基于模糊核聚类和主动学习的异常检测方法
2019-11-12吕宗平时熙然顾兆军
吕宗平 时熙然 顾兆军


摘 要: 针对日志数据的异常检测获取标记数据代价过高的问题,提出一种基于模糊核聚类与主动学习的算法,即KFCM?AL算法。首先将日志解析,之后利用模糊核聚类算法将待选样本在高维空间进行划分聚类,滤去样本冗余点,同时选取聚类中心进行标记构建初始分类器,最后结合主动学习利用较小的标记代价对异常检测模型进行优化。实验结果表明,所提方法能够利用较少的标记样本获取异常检测模型的性能提升。
关键词: 异常检测; 模糊核聚类; 主动学习; 日志解析; 聚类分析; 性能对比
中图分类号: TN911.23?34; TP301.6 文献标识码: A 文章编号: 1004?373X(2019)20?0053?05
Anomaly detection method based on fuzzy kernel clustering and active learning
L? Zongping1, SHI Xiran1, 2, GU Zhaojun1, 2
(1. Information Security Evaluation Center, Civil Aviation University of China, Tianjin 300300, China;
2. College of Computer Science and Technology, Civil Aviation University of China, Tianjin 300300, China)
Abstract: In allusion to the problem of high cost of obtaining marking data for anormal detection of log data, an algorithm based on kernel fuzzy C?means and active learning (KFCM?AL) is proposed. The log is parsed, and then the samples under selection are classified and clustered in high?dimensional space by means of KFCM algorithm. The redundant points of samples are filtered out, at the same time the clustering center is selected to make marking and build the initial classifier. In combination with active learning, the anomaly detection model is optimized with a smaller marking cost. The experimental results show this method can improve the performance of the anomaly detection model with fewer marking samples.
Keywords: abnormal detection; fuzzy kernel clustering; active learning; log parse; clustering analysis; performance comparison
0 引 言
随着信息时代的来临,互联网也越发紧密地与人们日常生活联系起来,网络信息安全的重要性也越发突出,逐渐成为研究人员研究的焦点。异常检测是保障网络信息安全不可或缺的重要技术手段。与传统使用人工关键字搜索和规则匹配的手动查询模式相比,异常检测不仅可以发现已知的异常行为,还能检测出未知的异常行为[1],更适用于应对目前层出不穷的网络攻击方式,具有实际需求和应用价值。
系统日志数据记录了网络服务运行过程中详细的操作信息,以及各个关键点的系统状态和重要事件,是异常检测的主要数据源[2]。近年来将机器学习算法引入基于日志的异常检测,已经是一種流行趋势,比如文献[3]使用递归神经网络建立日志的系统故障预测系统,文献[4]使用决策树、逻辑回归等机器学习算法对日志进行异常检测并评估。由于机器学习异常检测需要有大量的标记数据来进行训练,在现实情况下的日志数据中是无标记的数据,有标记的数据非常有限,于是主动学习也应运而生。主动学习的基本思想就是通过启发式的采样策略,迭代地从未标记样本中选取最有价值的样本进行标注,从而减轻专家的工作[5]。同时主动学习也在异常检测方面受到关注,比如刘敬等人结合主动学习和单分类支持向量机进行异常检测[6]和朱东阳等人使用主动学习和加权支持向量机对工业故障进行识别[7]。但是主动学习算法的样本选择策略受限于初始训练集的样本质量,易选中不具有代表性的离群点和大量相同标签的样本,使人工标注的负担加重[8]。
为了降低样本数据的冗余度,选择最有价值的样本进行人工标注,提升主动学习的检测精度,本文利用模糊核聚类算法过滤冗余样本点,降低样本复杂度,同时选取置信度最高的聚类中心的样本进行人工标注,以此构建主动学习初始分类器。
1 基本算法
1.1 支持向量机
定义 最优超平面。若训练数据集可以无误差地被划分,并且每一类数据距离超平面最近的向量与超平面之间的距离最大,则称这个平面为最优超平面。
当求解的问题线性可分时,支持向量机的本质就是求得一个最优超平面,使得两类样本到达超平面的距离最大。
当求解的问题线性不可分时,为了利用支持向量机对样本集进行分类,将样本映射到高维空间使其线性可分,然后在高维空间构建最大間隔超平面来进行分类。设训练集W={(x1,y1),(x2,y2),…,(xj,yj)},其中[xj∈Rh]表示样本的h维特征向量,[yj∈{-1,1}]是样本的类别标记。在核函数[K(θ)]映射的高维核空间,通过求解式(1)可以获得最大间隔超平面。
式中:b为位移量,决定了超平面与原点的距离;[αi]为拉格朗日乘因子,[αi]=0时,它所对应的样本点对构造最优超平面没有贡献,只有当[αi][≠]0时,它所对应的样本点才被称为支持向量,对构造最优超平面有贡献。因此,这就意味着构建支持向量机的最优超平面仅由支持向量决定。
1.2 模糊核聚类算法
模糊聚类(Fuzzy C?Means,FCM)算法通过迭代目标函数,得到每个样本在各个类别的隶属度,使相似度最高的样本划分为同一类别[9]。通过划分未标注样本集G获得模糊划分矩阵U,聚类中心C={c1,c2,…,cj,cn},cj表示第j个簇的聚类中心。FCM算法的目标函数如下:
由于FCM算法处理高维数据划分精度不高,引用模糊核聚类(Kernel Fuzzy C?means,KFCM)算法进行聚类。KFCM算法引入核方法的思想:利用非线性映射把原始样本集合都映射到高维空间来扩大每个样本类之间的差距,以此达到在高维特征空间线性可分的目的[10]。由于高斯核函数通常具有良好的泛化功能,而且高斯核函数的核值范围为(0,1),可以简化计算过程,因此本文选用高斯核函数:
2 基于模糊核聚类和主动学习的异常检测方法
为了改善主动学习初始分类器的样本选择策略,降低样本冗余度,本文提出了一种新的基于模糊核聚类和主动学习的异常检测方法,即KFCM?AL(Kernel Fuzzy C?means?Active Learning)算法,利用KFCM算法将日志聚类并将聚类中心进行标记,同时过滤掉冗余点,然后将其馈送到主动学习分类器进行训练,从而生成异常检测模型。最后构建的异常检测模型可以识别新传入的日志数据是否为异常数据。
2.1 日志数据预处理
HDFS日志数据集是由亚马逊的EC2平台所运行的基于Hadoop作业而生成,并由该领域专家进行了标记,可以运用到任意异常检测中[11]。
HDFS日志数据集记录了每个块操作的唯一块ID。在数据预处理阶段,可以利用唯一块ID将日志分割成一组日志序列,使用LogSig算法将原始日志文件解析成结构化日志消息[12],每条日志消息包含HDFS块ID和日志事件。
HDFS日志数据集解析图如图1所示。
图1 日志解析过程
之后从日志序列中提取特征向量生成事件计数向量,每一行代表了一个HDFS块;每列表示日志事件类型;每个单元格计算某个HDFS块上事件的发生。提取后的特征向量如图2所示。
图2 日志事件特征向量
2.2 基于模糊核聚类和主动学习的异常检测算法
2.2.1 算法参数
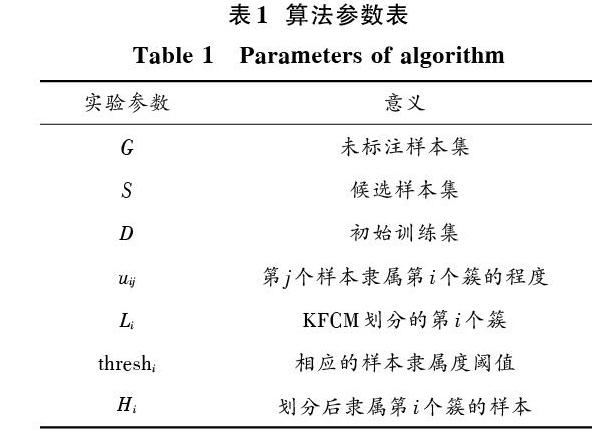
基于模糊核聚类和主动学习的异常检测算法所需参数如表1所示。
表1 算法参数表
2.2.2 KFCM?AL异常检测算法
在机器学习领域,按照训练样本的处理方法,支持向量机的学习方法可以分为被动学习和主动学习两种。被动学习随机地从数据集中选择样本进行训练,主动学习主动选择最有利于提升分类器性能的样本进行标记,从而减少训练所需标注样本个数。相较于被动学习,主动学习的选择策略可以用较小的代价获取分类器性能的改善[13]。
本文结合主动学习和KFCM算法,使用模糊核聚类算法划分的聚类中心构建候选训练集S,从S中随机选取一定的样本进行标记。令Li为KFCM划分的第i个簇,i=1,2,…,k,threshi表示样本相应的隶属度,取样规则如下:
利用KFCM算法将未标注样本集聚类成k个簇,将簇中心进行标记用于构建初始样本集,不需要全部样本点。
由支持向量机的特点可知, 未标注样本点离分类面越接近就越有可能成为新的支持向量, 从而重构和优化当前分类超平面, 提升支持向量机的分类精度。异常检测中,主动学习通常选择距离决策边界最近的样本进行标记,这些样本的不确定度最高,能够为模型提供最多的优化信息,该方法称为最近边界策略[6]。设x为被选中的待标记的样本,G为未标注样本集,D为训练样本集,其选择策略满足:
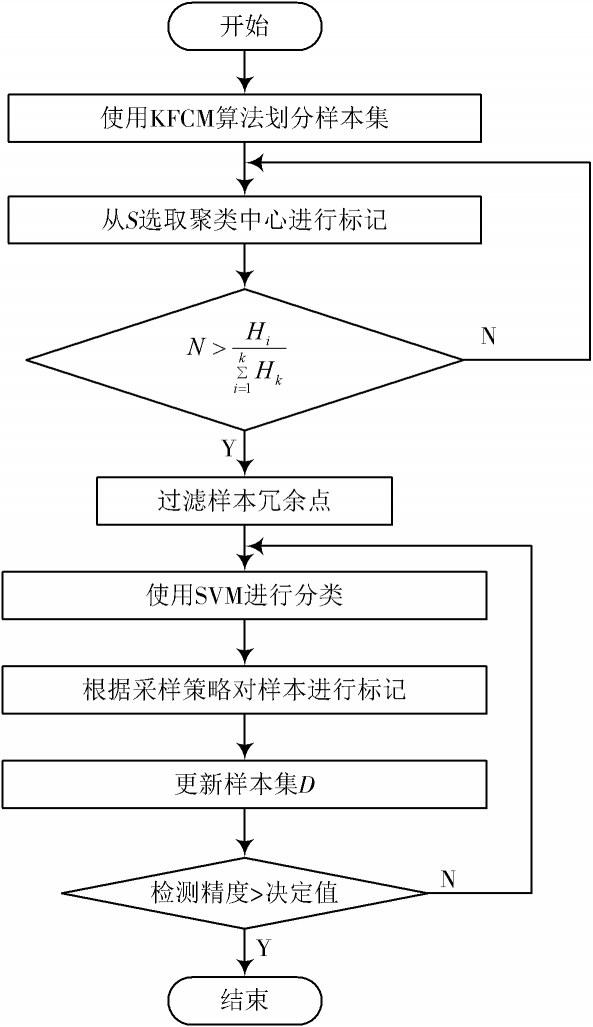
KFCM?AL算法的流程图如图2所示。算法步骤如下:
Step1:将初始样本集用模糊核聚类算法聚类,划分为L个样本簇。过滤掉单一类簇中的冗余数据,并选取聚类中心,进行标记构造初始训练集S,使S中至少包含一个输出y为1和一个输出y为-1 的样本;
Step2:根据初始训练集构造初始分类器f;
Step3:对所有样本使用f,根据样本选择准则从样本集中选择离分类边界最近的未标注样本[(x,y)],[y]为f给向量x预先打上的标注;
Step4:将该样本正确标注后加入训练集D中(y为x的正确标注);
Step5:若检测精度达到某一设定值,算法终止,返回f,否则重复Step2。
图3 KFCM?AL算法流程图
3 实验以及结果分析
为了验证KFCM?AL算法的有效性,使用Python语言编写程序实现算法,实验环境为Intel Core i7?3770 CPU 3.4 GHz处理器。实验目的是证明通过结合模糊核聚类算法和主动学习算法,可以有效地减少样本的复杂度,同时提高支持向量机的样本标记。对比方法选用随机取样算法和主动学习算法。
3.1 实验数据集和设置
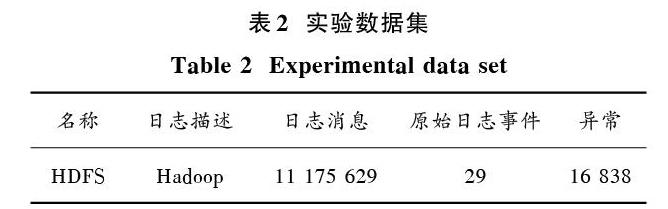
HDFS原始日志数据集包含从亚马逊EC2平台收集的11 175 629条日志消息,共记录29个原始日志事件,其中16 838条被原始领域专家手动标记异常,见表2。
表2 实验数据集
本文抽取5 000个日志事件计数向量,其中4 000個作为训练集,1 000个作为测试集。由于在实际的日志数据中正常的数据样本量远大于异常数据,所以在实验里标记异常数据占全部数据1.6%。
实验采用高斯核函数作为支持向量机的核函数,经过实验选择最优实验参数,设置核函数控制因子s2=2,惩罚因子C=1 024,模糊聚类算法最大迭代次数Vmax=150,样本隶属度阈值thresh=0.9。
实验使用准确率、召回率、误报率作为评价指标来评估异常检测方法的性能。准确率用于表示有多少样本被正确检测的百分比,召回率是检测到多少正确异常数据的百分比,误报率表示错误检测的样本占正确检测的样本的百分比。准确率越高表示模型总体检测性能越好,召回率越高表示模型的漏报率越低,灵敏度越高,误报率越低表示模型的检测精度越高。
表3 混淆矩阵

3.2 实验结果与分析
实验通过KFCM算法将样本进行聚类,然后结合支持向量机最优化超平面的思想,滤去样本的非支持向量,即数据样本冗余点。同时为了保证数据的完整性,只过滤掉单一类簇的非支持向量点,并选取样本中心进行标注。经过KFCM聚类后结果如图4所示。
图4 聚类结果图
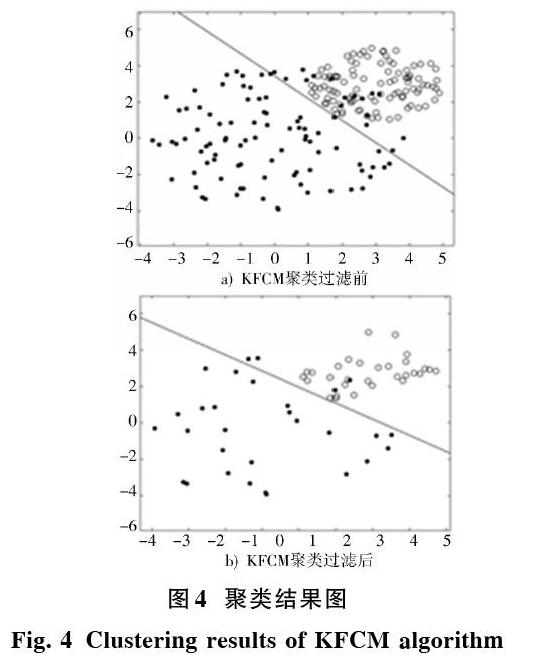
通过图4可以得知,KFCM算法可以滤去样本中的非支持向量点,使样本的复杂度降低,减少SVM算法进行学习训练的样本集规模,且避免SVM算法的过学习现象,提升SVM算法的检测精度。
为了对比算法的性能,保证达到同等异常检测条件下,实验选取随机取样和主动学习支持向量机作为对比算法。下面比较三者所需的标记样本数的比较结果。重复试验5次取平均值对3种算法进行对比,结果如表4所示。
表4 实验结果
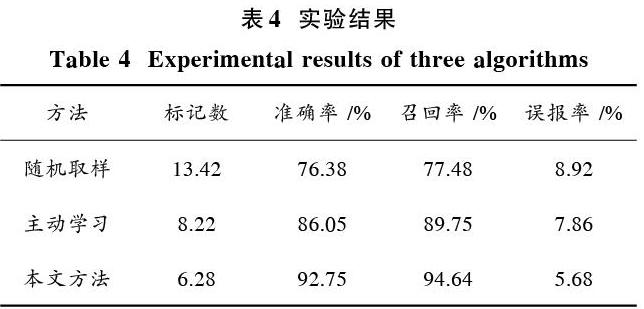
从实验结果可以看出,采用随机取样的方法需要的标记样本数最多,由于随机取样算法采集的样本多是正常数据且不在分类边界,所以检测精度效果最差;主动学习算法选择分类边界附近的点进行标记,由于这些点的置信度较低,所以标记这些点能为建立模型提供更多信息;本文方法采用模糊聚类与主动学习相结合,选取兼具代表性和置信度的样本点进行标记,更能充分利用样本的标记信息,减轻标记数据代价,获取的性能提升程度最高。
4 结 语
为了解决针对日志数据的异常检测获取标记数据代价过高的问题,本文提出一种基于模糊核聚类与主动学习支持向量机的算法。实验结果表明,本文方法能够利用较少的标记样本获取模型的性能提升。在未来的工作中,将结合日志数据研究更加适合的主动学习算法的选择策略和更具有专业性的日志解析方法。
注:本文通讯作者为时熙然。
参考文献
[1] 肖国荣.改进蚁群算法和支持向量机的网络入侵检测[J].计算机工程与应用,2014,50(3):75?78.
XIAO Guorong. Network intrusion detection by combination of improved ACO and SVM [J]. Computer engineering and application , 2014, 50(3): 75?78.
[2] DU M, LI F, ZHENG G, et al. DeepLog: anomaly detection and diagnosis from system logs through deep learning [C]// ACM Conference on Computer and Communications Security. Dallas: ACM, 2017: 1285?1298.
[3] ZHANG K, XU J, MIN M R, et al. Automated IT system failure prediction: a deep learning approach [C]// 2016 IEEE International Conference on Big Data. Washington: IEEE, 2016: 1291?1300.
[4] HE S L, ZHU J M, HE P J, et al. Experience report: system log analysis for anomaly detection [C]// 2016 IEEE 27th International Symposium on Software Reliability Engineering. Ottawa: IEEE, 2016: 207?218.
[5] 王一鹏,云晓春,张永铮,等.基于主动学习和SVM方法的网络协议识别技术[J].通信学报,2013(10):135?142.
WANG Yipeng, YUN Xiaochun, ZHANG Yongzheng, et al. Network protocol identification based on active learn and SVM algorithm [J]. Journal on communications, 2013(10): 135?142.
[6] 刘敬,谷利泽,钮心忻,等.基于单分类支持向量机和主动学习的网络异常检测研究[J].通信学报,2015,36(11):136?146.
LIU Jing, GU Lize, NIU Xinxin, et al. Research on network anomaly detection based on one?class and active learning [J]. Journal on communications, 2015, 36(11): 136?146.
[7] 朱东阳,沈静逸,黄炜平,等.基于主动学习和加权支持向量机的工业故障识别[J].浙江大学学报(工学版),2017,51(4):697?705.
ZHU Dongyang, SHEN Jingyi, HUANG Weiping, et al. Fault classification based on modified active learning and weighted SVM [J]. Journal of Zhejiang University (Engineering science), 2017, 51(4): 697?705.
[8] 吴伟宁,刘扬,郭茂祖,等.基于采样策略的主动学习算法研究进展[J].计算机研究与发展,2012,49(6):1162?1173.
WU Weining, LIU Yang, GUO Maozu, et al. Advances in active learning algorithms based on sampling strategy [J]. Journal of computer research and development, 2012, 49(6): 1162?1173.
[9] 唐成华,刘鹏程,汤申生,等.基于特征选择的模糊聚类异常入侵行为检测[J].计算机研究与发展,2015,52(3):718?728.
TANG Chenghua, LIU Pengcheng, TANG Shensheng, et al. Anomaly intrusion behavior detection based on fuzzy clustering and features selection [J]. Journal of computer research and development, 2015, 52(3): 718?728.
[10] 黄卫春,刘建林,熊李艳.基于样本一特征加权的可能性模糊核聚类算法[J].计算机工程与科学,2014(1):169?175.
HUANG Weichun, LIU Jianlin, XIONG Liyan. A sample?feature weighted possibilistic fuzzy kernel clustering algorithm [J]. Computer engineering & science, 2014(1): 169?175.
[11] XU W, HUANG L, FOX A, et al. Detecting large?scale system problems detection by mining console logs [C]// Proceedings of 27th International Conference on Machine Learning. Haifa, Israel: SOSP, 2009: 37?46.
[12] TANG L, LI T, PERNG C S. LogSig: generating system events from raw textual logs [C]// Proceedings of 20th ACM International Conference on Information and Knowledge Management. Glasgow: CIKM, 2011: 785?794.
[13] 白宁.基于主动学习的支持向量机算法[J].现代电子技术,2013,36(24):22?24.
BAI Ning. Support vector machine algorithm based on active learning [J]. Modern electronics technique, 2013, 36(24): 22?24.
