基于深度学习模型的遥感图像分割方法
2019-11-15许玥冯梦如皮家甜陈勇
许玥 冯梦如 皮家甜 陈勇

摘 要:利用遥感图像快速准确地检测地物信息是当前的研究热点。针对遥感图像地表物的传统人工目视解译分割方法效率低下和现有基于深度学习的遥感图像分割算法在复杂场景下准确率不高、背景噪声多的问题,提出一种基于改进的U-net架构与全连接条件随机场的图像分割算法。首先,融合VGG16和U-net构建新的网络模型,以有效提取具有高背景复杂度的遥感图像特征;然后,通过选取适当的激活函数和卷积方式,在提高图像分割准确率的同时显著降低模型预测时间;最后,在保证分割精度的基础上,使用全连接条件随机场进一步优化分割结果,以获得更加细致的分割边缘。在ISPRS提供的标准数据集Potsdam上进行的仿真测试表明,相较于U-net,所提算法的准确率、召回率和均交并比(MIoU)分别提升了15.06个百分点、29.11个百分点和0.3662,平均绝对误差(MAE)降低了0.02892。实验结果验证了该算法具备有效性和鲁棒性,是一种有效的遥感图像地表物提取算法。
关键词:深度学习;卷积神经网络;深度可分离卷积;全连接条件随机场
中图分类号:TP391.4
文献标志码:A
Abstract: To detect surface object information quickly and accurately by using remote sensing images is a current research hot spot. In order to solve the problems of inefficiency of the traditional manual visual interpretation segmentation method as well as the low accuracy and a lot of background noise of the existing remote sensing image segmentation based on deep learning in complex scenes, an image segmentation algorithm based on improved U-net network architecture and fully connected conditional random field was proposed. Firstly, a new network model was constructed by integrating VGG16 and U-net to effectively extract the features of remote sensing images with highly complex background. Then, by selecting the appropriate activation function and convolution method, the image segmentation accuracy was improved while the model prediction time was significantly reduced. Finally, on the basis of guaranteeing the segmentation accuracy, the segmentation result was further improved by using fully connected conditional random field. The simulation test on the standard dataset Potsdam provided by ISPRS showed that the accuracy, recall and the Mean Intersection over Union (MIoU) of the proposed algorithm were increased by 15.06 percentage points, 29.11 percentage points and 0.3662 respectively, and the Mean Absolute Error (MAE) of the algorithm was reduced by 0.02892 compared with those of U-net. Experimental results verify that the proposed algorithm is an effective and robust algorithm for extracting surface objects from remote sensing images.Key words: deep learning; Convolutional Neural Network (CNN); depth separable convolution; fully connected conditional random field
0 引言
對地物分割的研究已有几十年的历史,国内外学者针对不同的应用场景和数据源,提出并发表了众多方法和研究成果。传统的分割方法多基于阈值设定,所以针对不同地物的分布、形状、结构、纹理与色调信息,[1]采用的方法也不一。
针对植被分割,巫兆聪等[2]结合光谱纹理和形状结构信息分割森林植被,改善了分割质量;Yuan等[3]提出结合光谱和纹理特征的遥感图像分割方法提高了不同地物目标的分割效率和准确度;Palenichka等[4]提出基于视觉注意的森林植被多尺度分割方法。针对不透水表面分割有最近邻[5]、支持向量机[6]、隶属度函数[7]、形态学滤波[8]、矢量化[9]等方法。针对建筑物分割有均质区域识别[10]、形态学房屋指数计算[11]、聚类提取城市变化[12]、先验形状约束水平集模型[13]等方法和模型。
以上方法只能分割单一种类地物,针对某种地物的信息特征采用对应方法,所以以上方法不能用于解决本文的多分类问题。
现阶段深度学习被普遍应用在计算机视觉领域,其中卷积神经网络(Convolutional Neural Network, CNN)[14]以其局部权值共享的特殊结构以及良好的容错能力、并行处理能力和自学习能力被广泛地应用于图像分类[15]、对象检测[16]、语义分割[17]、人脸识别[18]等诸多计算机视觉领域。
在Long等[17]提出了全卷积网络(Fully Convolutional Network, FCN)原理之后,卷积神经网络的分类目标由对象精确至像素,拓展到了语义分割领域,这种end-to-end的全卷积神经网络被用来解决PASCAL VOC2012和Microsoft COCO等数据集的像素分类问题,达到了很好的效果并被作为基准。这些数据集来自日常人类视角的生活场景,而在本文中所使用的是地球观测数据,因同为语义分割任务则选用与FCN同样是全卷积神经网络的encoder-decoder结构的U-net[19]作为基础构架,但由于U-net构架较浅不能明确表征复杂的地物特征,所以在基础构架上增加网络层数以表征更高维的特征信息,构建为D-Unet;针对U-net的激活函数——线性整流函数(Rectified Linear Unit, ReLU)[20]易使神经元失活的问题,在D-Unet中使用ELU(Exponential Linear Units)函數[21]替换;针对加深网络层而导致的模型体积与参数量激增的问题,使用深度可分离卷积(Depthwise Separable Convolution)[22-23]替换标准卷积构建新的轻量级网络模型DS-Unet,降低训练与预测时的计算量,提高模型运行效率;针对神经网络过拟合问题,使用Dropout[13]降低网络层节点间的关联性,提高了模型泛化能力;最后将神经网络输出结果作为全连接条件随机场(Fully Connected Conditional Random Field)[24]的输入,对分割结果进一步优化,进行对比实验。改进的模型拥有很强的学习能力,拥有较强的泛化能力,性能稳定、鲁棒性强。
1 数据集及其预处理
研究采用国际摄影测量与遥感学会(International Society for Photogrammetry and Remote Sensing, ISPRS)提供的机载图像数据集2D Semantic Labeling Potsdam。Potsdam是一座典型的历史悠久的城市,拥有大型建筑、狭窄的街道和密集的沉降结构,这为遥感图像地物测绘提供了先决条件。该数据集包括高分辨率的真实正射影像(True Ortho Photo, TOP)和从密集图像匹配技术派生的数字表面模型(Digital Surface Model, DSM)[25]。TOP和DSM的地面采样距离为5cm,这为分割后依据像素点统计分类目标地物提供先决条件。该数据集包含38个(相同大小的)TOP区块(6000×6000像素),如图1所示。
1.1 基准值处理
本文分割目标为4类(植被、不透水表面、建筑、背景)。因Potsdam数据集提供的gt共分为6类(不透水表面、建筑、低植被、树木、车辆、背景),而本文所探讨的是遥感图像地物测绘,不透水表面上的车辆并不作为地物信息所统计,因车辆与不透水表面在二维空间上重合,则车辆类归类为不透水表面类。本文主要探讨卷积模型的优化改进,卷积神经网络的输入只有R、G、B三个通道,没有使用数据集所提供的DSM;又因低植被与树木的光谱、形状、空间信息相似,必须借助于DSM作为分类的依据,则最终把树木与低植被归为植被类,用以统计植被覆盖。不透水表面与车辆、低植被与树木的类别合并后详见表2。
数据集中提供的gt的每个通道的光谱分辨率为8位,而深度学习框架需要输入的gt为灰度图像,通过对RGB图像的R、G、B三个分量进行加权平均(加权平均算法)达到灰度化处理的目的,加权平均算法如式(1)所示:
1.2 使用eCognition标注未标注数据
原数据集提供38个区块的TOP,仅部分TOP提供标记的gt,其余场景的gt未发布,所以使用eCognition对未标注的14个TOP进行标注。
eCognition采用面向对象的分类技术对像素进行分类,这是一种基于目标对象的分类方法,因其能充分利用遥感图像的光谱、纹理、形状、空间信息、相邻关系等特征对像素分类,所以精度相对较高,能够接近人工目视解译精度,所以本文采用此方法标注剩余数据。面向对象的技术有两个重要特征和技术关键:选取合适的分割尺度对图像进行分割,使检测的地物能在最合适(图像首先被分割成一个个object,然后进行sample标记,最合适意味着用最少的object表达最为精确的地物边缘)的分割尺度中凸显出来;选取分割对象的多种典型特征建立地物的分类规则进行检测或分类。[26]
本文首先使用eCognition中的multiresolution segmentation算法根据不同图像的特征设定不同的参数对地物信息进行初始分割,遥感图像(图3(a))的部分区域(图4(a))的初始分割结果如图4(b)所示,此图像采用的参数Scale Parameter、Shape及Compactness分别为100、0.1与0.5。其中Scale Parameter表示分割的区块大小,一般参数设置越小,区块越小,分割越为精细;Shape表示形状参数,它与color(颜色参数)的权重和为1;compactness代表紧凑度,它与smoothness(平滑度)的权重和为1。然后选取合适的特征作为地物的分类规则,本文针对不同地物的光谱反射不同选择Layer Values特征,依据不透水表面与建筑物的面积、长宽差异度大而选定Area(Pxl)、Length/Width特征,依据植被与其他地物的边界光滑性差异度大而选择shape index(地物边长与其面积开四次方的比值)特征。最后使用eCognition中的classification算法对每个像素点进行分类,得到gt,如图3(b)所示。
2 遥感图像语义分割模型
本文改进的遥感图像语义分割深度神经网络命名为D-Unet与DS-Unet,用于从遥感图像中提取有效的地物信息。2.1 基于改进U-net的遥感图像语义分割模型
2.1.1 改进U-net构架
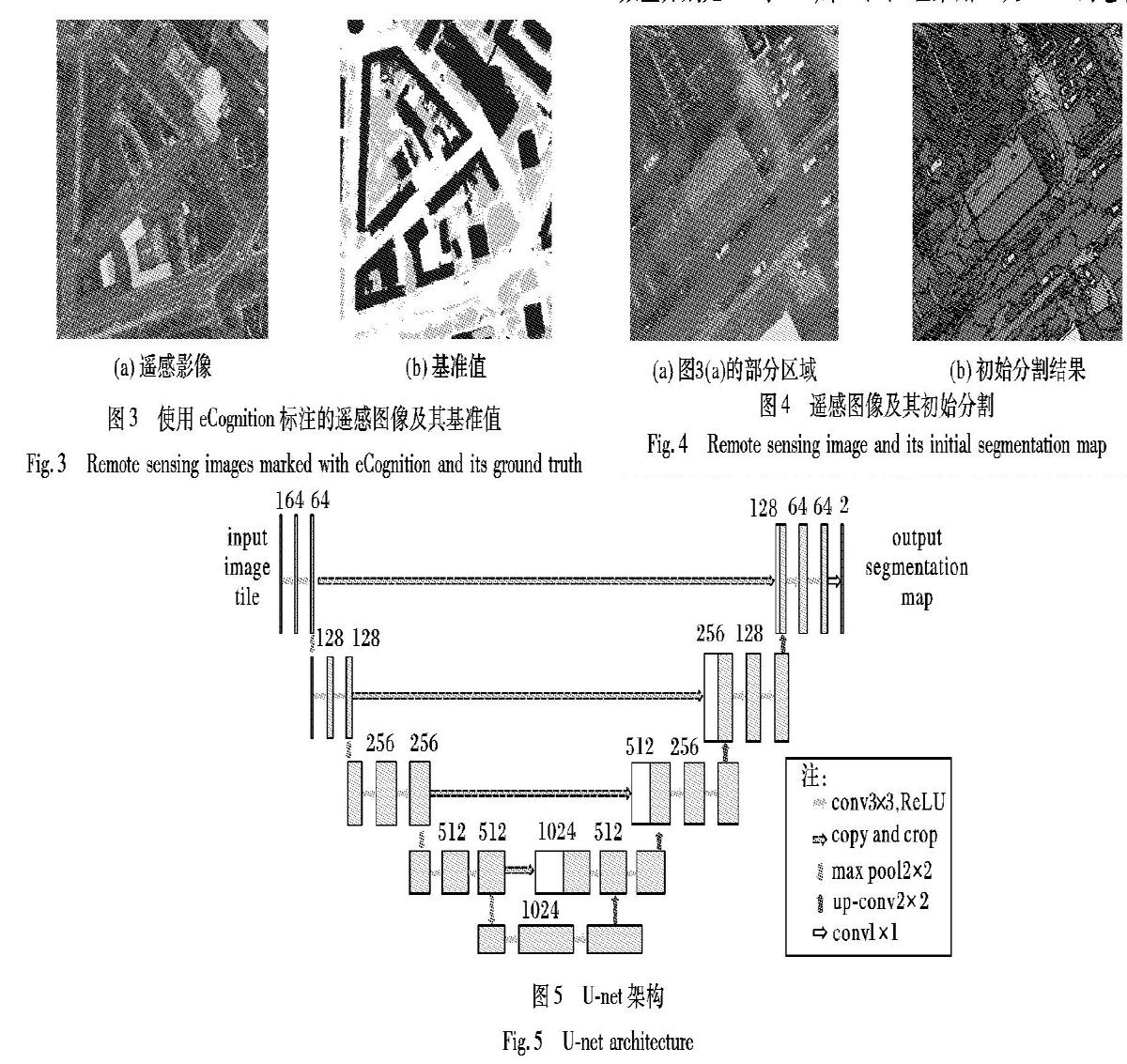
U-net常被用于医学图像的分割,它所处理的医学图像背景单一、复杂度低,所以使用低复杂度的基础模型U-net能够达到很高的精度且在精度与复杂度之間达到平衡,U-net的网络架构如图5所示。
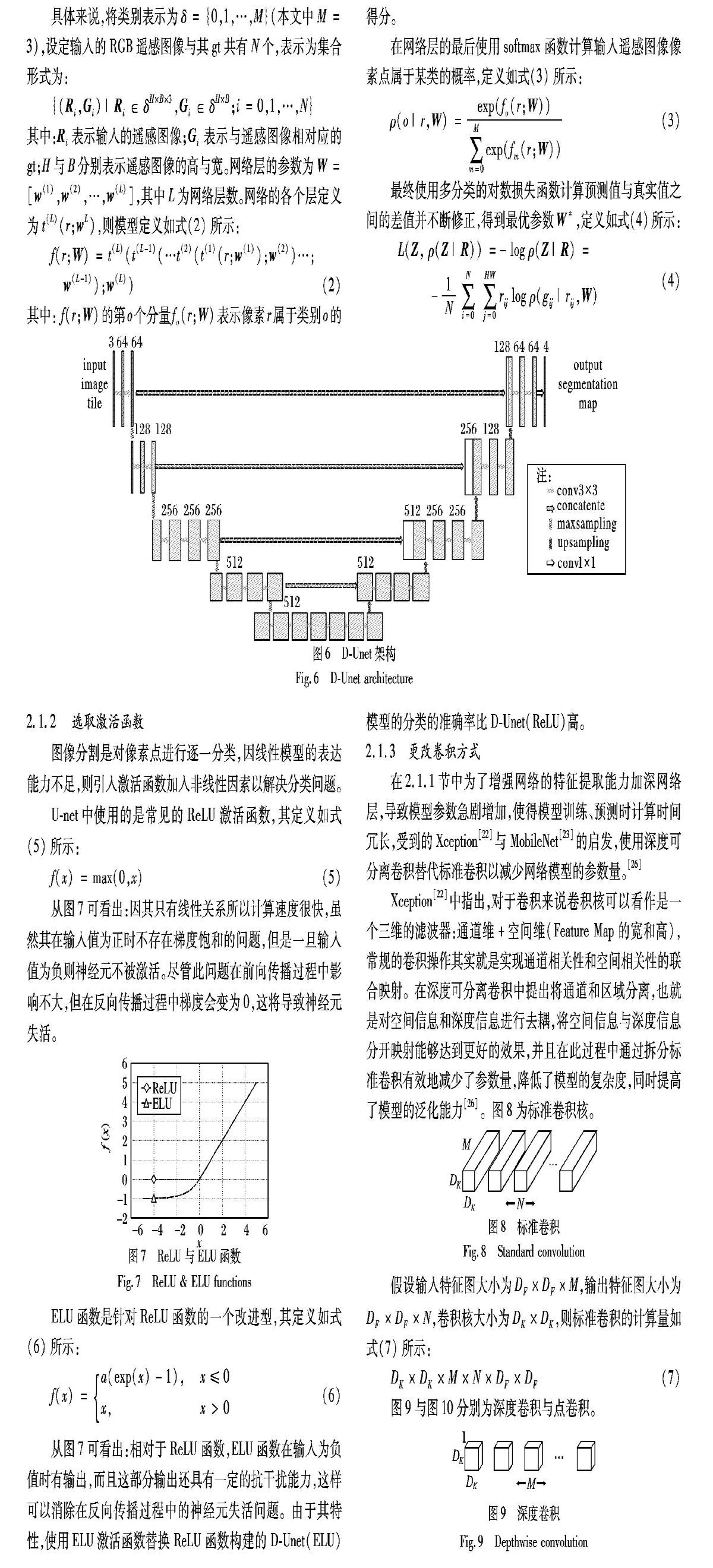
本文所使用的Potsdam遥感图像数据背景复杂,包含丰富的地物种类,且遥感光谱范围广泛,U-net并不能有效地提取复杂的遥感图像的像素特征,所以通过加深U-net的深度构建D-Unet以提取更加复杂的光谱特征。D-Unet的网络架构如图6所示。
网络的左半部分为下采样模块,依据VGG16所构建,它是卷积神经网络中的一种典型结构,通过逐渐缩减输入数据的空间维度以提取高维特征。其核心为5组conv与MaxPooling,其中第1、2组采用2次3×3的卷积运算,卷积核数量分别是64与128,第3、4、5组采用3次3×3的卷积运算,卷积核数量分别为256、512、512。在每一个卷积运算以后加入BN(Batch Normalization)层,对网络层的每一层的特征都做归一化,使得每层的特征分布更加均匀,在提高模型收敛速度的同时又能够提高模型的容错能力。[26]
网络的右半部分与左半部分呈中心对称,它由一系列的上采样层构成,其核心为与下采样相对应的5组Upsampling与conv,每一组conv的输入除了上一层进行Upsampling得到的深层抽象特征外,还有与其对应的下采样层输出的浅层局部特征,将深层特征与浅层特征通过Concatente方式融合,从而恢复了特征图细节并保证其相应的空间信息维度不变。[26]
从图7可看出:相对于ReLU函数,ELU函数在输入为负值时有输出,而且这部分输出还具有一定的抗干扰能力,这样可以消除在反向传播过程中的神经元失活问题。由于其特性,使用ELU激活函数替换ReLU函数构建的D-Unet(ELU)模型的分类的准确率比D-Unet(ReLU)高。
2.1.3 更改卷积方式
在2.1.1节中为了增强网络的特征提取能力加深网络层,导致模型参数急剧增加,使得模型训练、预测时计算时间冗长,受到的Xception[22]与MobileNet[23]的启发,使用深度可分离卷积替代标准卷积以减少网络模型的参数量。[26]Xception[22]中指出,对于卷积来说卷积核可以看作是一个三维的滤波器:通道维+空间维(Feature Map的宽和高),常规的卷积操作其实就是实现通道相关性和空间相关性的联合映射。在深度可分离卷积中提出将通道和区域分离,也就是对空间信息和深度信息进行去耦,将空间信息与深度信息分开映射能够达到更好的效果,并且在此过程中通过拆分标准卷积有效地减少了参数量,降低了模型的复杂度,同时提高了模型的泛化能力[26]。图8为标准卷积核。
当卷积核大小为3×3时,理论上深度可分离卷积的计算量为标准卷积的1/9。
本文主要利用深度可分离卷积降低参数量的特性,在D-Unet(ELU)基础上构建轻量级模型DS-Unet(ELU),其参数量大致减为原参数量的1/6,模型的预测时间大致为原时间的1/3。
2.1.4 预防过拟合
过拟合是所有深度模型在训练过程中都会遇到的问题,一般可以采用Dropout正则化解决。Dropout是以某个概率值暂时丢弃隐藏层的神经元来达到对网络进行“瘦身”的目的以降低网络的复杂度。
当某一节点在某次迭代中被随机选为抛弃点,那么神经网络在此次迭代中的forward过程会将此节点输出设为0,在backward过程中不会更新其权重和偏置项,则在某次迭代中节点随机失活不会参与训练,减弱了神经元节点间的联合适应性,增强了泛化能力。在此模型中添加rate=0.5的Dropout层用以防止过拟合。
2.2 基于全连接条件随机场的细分割
全卷积神经网络虽然能够实现像素级别的分类,但是得到的分割结果往往不够精细,存在边界不平滑和像素点定位不准确等问题,主要原因在于全卷积网络在像素点分类过程中很难考量到像素与像素之间的空间关系,导致像素级分类结果缺乏空间一致性。已有研究表明,使用全卷积网络得到像素级分类结果之后,再使用条件随机场(Conditional Random Field, CRF)综合图像的空间信息,能够得到更加精细并且具有空间一致性的结果[24,27]。针对本文中的分割问题,使用条件随机场考量像素点之间的空间位置关系,可进一步改进像素分割结果。条件随机场试图对多个变量在给定观测值后的条件概率进行建模。具体来说,若令
条件随机场的能量函数E(Y|X)主要由一阶势函数φ1和二阶势函数φ2组成。在像素级分类任务中,通过训练使条件随机场的势能最小,则可以使相似的像素有较大的概率分为同一类别,定义如式(10)所示:
3 实验与分析
3.1 实验
3.1.1 实验环境
本文实验环境分为网络训练和网络测试两个部分。
网络训练部分使用TeslaV100,内存16GB,共享内存8GB;软件环境为Ubuntu16.04,Python3.5,TensorFlow1.9.0,Keras2.2.4。
网络测试部分使用MacBookPro,CPU 2.2GHz Intel Core i7,内存16GB,显卡Intel Iris Pro 1536MB;软件环境为MacOSMojave10.14.3,Python3.5,Tensorflow1.9.0,Keras2.2.4。
3.1.2 数据增强
在第1章中的38张TOP及其对应的gt中随机选取24张进行随机切割、旋转、镜像、模糊、光照调整以及噪声(高斯噪声、椒盐噪声)等数据增强处理,生成30万张256×256大小的训练及验证集,剩余的14张TOP及其对应的gt用作测试集。
3.1.3 模型训练
在3.1.1节中的实验环境下对图5所示的网络模型进行训练。模型在使用Tensorflow作為后台的Keras深度学习框架下训练。权值初始化采用Glorot等[28]提出的方法。模型训练采用批处理方式,将300000×0.75(75%的图片作为训练集,其余作为验证集)张图片每32张作为一个批次(batch)输入模型进行训练,总共需要3984个批次完成一个epoch,设定模型总共遍历数据集50轮。训练时使用multi_gpu_model()函数同时调用4个GPU进行,优化器选用sgd,损失函数使用多分类的对数损失函数。在模型训练的过程中使用Callbacks函数中的ModelCheckpoint存储最优模型,设定监测对象为准确率,当它最大时自动保存最优权值;训练时使用Callbacks函数中的EarlyStopping监测模型训练情况,当达到指标时可提前终止训练,节省时间并且能够预防过拟合;训练过程中的学习率使用Callbacks函数中的ReduceLROnPlateau自适应调整,以适应训练过程中的动态变化,如图12所示;训练过程使用Tensorboard监测并可视化。训练模型的部分参数如表3所示。
从图13~14可看出,随着迭代次数的增加,曲线波动减小,准确率与训练损失变化趋于平缓,模型趋于收敛。图15~16反映了随着迭代次数的增加,验证集的准确率与损失值变化趋于平缓,损失函数基本收敛,表明模型达到了最优。
3.1.4 数据可视化
使用训练模型预测的结果被写入灰度图中,像素值位于0~3,将其转化为RGB图像,转化关系如表4所示。
3.1.5 基于像素的面积测算
数据集Potsdam的地面采样距离为5cm,为依据像素点数量进行面积测算提供了先决条件,每个像素点所表示的面积为5×5cm2,则只要统计像素数量即可进行遥感图像主要地物信息的面积测算,如式(13)所示:
其中:g为地面采样距离;n为像素点数量。
3.2 分析
3.2.1 性能评价
对分类后的遥感图像,使用混淆矩阵[29-30]、均交并比(Mean Intersection over Union, MIoU)与平均绝对误差(Mean Absolute Error, MAE)进行评估。遥感图像信息提取被视为一种多分类问题,可用混淆矩阵将预测输出的分类结果和gt进行像素级比较,评价每个像素的预测输出结果,即该像素分类结果取真阳性(True Positive,TP)、假阳性(False Positive,FP)、真阴性(True Negative,TN)、假阴性(False Negative,FN)四种结果中的一种,然后根据这四个指标计算以下指标:
3.2.2 结果分析
图17前两列为TOP、gt以及使用不同方法分割并可视化的结果,其中D-Unet(ELU)_CRF相对于D-Unet(ELU)是在粗分割的基础上使用CRF进行了细分割。
对比D-Unet(ReLU)与U-net(ReLU)的分割结果可看出:U-net网络构架改进后能够更精确地对地物像素点进行分类;在使用ELU函数替换ReLU函数后,D-Unet(ELU)的分割结果明显优于D-Unet(ReLU);在使用深度可分离卷积代替标准卷积构建为DS-Unet(ELU)后,模型分割准确率会略微下降,但是其由于网络参数少,预测时间减少很多,可用于对预测精度要求不高但有时效性要求的场景下。
对比D-Unet(ELU)_CRF与D-Unet(ELU)的分割结果可看出:在使用全连接条件随机场对粗分割结果进行优化后,在保证地物区域完整性的前提下精细化边界区域,增强了地物信息的完整性,得到了更为优异的分割结果。
图17后六列是对前两列的局部细节展示,分别是各个模型对植被、不透水表面(白色区域为不透水表面)与建筑物的分割结果。从中可看出:D-Unet(ELU)_CRF所得结果在精确度、边缘明晰度上要明显优于其他方法。在使用全连接条件随机场细分割后,对于D-Unet(ELU)存在的明显错分类进行了纠正,边缘也更加接近gt;
而D-Unet(ReLU)与DS-Unet(ELU)分割出的结果孤立点较多, 且建筑物分割不太完整, 边缘的错误比较显著,U-net(ReLU)模型甚至存在严重的错分类与欠分割问题,在建筑物的像素分类上尤为明显。
从表5可看出:
D-Unet(ReLU)的准确率、精确率、召回率、F1-score、MIoU分别较U-net提升了12.47个百分点、22.25个百分点、25.98个百分点、0.2604、0.3235,平均绝对误差降低了0.01744,验证了模型结构改进的有效性;
D-Unet(ELU)的准确率、精确率、召回率、F1-score、MIoU分别较D-Unet(ReLU)提升了2.59个百分点、2.12个百分点、4.13个百分点、0.0257、0.0427,平均绝对误差降低了0.01148,表明改用ELU函数后模型分割的效果更佳。
在使用全连接条件随机场对D-Unet(ELU)的粗分割结果优化以后,遥感图像分割的准确率准确率、精确率、召回率、F1-score、MIoU较D-Unet(ELU)有略微的提升,平均绝对误差略微下降,说明了所构建的D-Unet(ELU)_CRF模型的有效性。
在使用深度可分离卷积替换标准卷积后,模型的表现性能有所下降,的准确率、精确率、召回率、F1-score、MIoU分别较D-Unet(ELU)下降了2.85个百分点、1.98个百分点、3.7个百分点、0.0286、0.0474,DS-Unet(ELU)的平均绝对误差较D-Unet(ELU)升高了0.01542,但是与D-Unet(ReLU)相比性能差异不大。其优势体现在模型体积更小与预测效率的提升,因为其参数量更小,为标准卷积构成网络的1/6~1/5,具体见表6~7。
表7比较了D-Unet(ELU)、DS-Unet(ELU)与最先进的深度模型SegNet、FCN-8s、DeconvNet、Deeplab-ResNet以及RefineNet的复杂性。通过使用Intel Core i7对图像(平均尺寸2392×2191像素)执行测试的时间获得时间复杂度,同时表7还展示了深度模型的空间复杂度。可看出本文提出的D-Unet(ELU)模型在时间与空间复杂度上具有一定的竞争力,在使用深度可分离卷积卷积构建为DS-Unet(ELU)后在预测时间的消耗上大为减少,模型的大小也大为缩减。
在Potsdam的基准测试中,不同方法的定量比较如表8所示。其中:SVL_3算法使用SVL(Stair Vision Library)、归一化数字植被指数(Normalized Digital Vegetation Index,NDVI)、饱和度和归一化数字地表模型(Normalized Digital Surface Model,NDSM)训练基于AdaBoost的分类器以获得最优结果。Volpi等[31]的算法UZ_1与AZ1算法分别构建了不同的encoder-decoder结构的卷积神经网络。RIT_L2算法使用RGB与合成数据(红外线(Infrared Radiation,IR)、NDVI和NDSM)训练两个SegNet并进行特征融合。Sherrah[32]的算法DST_2使用FCN作为卷积模型并应用CRF作后处理。
从表8可看出,所有的方法都获得了良好的结果,本文所提出的分割模型D-Unet(ELU)的准确率最高,轻量级模型DS-Unet(ELU)也获得了较高的准确率。
本文所提出的网络优势在于只使用原始的RGB数据训练单个网络,在数据量以及模型对地物的分割精确率上都具有优势。
4 结语
针对目前人为勘测地物信息的任务耗费人力物力、办事效率低下等问题,本文提出了一种全卷积神经网络和全连接条件随机场的遥感图像地物信息分割方法,构建D-Unet(ELU)和DS-Unet(ELU)模型,对遥感图像实现像素級别的分类,解决了传统方法普遍存在的过程繁琐、方法普适性低、泛化能力弱的问题。其中D-Unet(ELU)的分割准确率高,但时效性较低,适用于对分割精度高但时效性要求不高的应用场景;DS-Unet(ELU)的分割精确度较D-Unet(ELU)略微降低,但时效性高,适用于对精度要求不严苛却对时效性要求高且设备性能低的应用场景。本文首先通过对遥感图像进行标注、数据增强,将处理好的数据放入D-Unet与DS-Unet模型中拟合;然后将输出结果放入全连接条件随机场中进一步处理,使得分割结果更接近gt;最后利用遥感图像具有地面采样距离这一特点提出了基于像素的面积测算方法。与测试集进行对比后发现所提出的方法能够精确地分割目标地物,具有高效性、可实施性。但因参数batchsize受限于硬件设备,不能设置为较为理想的数值,在一定程度上影响了边缘分割的精细度, 训练模型的时效性还有待提升。如何在保证精确性的情况下进一步降低模型参数减少模型训练时间与预测时间是接下来的工作重心。
参考文献(References)
[1] 高海燕, 吴波. 结合像元形状特征分割的高分辨率影像面向对象分类[J]. 遥感信息, 2010(6): 67-72. (GAO H Y, WU B. Object-oriented classification of high spatial resolution remote sensing imagery based on image segmentation with pixel shape feature[J]. Remote Sensing Information, 2010(6): 67-72.)
[2] 巫兆聪, 胡忠文, 张谦, 等. 结合光谱、纹理与形状结构信息的遥感影像分割方法[J]. 测绘学报, 2013, 42(1): 44-50. (WU Z C, HU Z W, ZHANG Q, et al. On combining spectral, textural and shape features for remote sensing image segmentation[J]. Acta Geodaetica et Cartographica Sinica, 2013, 42(1): 44-50.)
[3] YUAN J, WANG D, LI R. Remote sensing image segmentation by combining spectral and texture features[J]. IEEE Transactions on Geoscience and Remote Sensing, 2014, 52(1): 16-24.
[4] PALENICHKA R, DOYON F, LAKHSSASSI A, et al. Multi-scale segmentation of forest areas and tree detection in LiDAR images by the attentive vision method[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2013, 6(3): 1313-1323.
[5] 都伟冰, 王双亭, 王春来. 基于机载LiDAR粗糙度指数和回波强度的道路提取[J]. 测绘科学技术学报, 2013, 30(1): 63-67. (DU W B, WANG S T, WANG C L. Road extraction based on roughness index and echo intensity of airborne LiDAR[J]. Journal of Geomatics Science and Technology, 2013, 30(1): 63-67.)
[6] 张曦, 胡根生, 梁栋, 等. 基于时频特征的高分辨率遥感图像道路提取[J]. 地理空间信息, 2016, 14(6): 18-21, 24. (ZHANG X, HU G S, LIANG D, et al. Road extraction from high resolution remote sensing image based on time frequency feature[J]. Geospatial Information, 2016, 14(6): 18-21, 24.)
[7] 周绍光, 陈超, 赫春晓. 基于形状先验和Graph Cuts原理的道路分割新方法[J]. 测绘通报, 2013(12): 55-57. (ZHOU S G, CHEN C, HE C X. A new road segmentation based on shape prior and graph cuts[J]. Bulletin of Surveying and Mapping, 2013(12): 55-57.)
[8] 周家香, 周安发, 陶超, 等. 一种高分辨率遥感影像城区道路网提取方法[J]. 中南大学学报(自然科学版), 2013, 44(6): 2385-2391. (ZHOU J X, ZHOU A F, TAO C, et al. A methodology for urban roads network extraction from high resolution remote sensing imagery [J]. Journal of Central South University (Science & Technology), 2013, 44(6): 2385-2391.)
[9] 曾发明, 杨波, 吴德文, 等. 基于Canny边缘检测算子的矿区道路提取[J]. 国土资源遥感, 2013, 25(4): 72-78. (ZENG F M, YANG B, WU D W, et al. Extraction of roads in mining area based on Canny edge detection operator[J]. Remote Sensing for Land & Resources, 2013, 25(4): 72-78.)
[10] BEUMIER C, IDRISSA M. Building change detection from uniform regions[C]// Proceeddings of the 2012 Iberoamerican Congress on Pattern Recognition, LNCS 7441. Berlin: Springer, 2012: 648-655.
[11] HUANG X, ZHANG L, ZHU T. Building change detection from multitemporal high-resolution remotely sensed images based on a morphological building index[J]. IEEE Journal of Selected Topics in Applied Earth Observations & Remote Sensing, 2013, 7(1): 105-115.
[12] 李煒明, 吴毅红, 胡占义. 视角和光照显著变化时的变化检测方法研究[J]. 自动化学报, 2009, 35(5): 449-461. (LI W M, WU Y H, HU Z Y. Urban change detection under large view and illumination variations[J]. Acta Automatica Sinica, 2009, 35(5): 449-461.)
[13] 田昊, 杨剑, 汪彦明, 等. 基于先验形状约束水平集模型的建筑物提取方法[J]. 自动化学报, 2010, 36(11): 1502-1511. (TIAN H, YANG J, WANG Y M, et al. Towards automatic building extraction: variational level set model using prior shape knowledge[J]. Acta Automatica Sinica, 2010, 36(11): 1502-1511.)
[14] LECUN Y, BOTTOU L, BENGIO Y, et al. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 1998, 86(11): 2278-2324.
[15] KRIZHEVSKY A, SUTSKEVER I, HINTON G E. ImageNet classification with deep convolutional neural networks[C]// Proceedings of the 25th International Conference on Neural Information Processing Systems. New York: Curran Associates Inc., 2012: 1097-1105.
[16] HE K, GKIOXARI G, DOLLR P, et al. Mask R-CNN[C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2017: 2961-2969.
[17] LONG J, SHELHAMER E, DARRELL T. Fully convolutional networks for semantic segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(4): 640-651.
[18] FARFADE S S, SABERIAN M J, LI L. Multi-view face detection using deep convolutional neural networks[C]// Proceedings of the 5th ACM International Conference on Multimedia Retrieval. New York: ACM, 2015: 643-650.
[19] RONNEBERGER O, FISCHER P, BROX T. U-net: convolutional networks for biomedical image segmentation[C]// MICCAI 2015: Proceedings of the 18th International Conference on Medical Image Computing and Computer-Assisted Intervention. Berlin: Springer, 2015: 234-241.
[20] GLOROT X, BORDES A, BENGIO Y. Deep sparse rectifier neural networks[J]. Journal of Machine Learning Research, 2011, 15: 315-323.
[21] CLEVERT D, UNTERTHINER T, HOCHREITER S. Fast and accurate deep network learning by Exponential Linear Units (ELUs) [EB/OL]. [2019-01-10]. http://de.arxiv.org/pdf/1511.07289.
[22] CHOLLET F. Xception: deep learning with depthwise separable convolutions[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, 2017: 1800-1807.
[23] HOWARD A G, ZHU M, CHEN B, et al. MobileNets: efficient convolutional neural networks for mobile vision applications[EB/OL]. [2019-01-10]. https://arxiv.org/pdf/1704.04861.pdf.
[24] KRHENBHL P, KOLTUN V. Efficient inference in fully connected CRFs with Gaussian edge potentials[C]// Proceedings of the 2011 International Conference on Neural Information Processing Systems. New York: Curran Associates Inc., 2011: 109-117.
[25] ALTMAIER A, KANY C. Digital surface model generation from CORONA satellite images[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2002, 56(4): 221-235.
[26] 許玥. 基于改进Unet的遥感影像语义分割在地表水体变迁中的应用[D].重庆:重庆师范大学,2019:16-35. (XU Y. Application of semantic segmentation of remote sensing image based on improved unet in surface water change[D]. Chongqing: Chongqing Normal University,2019:16-35.)
[27] ZHENG S, JAYASUMANA S, ROMERA-PAREDES B, et al. Conditional random fields as recurrent neural networks[C]// Proceedings of the 2015 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2015: 1529-1537.
[28] GLOROT X, BENGIO Y. Understanding the difficulty of training deep feedforward neural networks[J]. Journal of Machine Learning Research, 2010, 9: 249-256.
[29] ODENA A. Semi-supervised learning with generative adversarial networks[EB/OL]. [2019-01-10]. https://arxiv.org/pdf/1606.01583.pdf.
[30] HUANG B, ZHAO B, SONG Y. Urban land-use mapping using a deep convolutional neural network with high spatial resolution multispectral remote sensing imagery[J]. Remote Sensing of Environment, 2018, 214: 73-86.
[31] VOLPI M, TUIA D. Dense semantic labeling of subdecimeter resolution images with convolutional neural networks[J]. IEEE Transactions on Geoscience and Remote Sensing, 2016, 55(2): 881-893.
[32] SHERRAH J. Fully convolutional networks for dense semantic labelling of high-resolution aerial imagery[EB/OL]. [2019-01-10]. https://arxiv.org/pdf/1606.02585.pdf.
