人口死亡率数据质量检验新方法及应用
2019-11-16黄荣清曾宪新
黄荣清 曾宪新


摘 要:死亡数据质量的评估是人口死亡分析的第一步。本文从分析人口死亡率随年龄变化的特征着手,提出了分年龄死亡率数据质量的判断方法和指标。运用此方法,对我国自1982年以来四次人口普查的人口死亡率质量进行了分析。研究结果显示,1981年人口死亡数据质量存在比较明显的缺陷;随着年代推移,人口死亡数据质量有所改善;我国人口死亡率在青年期和高龄期普遍存在质量问题;特定尾数年龄的观测死亡率与实际死亡率存在偏离;儿童期数据质量在2010年变差而且城市地区尤为明显。
关键词:数据质量评估;人口普查;死亡率
中图分类号:C92-03 文献标识码:A 文章编号:1000-4149(2019)05-0018-11
DOI:10.3969/j.issn.1000-4149.2019.00.021
一、引言
人口科学往往是从人口死亡的分析开始的,人口死亡水平及其变动一直是人口学研究的核心问题之一。由于数据所限的原因,关于我国人口死亡的研究大都是围绕着几次人口普查数据展开的[1]。为了使人口分析和研究建立在数据可靠的基础上,首先需要对所利用的观测数据的质量进行评估,并对有质量问题的数据作出具体修正。对于人口普查死亡数据质量的研究最早是针对1982年第三次人口普查进行的,研究表明1981年的婴儿死亡数据和老年数据均存在问题[2-3]。之后的研究大多认为总体上来讲第三次人口普查的数据质量比较好,可以直接使用[4-7]。1990年、2000年、2010年的第四、五、六次人口普查数据均存在不同程度的死亡漏报[8-14]。
人口死亡的质量评估可以归纳为两个方面:①总体水平的评估。报告(登记)的死亡人口数有无漏报,导致观测死亡率低于实际死亡率,观测的预期寿命高于实际预期寿命,现有绝大部分死亡数据质量评估的研究属于这一类。②局部数据的评估。观测的死亡率在全年龄或局部年龄是否异常?现有这方面的研究多集中于老年和婴幼儿死亡数据的分析。事实上这两方面是相互联系的,只是由于研究者的视角和所借助的手段不同,通常只对人口死亡数据质量的某一方面进行判断。
从1982年第三次人口普查以来,全国和各地区人口的分年龄死亡率主要是由人口普查结果计算得到的。对死亡率数据的质量,现有研究都只是关于总体水平和婴儿死亡率误差的研究,而对各个年龄死亡率数据的质量做系统深入研究的很少。究其原因,主要是由于方法的限制。现有研究进行人口死亡数据质量评估的基本思路大体上有以下三个:其一是通过人口死亡与经济发展水平的关系来判定所利用数据是否存在质量问题。这种方法比较适用于评估死亡水平和婴儿死亡率数据是否有问题。其二是利用死亡率死亡模式规律以及生命表方法来进行检验和调整。标准生命表通常选择根据1981年死亡数据构造的生命表。其三是通过各次人口普查队列人口的存活关系来判断是否存在死亡漏报的问题。这些方法的缺点是无法对单次普查的死亡数据进行系统地评估。现有关于死亡数据的评估实质是假定某一次的死亡数据质量可以接受(或假定我国的人口死亡符合某一模式),在此基础上对新普查数据进行评估。
本项研究的基本思路是:人口学死亡研究的一个重要结论是人口死亡随年龄变化是有规律可循的。因此,抛开死亡模型和死亡模式,人口死亡数据所反映出来的人口死亡随年龄的变动在方向上应该符合一定的规律。如果数据所反映的人口死亡随年龄的变动违背规律则说明死亡数据存在系统性的质量问题。这一思路的优点在于,它不依赖于其他数据同时也避开了对死亡模式和模型生命表的依赖。
二、人口死亡率的年龄变化
1.死亡率年龄变化的方向
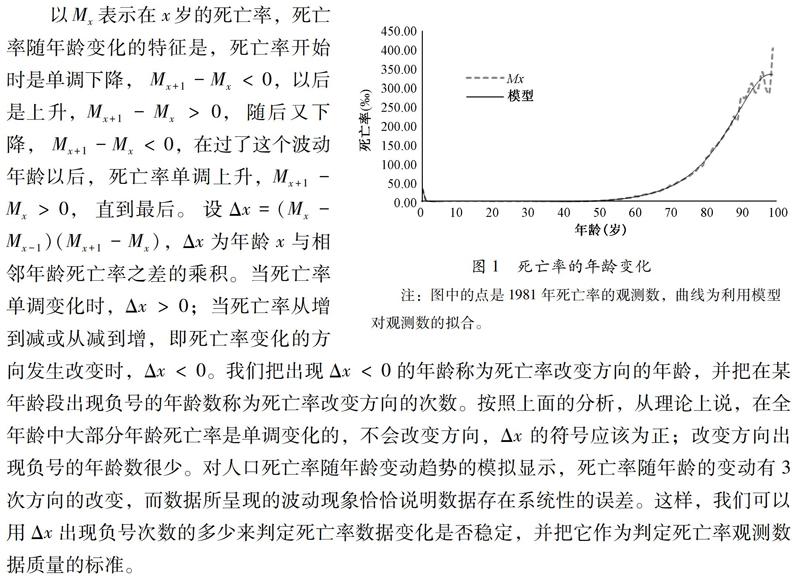
死亡率大小随年龄变化,在高死亡力的场合,婴幼儿死亡率和老年死亡率都很高,死亡率曲线的图形由高到低,再由低升高,所以可以用“U”型来概括;而在低死亡力的场合,婴幼儿死亡率已经不高,但老年死亡率仍旧很高,死亡率曲线的图形开始就不太高,但随年龄增加还是先降低,后升高,可以用“J”型来描述。但这只是从大的变化来说,实际上,在年龄别死亡率由低到高的变化过程中,中间还有一个“波动”存在,这个“波动”的峰值位置和高低在不同时期和地区虽然会有所不同,但根据对现有人口数据的观察,这个“波动”总是存在的,死亡率大小的年龄变化大致呈如下形状(见图1)。
对人口死亡率随年龄变动趋势的模拟显示,死亡率随年龄的变动有3次方向的改变,而数据所呈现的波动现象恰恰说明数据存在系统性的误差。这样,我们可以用Δx出现负号次数的多少来判定死亡率数据变化是否稳定,并把它作为判定死亡率观测数据质量的标准。
从第三次人口普查以来全国人口死亡率的观测数据在全年龄上改变方向的次数如表1所示。
由表1可以知道,全国人口死亡率观测数据改变方向的次数都远不止3次,最多的是由1982年人口普查资料算出的1981年的死亡率,次数较少的是2010年的结果。从男女合计、男性和女性的三个死亡率来看,1990年人口普查的结果死亡率改变方向的次数似乎最少。但由于1990年人口普查公布的死亡人口的最大年龄是截止到90岁,所以只能计算出0—90岁的死亡率。其他三次人口普查死亡人口的最大年龄是截止到100岁。而90—99岁年龄段往往是死亡率改变方向较频繁的区间。若都以90岁作为截止年龄,1981年、2000年、2010年Δx<0的次数分别为20次、13次和7次。所以,从死亡率年龄变化的稳定性来说,死亡率数据的质量是在提高的,2010年人口普查的死亡率质量较高。
这里应該注意的是,男女合计的死亡率改变方向的次数可以小于或大于单独的男性或女性死亡率改变方向的次数,或介于这两者之间。
2.死亡率改变方向的年龄
仍以1981年男女合计的观测死亡率为例,来说明判定观测死亡率改变方向的年龄特征。表2中“+”号表示Δx>0,“-”号表示Δx<0。
由表2可知,在年龄区间1—19岁和35—85岁,Δx符号改变的次数很少,在1—19岁,“-”号只在12岁上出现了一次,说明从12岁开始,死亡率由从高到低转到从低到高,完全符合死亡率大小随年龄变化的规律。从35岁以后,死亡率应该单调上升,所以应该是“+”号,这也是基本符合的。“-”号出现在几个以“0”为尾数的年龄上,说明在这些年龄上,死亡率数据还是有问题的。表2显示“-”号主要分布在20—34岁和85岁以上,即在青年期(见图2)和高龄期(见图3)这两个年龄区间,数据变化很不稳定,数据质量不好。
由表2的纵向来看,“-”号次数在各个年龄尾数上并不是均匀分配的。 出现“-”号次数最多的是以“1”和“0”为尾数的年龄,其次是以“2”、“3”、“8”、“9”为尾数的年龄。这说明,数据质量出现问题是以“0”、“1”年龄尾数为中心展开的。
3.死亡率大小改变的速度
我们再换一个角度来讨论死亡率随年龄变化的特征。令:
由表3可以发现,在1—13岁,δx>0, 表示死亡率加速下降,与理论相符。在以后的年龄,δx几乎是正负相间,即加速后减速再加速。在“0”、“2”、 “8”的尾数上,δx<0分别出现了8次、7次、7次,说明这些年龄是死亡率速度变化的分界,死亡率常常大于它左右两边的平均值。在“1”、“7”、“9”的尾数上,δx>0分别出现了10次、9次和8次,说明死亡率往往小于它左右两边的平均值。再从数值上看,以“0”、“9”、“1”为尾数的年龄的绝对值大,说明在这些尾数年龄上,死亡率大小的变化最显著。
从理论上说,如果一条曲线在区间内是连续光滑(二阶可导)的话,函数的图形会保持一致,年龄x的函数值与它左右两边函数平均值之差应该保持同一符号,当δx>0时为上凹,當δx<0时为上凸,在符号改变时会出现拐点。死亡率函数虽然不是连续函数,但从死亡率的变化规律和图形上可以知道,在儿童年龄段,它会保持加速下降,图形上凹,而在成年(35岁)后,几乎呈直线,其实也是上凹。
只是在青年期,才出现上凸的情形,这个年龄期的δx小于0(参考图1)。
当然,人口死亡数据只是死亡率的统计值而非实际死亡率,而统计值一定会出现随机误差。但由于中国人口的基数极大,死亡率的随机误差极小,变化幅度极小关于死亡率与调查人口的关系、随机误差的计算,参见:蒋庆琅.寿命表及其应用[M].上海:上海翻译公司,1984:49-50。 。而δx的观测值的符号出现这样的年龄分布规律,且有较大幅度的变化(在5%以上),就是以说明观察数据存在系统误差,同时可以推断,出现δx<0并且在“0”、“2”、“8”的尾数年龄上,观测死亡率通常会大于实际死亡率。而在“1”、“7”、“9”的尾数年龄上,观测死亡率通常会小于实际死亡率。
δx的符号变化和分布可以用来表示死亡率曲线的形状变化,所以它也可以用来判断死亡率观测数据的质量。一般来说,在一定的年龄区间内,δx的符号变化越多,图形就越不规则。出现δx<0的年龄,是死亡率随年龄变化速度的转折点,我们把全年龄δx<0 出现的次数作为判断数据质量的指标。由表3的数据可知,δx<0 共出现了41次,说明观测年龄死亡率与实际死亡率存在误差比较普遍。
综上所述,我们提出可分别用Δx出现负数的次数和δx的分布来检验年龄别死亡率观测值的质量。虽然检验的目标只有一个,即检验观测值是否和实际值(或者说真值)之间存在系统偏差,但由于Δx和δx 表示的意义不同,检验的侧重点和适用范围也不同。
从本质上来说,Δx和δx分别通过检验死亡率随年龄变动的方向和变动的凸凹特性是否吻合规律来判定数据的质量。一般来说,死亡率变化方向及其改变次数在理论上是比较确定的。Δx小于0出现一次,就意味着死亡率变化方向改变一次,所以用Δx检验比较可靠。但是这种方法的缺点是不够灵敏,只有观测死亡率误差达到一定程度才会改变实际死亡率原来的方向。另外,Δx的符号是根据连续三个年龄的变化来设的,所以,它比较适合于一定的年龄区间。理论上,青年期和高龄期人口死亡率的变动都有可能出现凸凹性的改变,即δx 小于0的情况。而且这两个时期区间的端点也不确定,所以δx出现负数的理论次数并不确定。因此,我们就不能单纯地根据δx出现负数的次数来确定数据的质量。但相邻年龄的死亡率变动波动(凸凹性)比死亡率变动方向的改变更为频繁,因此δx 对数据比较敏感。尽管凸凹性改变没有理论上的次数可以参照,但有一点是确定的,凸凹性的改变不应该有系统的年龄尾数特征,因此它在检验是否存在年龄尾数的指向上比较有效。两个指标各有所长,可以用于不同目的数据质量的甄别。
以下我们主要以Δx来判断某个年龄区间,或全年龄的观测数据的质量,而以δx来判断年龄尾数上的数据质量问题。
三、各次普查观测死亡率的质量比较
根据Δx出现“-”号的次数和分布,δx的符号、分布及绝对值大小,对各次普查死亡率的年龄误差可做如下归纳。
1.各次普查的比较
上面已详细列举了1981年死亡率数据的质量情况,这里不再重复,下面是1982年以后各次普查死亡率数据的质量情况。
1990年与1981年死亡率数据类似,Δx<0主要出现在青年期(21—30岁),共出现了8次(全部为11次),说明在这一时期的年龄数据质量是有问题的。从δx的值来看,“+”、“-”号在各年龄尾数上也没有太大的偏离,说明年龄别死亡率数据质量尚好。但应注意的是,1990年普查没有对90岁及以上的死亡作分年龄统计,而这个年龄段的数据质量往往是最容易出问题的。
2000年,Δx<0主要出现在25—36岁,共出现了8次(全部为21次),在高龄期96—98岁的3个年龄上,Δx的符号都为负,说明95岁以上的死亡率数据质量有明显问题。在年龄尾数上,以“0”为尾数的δx值都小于0,而以“1”、“9”为尾数的年龄δx值都大于0。可以推测以“0”为尾数的观测死亡率大于实际死亡率,而以“1”、“9”为尾数的年龄观测死亡率可能要小于实际死亡率。
2010年,总的来说,Δx<0出现的次数较少,只有9次,但出现的年龄与以往不同,主要出现在7—12岁,共出现了5次,说明在儿童期观测死亡率的质量有问题。另外4次,Δx<0的年龄为25岁、26岁、96岁、98岁。从δx的符号看,在以“0”、“2”为尾数的年龄上,δx大多为负,而在以“1”、“9”为尾数的年龄上,δx大都为正。可以认为在这些年龄,死亡率数据的质量有问题。
2.性别差异
从表1可知,1981年Δx<0出现的次数,女性多于男性,说明女性死亡率的数据质量比男性要差,但以后几次普查,Δx出现负号的次数,男性和女性就比较接近,说明两者的数据质量已比较接近。
从1981年的数据看,男性死亡率Δx出现负号主要在20—31歲,共出现了10次,其次是88—97岁,出现了8次;女性死亡率Δx出现负号主要在20—33岁,共出现了12次,其次是88—98岁,出现了9次;从尾数指向上看,男性δx出现负号主要是在 “8”、“0”、“2”的尾数上。在“7”、“9”、“1”的尾数上δx大多大于0,从绝对值来看,以尾数“0”和“1”为大。
1990年,男性和女性Δx出现负号都主要在21—38岁,共出现了10次(全部为11次),说明在这个年龄段,死亡率的大小变化反复,数据质量有问题。但δx的符号没有明显的尾数指向。这个特征和1981年有明显的不同。
2000年,男性和女性Δx<0主要出现在21—39岁,分别出现了10次和11次。
从δx值来看,在“0”和“2”的尾数上,δx的值小于0,而在“9”、“1”和“3”的尾数上,δx的值较多的大于0,且在“0”和“1”尾数上δx的绝对值大于临近年龄δx的绝对值。
2010年,男性Δx出现负号的年龄区间主要在5—13岁,共出现了7次。女性在7—10岁出现了4次,在14—19岁出现了5次,在25—28岁出现了4次,以上三个年龄段出现负号共13次,占了负号出现次数的大部分(共15次)。从δx的值来看,男性和女性都在“0”、“5”的年龄尾数上多数为负,在“1”、“6”、“9”尾数上则大多为正。
3.城乡差别
对1982年、1990年、2000年三次人口普查的数据检验结果显示,县(乡)人口死亡数据的Δx出现负号要多于市镇,说明县(乡)人口死亡率的质量要比市镇差,这似乎也很好解释;而在2010年,却出现了逆转,市镇人口死亡率的Δx<0出现的次数多于县(乡),其原因需要进一步解释。
1981年,市镇人口死亡率的Δx出现“-”号的次数主要在20—33岁,出现了10次,在93岁及以上出现了5次(全部共16次)。县(乡)人口死亡率的Δx出现“-”号的次数主要在20—33岁,出现了12次,在88岁及以上出现了9次(全部共26次)。可见,城乡人口死亡率数据在青年期、高龄期质量有问题,但县(乡)人口死亡数据在老年期问题更大一些。从δx的符号和数值来看,市镇人口死亡率有明显的尾数指向,在“0”为尾数年龄上都是负数,在“1”、“9”的尾数年龄,大多为正值。县(乡)人口死亡率尾数指向更明显,在“0”、“2”、“8”为尾数年龄上大多是负数,在“1”、“7”、“9”的尾数年龄,大多为正值,与市镇相比,δx的绝对值也更大,说明偏离更为严重。
1990年,市镇人口死亡率的Δx出现“-”号的次数主要在20—33岁,出现了8次(全部共9次)。县(乡)人口死亡率的Δx出现“-”号的次数主要在21—33岁,出现了10次,(全部共13次)。从δx的值来看,尾数指向不显著。但在“0”、“9”的尾数上,负数出现略多一些,而在“1”、“4”、“6”的尾数上,正数要多一些。
2000年,市镇人口死亡率的Δx出现“-”号的次数主要分布在6—10岁(4次),25—33岁出现了6次,在95岁及以上出现了4次(全部共19次)。县(乡)人口死亡率的Δx出现“-”号的次数在9—12岁(3次),在19 —37岁出现了12次,在93岁及以上出现了6次(全部共25次)。可见,城乡人口死亡率质量问题主要在青年期和高龄期。从δx的符号和数值上来看,市镇人口死亡率有明显的尾数指向,在“0”为尾数年龄上都是负数,在“1”,“9”的尾数年龄,都为正值。县(乡)人口死亡率在“0”、“2”、“5”为尾数年龄上大多是负数,在“1”、“6”、“9”的尾数年龄,大多为正值。
2010年,市镇人口死亡率的Δx出现“-”号的次数主要分布在6—9岁(3次),12—19岁出现了6次,24—30岁出现了4次,在95岁及以上出现了2次(全部共15次)。县(乡)人口死亡率的Δx出现“-”号的次数主要在8—13岁(3次),19—26岁出现了5次,在96岁及以上出现了2次(全部共11次)。可见,城乡人口死亡率的数据质量问题在儿童期、青年期、高龄期都有。从δx的符号和数值来看,市镇人口死亡率有一定的尾数指向,在“0”为尾数年龄上大多是负数,在“1”、“9”的尾数年龄,大多为正值。县(乡)人口死亡率的尾数指向与市镇类似, 比较城乡Δx的符号分布可以看出,在儿童期和青年期,市镇出现负号次数要明显地多于县(乡)。这大概是由于城乡人口迁移和流动加速,死亡报告在居住地和户籍所在地不明确造成的。
四、误差的产生来源
由以上的分析我们知道,中国人口死亡率的观测数据普遍存在以下问题:
①在青年期和高龄期,死亡率数据高低变化不稳定;②死亡率变化有特定期尾数指向,以 “0”为尾数的年龄观测死亡率往往高于实际死亡率,以“1”、“9”为尾数的年龄观测死亡率常常低于实际死亡率。
对于第一个问题,似乎可以用被调查者的年龄误报来解释。在20—30岁期间,是个人面临升学、就业、婚姻等重要人生大事的关键时期, 而年龄通常和人的利益有关,因而导致了这一时期的年龄误报;到老年期,尤其是高龄期,一些老年人因记不清自己的确切年龄而出现误报。
死亡率大小的年龄尾数指向显然也是和被调查者的年龄尾数指向有关。但对各次人口普查数据质量检验表明,人口年龄数据并没有明显的尾数指向。那么,如何解释死亡率的观测数据出现的这种尾数指向呢?
这可以从我国人口死亡率数据的获取途径来解释。
在发达国家,人口死亡率是个动态指标,它的数据获取主要是基于人口登记资料计算得到的。 而在我国,人口死亡率是根据人口普查资料计算得到的。
死亡率Mx是同期的死亡人口 Dx与平均人口Px之比,死亡率的数据质量通常取决于人口报告数据和死亡人口报告数据的质量。但在实际统计工作中,无论是人口登记还是人口普查,其数据总会存在一定的误差,即使通过了“无特定的年龄尾数指向”检验,也并不表明人口报告数据的“年龄尾数指向”完全不存在,只是说明存在的“年龄尾数指向”问题可能并不显著罢了。
當死亡率是基于人口登记资料计算得到时,死亡人口与人口的年龄在时间上是一致的,即使有一定的年龄指向存在,由于是比的关系,算出的死亡率可能也不会受太大的影响。如假定死亡人口和人口在某个年龄同时多登记了5%。因为Mx=Dx/Px, 所以计算的死亡率不会受影响。
当死亡率是基于人口普查资料得到时,就会出现不同的情况:同年龄的死亡人口与人口在时间上是不一致的,例如在1982年的第三次人口普查时,调查的是1981年的死亡人口。为了确定1981年死于x岁的人口死亡率,需要根据普查(1982)时x+1岁人口来推算。即在测定死亡率时,分子和分母用的是相邻的两个不同年龄尾数的对象人口,而相邻的年龄尾数指向的方向往往是相反的。例如,在“0”的尾数上,人口往往出现多报的现象,造成报告人口多于实际人口,而相邻的“1”的尾数上,人口往往存在少报的问题,造成报告人口少于实际人口。作为分子的死亡人口多报(或少报),而作为分母的人口少报(或多报)时,这就使原来不显著的误差得到了加强,例如以“0”为尾数的年龄的死亡人口多报了5%,以“1”为尾数的年龄的人口少报了5%,在计算以“0”为尾数的人口死亡率时,观测死亡率的误差就会扩大到10%。
已有研究普遍认为第三次(1982年)的人口普查质量要高于后几次人口普查。但从年龄别死亡率上说,上面的研究表明,由第三次人口普查资料计算的死亡率要比后面几次普查的质量要差。这是因为第三次普查计算的1981年某年龄(x岁)的人口死亡率,是根据普查(1982年)x+1岁的人口死亡率来推算的。而后几次人口普查,计算的是普查前1年的x岁死亡率,但用作推算的x岁的平均人口,一半是和死亡人口同年龄同期的人口,这大概就是年龄别死亡率误差相对较小的原因。
五、结论与建议
本文通过分析死亡率年龄变化的特征,从死亡率变化方向和变化速度两个方面提出了判定数据质量的方法和检验指标。对四次人口普查死亡率的观测数据的检验结果表明:①我国人口死亡率在青年期和高龄期普遍存在质量问题,表现为死亡率常改变方向;在以“0”为尾数的年龄,观测死亡率往往会高于实际死亡率,而在以“1”、“9”为尾数的年龄,观测死亡率往往会低于实际死亡率。②随着年代推移,死亡数据的质量有所改善,城乡、男女之间的差别缩小。③出现了新问题。儿童期数据质量在2010年以前较好,2010年数据明显变差,尤其是在城市。
死亡数据质量问题的产生,主要源于我国获得死亡人口数据的途径。由于死亡人口是由普查数据获得的,在计算死亡率时同一年龄的人口和死亡人口不同期,需要用下一个年龄的人口来估计,从而导致原来并不显著的年龄尾数误报被扩大。而儿童期和青年期死亡数据质量问题的产生,部分原因是流动人口的户籍地和常住地不一致,从而导致了漏报和误报的产生。
人口死亡本来是人口动态统计,其数据应该由人口日常登记资料来获得。我国现在主要依靠人口调查来获得,导致了许多问题的产生。所以,改变现行的统计方法,完备人口统计制度是提高人口死亡率数据质量的最有效途径。
这里要说明的是,文中讨论的年龄别死亡率的误差,从绝对值来说,其实是很小的(参考图1)。
但从理论上以及实际应用时(特别是在类似于保险等精算研究中),对有问题的数据进行修正是必要的。
参考文献:
[1]游允中.人口死亡研究和死亡数据[J].市场与人口分析,2006(6):19-21.
[2]达德利·鲍思顿. 中国婴儿死亡率模式[J]. 人口研究,1991(3): 29-35.
[3]COALE A J, LI S. The effect of age misreporting in China on the calculation of mortality rates at very high ages[J]. Demography, 1991,28(2):293-301.
[4]游允中.1982 年中国人口普查的可信度[J].人口与经济,1984(6):11-18.
[5]李树茁. 80年代中国人口死亡水平和模式的变动分析——兼论对1990年人口普查死亡水平的调整[J]. 人口研究,1994(2):37-44.
[6]黄荣清. 中国80 年代死亡水平研究[J].中国人口科学,1994(3):1-11.
[7]张二力,路磊. 对中国1990年人口普查成年人口死亡登记完整率的估计[J]. 中国人口科学,1992(3):27-29.
[8]翟振武. 1990年婴儿死亡率的调整及生命估计[J]. 人口研究,1993(2):9-16.
[9]李南,孙福滨. 死亡漏报的一种新的估计方法[J]. 人口研究,1994(5): 38-43.
[10]黄荣清,曾宪新.“六普”报告的婴儿死亡率误差和实际水平的估计[J]. 人口研究,2013(2): 3-16.
[11]马京奎. 2000 年人口普查国家级重点课题研究报告[M]. 北京: 中国统计出版社,2005:240-249.
[12]王金营,戈艳霞. 2010年人口普查数据质量评估以及对以往人口变动分析校正[J]. 人口研究,2013(1):22-33.
[13]赵梦晗,杨凡. 六普数据中婴儿死亡率及儿童死亡概率的质疑与评估[J]. 人口研究,2013(5): 68-80.
[14]孙福滨,李树茁,李南. 中国第四次人口普查全国及部分省区死亡漏报研究[J]. 中国人口科学,1993(2):20-25.
[责任编辑 武 玉]
