基于PSO优化的盲源分离式文本特征降维分类方法
2019-11-07丁小艳
丁小艳
基于PSO优化的盲源分离式文本特征降维分类方法
丁小艳
江苏医药职业学院医技学院, 江苏 盐城 224005
为了有效解决文本特征分类过程中高阶相关性问题,本文在盲源分离式文本特征降维分类方法的基础上引入粒子群(PSO)算法,有效规避迭代过程中局部最优解问题,且以负熵作为适应度函数,有效改善独立主成分分析的判别性能,经过实验证明经过优化后的方案,在精确度、准确率、召回率、1测试值等方面有较好的表现。
文本特征; 盲源分离; PSO; 分类
文本分类指的是以文本的特征为依据,将其分为不同的类型,使同一种文本的特征是最相似的。大部分文本采用的是自然语言,和计算机语言是有明显区别的,因此,在利用分类系统之前,首先要将文本转变成其特征项与特征权值所构成之向量,若将分词词类当成特征量,向量便有机会达到几万维度,这是非常庞杂的,此时计算工作量猛增,并且会产生一系列的无价值信息,对分类造成干扰,所以降维这个环节是非常重要的[1]。
就实践来看,降维方面可以应用的方法是特征选择或提取。前者是利用特征计算方法,从特征集合中选择能够更好的区分文本的特征项,包括(DF)、2(Ch-)统计、信息增益(IG)、互信息(MI)等方法。文献[1]对这些方法比较分析,结果表明,每种方法都有自身的优势和缺陷,适用于各种分类器以及数据集。一词多义、多词同义在本文中十分常见,特征选择的前提是不同特征彼此互不影响,因此利用这种方法来降维,往往难以实现预期的效果。后者需要对原始特征进行分析,由此确定新特征,以便实现降维进程内,找出文本特征下的语义关系,避免了前一种方法的缺陷。文献[2]指出,线性判别分析并不适用于高维小样本,此时类间散布矩阵是奇异矩阵,变换矩阵无法直接求解。通常情况下,文本有几万个甚至更多的特征,但在样本不足的状况下,线性判别分析的降维效果并不好。主成分分析能够提供彼此独立的若干主成分,去除其中二阶分析产生的冗余信息,保留高阶冗余信息[3]。文献[4]探讨了独立主成分分析(ICA算法)在降维方面的作用,利用该算法得到彼此互不影响的若干成分,解决了高阶相关性的问题,相比主成分分析,其在分类方面具有显著的优势。
面对分离矩阵,应用ICA方法,由于需要迭代,往往会产生局部最优解。为此,笔者将粒子群算法引入进来,并对ICA算法进行改良[5-7],然后通过改良后的PSO-ICA方法来提取文本向量的特征,然后提供给支持向量机[8],完成文本的分类。结果显示,改良后的方法更加适用于文本的分类。
1 独立分量分析
1.1 基本原理
基于峰度、互信息最大化和负熵值等进行判断,从而确定不同分量彼此间的独立性。笔者在本文中选择负熵为估计准则,它是以非高斯性为依据来评判独立性的,分量的独立性和非高斯性之间为正相关关系。负熵指的是:
()=(y)-() (1)
这里面,()=-òp()logp(),代表密度为p()的随机变量的熵:y和均为高斯随机向量,二者之间存在相同相关矩阵,()近似的表达为:
()µ{[()]-[()]}2(2)
这里面,代表标准的高斯变量,(·)为非二次项函数,其值和高斯性类型有关,目前应用最广泛的(·)包括三类,详见下式(3):

这里面,为常数,其取值不超过[12]这一范围。
1.2 文档的独立分量描述
设D×n作为文档的向量矩阵,A×h为混合矩阵,S×n为独立分量,我们将文档矩阵能够描述为:D×n=A×n·S×n,这里面,代表文档特征向量之维数;代表文档集合文档数量;代表独立分量数量,即需要降低的维度。
假定具有可逆矩阵,则根据S×n=w×m·D×n确定独立分量,这里面,代表维空间到维空间的投影矩阵,且≤。在文本分类过程中利用独立分量分析方法,从而通过计算确定独立分量,并用其取代文档矩阵,如此一来,我们就能够得到潜在的特征,同时也达到了降维的目的。
2 PSO优化ICA
Fast ICA算法计算简单,能够在短时间内收敛,不过它是利用梯度下降法进行计算的,若选择不合适的初始值,很有可能产生局部最优解。PSO算法能够找到全局最优解,不过它也有自身的缺陷,无法避免随机性、模糊性的问题,迭代环节容易发生“震荡”问题。为此,笔者将PSO和ICA融合在一起,提出了新的PSO-ICA算法。
ICA算法的思路是计算出分离矩阵,然后据此提取出特征,通过PSO算法对予以求解。PSO-ICA算法的执行流程为:
步骤1对文本矩阵予以去中心、白化处理,从而使后续的ICA计算变得更加简单,消除不同特征彼此间的相关性。
步骤2 初始化解混矩阵,考虑道包含的各列是彼此正交的,将其列数表示成(=1,2,…,),在=1的情况下,随机选取一列维的单位向量并以此为1的初始值,在2≤≤的情况下,w的初始值一定要符合这一条件:ǁwǁ=1,w^1,w^2,…,w^w-1。
步骤3 选择个粒子,对其参数进行初始化处理,以w为粒子的位置向量X其位置向量X和初始速度分别是w和0.2X。
步骤4 通过计算确定适应度值,其中=wT iMz/ǁMwǁ,因中的各列是彼此正交的,因此,在=1的情况下,1=;而在1<≤的情况下,有:


步骤5 计算更新所有粒子的实时位置和速度。
步骤6 若符合停止条件,终止搜索,返回全局最优位置w;否则需要回到步骤4。
步骤7 归一化w,得到:w=Mw/ǁMwǁ。
步骤8 令=+1,判断的所有列向量是否完成了运算,如果≤,跳转到步骤2;如果不然,则进入下一步。
步骤9 实现特征分离分离s=wT iz
3 结果与分析
立足以上理论进行实验,以反映出新方法的效果。实验条件为:Intel CoreTmi5-6500 CPU@3.20GHZ,使用64位操作系统,内存达到4 GB。
3.1 实验流程
中文文本分类步骤过程为:
①根据某项比例,将文本分成两个部分,即训练集、测试集。对所有文本展开分词、剔除停用词等处理,其中分词是借助中科院ICTCIAS系统达成的。
②通过VSM将全部文本转化成特征向量,运用IF-IDF算法确定特征词权值。
③运用PSO-ICA算法展开计算,获得分离矩阵与独立基子空间。
④将两个集合之文本特征向量投影至独立基空间中展开计算,便可得到所有文本之特征向量。
步骤5通过LIBSVM完成分类操作。
3.2 实验数据与评价方法
此次实验涉及到了两个数据集主要下载自CSDN平台,其中酒店评论链接为https://download.csdn.net/download/xyz1584172808/10342201。某电商某商品评论链接为http://blog.csdn.net/lingerlanlan/article/details/38418277。二者均包含了好评和差评。
根据四项指标来评估本文方法的分类效果,具体为精确度、准确率、召回率、1测试值。
3.3 实验结果与数据分析
基于三组数据完成3组实验,从而检验出PSO-ICA的文本分类效果,每组的数量和类型是确保存在差异的。
3.3.1 PSO-ICA在不同数目的数据集下的分类比较基于首个数据集完成本次实验,首先利用随机法把数据分成三组,具体分组详见表1。

表1 实验数据分组信息
通过PSO-ICA算法,获得各组数据之相关特征,并予以LIBSVM分类,实验结果详见表2。

表2 3组不同数据基于PSO-ICA的分类效果
对表2进行分析可知,在数据集包含的文本数量不断提高的过程中,分类四项指标的表现都有所增强,证明PSO-ICA更加适用于大样本的处理,且即便样本容量较小,也不会发生过拟合的问题。


图2 酒店评论数据降维分类效果

图3 某电商商品评论数据降维分类效果
对以上两图进行分析能够确定,分类的正确率,和独立分量的数量以及降维维度直接相关。在维度不断上升的过程中,分类正确率先是不断升高,达到一定的峰值后不断降低。原因在于维度达到一定水平后会形成灾难,使分类效果受到影响。因此,针对各种数量和类型的数据集,都有与之匹配的独立特征数。
3.3.3 PSO-ICA与Fast ICA的分类效果对比 Fast ICA在提取小文本集的特征过程中,有可能会出现局部最优解,引发分类效果降
低。笔者对此对比与实验2相同之数据集。对同一个数据集,通过Fast ICA和PSO-ICA予以降维处理,具体的分类效果详见表3和4,无论是从准确率,还是从1测试值角度来看,PSO-ICA算法都具有更好的表现。
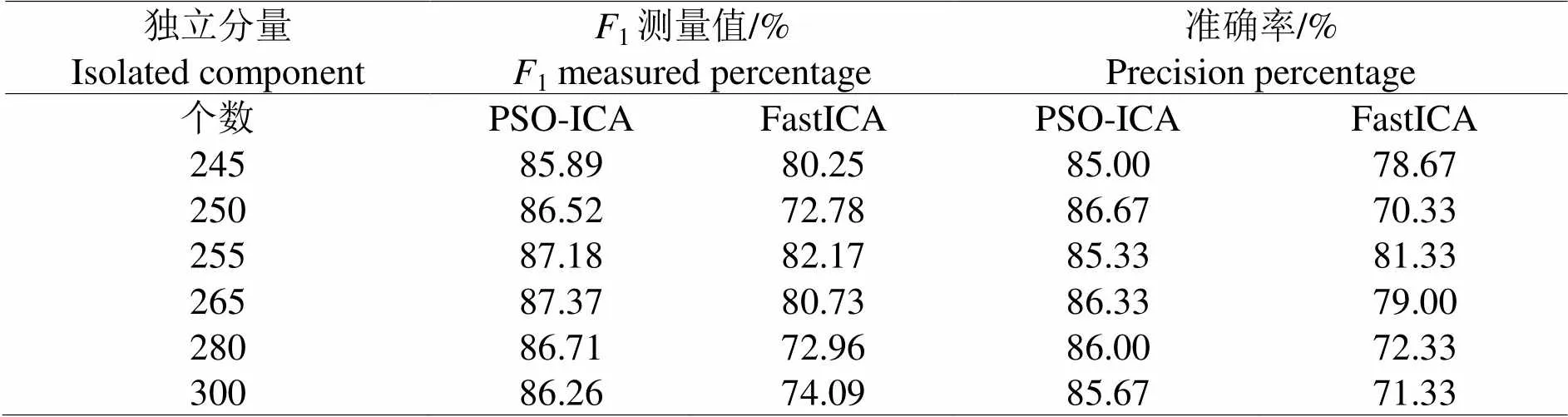
表3 不同方法下酒店评论数据的分类效果

表4 不同方法下某电商商品评论数据的分类效果
4 结语
文本分类是一项流程性的工作,它包括了多个环节,文本向量空间特征降维即为其中之一。考虑到文本向量的特征是高维、稀疏的,笔者将和PSO与ICA结合起来,运用PSO算法探寻ICA算法内的目标函数之最优解,其与传统梯度下降法相比,更易避免呈示出局部最优解。研究显示,新算法能够有效的缩短特征提取的耗时。经典PSO算法收敛耗时长、精度低,因此接下来的研究工作主要是进一步的改良PSO算法并将其和ICA结合,从而实现更为理想的分类效果。
[1] 代六玲,黄河燕,陈肇雄.中文文本分类中特征抽取方法的比较研究[J].中文信息学报,2004,18(1):26-32
[2] Wang S, Lu J, Gu X,. Semi- supervised linear discriminant analysis for dimension reduction and classification[J]. Pattern Recognition, 2016,57(C):179-189
[3] Chen XS. Accelerated k-nearest neighbors algorithm based on principal component analysis for text categorization[J]. Frontiers of Information Technology & Electronic Engineering, 2013,14(6):407-416
[4] 何海斌.文本分类中特征降维技术的研究[D].保定:河北大学,2010
[5] Han M, Jiang LW. Endpoint prediction model of basic oxygen furnace steelmaking based on PSO-ICA and RBF neural network[C]. Dalian, China: 2010 International Conference on Intelligent Control and Information Processing, 2010:388-393
[6] 刘广威,葛海波,程浩,等.基于IPSO-ICA算法的盲多用户检测[J].电视技术,2016,40(2):23-26
[7] Jo T. String vector based KNN for text categorization[C]. Bongpyeong, South Korea: International Conference on Advanced Communication Technology, 2017:458-463
[8] Zhou XF, Guo L, Liu P,. Latent factor SVM for text categorization[C]. Shenzhen China: 2014 IEEE International Conference on Data Mining Workshop, 2014:105-110
The Reduction Dimension Classification Method of Blind Source Separation Text Feature on PSO Optimization
DING Xiao-yan
224005,
In order to effectively solve the problem of high-order correlation in text feature classification, particle swarm optimization (PSO) algorithm was introduced on the basis of Blind Source Separation (BSS) text feature dimension reduction classification method to effectively avoid the local optimal solution problem in the iteration process. fitness function was regarded as Negative entropy to effectively improve the discriminant performance of independent principal component analysis. Experiments showed that the optimized scheme had better performance in accuracy, accuracy, recall and test value.
Text features; blind source separation; PSO; classification
TP391
A
1000-2324(2019)05-0881-04
10.3969/j.issn.1000-2324.2019.05.032
2018-05-05
2018-06-23
丁小艳(1982-),女,硕士,讲师,主要研究方向为大数据存储与索引,医疗信息安全技术. E-mail:didadi886@126.com
