基于数据挖掘的化工生产事故致因主题抽取
2019-11-06樊运晓
牛 毅,樊运晓,高 远
(中国地质大学(北京)工程技术学院,北京 100083)
0 引言
近年来,尽管我国化工安全生产形势整体趋好,但化工安全生产事故依然多发[1]。从历史事故中学习经验对进一步遏制事故的发生具有重要意义,然而人们往往更关注重大事故,而忽视小事故。海因里希曾在统计大量事故后提出著名的事故金字塔理论:伤亡、轻伤和无伤害事故的比例为1∶29∶300[2],即1起严重事故背后必然有更多的小事故发生,要防止严重事故发生必须先减少或消除小事故,小事故同样具有重要的研究价值[3]。在化工生产过程中,企业积累了大量的小型事故文本数据,但受数据量大、记录粗糙以及相应信息处理能力不足等因素限制,数据价值未得到充分利用,进而制约了对事故的深入研究。因此,如何从这些杂乱的事故信息中高效挖掘潜在价值,已成为亟待解决的问题。
当前针对化工事故数据应用的研究,还主要停留在对事故类型、事发区域或时段的简单统计分析方面[4]。面对复杂的事故发生机理,单一的统计指标不能充分描述事故的特征[5]。在此背景下,一些学者尝试通过数据挖掘技术对事故数据进行事故分类[6],事故聚类[5]和事故潜在关联规则挖掘[7]等方面研究,然而这些研究大多集中于道路交通[8]和建筑施工[9]等领域,在化工安全生产事故中的应用还相对较少。相较于数值型数据,文本数据作为事故记录的主要形式,蕴含着事故更深入的细节,但由于结构复杂、记录粗糙等原因,对大量化工事故文本数据系统的挖掘则更为缺乏。
基于上述问题,本文引入可从大量事故文本数据中提取主题和关键信息的数据挖掘方法:潜在狄利克雷分配(Latent Dirichlet Allocation,LDA)主题模型和社会网络分析法,以某化工企业1 578起小型事故为样本,利用该方法进一步挖掘事故致因及其分布规律,实现对化工事故的更深入分析,为企业事故预防工作提供有力支持。
1 数据挖掘
数据挖掘是指通过统计、机器学习等方法,从大量数据中挖掘对研究或决策具有深层价值信息的过程。
1.1 化工安全生产事故数据特征
目前,文本数据是各行业安全生产事故的最主要记录形式之一,其中重特大事故会以事故调查报告的形式详细剖析,然而数量上占绝大多数的轻伤或无人员伤亡的小事故往往只进行简单的记录,由于其记录粗糙、数量庞大以及不被重视等原因,针对这些文本数据的挖掘还十分缺乏。以化工行业为例,化工安全生产事故文本数据通常是以描述性的文字对事故发生过程及原因的记录,记录虽然粗糙,但蕴含着事故经过和生产一线工作状况等关键细节,同样具有巨大的利用价值和挖掘空间。
1.2 LDA主题模型
潜在狄利克雷分配(Latent Dirichlet Allocation,LDA)是由Blei提出的1种主题挖掘模型[10],该模型基于一定规则从海量文本中抽取主题,并根据主题分布对文本数据进行聚类,其中主题是指文本数据所蕴含的潜在主旨或核心思想。目前,该模型已广泛应用于图书情报、热点评论主题抽取[11]等领域。LDA也称为三层贝叶斯概率模型,如图1所示,其结构由文本、主题和词项3部分组成,其中每个文本由一系列服从概率分布的主题构成,主题又由一系列服从概率分布的词项构成[10]。
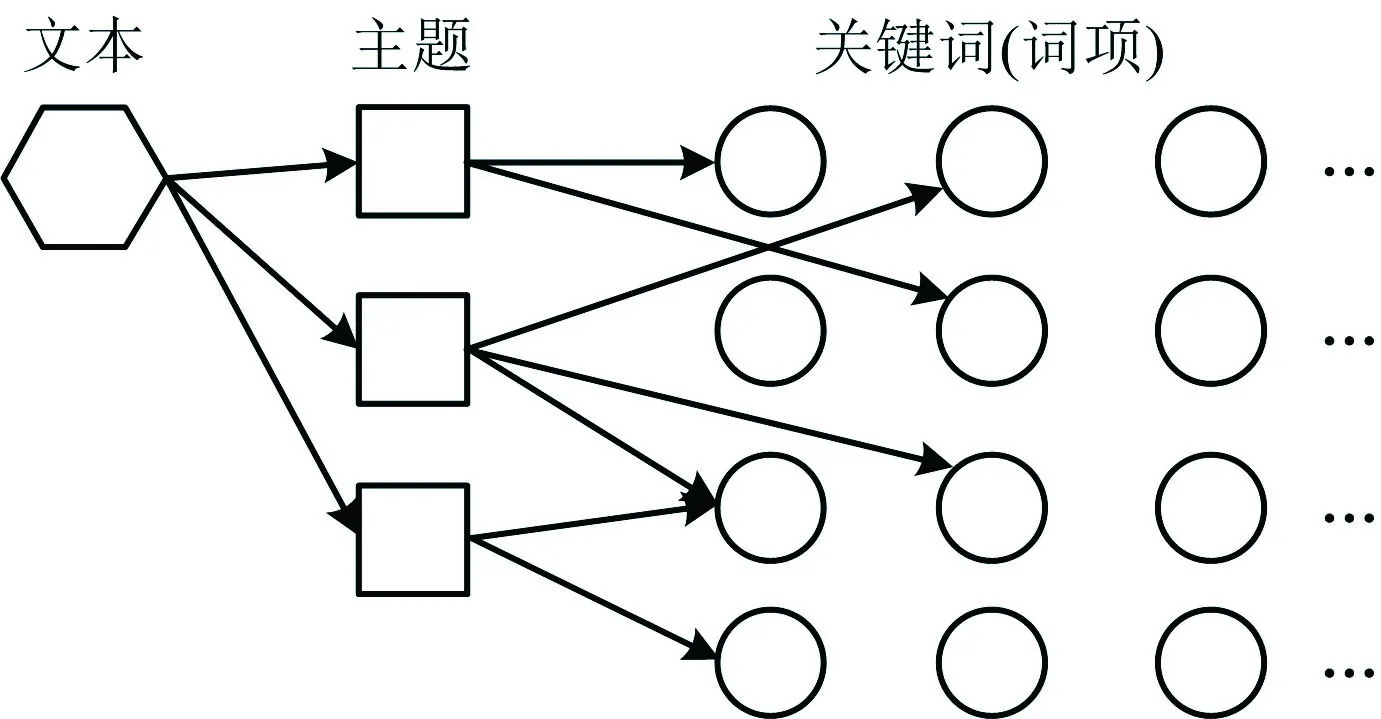
图1 三层贝叶斯概率结构模型Fig.1 Three-layer Bayesian probabilistic structure model
1)主题生成过程:LDA主题模型如图2所示,图2中主要符号含义:α,β为狄利克雷先验参数;m表示第m个文本;θm表示文本m的主题分布;n表示文本m的词项数;zm,n表示文本m的第n个词项对应的主题;wm,n表示文本m的第n词项;φzm,n表示主题的词项分布;K表示主题总数;M表示文本总数;k表示第k个主题;Nm表示第m篇文档的词项总数;Dir表示狄利克雷分布;Mult表示多项式分布。

图2 LDA主题模型Fig.2 LDA probability model
主题详细生成过程为[12]:
①从狄利克雷分布α中取样生成文档m∈(1,M)的主题分布θm,θm|α~Dir(α);
②针对文档m中的每个词项wm,n,其中,n∈(1,Nm):a.从多项式分布θm中取样生成该词项wm,n的主题zm,n|θm~Mult(θm);b.从词项分布φzm,n中取样最终生成词项wm,n|φzm,n~Mult(φzm,n),其中φzm,n|β~Dir(β)。在给定参数α,β情况下,模型的联合概率分布为:
(1)
2)参数估计:图2中,阴影圆圈表示观测变量,非阴影圆圈表示潜在变量,模型求解前需要对潜在变量进行估计。本文中,模型的参数估计主要基于变分推断EM算法。其原理为:通过近似隐藏变量的后验分布来简化问题,通过寻求最大似然解来进行参数估计[12]。
1.3 Tf-idf算法
事故记录中每个关键词是蕴含事故信息的基本单元,考虑到一些词频少的关键词可能携带更多的事故信息,因此利用Tf-idf(Term frequency-inverse document frequency)算法[13]对事故关键词进行加权处理。算法原理为:一个关键词在整个数据集中出现频率不高,但在某起事故中多次出现,则认为该关键词既对该起事故有很好的代表性,又对其他事故有很好的区分能力,那么此关键词在该事故中具有较高的权重。通过加权处理可有效避免这些关键事故信息的流失。
1.4 社会网络分析法
社会网络分析法旨在对系统要素间的关系进行量化研究[14],一个网络通常由“点”和“边”构成,“点”表示各个要素,“边”表示要素间的关系,“边”的粗细程度表示关联程度。事故致因要素间并非简单的线性关系,而是构成复杂的关系网络,为进一步发掘事故要素间的关系,基于社会网络分析法,将关键词看作“点”,关键词之间的关联看作“边”,构建事故关键词网络。算法原理为:在整个事故文本数据集中,若2个关键词同时出现在一个句子的频率超过一定值时,则认为这2个关键词有关联,该频率大小反映了关联度的强弱。
2 化工事故致因挖掘流程
化工事故致因挖掘主要包括数据收集与处理、事故致因挖掘、结果可视化分析等3个主要环节,具体流程如图3所示。

图3 化工事故主题抽取流程Fig.3 Chemical accident theme extraction process
2.1 数据收集与处理
本研究的数据来源为国内某大型化工集团2010—2016年期间的1 578起事故记录,该企业为中国最具代表性的化工企业之一。企业拥有较完善的事故信息采集系统,1 578起事故中大多为轻伤和设备损坏事故(少量死亡、重伤事故),记录内容为事故发生后第一时间对事故经过、生产环境和事故原因的文字性描述,蕴含着事故发生时的关键细节,且所有数据的记录形式统一,利于对该数据集进行系统地潜在规律挖掘。原始事故数据示例见表1。

表1 原始事故数据(示例)Table 1 Accident data after modification(example)
为达到模型计算的要求,同时提高模型效率及准确性,事故致因挖掘前,需将原始事故数据进行分词、去停用词等一系列处理:
1)分词处理:Jieba分词包是1个基于python实现的分词工具,借助该工具对事故文本数据进行分词处理。由于要分析数据的背景为化工事故,为了避免分词过程中无法识别某些化工或安全专业名词的情况,结合化工企业相关规范,制定了适用于化工安全事故分析的辅助字典,见表2。

表2 化工安全专业领域字典(部分)Table 2 Chemical safety professional domain dictionary (partial)
2)去停用词:事故记录中存在许多对事故分析无意义的词项,为提高模型效率,将这些词项加入停用词表,并将其过滤,即去停用词处理。
2.2 事故致因挖掘
通过对原始数据处理,得到适合模型计算的1 578起事故数据。基于Python编程语言,利用前文所介绍的LDA主题模型、Tf-idf算法以及社会网络分析法,对1 578起事故数据进行事故致因主题抽取、关键词加权以及建立关键词关系网络等工作。其具体流程如图3中②部分所示。
2.3 结果可视化分析
为帮助企业管理者更直观地了解企业安全状况及事故致因分布规律,将事故关键词关联规则、事故致因主题分布等抽象结果以文字—图像交互的形式展现出来,利用Gephi等可视化工具,绘制事故关键词关系网络、事故致因主题分布图等可视化结果。
3 结果及分析
3.1 事故关键词权重矩阵
事故记录中每个关键词所蕴含信息的重要程度不同,因此利用Tf-idf算法,建立文档—关键词权重矩阵,见表3。矩阵中的权重代表了关键词在事故中的重要程度,权重越高重要度越高。例如,事故‘3’中,关键词“不慎”的权重较高,说明注意力问题可能是导致该事故发生的主要原因。
3.2 事故关键词关系网络
基于社会网络分析法,利用Gephi软件绘制关键词关系网络图,如图4所示。整个事故集中,重要度越高的关键词,越靠近关系网络的中心位置,且关键词标签越大。相关的关键词由直线相连,直线的粗细则代表了关联程度的大小。由图4可知,“操作”、“检查”、“设备”等关键词位于整个关系网络的枢纽,尤其是“操作”,位于关系网络的最中心,说明不安全操作仍是事故预防工作中需重点防范的对象。
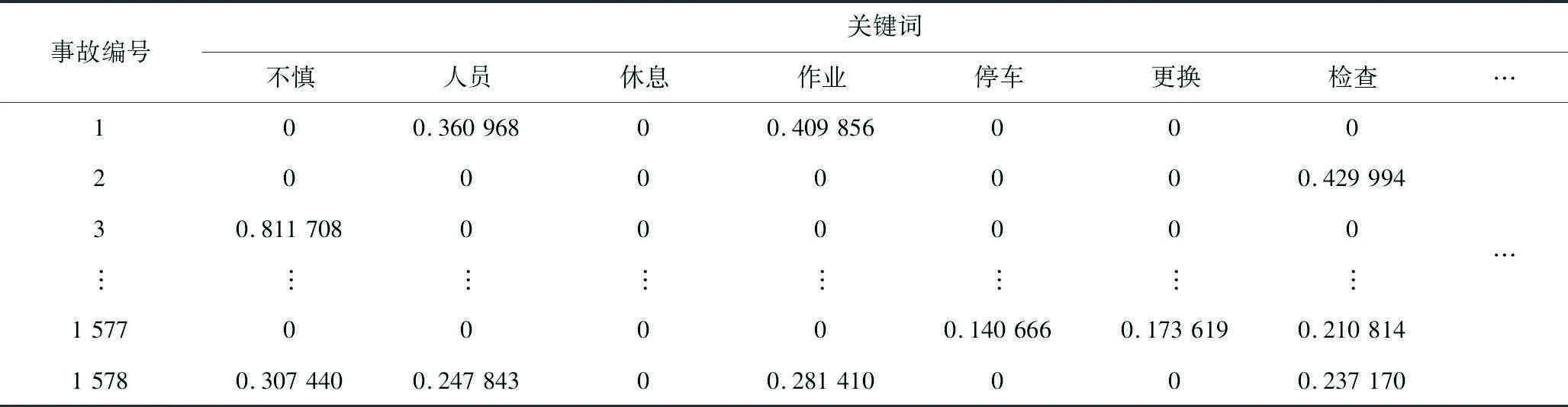
表3 关键词权重矩阵(部分)Table 3 Keyword weight matrix (partial)

图4 关键词关系网络Fig.4 Keywords Telational network
3.3 事故致因主题结果分析
1)主题数确定
本文采用困惑度指标[15]来确定主题数目,困惑度指标越小说明建模能力越好,则主题数目为最优,计算公式为:
(2)
式中:perplexity表示困惑度;m表示第m篇文档;P(wm)表示第m篇文档每个单词的概率;Nm表示第m篇文档的词项总数。困惑度随主题数目变化时的曲线如图5所示,从图5中可以看出,当主题数为5时,困惑度指标曲线处于低谷,此时模型效果最优,因此将主题数确定为5个。
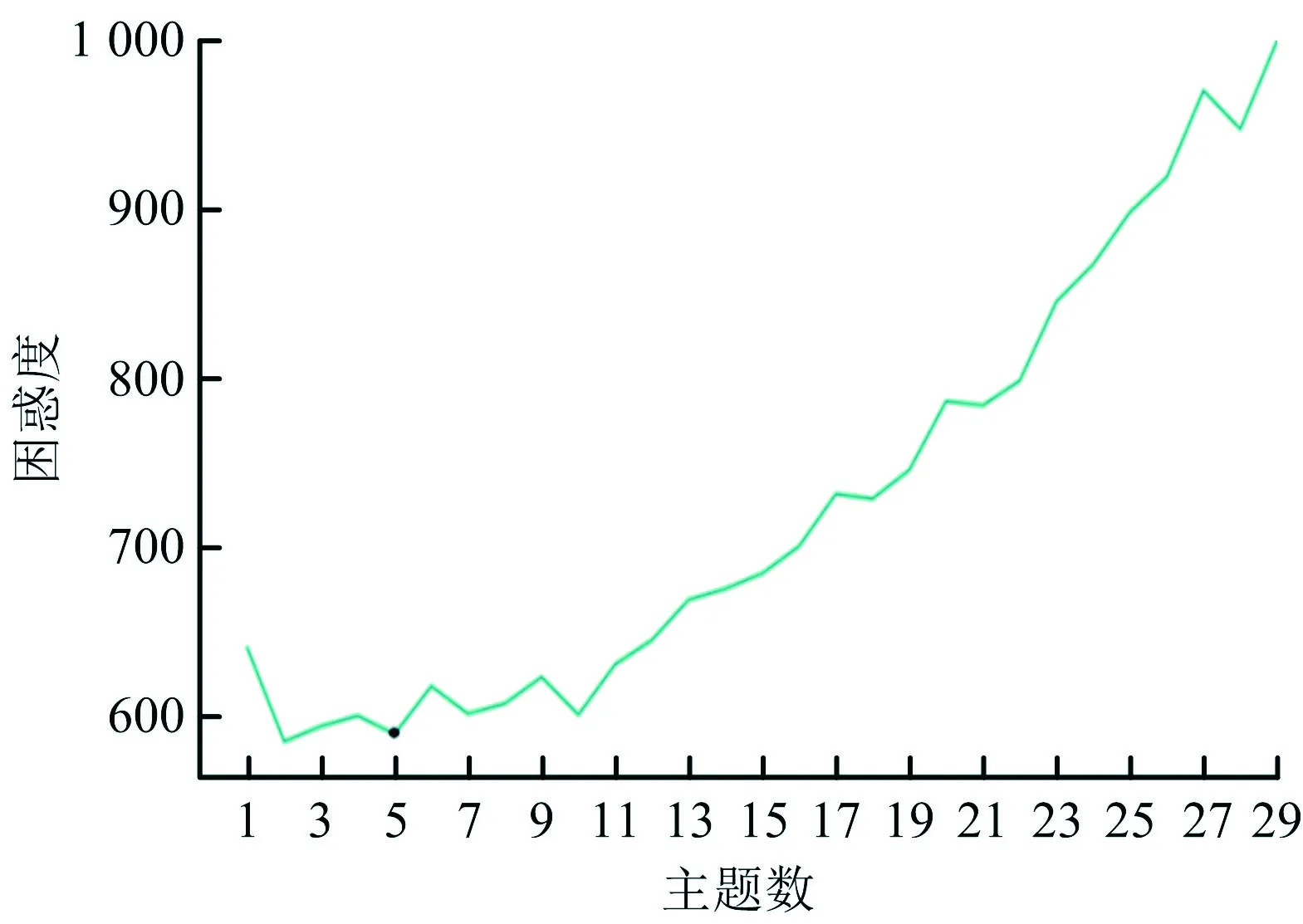
图5 困惑度指标Fig.5 Perplexityindicator
2)事故致因主题抽取结果
事故致因主题抽取结果见表4,通过主题模型求解,得到事故致因主题和关键词,并分析每个主题关键词之间的关系得到事故致因总结。其中,事故致因主题揭示了造成事故发生的主要原因类别,主题关键词反映了导致事故发生的关键细节,事故致因总结则是根据关键词对主题进一步细分为若干致因。
运用可视化工具pyLDAvis,绘制事故致因主题分布图,如图6所示。图6中左侧,圆圈代表不同的主题,主题标号与表4中相对应,圆圈大小代表了每个主题包含的事故数量,圆圈之间的距离代表了主题之间的关联程度。图右侧为频率最高的30个关键词列表。由图6可知,主题①数量最多,主题①,②距离接近且有重合部分,说明相关性较强,主题④,⑤则数量最少。
对各事故致因主题具体分析如下:

表4 主题抽取结果Table 4 Topic extraction results

图6 主题分布可视化Fig.6 Theme distribution visualization
1)员工注意力主题。由表4可知,在员工注意力主题方面,导致事故发生的主要表现为:在车间、楼梯等危险性较高区域,由于员工警惕性不强或注意力不集中而导致了事故发生。关键词“休息”反映出,休息不足或疲劳是造成注意力不集中的重要原因,“车间”“楼梯”则是员工在注意力不集中时事故高发的区域。在图4关键词网络中,该主题关键词处于中心位置,说明在关系网络中具有较高重要度。由图6可以看出,主题①数量最多,且与主题②有较高相关性。因此,从数量角度看,员工注意力不集中是造成事故发生的重要原因;从相关性角度看,员工注意力问题与作业现场风险管理问题之间存在较强关联。
2)作业现场风险管理主题。作业现场安全检查不到位、安全防护缺失、维修不及时以及未识别风险是作业现场风险管理主题的主要表现。由图4和图6可知,该主题在分布和数量上都与主题①较为相似,说明作业现场风险管理不足也是造成事故发生的重要原因之一,且与主题①具有一定关联性。因此,可以启发管理者在事故预防工作中,关注并切断2致因主题之间的某些关联要素,以提高预防工作的效果。例如,通过完善作业现场的风险管理,降低“车间”、“工作现场”的不安全状态,进而提高生产系统的容错率。
3)设备主题。设备主题由设备检查与维修、设备故障和变更管理等问题组成。通过对主题关键词分析,“检查”“维修”“巡检”等关键词突出的是设备维护不足问题,这就导致设备的不安全状态得不到及时发现和消除,从而产生安全隐患;“更换”等关键词则说明企业在变更管理工作中存在缺陷,未能消除由于设备变更而引起的事故隐患。由图6可知,该主题数量较多,也是导致事故发生的主要原因之一。
4)制度主题。从制度主题的关键词可以看出,主题主要由制度不完善、制度制定与实施、施工人员对制度不遵守等问题组成。从主题分布图中可知,相较于前3个主题,该主题数量明显较少,且与其他主题的相关性较弱。但制度本身是较为抽象的概念,往往在事故记录中难以直接体现,尽管如此,制度主题依然是5个事故致因主题之一,足以说明安全制度或管理体系问题的严峻性和重要性。
5)化学物质及工艺主题。上述4个致因主题都涉及到人因或组织缺陷,主题⑤则更加侧重于化学物质或工艺过程中本身的性质和反应。从主题关键词推断,“导热油”、“聚苯醚”等化学物质和“换热”、“蒸发”、“催化反应”等工艺过程中释放的能量是造成人员伤害及装置破坏的主要致因。因此,企业应在适当区域设立防护设施以减轻该类事故对工人及设备造成的危害。
通过聚类结果可以看出,5个主题中,4个涉及到人因或组织层面的缺陷,并占据事故致因绝大多数比重,说明事故预防的重点应放在改善人员安全素养和安全管理体系建设等方面。
4 结论
1)通过LDA主题模型、社会网络分析法等数据挖掘技术,以某化工企业2010—2016年文本类型事故数据为样本,通过挖掘关键词权重、事故构成要素关联关系、事故致因主题等潜在信息,实现了对该类事故数据的进一步识别与认识。
2)通过LDA主题模型抽取到的5个主题分别为员工注意力主题、作业现场风险管理主题、设备主题、制度主题、化学物质及工艺主题。分析聚类结果可知,员工注意力不集中、现场风险管理不足、设备检修不及时是导致事故发生的最主要原因,且员工注意力和现场风险管理之间存在较强关联性;人因和组织结构缺陷是导致大量事故发生的根本原因。
3)本文数据来源为单一化工企业,研究结果对化工行业具有一定参考价值,同时为其他行业事故文本数据挖掘提供了思路,但更系统的事故致因挖掘分析需要更全面的数据支撑。
