基于卷积神经网络的多尺度葡萄图像识别方法
2019-11-15邱津怡罗俊李秀贾伟倪福川冯慧
邱津怡 罗俊 李秀 贾伟 倪福川 冯慧


摘 要:葡萄品种质量检测需要识别多类别的葡萄,而葡萄图片中存在多种景深变化、多串等多种场景,单一预处理方法存在局限导致葡萄识别的效果不佳。实验的研究对象是大棚中采集的15个类别的自然场景葡萄图像,并建立相应图像数据集Vitis-15。针对葡萄图像中同一类别的差异较大而不同类别的差异较小的问题,提出一种基于卷积神经网络(CNN)的多尺度葡萄图像识别方法。首先,对Vitis-15数据集中的数据通过三种方法进行预处理:旋转图像的数据扩增方法、中心裁剪的多尺度图像方法以及前两种方法的数据融合方法;然后,采用迁移学习方法和卷积神经网络方法来进行分类识别,迁移学习选取ImageNet上预训练的Inception V3网络模型,卷积神经网络采用AlexNet、ResNet、Inception V3这三类模型;最后,提出适合Vitis-15的多尺度图像数据融合的分类模型MS-EAlexNet。实验结果表明,在同样的学习率和同样的测试集上,数据融合方法在MS-EAlexNet上的测试准确率达到了99.92%,相较扩增和多尺度图像方法提升了近1个百分点,
并且所提方法在分类小样本数据集上具有较高的效率。
关键词:图像识别;自然场景;迁移学习;卷积神经网络;多尺度图像;数据融合
中图分类号:TP183
文献标志码:A
Abstract: Grape quality inspection needs the identification of multiple categories of grapes, and there are many scenes such as depth of field changes and multiple strings in the grape images. Grape recognition is ineffective due to the limitations of single pretreatment method. The research objects were 15 kinds of natural scene grape images collected in the greenhouse, and the corresponding image dataset Vitis-15 was established. Aiming at the large intra-class differences and small inter-class of differences grape images, a multi-scale grape image recognition method based on Convolutional Neural Network (CNN) was proposed. Firstly, the data in Vitis-15 dataset were pre-processed by three methods, including the image rotating based data augmentation method, central cropping based multi-scale image method and data fusion method of the above two. Then, transfer learning method and convolution neural network method were adopted to realiize the classification and recognition. The Inception V3 network model pre-trained on ImageNet was selected for transfer learning, and three types of models — AlexNet, ResNet and Inception V3 were selected for convolution neural network. The multi-scale image data fusion classification model MS-EAlexNet was proposed, which was suitable for Vitis-15. Experimental results show that with the same learning rate on the same test dataset, compared with the augmentation and multi-scale image method, the data fusion method improves nearly 1% testing accuracy on MS-EAlexNet model with 99.92% accuracy, meanwhile the proposed method has higher efficiency in classifying small sample datasets.
Key words: image recognition; natural scene; transfer learning; Convolutional Neural Network (CNN); multi-scale image; data fusion
0 引言
近年來,我国葡萄产量逐年增加,截止到2014年,我国葡萄种植面积已达767.2千公顷(7672km2),
产量已跃居世界第一[1]。目前果园中葡萄分类识别需要大量的人力来完成,然而,由于人力分辨能力和速度的限制,果园中葡萄的分类识别效果不佳;并且由于果园环境的复杂性和不确定性,加之葡萄是簇生水果且其轮廓不规则,导致同一类间差别较大而不同类别间差异较小[2],使得葡萄串的识别和定位成为难题[3]。
多年来,图像识别对于智能果园管理、智能农业目标检测、定位与识别等问题至关重要,然而图像识别的关键在于图像特征的提取,使用显著对象作为图像内容表示和特征提取的主要图像组件[4]。按照特征提取方法的不同分为传统图像特征提取方法与深度卷积神经网络自动提取特征两种。通过文献[5]总结出:传统图像特征提取方法主要考虑图像的颜色特征、纹理特征、形状特征和空间关系特征。基于颜色直方图特征匹配方法主要有直方图相交法、距离法、中心距法、参考颜色表法、累加颜色直方图法等,由于颜色无法衡量图像的方向和大小,所以不能很好提取图像的局部特征。基于纹理特征提取常用的统计方法是灰度共生矩阵(Gray-Level Co-occurrence Matrix, GLCM)法和半方差图,常用的模型有随机场模型和分形模型,而纹理是居于区域的概念,所以会导致过度区域化而忽略了全局特征。基于形状特征提取的方法主要有边界特征法、傅里叶形状描述符法、几何参数法和形状不变矩法等,而对于形变目标识别效果不佳。基于空间关系特征提取常用两种方法:一种是对图像进行自动分割,划分图像中包含的对象区域,根据这些区域提取图像特征并建立索引关系;另一种是将图像划分为若干子块,对子块进行特征提取并建立索引关系,而对于图像的旋转、尺度变化不敏感。由于传统特征提取方法具有较强的局限性,针对图像分类问题,本文主要采用卷积神经网络来提取图像特征。
在图像识别技术发展过程中,许多深度学习模型被提出,如:深度置信网络(Deep Belief Network,DBN)[6]、判别特征网络(Discriminative Feature Network, DFN)[7]、卷积神经网络(Convolutional Neural Network, CNN)、循环神经网络(Recurrent Neural Network, RNN)[8]等。相较于浅层学习模型的特征提取依靠手工来进行选择,深度学习的深层网络结构可以逐层对数据进行特征提取,使得特征更明显且更容易被用于图像分类和识别。深度学习根据监督方式的不同,主要分为监督、半监督和无监督方式将图像语义标注信息表示为监督学习的问题[9]。
早在20世纪80年代,LeCun等[10]提出了基于卷积神经网络的手写数字识别网络LeNet-5。2012年Krizhevsky等[11]提出AlexNet模型,并在ImageNet竞赛中取得了冠军,该模型采用两块GPU,大幅提升了网络的运算效率。2014年Simonyan等[12]提出层数更深、分类效果更好的模型VGG(Visual Geometry Group)。
同年GoogLeNet[13]被提出,它采用一种网中网的结构,加大了整个模型的宽度和深度;但随着模型深度加深的同时,会出现模型难以训练的情况。He等[14]在2015年提出残差网络ResNet解决了这个问题;2016年Inception-v4[15]被提出,它是基于Inception-v3的改进,模型更简洁,计算量也更小。
在分类识别算法上,通过组合不同的描述符可以获得更好的分类结果[16],使用监督学习或者无监督学习要比使用随机滤波器和人工特征识别效果更好[17]。
在本文的实验中,采用了支持向量机(Support Vector Machine, SVM)方法[18]、迁移学习[19]和深度卷积神经网络来分类葡萄图像,并且提出适合Vitis-15数据集的分类识别模型MS-EAlexNet,最后通过调节参数及激活函数来优化网络,使得在测试集上的效果得以提升。
1 材料与方法
1.1 数据集概况
1.1.1 葡萄数据集Vitis-15
本实验数据于2017年和2018年通过采集大棚中15个类别的自然场景葡萄图像并建立相应小样本数据集,数据集命名为Vitis-15。在拍摄过程中,拍摄条件没有任何限制,在自然光的照射下用安卓和苹果手机对悬挂的葡萄进行拍摄,葡萄品种分别为:比昂扣、夏黑、金手指、美人指、水晶葡萄、摩尔多瓦、甬优一号、克伦生、阳光玫瑰、巨玫瑰、香玉、红提、红地球、黑珍珠、赤霞珠,如表1所示。
本数据集的复杂度在于:1)同一品种的葡萄由于年份及生长环境不同,成熟度、色泽、葡萄串的形状会有差别,导致同一类别间差异较大。如图1(a)所示,同一品种的甬优一号有黄绿色、紫红色、黄绿色与浅紫色相间。同一品种的夏黑,由于栽培方式和种植环境的不同,串形和大小有明顯差异。2)不同品种之间形状大小及颜色也较为相近,导致不同类别间差异较小。如图1(b)所示,阳光玫瑰、比昂扣和水晶葡萄三个类别,黑珍珠、甬优一号和夏黑三个类别,摩尔多瓦和赤霞珠两个类别,在外观上肉眼难以区分。3)拍摄的图片中既有单串的又有多串的;自然背景较为复杂,有逆光和背光拍摄;有的葡萄支架会与葡萄本身颜色接近形成干扰,葡萄叶片与果粒本身颜色也很接近形成较强的干扰。
1.1.2 Vitis-15数据集预处理
本实验中采取的数据预处理为数据缩放,预先将图片缩放至卷积神经网络要求大小(224×224和299×299)。由于原始拍摄图片宽高比并不是1∶1, 直接缩放到1∶1会使葡萄发生形变,丢失物体本身的特征信息,对葡萄图像分类识别的准确率会有所影响,所以在缩放时保留原始图像的宽高比,空白信息填充像素“0”(即为黑色)。
1.2 实验方法
1.2.1 支持向量机
训练机器学习分类算法,需要先进行数据预处理;再进行特征选择,最后选择分类器。在数据预处理过程中,先将特征值缩放到相同的区间,称为特征缩放。特征缩放有两个常用的方法:归一化和标准化。本文实验采用标准化。通过标准化,可以将特征列的均值设为0,方差设为1,使得特征列的值呈现标准正态分布,这更易于权重的更新。相较于归一化方法,标准化方法保持了异常值所蕴含的有用信息,并且使得算法受到这些值的影响较小。标准化的过程可用式(1)表示:
例如,在刑事案件追踪的研究中,对于准确率的要求较低,而更要求时效性时,可以采用迁移学习加SVM方法;在医学影像这种需要高精度的研究中,可以采用迁移学习加全连接层这种方法。
2.2 卷积神经网络结果分析
模型训练与测试均是在TensorFlow框架下完成的。硬件环境:Intel Xeon E5-2620v4 @2.10GHz CPU,128GB内存;NVIDIA GTX 1080 Ti GPU,11GB显存。软件环境:CUDA Toolkit 9.0,CUDNN V7.0;Python 3.5.2;TensorFlow-GPU 1.7.0;Ubuntu16.04操作系統。模型训练和测试均是通过GPU加速。
在划分训练集和测试集时,采用8∶2的比例来划分,不是整个所有扩增后的数据直接随机抽取20%作为测试集,而是采用分层抽样的思想,即每个种类都随机采样20%作为测试集,包括1277张图片,且所有模型的测试准确率均是在同一测试集上所得。
2.2.1 深度卷积网络模型的结果分析
本文实验分别采用AlexNet、ResNet50、ResNet101、ResNet152、ResNet200、Inception V3和MS-EAlexNet七种卷积神经网络进行训练,在测试集上的准确率如表2所示。通过表2和图4可以看出,在MS方法下,四种残差网络(ResNet50、ResNet101、ResNet152和ResNet200)的准确率在采用同样参数训练时,随着网络层数的加深而单调递减。
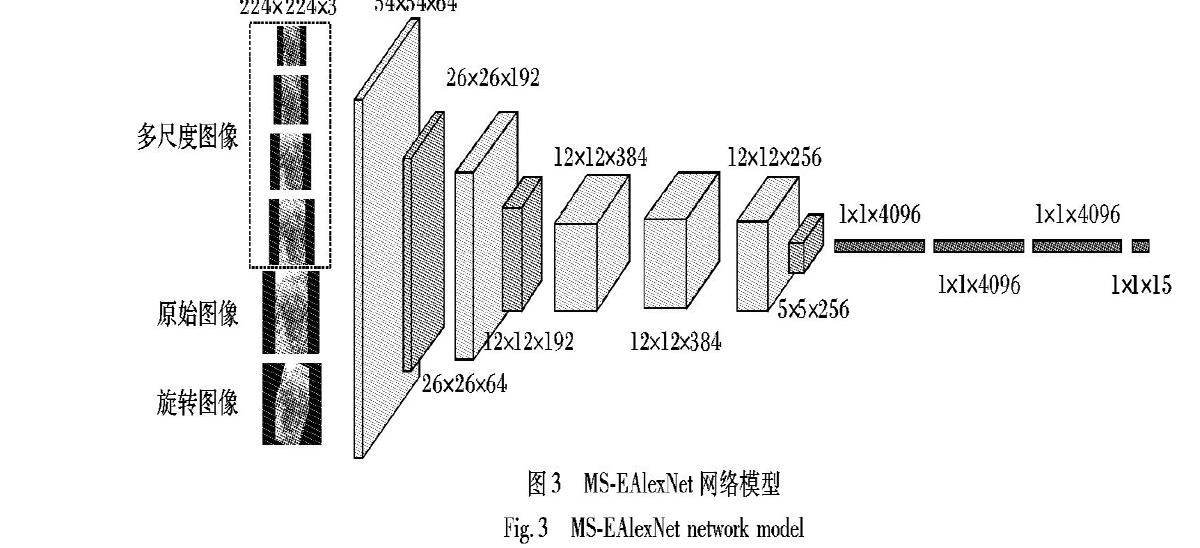
在实验过程中当采用与ResNet50和ResNet101这两个网络同样的参数时,ResNet152和ResNet200这两个网络会出现无法收敛现象,将学习率(learning rate, lr)由0.001降低到0.0001和0.00006后,网络能够收敛,也验证随着网络模型的加深,Vitis-15分类识别精度降低,所以在后续实验中不考虑ResNet152和ResNet200这两种深层网络。AlexNet网络相较残差和Inception V3网络,网络层数较少,迭代步数较少,训练时间最短且性能较好。对于Vitis-15数据集而言,可以采用AlexNet这类轻量型的卷积网络进行训练。因此可以得出对于小样本数据集分类问题,网络层数越深,模型反而更加难以训练,分类识别效果不佳,所以浅层的网络相较于深层的网络表现更好一些,并且小型网络能够极大地缩短训练时间且性能最好。本文提出的MS-EAlexNet网络,在同种方法对比时比AlexNet表现更好,在测试集上的准确率能够提升约0.1个百分点。
2.2.2 数据预处理三种方法对模型性能的影响
表2中展现了卷积神经网络三种数据预处理方法(MS、Augment、Mix)在七种网络模型上的测试准确率。通过实验发现,1、1/2、1/4这三个多尺度最终会使图片中全部为葡萄图像,不利于整串葡萄图像的识别,而连续多尺度的优点在于:1)基本保持了原始图像中葡萄串形的大小;2)还保留了原始葡萄图像中局部特征的完整性,所以选择了连续多尺度图像。从图5中可以得出,Augment与MS两种方法在AlexNet和MS-EAlexNet网络上测试准确率较为接近,而Mix方法在测试集上的准确率明显高于前两种方法,提升近1个百分点。最终本实验采用Mix方法。
2.2.3 BN和ReLU对模型性能的影响
本文采用批归一化处理和ReLU激活函数,对比分析两者对模型性能的影响。在网络的最后一个全连接层中修改激活函数(ReLU)和批归一化函数(Batch Normalization, BN),实验结果发现,修改ReLU激活函数,网络的性能没有明显变化,但是采用BN后网络提升了近1个百分点,达到99.92%的准确率。采用BN可以使得梯度更加可靠和可预测,改善梯度性质使得在计算梯度的方向采用更大的步长而能够保持对实际梯度方向的精确估计。不采用BN时,损失函数不仅非凸而且趋向平坦区域和尖锐极小值。这使得梯度下降算法更加不稳定。并且通过图6可以得出,在采用BN时,网络的训练准确率(图6(a))和训练损失值(图6(b))的波动程度降低,趋于平缓的上升和下降,虽然训练的损失函数最后收敛值高于没有采用BN的,但是在测试集上,采用BN的网络表现更好;而没有采用BN时,网络训练的准确率和损失值波动明显。
3 结语
本文基于卷积网络的多尺度葡萄图像品种识别研究,以融合多尺度数据和数据扩增两种方法训练卷积神经网络,对葡萄图像进行分类,并对网络模型、学习方法、批归一化参数等因素对模型性能的影响进行了对比分析,得到如下结论:
1)深度学习相较于迁移学习和支持向量机的方法,可以较好地自动提取葡萄特征,具有较高的分类性能。在深度学习网络模型中,较浅层的网络在Vitis-15数据集上分类效果要优于较深层的网络,网络层数越深,模型反而更加难以训练,本文提出的MS-EAlexNet网络模型在AlexNet网络基础上修改了网络参数并且增加了一层全连接层,在测试集上的准确率要高于AlexNet网络模型,也表明全连接层更适合分类识别问题。
2)相较于数据扩增和多尺度图像方法,两者在Vitis-15数据集分类结果都取得了较高的准确率,当将两种方法融合到一起时,测试集的准确率提升了近1个百分点,这也说明了多尺度图像数据融合在小样本数据集分类识别问题中丰富了数据的多样性,减轻了模型的过拟合现象,并且提升了网络的性能。
3)BN的使用使得网络在训练时更加稳定、波动性小、训练的准确率和训练的损失值更加平滑,并且网络的测试准确率也有明显提升。
通过本文的实验与分析,卷积神经网络对于特征提取要优于传统的特征提取算法,可以看出数据在预处理过程中数据融合方法是可行的,该方法可以有效提高分类管理和生产效率,可以应用于葡萄分类采摘机器人,降低葡萄人工分类的工作量和劳动力,可为果园智能化的识别提供帮助。
參考文献(References)
[1] 晁无疾. 调整提高转型升级促进我国葡萄产业稳步发展[J]. 中国果菜, 2015(9): 12-14. (CHAO W J. Adjustment, improvement, transformation and upgrading to promote the steady development of Chinas grape industry[J]. China Fruit Vegetable, 2015(9): 12-14.)
[2] ZHAO B, FENG J, WU X, et al. A Survey on deep learning-based fine-grained object classification and semantic segmentation[J]. International Journal of Automation and Computing, 2017, 14(2): 119-135.
[3] LUO L, TANG Y, ZOU X, et al. Vision-based extraction of spatial information in grape clusters for harvesting robots[J]. Biosystems Engineering, 2016, 151: 90-104.
[4] FAN J, GAO Y, LUO H. Multi-level annotation of natural scenes using dominant image components and semantic concepts[C]// Proceedings of the 12th Annual ACM International Conference on Multimedia. New York: ACM, 2004: 540-547.
[5] NIXON M S, AGUADO A S. 特征提取与图像处理[M]. 李实英, 杨高波, 译.北京: 电子工业出版社, 2010: 147-289. (NIXON M S, AGUADO A S. Feature Extraction and Image Processing[M]. LI S Y, YANG G B, translated. Beijing: Publishing House of Electronics Industry, 2010: 147-289.)
[6] HINTON G E, OSINDERO S, TEH Y W. A fast learning algorithm for deep belief nets[J]. Neural Computation, 2006, 18(7): 1527-1554.
[7] YU C, WANG J, PENG C, et al. Learning a discriminative feature network for semantic segmentation[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 1857-1866.
[8] SCHUSTER M, PALIWAL K K. Bidirectional recurrent neural networks[J]. IEEE Transactions on Signal Processing, 1997, 45(11): 2673-2681.
[9] CARNEIRO G, VASCONCELOS N. Formulating semantic image annotation as a supervised learning problem[C]// Proceedings of the 2005 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2005: 163-168.
[10] LeCUN Y, BOTTOU L, BENGIO Y, et al. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 1998, 86(11): 2278-2324.
[11] KRIZHEVSKY A, SUTSKEVER I, HINTON G E. ImageNet classification with deep convolutional neural networks[C]// Proceedings of the 25th International Conference on Neural Information Processing Systems. La Jolla, CA: Neural Information Processing Systems Foundation, 2012: 1097-1105.
[12] SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[EB/OL]. [2019-02-10]. https://arxiv.org/pdf/1409.1556.pdf.
[13] SZEGEDY C, LIU W, JIA Y, et al. Going deeper with convolutions[C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Patten Recognition. Piscataway: IEEE, 2015: 1-9.
[14] HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 770-778.
[15] SZEGEDY C, IOFFE S, van HOUCKE V, et al. Inception-V4, inception-ResNet and the impact of residual connections on learning[C]// Proceedings of the 2016 31st AAAI Conference on Artificial Intelligence. Pola Alto, CA: AAAI, 2016: 4278-4284.
[16] GEHLER P, NOWOZIN S. On feature combination for multiclass object classification[C]// Proceedings of the 12th IEEE International Conference on Computer Vision. Piscataway: IEEE, 2009: 221-228.
[17] JARRETT K, KAVUKCUOGLU K, RANZATO M, et al. What is the best multi-stage architecture for object recognition?[C]// Proceedings of the 12th IEEE International Conference on Computer Vision. Piscataway: IEEE, 2009: 2146-2153.
[18] CHEN P H, LIN C J, SCHOLKOPF, BERNHARD. A tutorial on ν-support vector machines[J]. Applied Stochastic Models in Business and Industry, 2005, 21(2): 111-136.
[19] WEISS K, KHOSHGOFTAAR T M, WANG D D. A survey of transfer learning[J]. Journal of Big Data, 2016, 3: 9.
[20] WOLD S. Principal component analysis[J]. Chemometrics & Intelligent Laboratory Systems, 1987, 2(1):37-52.
[21] SZEGEDY C, van HOUCKE V, IOFFE S, et al. Rethinking the Inception architecture for computer vision[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 2818-2826.
[22] LECUN Y, BENGIO Y, HINTON G. Deep learning[J]. Nature, 2015, 521(7553): 436-444.
