基于特征选择的M-SVM中文文本分类
2019-11-14刘永芬程丽陈志安
刘永芬 程丽 陈志安

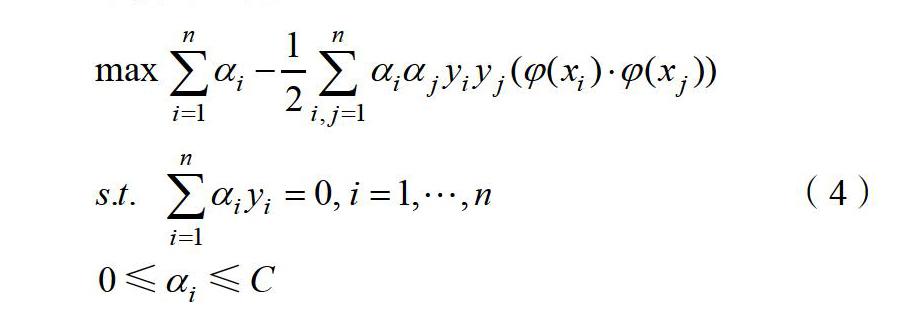
摘 要: 在文本分类领域,中文文本需要经过数据处理,将文档表达成计算机可以理解并处理的信息。本文采用TF-IDF作为文本表示方法,针对中文文章的多分类问题,对传统支持向量机进行改进,提出了一种基于特征选择的多类支持向量机分类方法。在中文文章数据集的对比实验结果表明,本文的方法在多分类性能上较优于其他模式识别方法。
关键词: M-SVM;特征选择;中文文本分类
中图分类号: TP391 文献标识码: A DOI:10.3969/j.issn.1003-6970.2019.09.016
本文著录格式:刘永芬,程丽,陈志安. 基于特征选择的M-SVM中文文本分类[J]. 软件,2019,40(9):71-74
Chinese Text Classification of M-SVM Based on Feature Selection
LIU Yong-fen1, CHENG Li1, CHEN Zhi-an2
(1. Jinshan College of Fujian Agricultural and Forestry University, Fuzhou Fujian 350002;2. China Mobile Communication Group Company Limited Fujian Branch, Fuzhou Fujian 350001)
【Abstract】: In the field of text classification, Chinese text needs to be processed through data processing, and the document can be reached into information that can be understood and processed by computer. In this paper, TF-IDF is used as the text representation method to improve the traditional support vector machine (SVM) for the multi-classification problem of Chinese articles, and a multi-class support vector machine classification method based on feature selection is proposed. The experimental results show that the proposed method is superior to other pattern recognition methods in multi-classification performance.
【Key words】: Feature selection; Chinese text classification
0 引言
在网络信息高速传输并呈爆炸式增长的时代,中文信息处理也迎来了前所未有的挑战。互联网产生的文本数据呈现出半结构化或非结构化等特点[1],不利于计算机直接处理,因此如何从互联网中文信息中获取知识,快速有效地组织成用户所需的信息成为文本挖掘的主要任务。自动文本分类作为其中的一个重要分支,也逐渐成为学者们研究的热点。支持向量机SVM由Cortes在1995年提出的[2],基本思想是通过构造一个非线性的超平面,实现对输入空间的分类。支持向量机的求解主要是解决二次规划优化问题,通过求解得到的支持向量所描述的最大边缘间隔来区分两类,当数据集特征较稀疏时,SVM也拥有较好的分类能力[3]。许多学者将其应用于图像处理、人脸识别、仿真预测等领域[4-5]。Goudjil等[6]提出了一種新的基于SVM的文本分类主动学习方法,实验表明将SVM应用于文本分类领域的可行性。Zainuddin等[7]通过实验证明特征选择在情感分析中起到了重要的作用。陈海红[8]将多核SVM应用于文本分类。也有学者提出了一种将SVM与BP神经网络相结合的分类方法[9]。王非[10]提出了基于微博的情感新词发现方法。然而多数文献将SVM应用于英文文本分类,而情感分析通常是二分类问题,针对中文文章分类的多类问题还需要将传统的二分SVM算法进行改进,以期能够解决序列数据的多分类问题。
为此,本文提出了一种基于特征选择的M-SVM中文文章多分类方法。通过文本预处理,对文章进行分词、去除停用词,设置最小/最大文档频率阈值进行特征选择,将文本的TF-IDF特征表示作为层次SVM分类模型的输入。通过多次对比实验实验结果表明,本文的方法较其他方法具有较高的分类精度。
1 文本预处理
1.1中文分词
在自然语言处理技术中,由于英文每个单词间都以空格作为分隔符,因此处理英文文本并对一篇英文文章提取特征要比处理中文文本简单许多。中文文本中字字相连,词和词组的边界模糊,要获取特征必须有分词这道工序。不同的中文分词方法会产生不同的切分效果,例如语句“你说的确实在理”,存在多种切分,分成的词可能的情况有 “的确”、“确实”、“实在”,然而结合语义,将语句分为“你说的/确实/在理”更为恰当。再如语句“2018年底部队友谊球赛”,可能存在的歧义有“底部”、“部队”、“队友”,而分词不能曲解原文的含义,因此寻找一个合适的分词方法显得尤为重要。jieba分词采用一种有序的字典树构造词条字典,用于保存关联数组,通过该技术分词的结果为“2018/年底/部队/友谊/球赛”,由此可见该分词方法在一定程度上有效地解决了交叉歧义的问题。
1.2 TF-IDF文本表示
TF-IDF是一种统计方法,在给定的语料中,TF(Term Frequency)词频指的是特定词语在文档中出现的次数除以文档的词语总数。IDF(Inverse Document Frequency)逆向文档频率指数表示一个词语的权重指数,可以由总文件数目除以包含该词语之文件的数目,再取对数得到。计算出每个词的词频和权重指数后相乘,可得到该词在文档中的重要程度。如果某一特定语料中的有一个词有高词语频率,以及该词语在整个语料中的低文件频率,可以得到较高的TF-IDF值[11]。
1.3特征选择
特征选择就是从一组特征集(包含特征数量为m)中挑选出一些最有效的特征特征子集(包含特征数量为d)以达到降低特征空间维度的目的,即建立一个从高维特征空间到低维特征空间的映射f:Rm→Rd,其中d
传统SVM算法假设分类问题在H上是线性可分的,那么在H空间中构造最优超平面为:
![]() (1)
(1)
求解的初始优化问题转化为:
 (2)
(2)
其中,C为惩罚因子,表示对错分样本的惩罚程度,C值越大,对目标函数的损失也越大。上式的求解在保持基于VC维的上界小的基础上,通过最小化![]() 达到经验风险最小化。引入松弛变量能够消除个别样本点对分类器的不良影响,在训练错误和泛化能力间有所折中,所以它具有一定的鲁棒性。满足式(2)中约束条件的最小松弛变量
达到经验风险最小化。引入松弛变量能够消除个别样本点对分类器的不良影响,在训练错误和泛化能力间有所折中,所以它具有一定的鲁棒性。满足式(2)中约束条件的最小松弛变量![]() 为:
为:
![]() (3)
(3)
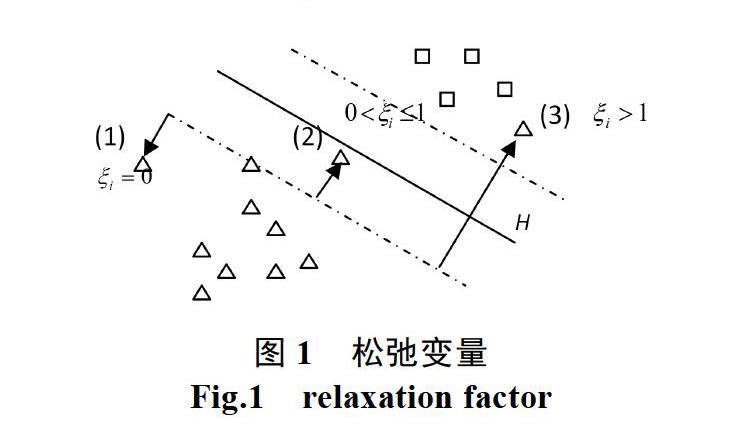
从图1-3可以看出,(1)当![]() =0时,表示样本点位于分类边界之外或者在边界上,分类正确;(2)当0<
=0时,表示样本点位于分类边界之外或者在边界上,分类正确;(2)当0<![]() 1時,表示样本点位于分类面内,分类正确;(3)当
1時,表示样本点位于分类面内,分类正确;(3)当![]() >1时,样本点被错误分类。
>1时,样本点被错误分类。
对偶问题为:
 (4)
(4)
通过非线性映射:![]() :Rm→H,x→
:Rm→H,x→![]() ,将输入空间映射到Hilbert 空间H中,如果高维空间中只涉及
,将输入空间映射到Hilbert 空间H中,如果高维空间中只涉及![]() 的内积运算,即
的内积运算,即![]() ,而没有单独的
,而没有单独的![]() 出現,则可以用原始空间的函数实现高维空间的这种内积运算,无需知道非线性映射
出現,则可以用原始空间的函数实现高维空间的这种内积运算,无需知道非线性映射![]() 的具体形式。根据泛函的有关理论,只要一种核函数K(xi,xj)满足Mercer条件[12],它就对应某一变换空间中的内积,使得
的具体形式。根据泛函的有关理论,只要一种核函数K(xi,xj)满足Mercer条件[12],它就对应某一变换空间中的内积,使得
![]() (5)
(5)
因此,非线性支持向量机对应的判别函数为:
![]() (6)
(6)
根据Hilbert-Schmidt理论,核函数![]() 是满足Mercer条件的任意对称函数。常见的核函数如下:
是满足Mercer条件的任意对称函数。常见的核函数如下:
(1)poly多项式核函数:![]() ,d表示多项式的梯度。
,d表示多项式的梯度。
(2)Sigmoid感知核函数:![]()
![]()
(3)高斯核函数:
最常用是高斯核函数,此外,还有叠加核函数、样条核函数和傅里叶序列等。由于支持向量机允许使用不同的核函数,即允许使用不同的假设空间,所以它在解决多样应用问题时,具有一定的柔韧性。显然,支持向量机的鲁棒性和柔韧性也是我们设计解决其他问题算法时所渴求的[13]。然而传统的SVM只能解决二值问题,针对多类别文本分类问题,还需对其进行改进。
3 M-SVM算法
针对多类问题,弥补现有多类支持向量机算法的不足,本文提出了一种多类支持向量机M-SVM(Multiclass Support Vector Machine)方法。首先将所有类别分成两个子类,再将子类进一步划分成两个次级子类,如此循环直到每个子类只包含一个单独的类别为止,包含了不同类别的子类作为层次树的分支结点,只包含一类样本的子类作为层次树的叶子结点,从而形成了层次树结构模型。从某种程度上说,层次树模型是一种先验知识,其作用是指导支持向量机对待测样本做最后的分类。多类支持向量机的训练过程如图2所示。
对于待测样本x,先从根结点分类器对其进行划分,根据判别函数将其归为左子结点或者右子结点,逐层往下直至待测样本x被分配到某个叶子结点,则将待测样本x归到叶子结点所属的类别,分类过程结束。
4 实验结果与分析
实验数据为搜狐文章语料库24000篇文章,包含教育、新闻、体育、科技、健康、财经等12个类别,每篇文章采用jieba进行中文分词处理,对去除停用词后的数据运用TF-IDF对语料中的每一篇文章进行特征表示。M-SVM根据设置min_df,max_df等不同的参数,得到不同的分类精度。DF表示在语料中出现过某个词的文档数量,通过特征选择,忽略低于min_df文档频率以及高于max_df文档频率的词,得到特征选择后的文档TF-IDF特征表示,取数据集中90%作为训练集数据和10%作为测试集数据。通过多次实验得到以下分类精度,如图3所示。
从结果中我们发现随着特征数的增加,模型分类精度呈曲线上升趋势,当特征数达到16111时,分类精度达到最高,接着精度随特征数的增加略有下降。由此可知,对于语料中每篇文章按照一定的特征选择方法,选择出最能代表该文章的词,对于提高模型分类性能以及运行速度都具有很大的帮助。
再按照不同的训练集和测试集占比进行多次实验,并与Naive Bayes分类方法进行对比实验。经过多次实验对比,取各方法在当前数据集分类中表现最优的参数,其中min_df取40, max_df=3000;M-SVM的参数C设置为1,另外,gamma值太大容易造成过拟合,太小高斯核函数会退化成线性核函数,本文采用gamma值为0.5的高斯核函数;Naive Bayes的平滑参数alpha设置为1.5,通过调整训练样本与测试樣本之间的占比,得到各方法的分类精度如表所示。
从实验结果可知,随着训练数据越来越多,模型的分类精度也随着提高,其中M-SVM的在训练集样本占所有数据比例90%时,具有最好的文本分类效果。
5 总结
本文提出了一种基于特征选择的多类SVM方法,并与传统贝叶斯方法进行了比较实验,实验结果表明该方法在长文本分类中取得了较好的效果,它较大程度地提高中文文本的分类精度。在当前数据集中的实验可得,当文本特征数16111,训练集数据占90%时,模型具有较高的分类精度。由此可见,在训练数据较多的情况下,对于高维度数据采用一定的特征选择方法,选取最有代表性的特征来对文本进行表示,模型能够输出较好的分类性能。
参考文献
- 谢子超. 非结构化文本的自动分类检索平台的研究与实现
[J]. 软件, 2015, 36(11): 112-114.
[2] Cortes C, Vapnik V. Support-vector networks[J]. Machine Learning, 1995, 20(3): 273-297.
[3] Joachims T. Text categorization with Support Vector Machines: Learning with Many Relevant Features[M]. Machine Learning: ECML-98. Springer Berlin Heidelberg, 1999: 137- 142.
[4] 祁亨年. 支持向量机及其应用研究综述[J]. 计算机工程, 2004, 30(10): 6-9.
[5] 聂敬云, 李春青, 李威威, 等. 关于遗传算法优化的最小二乘支持向量机在MBR仿真预测中的研究[J]. 软件, 2015, 36(5): 40-44.
[6] Goudjil M, Koudil M, Bedda M, et al. A Novel Active Learning Method Using SVM for Text Classification[J]. International Journal of Automation and Computing, 2018, v.15(03): 44-52.
[7] Zainuddin N, Selamat A, Ibrahim R. Twitter Feature Selection and Classification Using Suport Vector Machine for Aspect-Based Sentiment Analysis[M].Trends in Applied Knowledge-Based Systems and Data Science. 2016, v.9799: 269-279.
[8] 陈海红. 多核SVM文本分类研究[J]. 软件, 2015, 36(5): 7-10.
[9] 王宏涛, 孙剑伟. 基于BP神经网络SVM的分类方法研究[J]. 软件, 2015, 36(11): 96-99.
[10] 王非. 基于微博的情感新词发现研究[J]. 软件, 2015, 36(11): 06-08.
[11] Trstenjak B, Mikac S, Donko D.KNN with TF-IDF based Framework for Text Categorization[J]. Procedia Engineering, 2014, 69: 1356-1364.
[12] Burges C. A Tutorial on Support Vector Machines for Pattern Recognition[J]. Data Mining and Knowledge Discovery, 1998, 2(2): 121-167.
[13] Amari S, Wu S. Improving support vector machine classifiers by modifying kernel functions[J]. Neural Networks, 1999, 12(6): 783-789.
