基于新型间谍技术的半监督自训练正例无标记学习
2019-11-15李婷婷吕佳范伟亚
李婷婷 吕佳 范伟亚

摘 要:正例无标记(PU)学习中的间谍技术极易受噪声和离群点干扰,导致划分的可靠正例不纯,且在初始正例中随机选择间谍样本的机制极易造成划分可靠负例时效率低下,针对这些问题提出一种结合新型间谍技術和半监督自训练的PU学习框架。首先,该框架对初始有标记样本进行聚类并选取离聚类中心较近的样本来取代间谍样本,这些样本能有效地映射出无标记样本的分布结构,从而更好地辅助选取可靠负例;然后对间谍技术划分后的可靠正例进行自训练提纯,采用二次训练的方式取回被误分为正例样本的可靠负例。该框架有效地解决了传统间谍技术在PU学习中分类效率易受数据分布干扰以及随机间谍样本影响的问题。通过9个标准数据集上的仿真实验结果表明,所提框架的平均分类准确率和F-值均高于基本PU学习算法(Basic_PU)、基于间谍技术的PU学习算法(SPY)、基于朴素贝叶斯的自训练PU学习算法(NBST)和基于迭代剪枝的PU学习算法(Pruning)。
关键词:正例无标记学习;间谍技术;半监督自训练;聚类;可靠负例;可靠正例
中图分类号:TP181
文献标志码:A
Abstract: Spy technology in Positive and Unlabeled (PU) learning is easily susceptible to noise and outliers, which leads to the impurity of reliable positive instances, and the mechanism of selecting spy instances in the initial positive instances randomly tends to cause inefficiency in dividing reliable negative instances. To solve these problems, a PU learning framework combining new spy technology and semi-supervised self-training was proposed. Firstly, the initial labeled instances were clustered and the instances closer to the cluster center were selected to replace the spy instances. These instances were able to map the distribution structure of unlabeled instances effectively, so as to better assist to the selection of reliable negative instances. Then, the reliable positive instances divided by spy technology were purified by self-training, and the reliable negative instances which were divided as positive instances mistakenly were corrected by secondary training. The proposed framework can solve the problem of PU learning that the classification efficiency of traditional spy technology is susceptible to data distribution and random spy instances. The experiments on nine standard data sets show that the average classification accuracy and F-measure of the proposed framework are higher than those of Basic PU-learning algorithm (Basic_PU), PU-learning algorithm based on spy technology (SPY), Self-Training PU learning algorithm based on Naive Bayes (NBST) and Iterative pruning based PU learning (Pruning) algorithm.
Key words: Positive and Unlabeled (PU) learning; spy technology; semi-supervised self-training; clustering; reliable negative instance; reliable positive instance
0 引言
正例无标记(Positive and Unlabeled, PU)学习是指训练集在仅含正例样本和无标记样本的情况下训练分类器的过程[1-2]。从正例样本和无标记样本中学习分类器是实际应用中一类重要的分类问题,常见于在用户提供的大量数据中检索相似样本、网络评论中的欺骗性意见检测以及医疗行业中疾病基因预测等领域[3-4]。
PU学习的特点是初始有标记样本中没有已标注的负例样本,常见的监督学习或者半监督学习方法在这样的场景中往往失效[5]。近年来已有学者展开了相应的研究,即通过找出无标记样本中的可靠负例来扩充初始有标记样本集,进而在重新初始化后的标记样本集上训练分类器对无标记样本进行分类,但该方法得出的可靠负例往往包含较多被误分为负例的正例样本[6]。对此,Villatoro-Tello等[7]通过选出无标记样本集中分布较好的负例样本迭代添加到初始已标记样本集中的训练分类器,降低了算法对已标记样本中噪声的敏感性,有效地选出了无标记样本中的可靠负例,并成功地将该方法运用于文本分类领域。Han等[8]进一步研究发现,在选出无标记样本中可靠负例的同时,也可以对应选出无标记样本中的可靠正例,由此提出了一种基于聚类提取可靠正负例样本的方法,并用加权极值学习机对分类器进行训练。实验结果表明,该方法能够有效地对仅含正样本和无标记样本的不确定数据流进行分类。以上方法都是在重新初始化后的已标记样本集上训练分类器,但重新初始化后的已标记样本集中正例样本是绝对可靠的,而负例样本则是相对可靠的,初始化强烈倾向于正例样本,这在一定程度上影响了算法的分类效果。
第10期
李婷婷等:基于新型间谍技术的半监督自训练正例无标记学习
计算机应用 第39卷
为了解决PU学习中重新初始化后的标记样本强烈倾向于正例的问题,Zeng等[9]采用一种能平衡倾向性的间谍技术来重新初始化标记样本,该技术通过将初始正例中部分样本看作间谍样本发送到无标记样本中,通过间谍样本推断出无标记样本中未知正例的行为,同时有效地选出了可靠负例。文献[10]将间谍技术应用于移动互联网流量数据的用户行为分析上,提出了基于二分网络特征的PU学习方法用于用户行为分类和预测,利用实际的QQ流量数据和移动视频流量数据验证了该方法的有效性。类似地,文献[11]描述了现实获取的数据只包含少量已知的被攻击的统一资源定位符(Uniform Resource Locator, URL)和大量未标记实例,文中将此形式化为PU问题。
通过将间谍技术与成本敏感策略相结合,提出一种基于间谍技术的PU学习算法(PU learning algorithm based on spy technology, SPY),用于检测潜在URL攻击。实验结果表明,该方法能够有效地发现潜在的URL攻击。张璞等[12]提出了一种基于间谍技术的PU学习的建议语句分类方法,该方法为了降低特征维度、缓解数据稀疏性,在自编码神经网络特征空间中使用间谍技术划分可靠反例无标注样例进行分类。由此可见,嵌入间谍技术的PU学习方法有效地平衡了初始正负例样本,使其在分类过程中具有更好的泛化性,从而更好地对无标记样本进行分类。
然而,传统间谍技术极易受噪声和离群点干扰,分类过程中很少考虑到划分结果的纯净度问题,且随机选择间谍样本的机制也给分类结果带来一定的不稳定性。本文鉴于半监督自训练方法可以迭代选取高质量无标记样本对分类器进行更新,更新后的分类器能产生更精准的分类效果,从而提出了间谍技术结合半监督自训练的PU学习方法(PU learning method combining spy technology and semi-supervised Self-Training, SPYST),
SPYST通过将间谍技术的分类结果用半监督自训练方法进行二次提纯取得了更有效的分类效果,但SPYST尚未解决间谍样本选择的随机性带来的分类误差。因此,在SPYST的基础上从数据的空间结构出发,将初始正例的空间结构展露出来,然后挑选更具代表性的间谍样本,进一步提出了改进间谍技术后结合半监督自训练的PU学习方法(Improved SPYST, ISPYST)。
本文的主要工作为:
1)对PU学习中间谍技术展开研究,结合自训练方法对间谍技术的粗糙分类结果进行二次提纯。现有的国内外文献对间谍技术的研究主要集中于将该技术应用于文本分类、网络意见检测等方面,极少对间谍技术分类结果的纯净度进行研究。
2) 间谍技术中间谍样本的随机选取给分类结果带来一定的不稳定性,本文通过对初始正例的空间结构进行研究,选取了离聚类中心较近的样本作为间谍样本,这些样本更具代表性,能更好地反映无标记样本中未知正例的行为方式。
1 相关工作
1.1 PU学习
PU学习是指在仅包含少量正例样本和无标记样本中进行分类的一种特殊半监督学习,常见的PU学习过程是把无标记样本全部看作负类结合初始正例构造分类器再对无标记样本进行分类,找出无标记样本中隐藏的可靠负例,进而将可靠负例加入初始正例样本重新初始化有标记样本集。分类过程如图1所示,其中P表示初始正例样本,U表示无标记样本,C表示分类器,RN表示可靠负例,P′表示划分出的正例样本,N′表示划分出的负例样本。但该方法获得的标记样本中正例样本是绝对可靠的,所包含的样本信息也绝对准确;而标记样本中负例样本却只是相对可靠,所包含的样本信息的无法达到绝对真实。所以,重新初始化后的标记样本更倾向于正例样本,在后续的分类过程中更利于无标记样本中未知正例的划分,这就造成的分类结果的不平衡性。
1.2 基于间谍技术的PU学习
间谍技术是基于解决常见PU学习中重新初始化后标记样本强烈倾向于正例样本而提出,该方法能有效地平衡初始化后标记样本的倾向性问题,同时辅助识别无标记样本中的可靠负例。间谍技术是指通过从初始有标记样本中随机选出部分正例发送到无标记样本集,这些选出的正例样本被称之为间谍样本,它与无标记样本中的未知正例样本的行为是一致的,从而能够可靠地对未知正例样本行为进行评估。混合间谍样本的无标记样本集在分类算法训练完成后,根据间谍样本的后验概率设置阈值θ,当无标记样本属于正类的概率小于θ时,该样本被视为可靠负例,其余样本则被视为可靠正例[11]2599-2600。通过间谍技术划分数据类别的详细算法过程如下。
1.3 半监督自训练学习
半监督自训练是指在无标记样本中选取高质量样本给初始标记样本学习,底层分类器被重新训练,直至无标记样本被全部划分。半监督自训练算法在循环迭代的过程中,不断更新分类器划分无标记样本,使得无标记样本每一次都能在分类器状态最好的情况下被提纯,确保了无标记样本的分类准确率[13-15]。半监督自训练算法的一般流程如下:
输入 初始有标记样本集L,初始无标记样本集U,底层分类器C,迭代次数f,用于选择下一次迭代的无标记样本个数H,选择度量M,选择函数E(Uf,H,C,M),最大迭代次数Maxlteration。
2 本文算法
2.1 SPYST
2.1.1 算法思想
在初始数据集分布较好且无噪声或离群点干扰的环境中使用间谍技術识别可靠负例和可靠正例能取得令人满意的效果,然而,大多数真实的数据集都含有噪声或离群点,这样的数据集通过传统间谍技术分类变得不再可靠。原因是:间谍样本中离群点的后验概率Pr(C1|st)可能比大多数甚至所有的实际的负例样本要小得多。在这种情况下,通过间谍样本的概率值Pr(C1|st)来确定阈值θ,就无法在召回间谍样本的同时对无标记样本进行有效分类,导致了选出的可靠正例往往不纯,可靠负例过少甚至没有。图3表示在噪声干扰的环境中的分类结果,其中C1代表在分类过程中被当作正类的样本集,C-1代表在分类过程中被当作负类的样本集。由图3可知,在有噪声或离群点的环境中通过间谍技术选出可靠负例时效率不高,得出的可靠正例包含较多被误分为正类的负例样本。所以,在数据分布较差的环境中用间谍技术进行PU学习的方法变得不尽人意。
因此,本文提出了一种结合间谍技术与半监督自训练的PU学习方法SPYST。SPYST在间谍技术对无标记样本首次分类完成后,将RP看作新的无标记样本U′,并对新的无标记样本进行自训练提纯,此处选用稳定性较强的朴素贝叶斯作为分类器。SPYST首先对新的无标记样本做朴素贝叶斯分类,然后将分类置信度从高到低排序,选出置信度较高的无标记样本及其相应的类标签添加到初始正例样本与RN的合集中,这主要是因为高置信度样本携带更多有效分布信息,利于分类器的重新训练。循环迭代上述过程直至新的无标记样本被全部划分完成。这也就达到了对间谍技术的粗糙分类结果进行精细化提纯的目的,从而得出了分类效率更高的PU学习框架。SPYST整体学习框架如图4所示,其中P表示初始正例样本,U表示无标记样本,S表示选出的间谍样本,C表示朴素贝叶斯分类器,RN表示可靠负例,RP表示可靠正例,topf表示选出的前f个高置信度样本。
2.2.1 算法思想
在SPYST算法流程的Step1中,通过随机选取的机制选出了初始正例中的间谍样本,但这种随机性就可能导致间谍样本处于类簇的边界位置,如图5所示,图中圈出了初始正例中随机选取的间谍样本,并赋予间谍样本1~11的编号。
从图5可看出:编号为1和11的两个间谍样本对于初始正例集来说,属于离群点,而编号为3的间谍样本属于噪声点,这些间谍样本与无標记样本中未知正例的空间结构相似度较低,无法有效地对无标记样本的空间结构进行评估。在随机选择间谍样本时,若大量的噪声或离群点被选作间谍样本,会极大地影响分类器对无标记样本的评估,这种随机选择的机制直接导致了分类效率的降低。
因此,本文在算法SPYST的基础上提出了一种结合改进的间谍技术与自训练方法的PU学习算法ISPYST,有效地降低间谍样本的随机性带来的分类误差。ISPYST通过挖掘出初始正例样本的空间分布信息来改进SPYST算法,在把握空间结构的基础上计算正例样本的聚类中心,并找出距离聚类中心较近的样本作为间谍样本。这些样本在空间结构上离聚类中心更近,所包含正例样本的真实信息量也更大,当这样的样本被选作间谍样本时,更能有效地体现无标记样本中未知正例的分布情况。在此,本文选用了简单实用且收敛速度较快的K-Means聚类算法对初始正例进行聚类,K-Means算法的思想很简单,对于给定的样本集X,按照样本之间的距离大小,将样本集划分为K个簇,让簇内的点尽量紧密地连在一起,而让簇间的距离尽量地大,将离聚类中心较近的正例样本选作间谍样本[16]。
2.2.2 ISPYST算法流程
ISPYST仅对SPYST算法流程的Step 1进行替换,即ISPYST通过找出初始正例集上离聚类中心较近的样本代替传统随机选择的间谍样本,而SPYST其余步骤Step2至Step16不变,替换完成后形成新算法ISPYST。具体替换步骤如下:
3 仿真实验与分析
3.1 实验说明
为了验证算法SPYST以及ISPYST的有效性,选用以下算法进行对比实验:
1)基本PU学习算法(Basic PU-learning algorithm, Basic_PU)。
2)基于间谍技术的PU学习算法(SPY)[11]2600。
3)基于朴素贝叶斯的自训练PU学习算法(Self-Training PU learning algorithm based on Naive Bayes, NBST)。
4)基于迭代剪枝的PU学习(iterative Pruning based PU learning, Pruning)[17]。
对比实验所用数据集来自于UCI和Kaggle数据库,总共选用9组二分类数据进行实验说明,数据集名称、规模以及属性数见表1。
实验过程中,把数据集随机划分成训练集和测试集两部分,其中训练集占80%,测试集占20%。首先选出训练集中20%的正例样本作为初始有标记样本,然后将剩余80%的正例样本以及训练集中全部的负例样本除去标签后作为无标记样本集。所有算法重复实验50次,以平均分类准确率以及F-值作为算法性能评价指标。
3.2 实验结果及分析
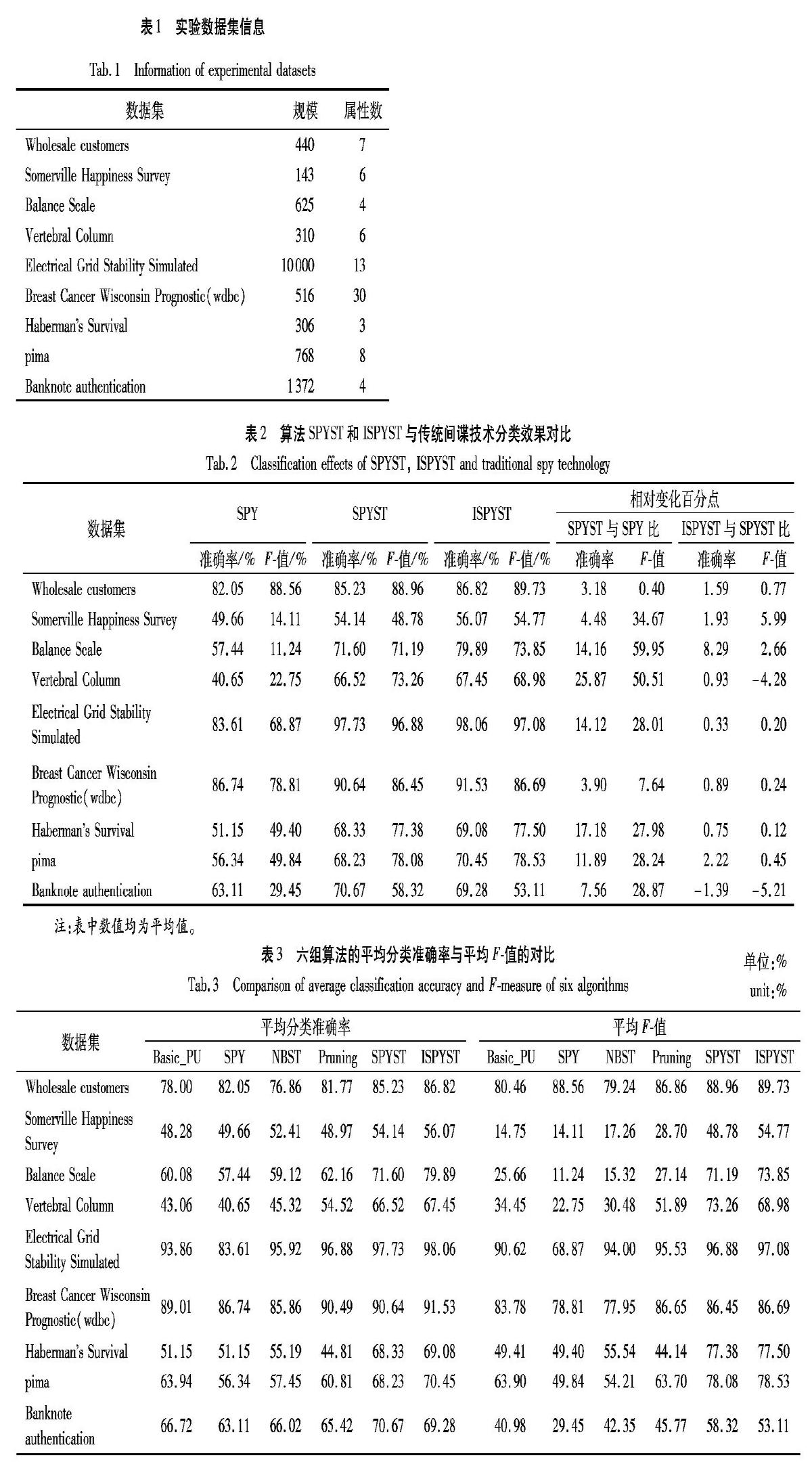
为了证明本文算法较传统间谍技术的分类性能有所提升,设置了如表2 所示的实验。表2显示了当初始有标记样本占全部正例样本的20%,且间谍样本占初始正例的15%时,本文算法与传统间谍技术的分类效果提升率。
由表2可知,改进后的算法SPYST对比传统的间谍技术在进行PU学习的过程中整体上具有更好的分类性能。传统的间谍技术在数据集Somerville Happiness Survey和Vertebral Column上分类效果极其异常,说明SPY根本无法在这样的数据集上做PU分类。通过分析得知这两组数据集初始分布不均匀,且其中包含大量噪声和离群点,而SPY对噪声和离群点异常敏感,且SPY在初始正例过少的情况下极难捕捉有效信息,导致了该方法分类效率低下。本文所提算法SPYST通过对SPY的分类结果做深度自训练,不断迭代提纯可靠正例,从而取得了更高的分类效率。由于SPYST采用随机选取间谍样本的机制,导致分类结果存在一定的不稳定性,针对这一问题,本文提出了改进后的算法ISPYST,该方法基于初始正例的空间结构选取最具代表性的正例作间谍样本,有效地减小了随机性带来的分类误差,从而提高了分类效率。从表2可以看出,ISPYST的分类效果在SPYST的基础上整体得到了进一步的提升。而在数据集Banknote authentication上,算法ISPYST的分类提升率相对低于算法SPYST,这是因为该数据集的数据分布过于集中,导致选出的间谍样本结构极其相似,所含的样本信息不能很好地对无标记样本中的未知正例进行评估。因此,算法ISPYST在空间分布过于密集的数据集上还存在一定的局限性。为了进一步验证本文所提算法SPYST与ISPYST的有效性,表3给出了当初始有标记样本占全部正例样本的20%,且间谍样本占初始正例的15%时,本文算法与4组对比算法的实验结果。
从表3可看出,当初始有标记样本占全部正例样本的20%时,本文所提算法SPYST与ISPYST整体性能均优于对比算法。在数据集Somerville Happiness Survey、Balance Scale、Vertebral Column以及Habermans Survival上有较好的体现,这主要是因为这四个数据集初始分布太差,對比算法易受噪声干扰,无法有效地利用少量初始正例中的有用信息,导致分类误判率过高;而SPYST通过对间谍技术的分类结果进行再次的精细化提纯,得出了更好的分类效果;ISPYST在SPYST的基础上对初始正例样本的空间结构做深入剖析,选出更具代表性的间谍样本,使得SPYST的分类效果得以进一步提升。在数据集Breast Cancer Wisconsin Prognostic(wdbc)和Electrical Grid Stability Simulated上,本文算法和对比算法分类效果整体相差不大,这是因为这两组数据集原始分布较为均匀,没有噪声和离群点的干扰,本文算法在这样的数据集上进行分类时,提升效果不明显。
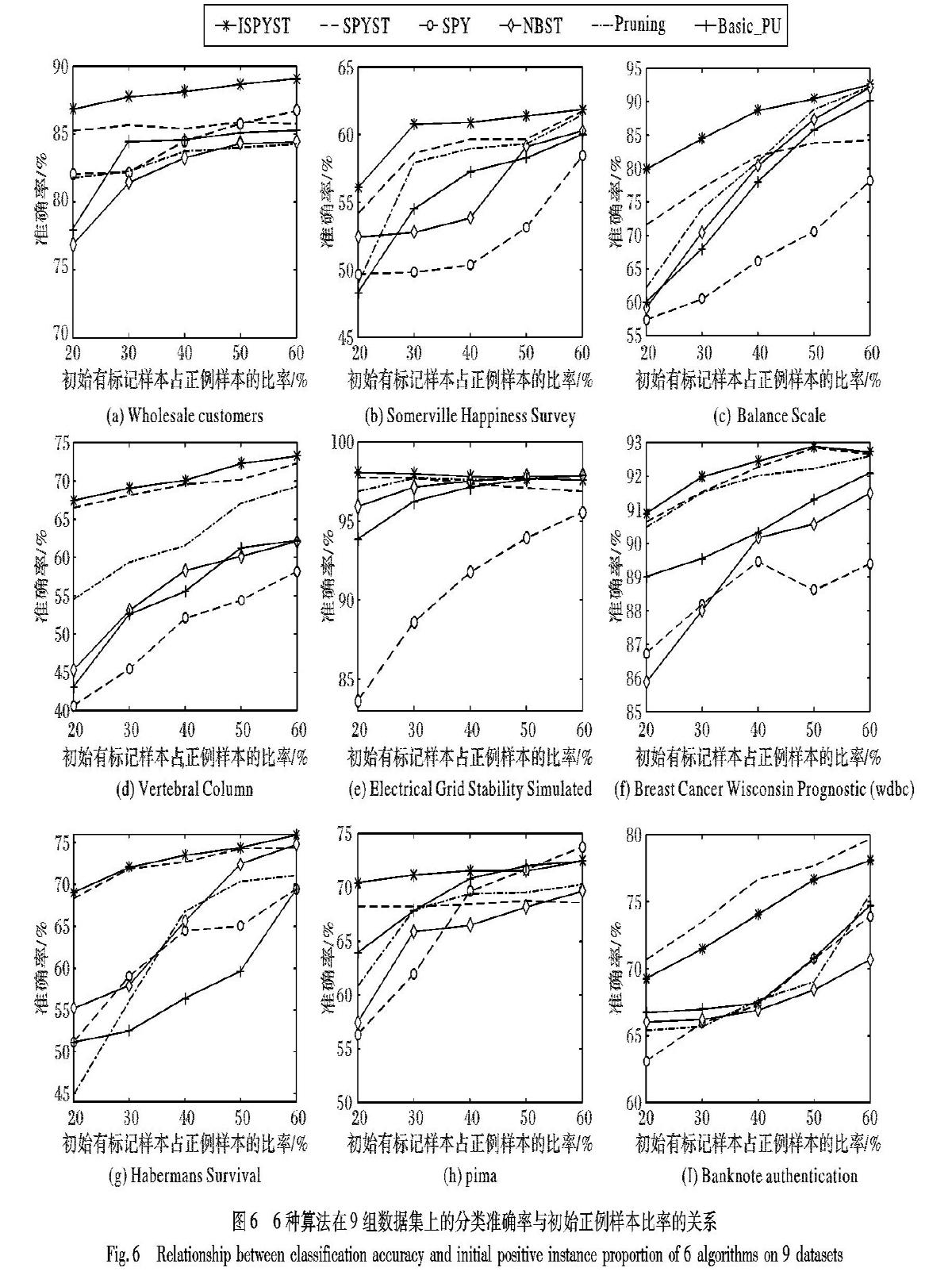
为了说明初始正例样本占比对各个算法的影响,图6通过逐步提高初始正例样本的占比进行分类实验,得出不同算法在初始样本数量不同情况下的准确率。从图6可看出,本文所提算法SPYST与ISPYST分类准确率整体上高于对比算法,尤其是在Wholesale customers、Somerville Happiness Survey、Vertebral Column、Habermans Survival、 pima以及Banknote authentication这6个数据集上,本文算法在初始正例占比极小的情况下相对于对比算法有较好的分类性能。这是因为SPYST对间谍技术的粗糙分类结果进行自训练加工,能得到更高的分类准确率。此外,ISPYST将少量初始正例的空间结构清晰地展示出来,选出了最能体现无标记样本中未知正例行为的样本作为间谍样本,解决了传统间谍技术随机选择间谍样本所带来的分类误差。而随着初始正例占比的不断增加,本文所提算法的分类优势逐渐减弱,在数据集Breast Cancer Wisconsin Origina、Electrical Grid Stability Simulated、 pima以及Habermans Survival上表现得尤为明显,这主要是因为在初始正例足够多的情况下,样本包含的有用信息更全面,所有算法都能有效地捕捉样本信息,从而达到较好的分类效果。SPYST与ISPYST倾向于在初始正例极其缺失的情况下做PU学习,当初始正例较多的情况下,本文所提算法并不占优势,甚至可能处于劣势。在数据集Banknote authentication上,改进后的算法ISPYST比SPYST分类效果差,这是因为该数据集的原始数据分布过于密集,在找出离聚类中心较近的样本作间谍样本时,间谍样本相互之间的区分度并不明显,导致间谍样本无法有效地提取无标记样本中正例样本的信息。算法ISPYST在空间分布过于密集的数据集上进行PU学习时会出现过拟合现象,降低了算法的分类性能。
4 结语
针对PU学习方法在初始正例过少的环境中难以有效地获取样本空间结构信息,且传统间谍技术易受噪声和离群点干扰,导致划分可靠负例时效率不高、得出的可靠正例不纯等问题,提出了两种学习框架,即间谍技术结合自训练的PU学习方法(SPYST)以及改进间谍技术后结合自训练的PU学习方法(ISPYST)。SPYST通过对间谍技术的分类结果进行二次训练,选取高置信度样本加入已标记样本集迭代自训练,解决了部分样本被误标记的问题;ISPYST在SPYST的基础上利用初始正例空间结构所包含的潜在信息,选出距离簇中心较近的样本作为间谍样本,这些间谍样本更能体现正例的行为特征,从而有效地划分出可靠正例与可靠负例。在9组标准数据集上的对比实验证实了本文所提算法在仅含少量初始正例的环境中也能捕获全面的数据分布信息,进而得出更好的分类效果。但本文算法在数据分布过于密集的数据集上还存在一定的局限性,因此,在后续工作中,将讨论如何通过挖掘数据集原始分布特征来获取有用信息,从而选出可靠负例来扩充初始有标记样本集,进而提高PU学习的分类性能。
参考文献(References)
[1] du PLESSIS M C, NIU G, SUGIYAMA M. Class-prior estimation for learning from positive and unlabeled data[J]. Machine Learning, 2017, 106(4): 463-492.
[2] SANSONE E, de NATALE F G B, ZHOU Z. Efficient training for positive unlabeled learning[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 38(7): 99-113.
[3] NIKDELFAZ O, JALILI S. Disease genes prediction by HMM based PU-learning using gene expression profiles[J]. Journal of Biomedical Informatics, 2018, 81: 102-111.
[4] FREY N C, WANG J, BELLIDO G I V, et al. Prediction of synthesis of 2D metal carbides and nitrides (MXenes) and their precursors with positive and unlabeled machine learning [J]. ACS Nano, 2019, 13(3): 3031-3041.
[5] 甘洪啸. 基于PU学习和贝叶斯网的不确定数据分类研究[D]. 咸阳: 西北农林科技大学, 2017: 1-61. (GAN H X. Research on uncertain data classification based on PU learning and Bayesian network[D]. Xianyang: Northwest A & F University, 2017: 1-61.)
[6] WU Z, CAO J, WANG Y, et al. hPSD: a hybrid PU-learning-based spammer detection model for product reviews[J]. IEEE Transactions on Cybernetics, 2018(99): 1-12.
[7] VILLATORO-TELLO E, ANGUIANO E, MONTES-Y-GMEZ M, et al. Enhancing semi-supevised text classification using document summaries[C]// Proceedings of the 2016 Ibero-American Conference on Artificial Intelligence, LNCS 10022. Berlin: Springer, 2016: 115-126.
[8] HAN D, LI S, WEI F, et al. Two birds with one stone: classifying positive and unlabeled examples on uncertain data streams[J]. Neurocomputing, 2018, 277: 149-160.
[9] ZENG X, LIAO Y, LIU Y, et al. Prediction and validation of disease genes using HeteSim scores[J]. IEEE/ACM Transactions on Computational Biology and Bioinformatics, 2017, 14(3): 687-695.
[10] YU K, LIU Y, QIN L, et al. Positive and unlabeled learning for user behavior analysis based on mobile Internet traffic data[J]. IEEE Access, 2018, 6: 37568-37580.
[11] ZHANG Y, LI L, ZHOU J, et al. POSTER: a PU learning based system for potential malicious URL detection[C]// Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security. New York: ACM, 2017: 2599-2601.
[12] 張璞, 刘畅, 李逍. 基于PU学习的建议语句分类方法[J]. 计算机应用, 2019, 39(3): 639-643. (ZHANG P, LIU C, LI X. Suggestion sentence classification method based on PU learning[J]. Journal of Computer Applications, 2019, 39(3): 639-643.)
[13] JUN N L, QING S Z. Semi-Supervised self-training method based on an optimum-path forest[J]. IEEE Access, 2019, 7(1): 2169-3536.
[14] TANHA J, van SOMEREN M, AFSARMANESH H. Semi-supervised self-training for decision tree classifiers[J]. International Journal of Machine Learning & Cybernetics, 2017, 8(1): 355-370.
[15] 罗云松, 吕佳. 结合密度峰值优化模糊聚类的自训练方法[J]. 重庆师范大学学报(自然科学版), 2019, 36(2): 96-102. (LUO Y S, LYU J. Self-training algorithm combined with density peak optimization fuzzy clustering[J]. Journal of Chongqing Normal University (Natural Science Edition), 2019, 36(2): 96-102.)
[16] CAP M, PREZ A, LOZANO J A. An efficient approximation to the K-means clustering for massive data[J]. Knowledge-Based Systems, 2017, 117: 56-69.
[17] FUSILIER D H, MONTES-Y-GMEZ M, ROSSO P, et al. Detecting positive and negative deceptive opinions using PU-learning[J]. Information Processing & Management, 2015, 51(4): 433-443.
