基于自适应锚定邻域回归的图像超分辨率算法
2019-11-15叶双杨晓敏严斌宇
叶双 杨晓敏 严斌宇

摘 要:在基于字典的图像超分辨率(SR)算法中,锚定邻域回归超分辨率(ANR)算法由于其优越的重建速度和质量引起了人们的广泛关注。然而,ANR算法的锚定邻域投影并不稳定,以致于不足以涵盖各种样式的映射关系。因此提出一种基于自适应锚定邻域回归的图像SR算法,根据样本分布自适应地计算邻域中心从而以更精确的邻域来预计算投影矩阵。首先,以图像块为中心,运用K均值聚类算法将训练样本聚类成不同的簇;然后,用每个簇的聚类中心替换字典原子来计算相应的邻域;最后,运用这些邻域来预计算从低分辨率(LR)空间到高分辨率(HR)空间的映射矩阵。实验结果表明,所提算法在Set14上平均重建效果以31.56dB的峰值信噪比(PSNR)及0.8712的结构相似性(SSIM)优于其他基于字典的先进算法,甚至胜过超分辨率卷积神经网络(SRCNN)算法。同时,在主观表现上看,所提算法恢复出了尖锐的图像边缘且产生的伪影较少。
关键词: 图像超分辨率;自适应聚类;自适应邻域;K均值聚类算法
中图分类号:TP391.41
文献标志码:A
Abstract:Among the dictionary-based Super-Resolution (SR) algorithms, the Anchored Neighborhood Regression (ANR) algorithm has been attracted widely attention due to its superior reconstruction speed and quality. However, the anchored neighborhood projections of ANR are unstable to cover varieties of mapping relationships. Aiming at the problem, an image SR algorithm based on adaptive anchored neighborhood regression was proposed, which adaptively calculated the neighborhood center based on the distribution of samples in order to pre-estimate the projection matrix based on more accurate neighborhood. Firstly, K-means clustering algorithm was used to cluster the training samples into different clusters with the image patches as centers. Then, the dictionary atoms were replaced with the cluster centers to calculate the corresponding neighborhoods. Finally, the neighborhoods were applied to pre-compute the projection matrix from LR space to HR space. Experimental results show that the average reconstruction performance of the proposed algorithm on Set14 is better than that of other state-of-the-art dictionary-based algorithms with 31.56dB of Peak Signal-to-Noise Ratio (PSNR) and 0.8712 of Structural SIMilarity index (SSIM), and even is superior to the Super-Resolution Convolutional Neural Network (SRCNN) algorithm. At the same time, in terms of the subjective performance, the proposed algorithm produces sharp edges in reconstruction results with little artifacts.
Key words: image super-resolution; adaptive clustering; adaptive neighborhood; K-means clustering algorithm
0 引言
圖像的超分辨率(Super-Resolution, SR)技术是一种由软件实现的,以提高图像分辨率,丰富图像细节信息为目的的技术。目前图像超分辨率技术已广泛应用于很多领域中,如安全监视[1]、刑事调查[2]、卫星遥感[3]和医学诊断[4]等。
由于高分辨率(High-Resolution, HR)图像可以提供比低分辨率(Low-Resolution, LR)图像更多的细节信息,因此在实际生活中被迫切需要。然而,由于低分辨率图像产生的复杂性,且从低分辨率图像映射到高分辨率图像的过程在大多数情况下都是不可逆的,因此如何由已知的低分辨率图像得到未知的高分辨率图像是一个高度病态求解的问题。近年来,人们针对这一问题广泛研究了许多图像超分辨率算法,这些算法大致可以分为如下三类:基于插值的图像超分辨率算法[5-11]、基于重建的图像超分辨率算法[12-17]和基于学习的图像超分辨率算法[18-28]。
基于插值的超分辨率算法通常采用某些插值函数来根据已知的低分辨率像素值估计相应的高分辨率像素值。这一类算法不需要借助额外的数据进行重建,且实现非常简单。虽然传统的插值算法如双三次或双线性插值由于其计算复杂度低而被广泛应用,但其恢复出来的高分辨率图像的细节相对模糊。并且,由于這一类算法仅仅只能利用有限的信息来估计未知信息而不能显著增加图像信息,因此随着放大系数的增加,估计出的重建图像效果会越来越差。
为了能利用更多的图像信息,基于重建的图像超分辨率算法使用了同一场景的多幅低分辨率图像来重建高分辨率图像。与基于插值的算法相比,基于重建的图像超分辨率算法实质上增加了重建中所需的信息,因此也实现了相对基于插值的超分辨率算法更好的结果。但是,该类算法的缺点也很明显:首先,人们难以获得多个在相同场景下的低分辨率图像,这从很大程度上限制了该类算法的应用;其次,基于重建的算法的重建性能通常在一定放大倍数后会受到制约;第三,由于相同场景下不同低分辨率图像间存在像素偏移,因此在进行特征预提取时需要先进行图像配准,而图像配准的过程对一些失真严重的图像来说十分困难。
基于学习的图像超分辨率算法利用图像的先验知识来重建高分辨率图像。该类算法在学习阶段预先学习好高分辨率图像块与相应的低分辨率图像块之间的映射关系,在重建阶段通过学习到的映射关系生成具有更精细细节的高分辨率图像。为了有效利用图像间的不同假设和先验知识,研究人员先后提出了几种基于学习的图像超分辨率算法:
基于邻域嵌入(Neighbor Embedding, NE)的超分辨率算法假设每个输入的低分辨率图像块及其对应的高分辨率图像块位于具有相似局部几何的低维非线性流形上[26],进而通过流形关系进行重建。基于局部线性嵌入(Locally Linear Embedding, LLE)的超分辨率算法假设不同放大尺寸的图像块共享相似的流形几何结构,因此高分辨率图像块可以通过流形关系所匹配到的低分辨率图像块来进行重建[24]。然而,流形假设往往在实践中并不精确,因此重建结果通常并不理想。为了克服这个缺点,Yang等[19]提出了一种基于稀疏编码(Sparse Coding,SC)的图像超分辨率算法,通过学习到的高低分辨率词典的稀疏系数来构建高低分辨率空间中图像块之间的对应关系,进而重建出高分辨率图像。基于稀疏编码的图像超分辨率算法主要瓶颈是其较高的计算复杂度,目前,研究人员针对这一问题提出了许多降低计算复杂度的解决方案[20-21]。文献[29]将改进的K-SVD(K-Single Value Decomposition)和OMP(Orthogonal Matching Pursuit)算法引入基于稀疏编码的图像超分辨率算法中,在维持一定重建性能的同时,对训练词典的过程以及重建过程进行加速。随后,Timofte等[20]提出了锚定邻域回归(Anchored Neighbor Regression, ANR)算法,
由于从低分辨率到高分辨率图像的锚定线性回归量(投影矩阵)可以离线计算,一旦学习了映射关系,就可以实时重建高分辨率图像。因此,ANR算法在取得优越的重建效果的同时也实现了极快的重建速度。ANR算法仅关注于从过完备字典中实现锚定邻域的投影,然而,一组过完备字典并不能覆盖各种形式的映射关系,因此在一定程度上限制了ANR算法的应用。
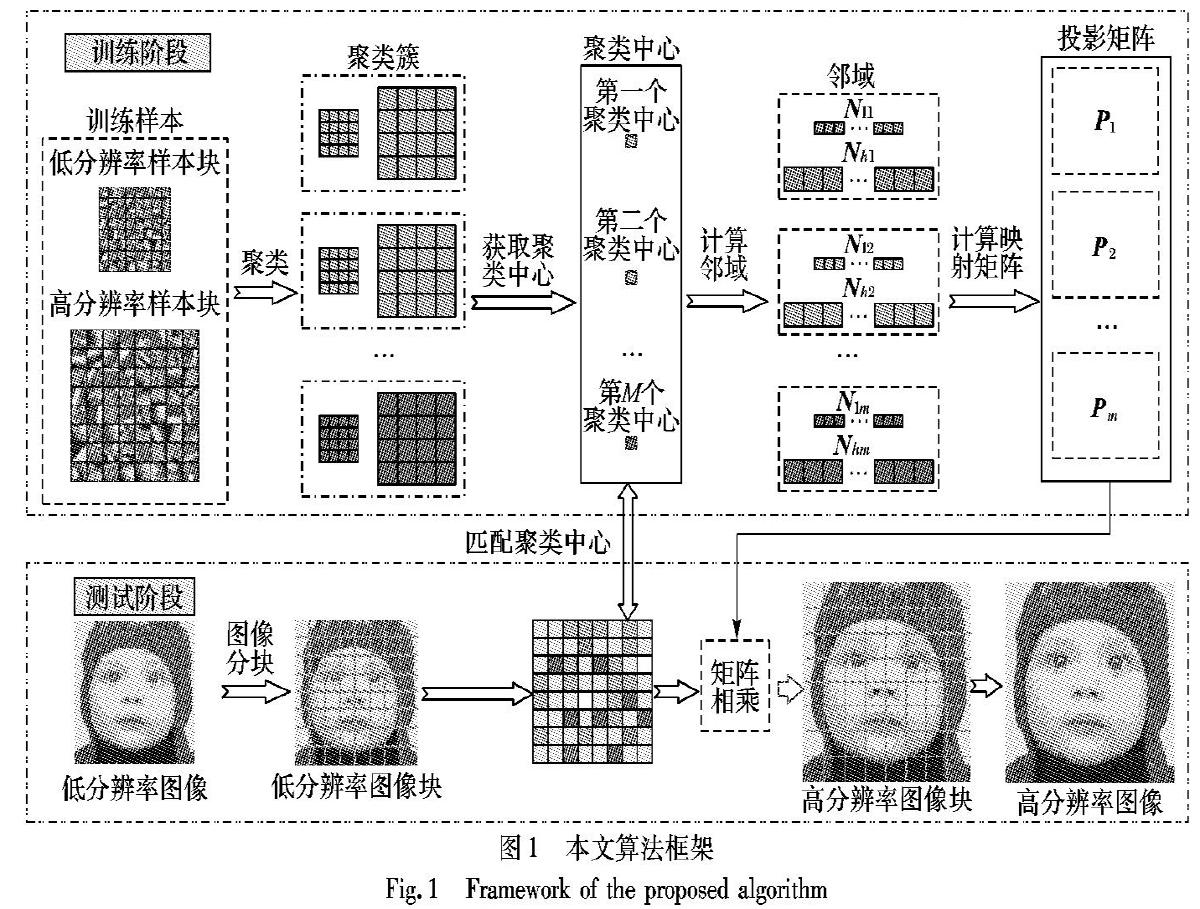
为解决ANR算法中邻域不精确问题,本文提出了一种基于自适应锚定邻域回归的图像超分辨率算法,根据样本分布来自适应地选择邻域。本文算法的大致流程简述如下:首先,模糊并下采样高分辨率图像块以得到高、低分辨率训练样本对;然后,应用K均值聚类算法将高、低分辨率图像块分成不同的簇组,再由各簇组的聚类中心和高低分辨率字典原子的关系来构建邻域;最后,将这些邻域用于预计算精确的锚邻域投影(回归量),并用于重建高分辨率图像。本文主要工作如下:
1)使用K均值聚类算法将图像块聚类成几个不同的簇来重新分配样本空间,然后用聚类中心替代ANR算法中的字典作为锚点来计算邻域。
2)用欧氏距离来重新计算每个聚类中心的邻域,然后将这些邻域应用于计算离线存储的投影矩阵(回归量)。由于聚类中心是根据样本分布形成的,因此本文算法可以实现邻域的自适应。
1 锚定邻域回归算法
ANR算法的核心是假设字典中的每个原子都可以由其最近的邻域线性表示,因此,相同的表示系数可用来重建其高分辨率图像。ANR算法使用与文献[29]中相同的一组外部字典,且称低分辨率稀疏词典原子为锚点。然后,使用式(1)从一组学习字典中稀疏地重建高分辨率图像:
其中:Dl和Dh是联合学习的稀疏字典;Y和X是待训练的高低分辨率图像块对;Z为稀疏表示系数;φ为加权因子。字典D大小固定,不会随着训练数据库的增加而产生很大变化。
ANR算法首先将超分辨率问题定义为一种岭回归问题,进而由岭回归的闭式解可以求解出低分辨率图像邻域与高分辨率图像邻域之间的相互关系,进而重建出高分辨率图像。具体来说,对于每个字典原子,ANR算法首先计算离其最近的K样本图像块作为其邻域。然后,通过优化低分辨率图像块来获得相应的高分辨率表示系数。上述过程可以表示为:
其中:Nl表示根据样本图像块计算得到的邻域,其对应于邻域嵌入中的输入图像块Y的K个最近邻,以及稀疏编码和全局回归(Global Regression, GR)[20]中的低分辨率字典Dl;λ为正则项;α是用于重建高分辨率图像块的系数向量。式(2)的闭式解为:
求解得到的系数α可进一步用来计算高分辨率图像块:
其中:Nh表示对应于Nl的高分辨率图像块邻域。由式(3)~(4)可以归纳出重建阶段所使用的投影矩阵。由于投影矩阵与重建过程中的低分辨率图像无关,因此投影矩阵可以离线计算:
整个ANR算法的重建过程只需通过计算一组矩阵乘法就可以得到解决:将预先计算好的回归量PG与低分辨率输入图像块Y相乘,就可以得到其对应的高分辨率图像块X。
根据上述推导,ANR算法可以分别从训练阶段和重建阶段来确定锚点。在训练阶段,ANR算法将每个字典原子作為划分邻域的中心,使用余弦距离计算离字典原子(即划分邻域的中心)最近的样本来作为其邻域。在重建阶段,对于输入的低分辨率样本块,ANR算法根据相关性匹配出与其最相关的字典原子,并使用该原子存储的投影矩阵来生成高分辨率图像块。然而,由于字典原子并不能准确地由其固定尺寸的邻域来进行表示,导致样本空间的不精确划分。因此,本文提出了一种自适应方式的算法来确定邻域并用自适应邻域重建高分辨率图像。具体地,对于每个训练样本块,计算离它最近的K个图像块作为其邻域,并且将每个图像块本身作为其邻域分组的中心。
2 本文算法
本文算法包含四个关键步骤:1)选择Yang算法[19]中用于训练稀疏字典对的样本作为本文的训练样本,并根据样本的自相似性将训练样本聚类成若干簇;2)对于每个簇的聚类中心,找到离其最近的K个图像块作为其邻域;3)使用目标邻域离线计算投影矩阵;4)利用预先计算的投影矩阵重建高分辨率图像块。
本文框架如图1所示。
2.1 训练样本的选择
本文选取Yang算法[19]中用于训练稀疏字典的训练样本来进行聚类,由于本文使用聚类中心来替换ANR算法中的字典原子作为中心进而来计算邻域,因此在本文算法中不需要用到字典。
2.2 图像块聚类
与SC和GR方法相同,本文选择整个字典来获取最终的高分辨率图像块。
然而,原子周围的局部流形更能由内部的密集样品而非一组外部临近原子来表示。
因此,用聚类中心的邻域替换整个词典来重建高分辨率图像块是很有必要的。特别地,本文将训练样本图像块聚类成不同的簇,用聚类中心作为邻域中心来重新分割样本空间。具体而言,对于第i个聚类中心mi,本文选择离其最近的K个图像块作为其邻域Nil,相应地,对应的高分辨率邻域Nih也可以获得。低分辨率邻域Nil及其高分辨率邻域Nih构成第i个聚类对,并代表低、高分辨率邻域之间的对应关系。由于本文算法是根据训练样本的分布自适应地获得聚类中心,因此可以更精确地划分样本空间,从而提升重建效果。
2.3 投影矩阵计算
如第1章所述,ANR算法在重建速度方面取得了显着成就,因此,在本文算法中将继续沿用这一优势。对于第i个低分辨率聚类中心mi,本文使用式(6)计算投影矩阵Pi:
其中:Nil表示第i个聚类中心在低分辨率空间的邻域;Nih是其对应在高分辨率空间的邻域。
2.4 高分辨率图像块重建
在重建阶段,对于给定的低分辨率图像块yi,在训练样本库中选择离其最近的聚类中心mi并计算相应的投影矩阵Pi。然后,待重建的高分辨率图像块xi可以通过与ANR算法相同的方式获得,xi= yiPi。因为已经在训练阶段获得并存储了所有锚点及其投影矩阵,所以超分辨率过程的计算成本可以得到显著降低。
本文算法通过用聚类中心替换ANR算法中的字典原子作为锚点来获得邻域,并且基于聚类中心来搜索适当的邻域大小以获得最终精确的高分辨率图像块。
邻域大小(数量)对重建效果的影响将通过实验进行分析讨论。
简而言之,本文算法能自适应地选择基于样本的邻域,更合理地选取锚点从而更精确地表示图像,因此可以获得优于其他先进算法的重建效果。
3 实验与分析
3.1 数据集
在本节中,通过与先进算法进行比较来验证所提出的图像超分辨率算法的有效性。为公平比较,本文选择与Yang算法[19]和Zeyde算法[29]相同的训练集,该训练集包含91张高分辨率图像。本文使用下采样系数×3对高分辨率图像进行下采样,并且通过双三次插值生成具有相同大小的低分辨率图像以构建高、低分辨率字典对,该字典对应用于所有参与比较的基于稀疏编码的超分辨率算法。本文选择了两个常见的数据集Set5[29]和Set14[30]用来测试,分别包含5和14张RGB图像。
3.2 参数设置
本文的参数沿用ANR算法中的设置:锚点数为1024,低分辨率和高分辨率图像的训练样本数为500000,放大因子为3,归一化因子λ为0.1。此外,本文将聚类簇数量设置为1024。所有实验都在具有Intel Core i5-6400和8GB RAM的Windows 7(64位)上进行。
3.3 参数灵敏度
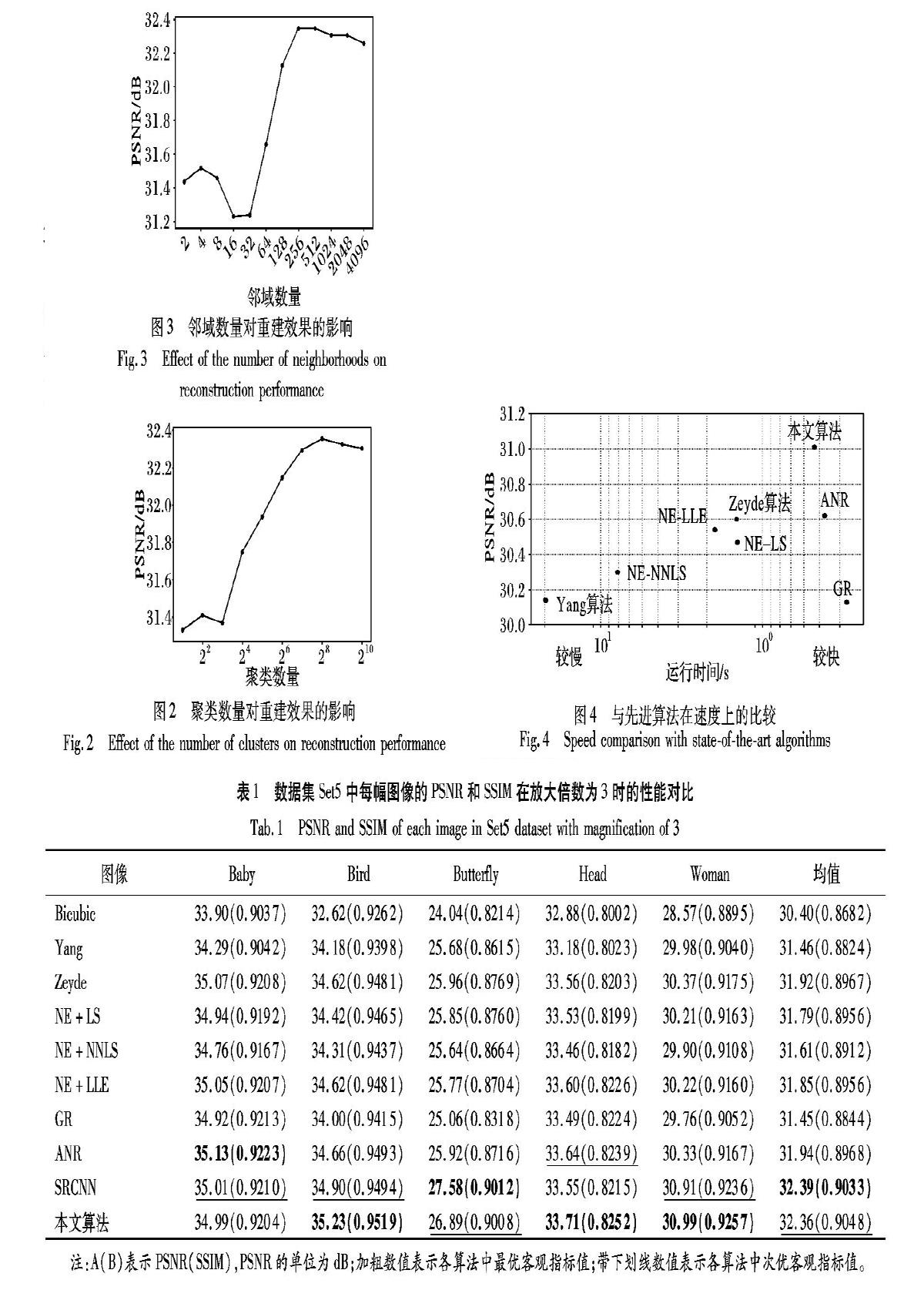
3.3.1 聚类数量对重建效果的影响
本文设置了不同的聚类数量来进行广泛的实验,以此来验证本文算法在不同簇数下的性能。图2显示了不同聚类数量下本文算法在数据集Set5上的平均峰值信噪比(Peak Signal-to-Noise Ratio, PSNR)值。从图2可以看出:当放大簇数直到值达到峰值256时,PSNR值增加,当簇数超过256后PSNR值开始减小。因此,对本文算法256为最佳聚类数量。为了公平地与其他先进方法算法进行比较,本文在实验中沿用ANR算法中的字典大小1024作为聚类数量。越大的聚类数量可以涵盖更多图像隐含的映射关系,进而可以越精确地对重建图像块进行越精细的表征。但是,在一定的训练图像规模下,随着聚类数量的增多,每一簇所含的样本量会逐渐地减少,进而在重建时对图像的表征不是很完全而导致重建性能的降低。
3.3.2 邻域数量对重建效果的影响
由之前的陈述可知,从理论上讲,邻域数量越多重建高分辨率图像的结果就越准确,因此,随着邻域数量的增加,将获得更高质量的高分辨率图像。在训练阶段,本文通过设置不同的邻域数量来证明这一假设,然后分析所有测试图像的PSNR,实验结果如图3所示。
[21] ZHAO J, HU H, CAO F. Image super-resolution via adaptive sparse representation[J]. Knowledge-Based Systems, 2017, 124: 23-33.
[22] HUANG K, HU R, JIANG J, et al. Face image super-resolution through improved neighbor embedding[C]// Proceedings of the 2016 International Conference on Multimedia Modeling, LNCS 9516. Cham: Springer, 2016: 409-420.
[23] PARK J S, SOH J W, CHO N I. High dynamic range and super-resolution imaging from a single image[J]. IEEE Access, 2018, 6: 10966-10978.
[24] CHANG H, YEUNG D Y, XIONG Y. Super-resolution through neighbor embedding[C]// Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2004: I-I.
[25] ZHANG K, TAO D, GAO X, et al. Learning multiple linear mappings for efficient single image super-resolution[J]. IEEE Transactions on Image Processing, 2015, 24(3): 846-861.
[26] JIANG J, MA X, CHEN C, et al. Single image super-resolution via locally regularized anchored neighborhood regression and nonlocal means[J]. IEEE Transactions on Multimedia, 2017, 19(1): 15-26.
[27] TIMOFTE R, ROTHE R, van GOOL L. Seven ways to improve example-based single image super resolution[C]// Proceedings of the IEEE 2016 Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 1865-1873.
[28] DOU Q, WEI S, YANG X, et al. Medical image super-resolution via minimum error regression model selection using random forest[J]. Sustainable Cities and Society, 2018, 42: 1-12.
[29] ZEYDE R, ELAD M, PROTTER M. On single image scale-up using sparse-representations[C]// Proceedings of the 2010 International Conference on Curves and Surfaces, LNCS 6920. Berlin: Springer, 2010: 711-730.
[30] BEVILACQUA M, ROUMY A, GUILLEMOT C, et al. Low-complexity single-image super-resolution based on nonnegative neighbor embedding[EB/OL]. [2019-01-12]. http://people.rennes.inria.fr/Aline.Roumy/publi/12bmvc_Bevilacqua_lowComplexitySR.pdf.
[31] DONG C, LOY C C, HE K, et al. Image super-resolution using deep convolutional networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2016, 38(2): 295-307.
