftmax 演变而来的,ARC loss 与其他损失函数最大不同之处:前者是角度距离,后者是余弦距离,角度距离比余弦距离在对角度的影响更加直接,所以ARC Loss 可以直接在角度空间中最大化分类界限,可以加速函数的收敛。公式如下ARC loss:

相比于Coupled Clusters Loss,Arc Loss 在角度空间中,所以能够更快的收敛,效果优于前者。
2 实验
2.1 数据集
数据集采用VehicleID,以便于与DRDL 框架原始网络进行分析对比。该数据集图片来自现实生活中,是由不同安防摄像头拍摄,为了去除车牌干扰,车牌照均被人工处理。
数据集一共有221763 张图片,总共包含26267 辆车(平均每辆车含有8.44 张图片)。其中10319 辆车被打上了车型的标签,共90196 张图片。数据集分为训练部分和测设部分。训练部分共有110178 张图片含有标签47558 张图片,共包含13134 辆车,测试部分共有111585 张图片含有标签42638 张图片,共包含13133 辆车。如表2 所示。
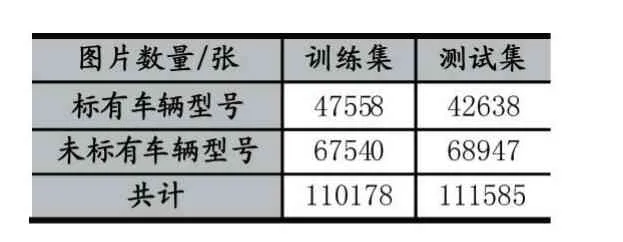
表2 训练集和测试集
为了能够更好地体现测试效果,原测试集太大,所以将其分成大、中、小三个部分分别测试。小测试集含有800 辆车,共7332 张图片,中测试集含有1600 辆车,含有12995 张图片,大测试集含有2400 辆车,含有20038 张图。如表3 所示。

表3 测试数据分类
2.2 结果分析
本实验与文献[1]使用相同的验证方法,训练集和测试集如表3 部分中介绍。
在进行车辆再识别之前,需要对车辆的型号进行验证。该任务主要是验证两张图片中的车辆是否为同一个车型,结果显示本文的方法均有提升,其中小、中、大数据集分别针对原始算法提高了0.144、0.166、0.229,准确率提高的主要原因是本文采用的算法的网络层数更深,能够提取到更多的车辆细节特征。验证结果如表4 所示。

表4 模型的分类预测准确度
为了表明车辆再识别结果的普适性,实验结果如图4,表示为在小数据集的累积匹配曲线(CMC)。因为累积匹配曲线广泛用于再识别领域。表5 显示了与原方法比较的Top 1 至Top 5 的匹配率。由结果可以看出我们的方法优于DRDL 原方法在所有测试集的结果。其中本文算法的Top 1 和Top 5 在小数据集上的结果分别高于DRDL 原始算法0.143 和0.052,主要原因是本文采用的ResNet-101 的网络层数更深,能够提取到比VGG 更多的车辆特征,以及ARC Loss 在车辆相似度估计计算时能够最大化分类界限。
3 结语
本文提出基于DRDL 模型的改进车辆再识别算法,用于提高车辆再识别的准确度。在DRDL 框架结构下用ResNet 作为主干网络,用来提取更多的车辆特征,然后修改原来框架中的Loss 函数,利用ARC Loss进行车辆相似度的估计计算。相比于原始DRDL 算法,本文的算法能够有一个较高的精度,实验结果显示该算法能够有理想的提升。下一步将主要研究如何在保证准确率不降低的同时提高检测速度。

图4 小数据集CMC曲线

表5 车辆再识别匹配率
