结合互信息最大化的文本到图像生成方法
2019-11-08莫建文徐凯亮林乐平欧阳宁
莫建文,徐凯亮,林乐平,欧阳宁
(桂林电子科技大学 信息与通信学院, 广西壮族自治区 桂林 541004)
通过自然语言描述自动地生成图像在图像生成领域一直都是一项很具有挑战的任务,在一些应用方面都有着广泛的需求,比如艺术生成,计算机辅助设计等。近年来,这个研究领域也越来越活跃,并且已经取得了很大的进展。
现阶段,生成对抗网络(Generative Adversarial Networks,GAN)在图像处理中得到广泛应用[1]。文本到图像生成方法主要在生成对抗网络的基础上进行研究,研究目的是为了学习从文本语义空间到彩色图像空间的映射。最初,REED等[2]通过基于条件生成对抗网络[3]的框架来处理这项任务,方法是将整个文本描述编码为一个全局的句向量并作为条件进行图像生成,并且提出了一种新的图像文本匹配对抗训练策略,这种方法成功地生成了分辨率64×64的可信赖图像,但无法生成生动的对象细节。而后,ZHANG等[4]提出了分阶段的堆叠式生成对抗网络(Stacked Generative Adversarial Networks,StackGAN),训练策略是先绘制对象的大致轮廓,再修补细节和缺陷,生成过程分为多阶段生成网络,最后阶段生成分辨率为256×256的图像,这项策略极大地提高了图像的生成质量。之后又提出了StackGAN的端对端改进方法StackGAN-v2[5],并进一步对模型的稳定性进行了优化。文献[6]在这个基础上提出了与注意力机制联合的生成对抗网络,提供了更为细致的图像-文本匹配损失计算方法。该网络生成的图像更加生动,并且与文本描述的匹配度更高。值得注意的是,以上所述方法虽然能生成分辨率越来越高的图像,更加逼真,并且细节更为丰富,但以上方法的目标优化函数只是在减小生成样本分布和源样本分布间的JS散度。该方法可以拉近两个分布的距离,使生成样本分布逐渐趋近于源样本分布,但不能保证整体分布间的相似度。当只有一部分输入信号在语义层面上起作用时,对训练是极其不利的。由于生成对抗网络训练不稳定且收敛困难,因此很容易出现“模式坍塌”现象,训练出单一模式的样本,在文本到图像任务当中,甚至还会训练出不匹配和无意义的样本。
生成对抗网络模型不稳定的原因主要为训练过于自由,难以达到纳什均衡,导致模型训练容易陷入局部最优,使得模型只需要生成符合部分模式的样本就可以满足目标函数的优化目标。加入有效的全局特征互信息约束和局部位置特征互信息约束,可以使模型对空间结构变得更加敏感,能使该问题得到一定程度的缓解。互信息最大化优化原理[7-8]主张在神经网络的输入和输出之间进行最大化互信息,这可以获取更为鲁棒且均匀的映射关系。文献[9]中提出的互信息神经估计可以利用神经网络学习到连续变量的互信息估计,适用于深度神经网络中的互信息估计。笔者利用互信息对模型进行优化的思想启发于文献[10]中提出的可解释表示学习方法,通过最大化条件变量与生成数据的互信息,使得控制条件变量变化的同时能生成可解释的图像特征。另外,估计和最大化互信息的方法主要借鉴了文献[11]中提出的通过互信息学习深度表示的方法。该方法遵循互信息神经估计,为学习一个可靠的特征表示,最大化输入数据和高级表示之间的互信息来进行表示学习,并通过最大化输入的表示和局部位置向量之间的平均互信息来改善分类任务的表示质量。该方法提出的互信息编码器不需要解码器,且训练过程是无监督的。通常生成模型也常用作构建表示的方法[12-14],并且互信息在代表性质量中起着重要作用。
在StackGAN-v2的网络模型基础上,利用了互信息与图像空间结构的联系,并针对图像生成任务,改进了最大化互信息方法,设计了一种结合互信息估计和最大化的堆叠式生成对抗网络模型。模型主要有两个改进部分,分别为全局互信息最大化模块和局部平均互信息最大化模块。在生成对抗网络模型的输入和输出间构建互信息最大化模型,最大化模型中有两个互信息估计器(即全局鉴别器和局部鉴别器),估计输入随机向量和生成特征图之间的互信息,并分别考虑全局特征和局部特征两者与全局向量之间的互信息。利用估计器来估计输入和输出间的互信息量,将互信息估计量作为互信息正则项加入到生成器损失当中,通过最大化互信息方法约束并优化模型参数间的互信息量。实验表明这种方法可以有效约束输入与输出的全局和局部相关性,缓解“模式坍塌”问题,生成更具多样性的样本。
1 方 法
在生成对抗网络模型的基础上,结合了互信息估计和最大化优化方法。具体如图1所示。
图1中提出的方法有两个组成部分:生成对抗网络模型和互信息最大化模型。首先由生成对抗网络生成不同尺度的特征图,然后将生成过程最后阶段的特征图与输入的全局向量进行互信息最大化优化。具体计算方法将在本节的其余部分详细阐述。
1.1 网络模型
沿用了StackGAN-v2中的多尺度图像分布近似和条件与非条件联合分布近似理论,网络框架为树形结构,具有多个生成器来生成不同尺寸的图像。具体架构如图2所示。
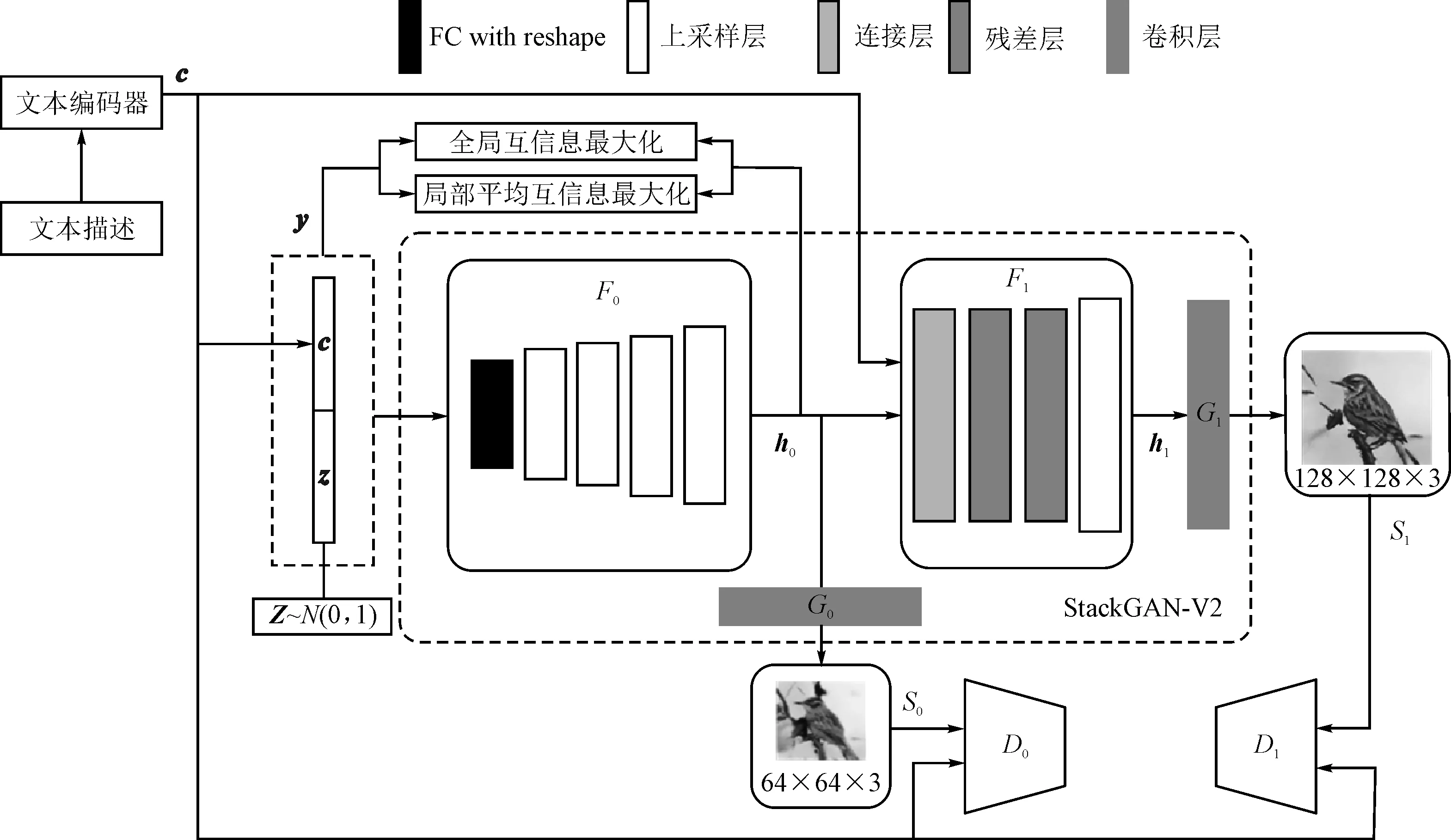
图2 网络模型架构
图2中的大虚线框为输出128×128分辨率的StackGAN-v2模型。c是条件向量,通过训练好的文本编码器[2]将文本描述映射为文本嵌入向量,再进行条件增强[5]处理得到低维条件向量c。首先由条件向量c与高斯随机噪声向量z组合得到全局向量y,然后通过StackGAN-v2生成不同尺寸的图像。F0,G0,D0和F1,G1,D1分别为不同尺寸的生成器和鉴别器。另外,在输入层y与特征层h0之间进行互信息估计。
过程具体可表示为
(1)
其中,z~N(0,1),为高斯先验;{h0,h1}表示不同尺度的特征层;{s0,s1}是分辨率逐渐增加的图像。每个生成器都有不同的鉴别器进行竞争,并学习不同尺度的判别特征。Fi、Gi和Di都被建模为神经网络。
1.2 互信息估计与最大化
1.2.1 全局互信息估计
文本到图像任务学习的目标是向量分布Y到源图像近似分布S的映射。向量y由条件向量c和随机向量z组成,向量y具有全局信息,而条件向量c在生成过程中起主导作用。图2中的全局互信息最大化模块具体如图3所示。
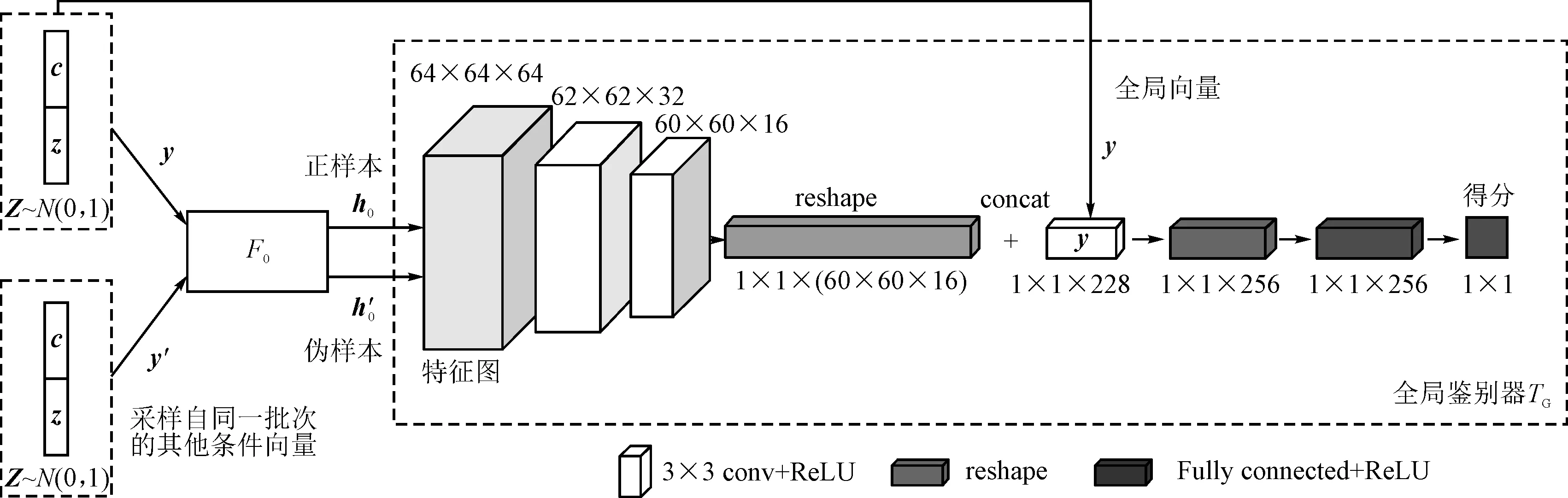
图3 全局互信息估计示意图

通过图3中表示的全局鉴别器TG估计并最大化互信息的方法来优化生成器F0,该方法训练鉴别器来估计互信息并打分,可以定义一个Jensen-Shannon互信息估计量[11,15]:
(2)
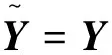
1.2.2 局部平均互信息估计
只进行全局互信息最大化优化通常不足以学习有用的表示。为了保证表示模型能够适应图像生成任务,并生成模式更为均匀的样本,所提方法最大化全局向量与局部位置特征向量之间的平均互信息,提高相同的全局表征与所有局部块的互信息,构建了局部-全局对,这有利于学习到共享的数据。图2中的局部平均互信息最大化模块如图4所示。
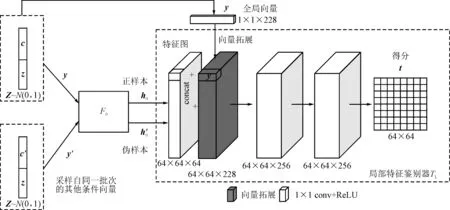
图4 局部平均互信息估计示意图
局部平均互信息估计框架如图4所示。特征图中的每个位置向量都可认为是一个局部位置特征向量,通过尺寸为64×64的特征映射h0提取得到64×64个具有位置信息的局部位置特征向量,并将全局向量y分别与每个局部位置特征向量连接起来,构建64×64个局部-全局对。正伪样本生成方式与图3一致,通过一个局部特征鉴别器TL为每个局部-全局对生成一个得分。
正样本得分矩阵t可表示为
(3)
其中,M×M为特征映射h0的尺寸,在实验中设置M=64;TL是由神经网络建模的局部鉴别器函数;ti,j为特征映射h0第i行第j列的局部位置特征向量经过局部鉴别器TL的得分。式(3)反映了数据中有用的结构(例如空间结构性)。
伪样本得分矩阵可表示为
(4)
为计算得分矩阵t的平均得分,令
(5)
在局部-全局对上,参照式(2)并结合式(3)、式(4)和式(5),可定义平均互信息估计为
(6)
其中,第1项为正样本的平均互信息估计量,第2项为伪样本的平均互信息估计量,总体表现为局部位置特征向量与全局向量的平均互信息估计量。
1.2.3 最大化互信息正则项
在标准的堆叠式条件生成对抗网络模型中,生成模型的输入是由一个条件向量(例如文本嵌入向量)和一个连续的噪声随机向量(例如标准高斯分布)组合而成的,令其为向量y。由于文本条件类别不明确,存在同一个文本与多张图片相关和同一张图片与多个文本相关的情况,生成模型会将不同的输入y映射到相同的生成样本F0(y),导致F0(y)仅仅依赖于y的少数维度,从而生成的分布只是真实数据分布的“子分布”。简单来说,就是因为生成样本分布过于集中,不够均匀,为此将全局互信息估计量和局部平均互信息估计量进行最大化优化,利用最大化互信息方法来约束生成器输入和输出的特征层,使得y的每个维度都尽可能地与特征映射h0产生特定的关系,迫使生成的分布更趋向于真实分布。
互信息总估计量由全局互信息和局部平均互信息两部分组成,因此总估计量由式(2)和式(6)可知
(7)
其中,α和β为超参数,设置为0.5和1。
在StackGAN-v2中的多尺度图像分布近似和条件与非条件联合分布近似理论下,为最大化互信息,将互信息正则项I(F0(Y),Y)加入生成器优化目标当中,因此可知判别器的最大化优化目标为
(8)
其中,xi来自第i个尺度的真实图像分布pdatai,si来自相同尺度的模型分布pGi。多个鉴别器并行训练,前两项为无条件损失,后两项为条件损失。
生成器最小化优化目标为
(9)
其中,第1项为无条件损失,第2项为条件损失。
(10)
其中,ρ为超参数,I(F0(Y),Y)为互信息正则项。由于生成器为最小化目标,所以在互信息正则项前加了负号。关于超参数ρ大小对结果的影响,利用实验进行了详细分析。
2 实 验
实验平台的配置为 Intel Xeon E5-2687W八核3.1GHz处理器、32GB内存、GTX1080Ti 显卡以及 Ubuntu 16.04 操作系统,并使用基于Python编程语言的 Pytroch深度学习框架。
2.1 数据集及评估指标
(1)数据集。实验在数据集CUB[16]上评估了所提出的网络模型。CUB数据集包含了200类别的11 788张鸟类图像,其中8 855张样本作为训练集,2 933张样本作为测试集,每张图像都注释了10个文本描述。预先训练的文本编码器将每个句子编码为1 024维度的文本嵌入向量,再进行条件增强处理而得到128维的条件向量。
(2)评估指标。选择多样性指标值inception score[13]为定量评估指标,评估方法表示为
Is=exp(ExDKL(p(y|x)‖p(y))) ,
(11)
其中x表示一个生成的样本,y是inception模型预测的标签。这个指标表示为一个好的模型应该具备多样性,因此边缘分布p(y)和条件分布p(y|x)的KL散度应该足够大。
2.2 实现细节
框架类似StackGAN-v2,类推也可以生成分辨率为256×256的图像,甚至分辨率更高的图像。由于分辨率128×128的图像已经具备了完整的特征和结构信息,而所提出的方法主要针对样本的空间结构信息进行优化,为了生成更可靠的全局和局部特征,并减轻计算负担,设置128×128为生成目标的分辨率。从图1中可知。将随机向量z与条件向量c级联组合得到输入,经过全连接网络并重组得到4×4×32Nt的特征张量。通过4个上采样块得到64×64×2Nt的特征张量,接着经过两个残差块和一个上采样块得到128×128×Nt的特征张量,分别经过卷积核为3×3的卷积层得到相应比例的图像。为增加输入输出的相关性,该部分框架额外增加了全局鉴别器TG和局部鉴别器TL来估计互信息的得分。

表1 全局鉴别器TG网络细节

表2 局部鉴别器TL网络细节
表1和表2中的Input_1和Input_2分别为特征图和全局向量;表1中的reshape为向量重组的操作;表2中的expend为向量拓展成向量矩阵的操作,表1和表2中的concat为通道相加的操作,conv为卷积,fc为全连接,Relu为激活函数。设置Nt为32。互信息项作为正则项添加到生成器损失当中,全局鉴别器TG和局部鉴别器TL采用学习率为0.000 1的Adam求解器,其余模型均采用学习率为0.000 2的Adam求解器,其中Adam求解器动量皆设置为[0.5,0.999],批次大小为24,迭代600个epoch。
2.3 结果对比
为了证明互信息正则项的有效性,主要通过与各种主流的文本到图像生成的网络模型进行结果对比,利用多样性指标值来衡量模型生成图像的客观性和多样性。按照StackGAN的实验设置,总共采样了约30 000张模型生成的随机图像来评估模型的该指标。

表3 多样性指标值对比结果
从表3可以看出,所提模型较之前不同的模型都有了显著的提高,多样性指标值较StackGAN-v2提高了0.41,这表明所提模型生成的样本多样性明显强于其他模型。另外,特别详细地与StackGAN-v2进行了结果比较,定性地比较了两种模型在不同鸟类测试图像的文本描述条件情况下生成的相同姿态图像,结果如图5所示。

图5 相同姿态结果对比图
图5中结果都是在数据集CUB上得到,笔者所提模型最终输出尺寸为128×128。比较了StackGAN-v2的两种不同分辨率输出,尺寸分别为128×128和256×256。由对比结果可以看出,所提模型在特征方面的处理强于StackGAN-v2。例如,图5(a)中的样本,文本中描述为短鸟喙,而StackGAN-v2中128×128分辨率的样本已经丢失了该特征。在特征几乎完全固定的情况下,提高分辨率只能增强纹理的细节,而笔者所提模型结果明显保留了更多语义细节信息。空间结构的边缘信息可以反映在图5(b)和图5(c)中。图5(b)中文本描述的白色胸部在所提模型中更为明显且整体性强;在图5(c)中,笔者所提模型对于灰色翅膀和尾巴的纹理描述和结构的表现都略强于StackGAN-v2;图5(d)主要表现在整体的色彩和内容上,笔者所提模型生成的样本更接近原图;而图5(e)中,两个模型都表现出了模式崩溃的倾向,两者较原图都有比较大的差距,但笔者所提模型明显鲁棒性更强一些。StackGAN-v2只保留了整体的形状而完全丢失了局部特征,笔者所提模型还保留了文本描述中提到的鸟嘴。
另外,定性地比较了两种模型在同一测试图像的10个不同文本描述条件下生成的图像。结果如图6所示。

图6 不同文本描述生成图像对比图
图6表示为同一测试图像的10个不同文本描述条件下生成的图像,大致描述了一只小鸟,拥有短鸟喙、红色的冠和胸部,还有棕色的翅膀。可以观察出两种模型都能生成不同姿态的样本,而笔者所提模型拥有更健全的特征和细节并且鲁棒性更强。例如图6(c)、(e)和(g)的文本描述都提到了鸟喙,StackGAN-v2的生成样本已经丢失了该特征,笔者所提模型结果保留了较为完整的特征。出现同样情况的还有图6(b)中的眼睛和(d)中的尾巴;另外在图6(b)、(d)、(f)、(g)和(j)中,StackGAN-v2已经出现了明显的畸形等现象,而笔者所提模型出现该情况的结果相对较少。实验表明,针对全局-局部特征加入的互信息正则项,有效地加强了局部信息与全局信息的相关性,使生成图像的局部特征不易丢失,保持了更完整的姿态,模式也更为均匀,也因此提高了生成样本的多样性。
另外,对不同的输入和不同的超参数ρ做了多样性指标值评估,如表4所示。

表4 不同互信息正则项超参数的多样性指标值对比结果
表4中Our1方法为直接最大化条件向量c和特征图h0的互信息,Our2方法将高斯随机噪声z与条件向量c组合后与特征图h0的互信息作为最大化优化目标,其中ρ为式(10)中的互信息正则项的超参数。实验表明,当ρ=3时,多样性指标值最大,多样性最好;当超参数设置过高时,观察生成样本发现,部分样本会出现模式塌陷,导致多样性变差。结果表明,Our2方法分数高于Our1方法,这说明了不仅仅文本语义对结果有影响,选取的随机噪声分布Z同样对结果也有一定的影响。综上所述,笔者所提模型最后选择了Our2方法。
3 总 结
由于文本到图像任务当中生成对抗网络训练困难,常常会出现模式丢失或模式崩溃等现象,导致生成的样本缺乏多样性。笔者提出了一种结合局部-全局互信息最大化的堆叠式文本到图像的生成对抗网络模型。该模型通过估计全局特征和局部特征两者与全局向量间的互信息并将其最大化的方法,增强文本描述与生成样本的相关性,建立更为全面且可靠的映射关系。实验结果表明,该方法在保证了生成样本质量不降低的情况下,提升样本多样性。
