基于机器学习方法的安全帽佩戴行为检测*
2019-11-06杨莉琼蔡利强
杨莉琼,蔡利强,古 松
(西南科技大学 土木工程与建筑学院,四川 绵阳 621010)
0 引言
安全帽作为安全防护用品,其主要作用是保护施工现场人员的头部,防高空物体坠落,防物体打击、碰撞。为了提高监管效率满足现场实时连续监控的要求,学者们提出应用计算机视觉技术智能检测施工人员是否佩戴安全帽[1-3]。目前,安全帽检测方法主要分成2类:1类是基于传统图像特征提取的检测方法。文献[4]提出的人形检测方法易受客观环境如光照、背景等干扰;文献[5]提出基于安全帽轮廓特征的检测方法精度不高,存在较多的误报、漏报问题。2类是基于人工智能的方法。文献[6]提出的方法提高了安全帽检测精度,但未考虑安全帽是否佩戴在头部;文献[7]提出的改进方法虽然能判断工人是否佩戴安全帽,但由于工人工作姿势及身体特征的复杂多样性导致检测精度不高;文献[8]提出基于卷积神经网络的行人安全帽识别方法适合于运动目标,如果人员处于相对静止时则会产生较大误差;文献[9]提出基于深度学习的检测方法虽然检测精度较高,但检测速度比较慢,无法满足现场安全预警的实时性要求。
基于传统图像特征提取的安全帽佩戴检测方法未考虑复杂的施工环境对其精度的影响;而基于人工智能的方法具有较好的环境适应性,但文献[6-9]未考虑检测效率。本文在综合考虑现场安全监控的时效性、准确性以及复杂环境的适用性,提出1种基于机器学习的安全帽佩戴行为检测方法,提高了检测精度与效率。
1 安全帽佩戴行为检测
安全帽作为保护头部的重要装置,施工及现场管理人员进入工地后必须正确佩戴安全帽,即“人”“帽”不分离。因此,为保证图像检测结果的准确可靠,首先要检测出佩戴安全帽的头部区域,再通过提取安全帽特征的方法分析判断人员是否佩戴了安全帽。
1.1 工作平台
基于机器学习的安全帽佩戴行为检测平台如图1所示,包括部署在不同施工区域的监控相机、运行安全帽检测算法的智能监控工作站、连接相机和工作站的施工现场通信网络3部分。其中,监控相机的架设要符合《建筑工程施工现场视频监控技术规范》和其视角范围需覆盖整个监控区域的要求;相机获得的施工现场实时图像通过施工现场通信网络传输给智能监控工作站;安全帽检测算法的智能识别模块检测人员是否佩戴安全帽,并将结果通过预警模块显示在监控软件界面上,以颜色框标识在未佩戴安全帽的人员脸部。
1.2 检测流程
安全帽佩戴行为检测流程如图2所示,主要步骤如下:
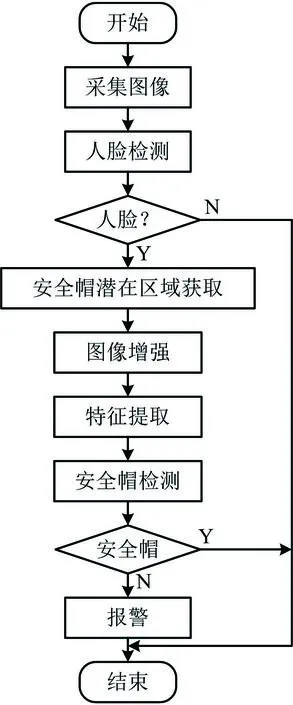
图2 施工人员安全帽佩戴检测流程Fig.2 Detection procedure on wearing of safety helmet for construction personnel
1)启动软硬件系统。监控站通过施工现场通信网络打开监控相机,同时在监控工作站启动安全帽检测软件,从相机获取的现场视频流中以帧为单位采集图像。
2)对施工现场人员进行人脸检测。安全帽检测软件利用深度学习YOLOv3算法训练出的模型定位人脸区域,当检测出人脸时根据一定比例估算安全帽的可能区域及大小。
3)对安全帽进行检测。对安全帽可能区域图像使用MSRCR(带颜色恢复的视网膜图像增强)方法进行增强处理,使用方向梯度直方图(Histogram of Oriented Gradient,HOG)提取样本的特征向量,再使用机器学习的支持向量机(Support Vector Machine,SVM)对安全帽可能区域进行检测。
4)根据检测结果进行报警。当人脸的安全帽区域没有发现安全帽时,发出警告信息并保存图像,该帧检测结束,进入下一帧图像检测。
2 基于深度学习的施工现场人脸检测
基于深度学习的人脸检测算法能够实现从端到端的网络结构,不需要人为手动提取人工特征,使用多个卷积层自动提取图像特征,并通过深层网络消除干扰因素的影响,能够大大提高识别的准确率,且对环境具有较好地鲁棒性。目前,基于深度学习的目标检测算法原理主要有2类:第1类算法通过对目标应用候选框算法产生大量的候选框,进行分类回归后得到边界框预测,虽然识别精度较高,但由于过程中产生大量候选框,导致检测速度比较慢,无法实现实时检测,如开源算法Faster R-CNN;第2类算法通过对目标图像中的逻辑划分区域进行抽样,利用卷积神经网络进行分类回归,检测速度快但精度有所下降,如SSD和YOLO算法。综合考虑现场安全监控的时效性、准确性以及复杂环境的适用性要求,选择YOLO算法进行人脸检测[10-11]。
2.1 卷积神经网络获取施工现场图像的特征图谱
卷积神经网络可以通过降维操作训练输入的施工现场图片,进而提高识别精度。该网络由施工现场图像输入层、现场目标特征提取卷积层、激励层、池化层、全连接层组成。其中,施工现场图像输入层主要是对图像进行去均值、归一化、降维等预处理;现场目标特征提取卷积层通过卷积核对目标进行局部感知,提取标志性特征,再将获取的特征与之前学习到的施工人员人脸特征进行比对,当满足一定阈值时判定目标是施工人员,最终完成施工人员的人脸识别;激励层将卷积层的输出进行非线性映射;池化层对特征进行降维处理。完成上述处理后,网络的输出层会得到关于施工人员的人脸识别特征图谱。
2.2 YOLO的人脸识别框架
YOLO采用端到端训练和检测,首先利用卷积神经网络提取施工现场图像中的目标特征,得到该图像的特征图谱;然后将输入图像分成相同大小的细胞网格,使用施工现场图像中目标的中心坐标所在细胞网格进行预测;最后根据每个细胞网格固有数量的基础框,计算出真值交并比(IOU)最高的基础框,并用来判断目标是否为施工人员的人脸。预测输出的特征图谱包含2个维度:①26×26网格数。②深度为X×(5+Y)的维度,其中X为每个细胞网格基础框的数量;Y为基础框的类别数;5表示矩形框的4个顶点坐标信息和该框的置信度,YOLO的整体结构如图3所示。

图3 YOLO整体结构Fig.3 YOLO overall structure
2.3 施工人员的人脸多尺度预测
当无法从施工现场图片中提取人脸特征时,算法需要将其图片的像素点映射到高一级尺度,进而在高一级尺度生成边界框预测信息。尺度预测得到3个边界框,通过锚点得到9个聚类中心,并分配给各级尺度:1级尺度添加卷积层输出边界框信息;2级尺度对1级尺度的倒数第2层卷积层进行上采样,并与最后16×16的特征图相加,再将结果进行卷积操作,得到边界框信息;3级尺度操作过程与2级尺度一样,只是特征图尺寸变为32×32。上述边界框有4个参数,即x,y,w,h,其中x,y表示施工现场图像中目标图像预测边界框中心点坐标值;w表示该边界框的长度;h表示边界框的宽度。
边界框预测如图4所示,其中:cx,cy表示该边界框中心所在细胞的左上角顶点坐标;pw,ph为预测边界框的宽和高,可通过式(1)~(4)预测得到预测框的4个参数(bx,by,bw,bh);σ()为sigmoid函数,输出0到1;tx和ty为预测坐标的偏移值;tw和th为尺度缩放。
bx=σtx+cx
(1)
by=σty+cy
(2)
bw=pwetw
(3)
bh=pheth
(4)

图4 边界框预测Fig.4 Prediction of boundary frame
YOLO框架对每个边界框进行逻辑回归分析后得到其分类得分,若预测边界框接近真实边界框,得分为1;若预测边界框与真实边界框相差较多,以至低于阈值0.5,得分为0,该预测框则被忽略。
2.4 施工现场的人脸训练
YOLO训练采用损失函数见式(5),考虑了预测框的位置、大小、种类、置信度等信息。

(5)

3 基于支持向量机的安全帽检测
在识别出人脸并得到人脸位置后,检测算法通过安全帽与人脸的关系推测出安全帽可能的区域。根据提前制作的大量安全帽正负样本,使用HOG提取样本的特征向量,再利用SVM分类器对安全帽区域进行检测[12-13]。若未佩戴安全帽,则报警并保存当前帧。关键步骤如下。
1)对安全帽图像进行增强处理
在实际施工环境中,光照会影响成像效果。如果不滤除光照影响,算法精度将受到很大的影响。本文应用基于Retinex算法的MSRCR图像增强方法对施工场景中的安全帽进行图像增强,使得整幅图像亮度适中、色彩饱和,达到符合人眼观察和细节完整描述的目的。Retinex是基于光照的均匀程度对物体的颜色没有影响,不同光照下的同一物体应是相同颜色的理论。人眼获取的图像S是由于光照L照射到物体上,根据每个物体的反射特性反射到人眼得到的,并且反射特性R与物体的性质有关,与光照L无关。使用MSRCR方法对图像处理后其亮度和对比度都有所增强,色彩饱和鲜明。
2)提取安全帽的HOG特征
HOG特征是对目标局部纹理的描述,通过检测梯度方向和目标边缘密度实现对目标的检测。内容如下:对采集的安全帽图像进行灰度化和归一化后计算每个像素的梯度信息;以梯度幅值的方向权重为标准进行投影,并将图像分为一些小的细胞;提取细胞元特征,并计算归一化特征向量;对特征向量进行拼接得到原始图像的完整特征向量,用于SVM分类操作[14]。对1张像素为472 px×350 px的安全帽图片进行HOG特征提取,如图5所示。设置块像素为16 px×16 px,细胞像素为8 px×8 px,block在检测窗口中上下移动的像素为8 px×8 px,一个细胞的梯度直方图化为9个bin,滑动窗口在检测图片中上下移动像素为8 px×8 px,得到该安全帽如图5所示的HOG特征。

图5 安全帽HOG特征提取Fig.5 HOG features extraction of safety helmet
3)应用SVM对安全帽进行分类
得到上述安全帽特征后,利用SVM进行识别。对于安全帽这类目标,图像特征明显、类别较少,能充分发挥SVM分类器的效率。同时搭配颜色识别,SVM的分类准确度会更高。这里采用线性不可分的分类器,引入松弛变量ξi,得到较好的分类超平面:
yi(ωTxi+b)≥1-ξi
(6)
式中:i为样本点;y为类标记;ωT为超平面转置;x为向量;ξ为松弛变量。
目标函数变为:
(7)
式中:‖ω‖为ω的二阶范数;C为惩罚因子,用于调节参数,构造拉格朗日函数并求解对偶后的最大值最小值问题:
(8)
式中:α为拉格朗日乘子;s.t.为约束条件。制作安全帽正样本以及施工现场环境负样本,进行HOG特征提取,并使用线性不可分SVM分类器进行训练得到检测集。对一张图片上的安全帽进行检测如图6所示。

图6 安全帽检测Fig.6 Detection of safety helmet
4 实验与测试结果
4.1 工程背景
某高铁站房扩建工程临近既有线路施工,环境复杂;现场人员构成复杂且数量较多,分别归属于不同的参与方,管理难度较大。为了便于监管,现场人员中的监理人员、施工管理人员、技术人员、作业工人分别佩戴蓝色、白色、红色、黄色的安全帽。由于实际工程施工受限,本文方法测试选在入口处对进出工地的人员开展安全帽佩戴智能识别测试。
4.2 人员安全帽数据集制作
1)施工现场人脸数据集制作
通过工地调查,共收集5 600张样本。应用深度学习算法,对人员是否佩戴安全帽行为识别首先要检测到人脸。将5 600张样本分为一类,每张样本包含1个人脸,对每1张样本进行标注后开始训练。
数据集建好后,将其中90%作为训练集,10%作为测试集,划分训练数据和测试数据后,下载权重文件darknet53.conv.74,并在此权重上进行人脸数据的训练,9 000次迭代后误差降为0.02。
2)安全帽数据集制作
通过工地调查,共收集3 000张样本。人员佩戴各种颜色的安全帽为正样本,与安全帽形状、颜色类似的施工现场其他物体为负样本。考虑到施工人员未佩戴安全帽时,头发形状与安全帽形状也有相似之处,负样本中又添加了各种发型及颜色样本,将正负样本分类标记后进行训练,得到训练结果。
4.3 现场验证
工地入口有3个,选择人流较大的A出口,将网络监控摄像头架设在入口处进行图像采集,通过图像算法程序分析后对未佩戴安全帽的人员进行预警,并框选人脸显示在软件界面上。为验证本文方法的准确性,设定了人员稀疏、人员拥挤等情况进行现场测试验证,实验效果如图7所示。

图7 施工人员安全帽佩戴检测Fig.7 Detection of safety helmet wearing for construction personnel
通过1 000次的测试,本系统能够准确识别在稀疏或拥挤状态下未佩戴安全帽的人员,并且能够对多种颜色的安全帽进行识别。算法进行优化后对多人同时进入时存在部分遮挡的情况也能较为准确的识别,实验结果如图8所示。其中:“正确”表示工人未佩戴安全帽被识别,比例约90%;“错误”表示工人佩戴安全帽被识别为没有佩戴安全帽,比例约8%;“漏检”表示工人未佩戴安全帽未被识别,比例约2%。同时,测试结果满足实时性的要求,多次测试的统计数据显示,采集一帧图像的时间小于50 ms,检测一帧图像的时间小于50 ms。因此,系统识别的时间不到100 ms。

图8 实验结果Fig.8 Experimental results
为检验对复杂环境的适应性,选择在施工现场的塔吊作业区域进行实验。测试达到200次,正确率约91%、错误率约6%、漏检率约3%。现场的实验效果如图9所示。

图9 塔吊作业区域检测效果Fig.9 Detection effect in tower crane operation
5 结论
1)提出1种基于机器学习的安全帽佩戴行为检测方法,并在施工区域验证其正确有效。
2)测试数据表明在施工通道和塔吊作业区域,该方法可实时有效的检测出工人未戴安全帽的行为,识别率达到90%以上,识别时间低于0.1 s。
3)考虑图像受环境光照和相机成像质量影响,下一步将围绕算法稳定性开展深入研究,尤其是结合不同施工区域的成像特点对算法进行针对性优化,并考虑适当引入其他传感器进一步提高该方法的实用性。
