基于多属性决策的CEPH系统数据存储选择方法
2019-11-14林庆新
林庆新
(福州大学至诚学院,福建 福州 350002)
随着物联网、社交网络的发展,传统的存储模式已经很难满足要求,具有高可用、可扩展的云存储系统变得越来越重要。人们通常将个人的照片、视频或文档存储在云存储上,以方便随时随地的浏览和使用。据统计,全球数据中心将于每年37%的数据量复合式增长,其中88%的数据存储在公有云或私有云[1]。如何以低廉、高效便捷地提供海量的存储空间是亟待解决的问题。其中CEPH分布式存储系统是满足以上一系列条件的软件定义存储(SDS)系统之一,CEPH系统是Sage Weil在攻读博士期间设计了一种可以作为分布式存储的分布式文件系统[2],其通过CRUSH (controlled replication under scalable hashing)算法[3]计算得到数据对象的存储位置,取消对单一节点的依赖,实现无中心结构。以其开源特性以及通过RADOS模块提供块存储、对象存储和文件系统的统一存储能力,受到学术界和工业界追捧,在越来越多的企业中得到应用。
原生的CEPH系统以存储空间为Weight值通过CRUSH算法进行计算,使数据在各个磁盘上分布尽量均匀,同时为了保障数据安全性采用多副本存储模式。但CEPH作为大规模的分布式存储系统,由成百上千个存储节点组成,各个节点配置的服务器性能、网络性能等各异。并且不同的生产环境对存储的关注点也不同,相应的性能要求也不一样,有IO敏感型、延时敏感型、空间敏感型等要求。因此开展了一系列的对CEPH的性能优化的研究。
Edwin H M 等人提出了一种基于MapReduce的分治策略,保证了Ceph存储节点工作量负载的平衡,有效的解决了系统在处理较大数据量时计算应用迁移的问题[4]。加州大学圣克鲁兹分校的 Michael Sevilla 等人也提出了针对 Ceph 文件系统负载处理策略[5]。王勇等提出了基于软件定义网络和多属性决策的 Ceph 存储系统节点选择方法[6]。关注点均在如何高效地存储和查询元数据、如何把数据均匀地分散到不同的数据服务器,以及数据的可靠性等方面。并未考虑不同生产场景对存储性能及IO要求的差异,多属性决策对OSD选择的实现。
本文提出通过各个节点磁盘的IO性能、存储数据的冷热程度以及不同应用请求的优先级进行多属性决策来选择数据的存储位置和动态迁移策略。
1 相关工作及问题描述
1.1 数据存储过程
Ceph分布式存储采用了CRUSH算法对数据的分布和查找。存储数据时,文件会被拆分成Object对象,然后对Object哈希获取Oid。通过HASH(Oid)&mask获得Pgid,通过CRUSH(Pgid,Rules,……)获得OSD存储对象。在数据的存储和查找的整个过程中,影响最大的两个步骤是Oid到PG的映射和PG到OSD 的映射[2-3]。具体过程可用式(1)、式(2)表示。
HASH(Oid)&mask=pgid,
(1)
HASH(pgid,rules,…)=(OSD 0,OSD 1,…,OSDn)。
(2)
CEPH存储过程的伪代码如下:
输入:存储文件(file)
输出:object存储在OSD上
file=data.txt //要存储的文件对象
objects = splits(file) //将文件切分成多个除最后一个外的等大的小对象
for (i= 0;i< length(objects);i++)
{
obj_hash_value = hash(objects[i]) //获取对象的哈希值
pgid = obj_hash_value % pg_num //用对象的哈希值对pg_num取模,获取对应的pgid
osds = crush(pgid,rules,…)//通过crush算法计算pg对应的一组osds
1.2 数据读写过程
Ceph通过多副本的模式来保障数据的可靠性,通常通过规则约束尽量将副本存储在不同故障域的osd上。在数据强一致模式要求下,将多副本的一个副本设置为主副本,读取数据时只从主副本读取,写操作需要多副本全部写。
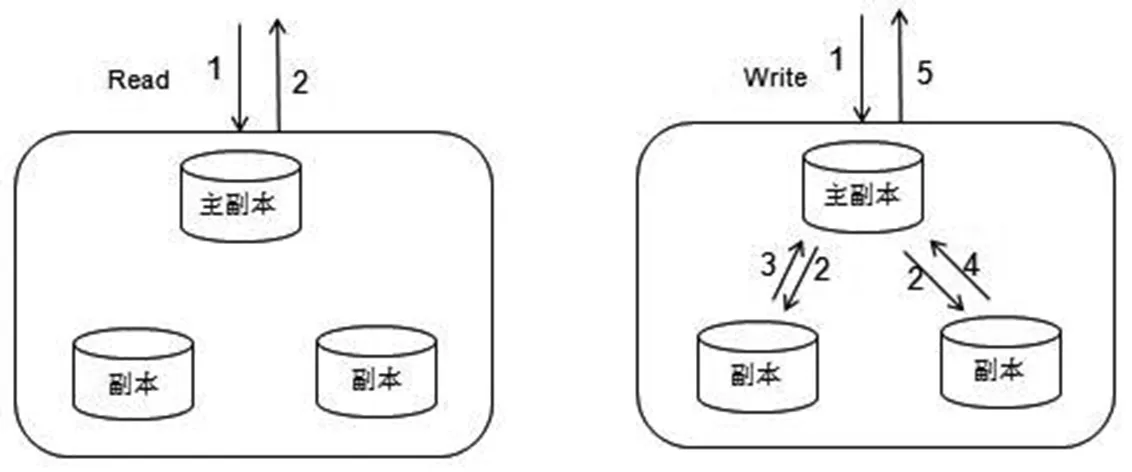
图1 多副本的数据读写模式Fig.1 Multi-copy data reading and writing mode
1.3 存在问题描述
通过上述对数据的存储过程和数据读写过程的描述,不难发现原生的CEPH存储系统具有灵活的扩展性、数据强一致性及存储空间的均匀分配具有良好的性能,但在存储数据特点、磁盘属性、应用场景需求等并未考虑具有优化空间。具体问题如下:
1)未考虑不同存储节点不同磁盘的读写性能不一样,如何对多副本多磁盘类型以最优化的组合方式提供服务。
2)储数据的访问满足Zipf定律[7],但是系统缺乏对数据访问的统计方式以确定冷热数据,确保优质资源用于高要求的热数据。客户端只与主副本 OSD 进行通信,从副本 OSD 的各项请求均由主副本 OSD 发出。所以如果将热数据的主副本存储在高IO能力的磁盘中可以较好地提高系统的性能
3)Ceph 存储集群从客户端接收数据不管是来自 Ceph 块设备、对象存储、还是文件系统。都是由 Ceph OSD 守护进程处理存储设备上的读/写操作。但是OSD守护进程采用的是先来先服务(first in first out,FIFO)策略,同等对待客户端的不同请求,以尽力服务(best effort)的方式顺序处理[8]。然而,它并没有考虑不同类型应用对IO请求的时效性要求,使得需要实时响应的IO请求和普通IO请求一同排队等待,从而导致整个系统服务质量降低。系统在高负载的情况下,缺乏一个保障机制确保高级别的数据优先得到保障。
2 多属性决策模型设计与实现
2.1 多属性设计与实现
2.1.1 充分考虑磁盘的IO性能(L)
通过数据的管理策略充分利用异构存储设备的性能,就能低投入产出大容量高性能的存储。那么如何有效的组合异构存储设备就显得尤为重要。本文以存储3副本及SSD和HDD两种磁盘类型为例,其中R1|R2|R3为3个副本,S表示SSD盘并以1表示,H表示HDD硬盘以0表示,L为组合读写负载能力。根据Ceph对数据的读写机制的分析,从表1中可以看出F8的读写性能都好、F1的读写性能都差、其它组合方式都有可能提高读得性能但无法提高写性能。组合的性能与L正相关。
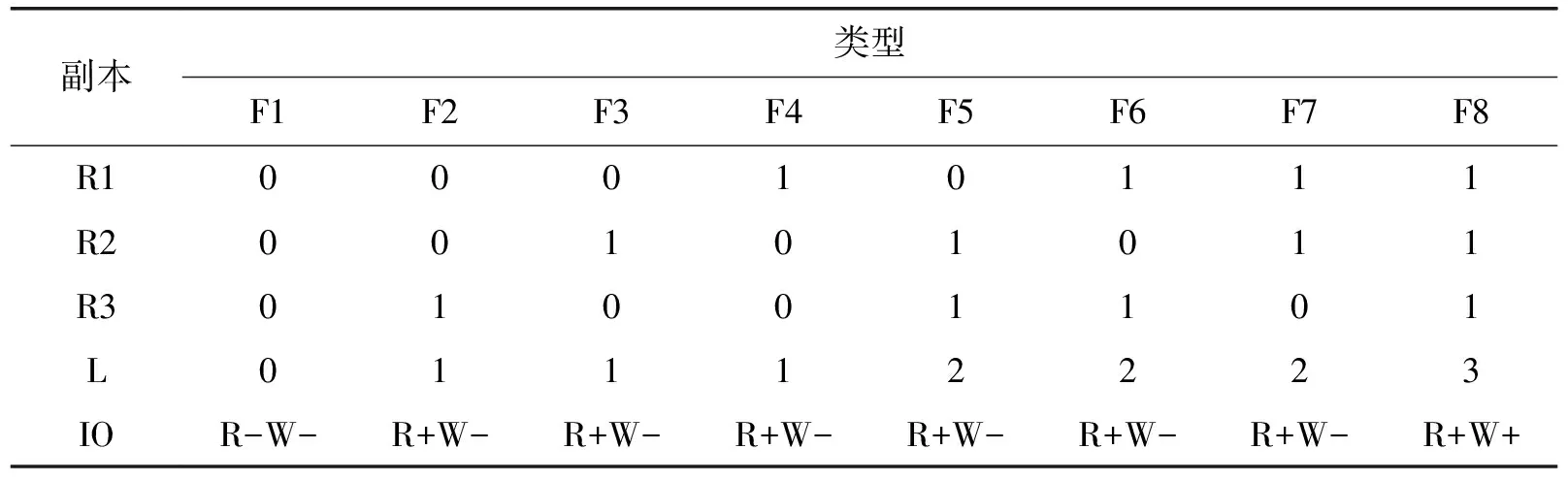
表1 副本与磁盘组合方式
2.1.2 数据的冷热识别与统计(H)
通过N版本布隆过滤器[8]统计数据的访问和读写情况。N版本布隆过滤器会保存N-1个历史版本和当前版本,不同的时间段数据的读写情况会记录在对应的过滤器上,经过一定的时间或一定的访问量,会根据的时间的逆序删除过滤器。
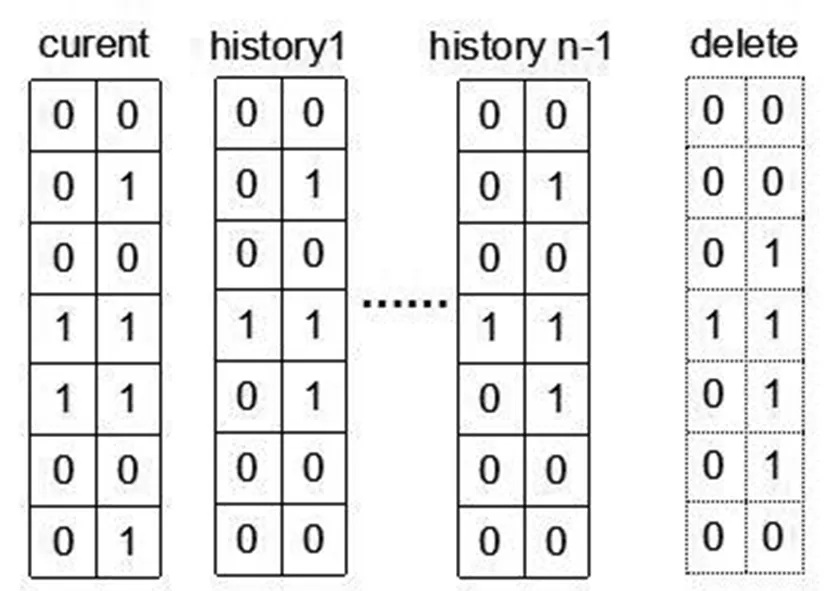
图2 N版本布隆过滤器Fig.2 N version Bloom filter
过滤器每个存储单元包含两位(初始化都为0),其中一位用来表示读写(0表示读,1表示写),一位用来表示是否被访问(0表示没被访问,1表示被访问过)。每次I/O请求都会在osd对应数据的过滤器上做修改,并遵守规则:读请求,不修改读写标志位;写请求,把读写标志位设为1。
通过统计数据对象的所有布隆过滤器的读写情况和访问情况就能判断出数据对象的冷热程度和读写情况。冷热数据与时间周期有关不能只单纯的统计布隆过滤器的访问数量,而描述数据集的热门程度显然不是单看其当前的访问量,应该计算其访问量与时间周期的比并对H进行排序。如式(3)所示,其中Ci为访问量,△t为单位时间,数据冷热度与Hi负相关,值越小说明读写需求越低。
Hi=Ci/△t
(3)
2.1.3 请求进程及数据的优先级(P)
客户端对集群的请求都是通过OSD的守护进展RADOS进行读写操作,CEPH提供统一的对象存储,包括块存储、对象存储和文件系统[9]。不同的存储对象在实际的生产环境不同,块存储通过RBD用于主机或虚拟机的存储对象,对象存储通过RADOSGW用于第三方存储系统的兼容与地接,文件系统通过CEPHFS用于文件系统的读写。在生产环境中对IO及延时的敏感性通常RBD>RADOSGW>CEPHFS,我们将其请求的优先级设为P。PRBD>PRADOSGW>PCEPHFS优先级越高在IO请求和资源配置上越优先保障
2.2 多属性决策选择OSD模型
除了磁盘容量外,本文提出决定OSD选择属性的还有磁盘IO属性(L),数据的冷热情况(H),数据的优先级(P)。LHP的3个属性假设为相互独立、离散的3个变量,那么可以归结为运筹学中的多属性决策问题。采用TOPSIS (technique for order preference by similarity to an ideal solution)方法进行分析[10]。3个指标中,磁盘的IO属性L为正指标,值越大说明磁盘的读写性能越好;数据优先级P为正指标值越大数据优先级越高;数据冷热情况H为负指标值越小说明数据读写需求越低。建立TOPSIS 模型中负号表示负指标,多属性决策选择OSD算法如下:
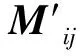
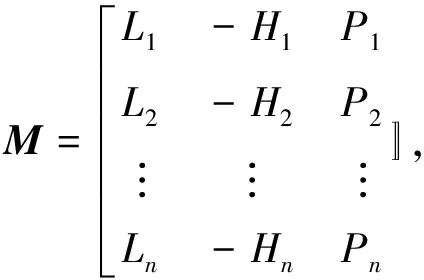
(4)
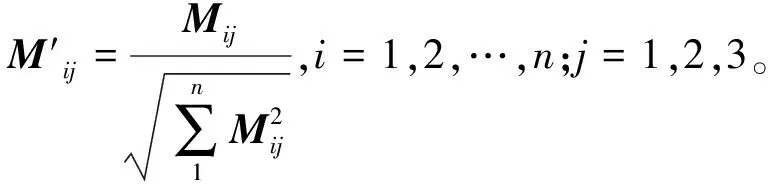
(5)
步骤2:磁盘的IO能力L,数据冷热程度H及数据的优先级P对OSD的选择权重是不一样的,设置适当的权重系数W,分别为WL,WH,WP权重系数可根据不同的应用场景进行调整。即可得权重系数矩阵W。由矩阵(5)×(6)可得osd,不同属性的选择权重值。
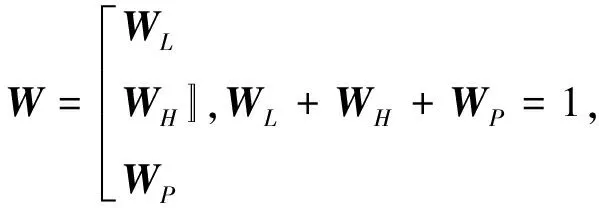
(6)
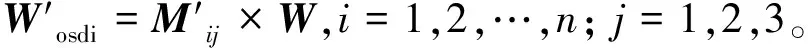
(7)
步骤3:通过式(7)就可以获得适合当前环境下的最优osd存储。
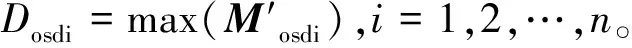
(8)
对存储节点的IO性能、数据读写情况以及请求进程的优先级3个属性通过TOPSIS方法进行多属性决策,选出最优的OSD存储方案。
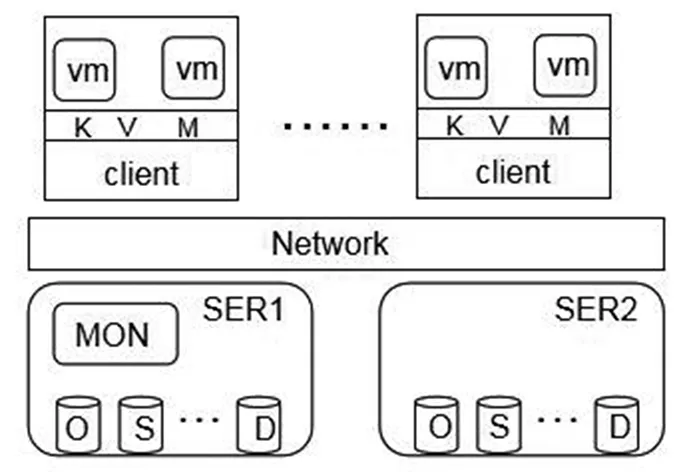
图3 实验环境拓扑 Fig.3 Experimental environment topology
3 实验及测试结果
3.1 测试环境
在本文测试中,使用了两台服务器,每台服务器均使用了3块SSD硬盘和4块HDD硬盘,其中1块SSD为系统盘而其他6块硬盘为Ceph的数据盘,运行Cent OS 7.0操作系统。将每块HDD硬盘做为一个OSD,每块SSD分成两个分区,做成2个OSD。存储集群中共16个OSD其中8个SSD和8个HDD。
采用fio软件用于监控和测试IO负载情况,通过Iometer进行块存储设备测试,采用Cosbench进行对象存储测试。
3.2 测试结果分析
主要通过测试软件对OSD的不同IO性能组合进行读写测试比较;在系统一定压力下,带有不同优先级的读写性能测试。测试主要参考标准为存储系统的读写响应时间。
3.2.1 IO性能测试
测试为3副本模式2类OSD及3种组合方式(3HDD、1SSD+2HDD、3SSD),数据的单次读写文件大小为128kB,进行顺序读、顺序写、随机读、随机写4种测试如图4、图5、图6、图7所示。
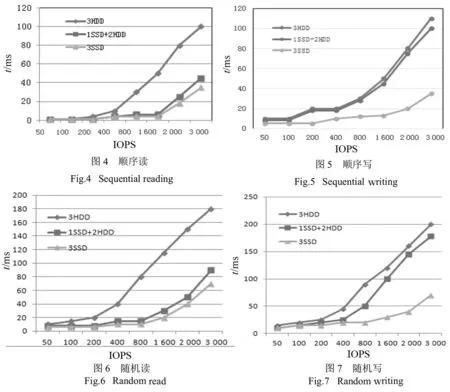
从实验结果分析,在考虑各个OSD的IO性能的情况并进行副本有效的组合,可以提高数据的读写性能。与3.1.1节分析情况基本吻合。并且对数据进行读写形成冷热数据,形成分层数据,对数据迁移和读写性能具有明显的提高。
3.2.2 数据优先级测试
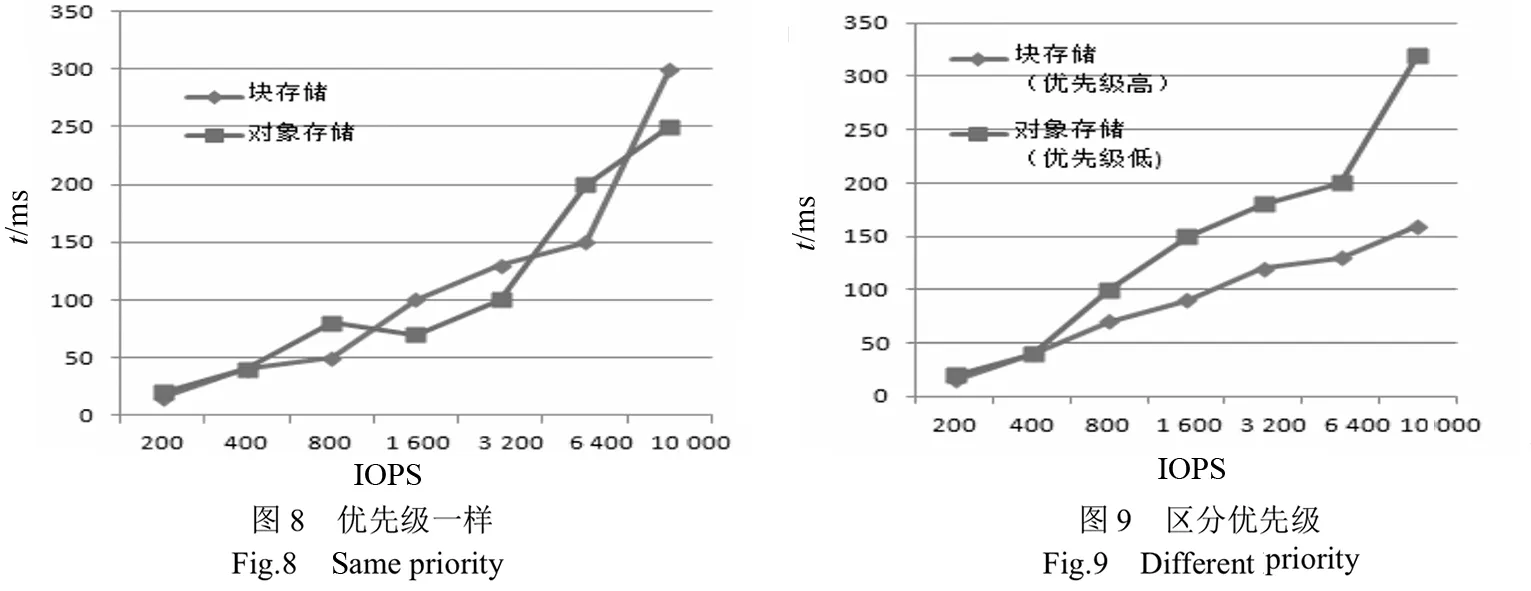
通过区分应用优先级和不区分优先级两种场景的两种应用对CEPH存储系统发起请求,通过Iometer和Cosbench对块存储和对象存储进行监控和测试,如图8、图9所示。
在存储系统达到一定负载压力的情况下,且不区分数据优先级的情况下,各应用以先来先服务的方式对资源进行抢占;在区分优先级的下,优先级高的应用得到优先保障,确保服务质量。
3.3 小结
通过上述对存储系统性能测试的结果表明,通过区分OSD的IO能力并进行有效组合、区分冷热数据、应用数据的优先级等多属性决策选择最优的OSD存储进行有效的数据管理和迁移方案,比对比原生的CEPH存储系统在读写性能得到有效的提升,同时能有效保障高优先级的应用场景,总体性能提升了13.7%。
4 结语
通过N版本布隆过滤器统计冷热数据、采集OSD的IO性能并进行有效组合、通过标注应用的优先级区分不同的应用场景,采用TOPSIS方法对多属性进行决策选择最优的OSD存储。通过实验表明本文提出的方法能够较好的弥补原生CEPH集群使用磁盘空间做为属性决策所带来的不足,优化了集群在读、写性能,同时保障优先级高的应用优先服务。下一步将继续研究基于神经网络学习方法实现存储系统对数据属性的自学习和属性权重的自优化方法。
