基于LSTM 模型的Web 页面访问量预测
2019-11-05林峰江荔
林峰,江荔
(福州职业技术学院,福州350108)
0 引言
互联网用户的激增和上网行为的普及,给网站的正常运维带来了挑战。为了应对用户的高并发访问,负载均衡、缓存技术、分布式存储是IT 运维人员常用的技术手段和解决方案。特别是缓存技术的使用,将Web 页面内容存储在专用的缓存服务器内存中,能够提高网页的加载速度,减少磁盘的I/O 操作,极大地缓解网站的负载,为用户带来更好的体验。但是缓存服务器的数量和性能是有限的,特别是中小企业的Web站点,不可能将庞大的Web 页面内容完全存储到缓存服务器中。因此如何预测未来高热度的Web 页面地址,并将其内容提前存储到缓存服务器中已成为当前研究的热点之一[1-3]。
时间序列分析是用来研究数据随时间变化而变化的一类技术,它的基本出发点是事物的发展具有一定的连续性,会按照本身固有的规律进行,只要规律依赖的条件不产生质的变化,则事物未来的基本发展趋势仍将会有规律的延续下去。Web 页面访问量就可采用时间序列分析技术进行预测。时间序列分析常用的算法包括移动平均(MA)、指数平滑(ES)和差分自回归移动平均模型(ARIMA),这些算法基于数理统计,对大数据量的时间序列预测存在精度不高的问题[4]。LSTM(Long Short Term Memory,长短期记忆网络)是一种循环神经网络,是当前深度学习技术领域中较为热门的算法模型,在语音识别、时间序列、机器翻译等领域具有广泛而成功的应用,对大数据量的时间序列预测有较高的精确度[5-6]。
本文基于循环人工神经网络的理论,通过对Web页面访问量进行标准化预处理,构造含1,169 个参数的长短期记忆网络,经过100 轮的训练,长短期记忆网络损失函数可逐步收敛,通过样本集的测试,模型均方根误差(Root Mean Square Error,RMSE)可达19.45,具有较高的准确性,可用于Web 页面访问量的预测,结合Web 缓存等技术,对提高网站的整体性能将有显著的成效。
1 LSTM网络
循环神经网络(Recurrent Neural Network,RNN)是一类递归神经网络,可处理序列数据,具有记忆性、持续性等特点,能以很高的效率对序列特征进行学习,在机器翻译、语音识别和个性化推荐领域中,有着广泛的应用。LSTM 是循环神经网络RNN 的一种改进版本,由Hochreiter 和Schmidhuber 于1997 年提出,可解决传统RNN 网络梯度消失、不能有效保留长时间记忆信息等缺点。LSTM 通过输入门(Input Gate)、忘记门(Forget Gate)、候选门(Candidate Gate)、输出门(Output Gate)等4 个相互交互的“门”单元,控制着记忆信息值的修改。
忘记门是较为重要和复杂的门单元,其作用是控制着要从前面的记忆中丢弃多少信息。以音乐个性化推荐为例,用户过去的行为操作,对当前的推荐决策有重要的影响:对于正向操作行为,如用户对某一位歌手的歌曲特别感兴趣,那么这种正向操作的“记忆”将得到加强;相反对于负向操作行为,如删除、跳过等行为,其对应的信息则会逐渐减弱。忘记门是通过如公式(1)所示的激活函数来实现的:

式中通过将上一隐藏层的输出信息St-1与当前的输入xt进行线性组合,利用激活函数将函数值进行压缩,得到一个0 到1 之间的值:当该值越接近于1 时,表征记忆体保留的信息越多;当该值越接近于0 时,表征记忆体丢弃的信息越多[7-9]。
2 基于LSTM模型的Web页面访问预测
2.1 数据集描述
本文所使用的时间序列数据集,来自互联网标准测试数据集“Web Traffic Time Series Forecasting”,该数据集记录了近145,000 篇维基百科页面,从2015 年7月1 日到2016 年12 月31 日近550 天内,每日的访问量情况。数据格式如表1 所示。
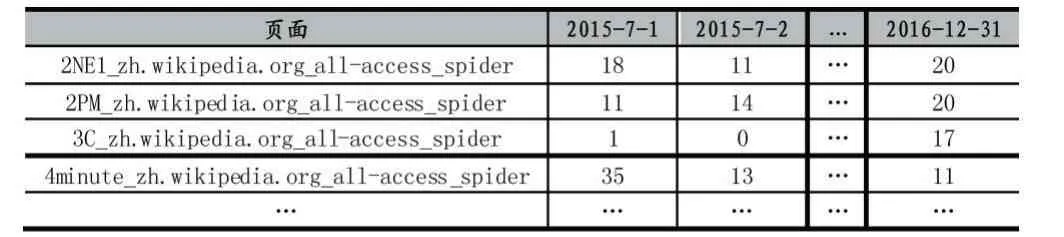
表1 数据集样例
其中,中文维基百科“3C”词条的页面日访问情况如图1 所示,可以观测到该访问曲线存在两个高峰值,若能成功预测出现高峰的日期,并提前对该页面内容进行预处理,势必能极大提高网站性能,缓解服务器压力。

图1 维基百科某页面日访问情况
2.2 数据预处理
页面访问量数据原始值取值范围差异过大,不适合直接用于分析和建模,需要经过标准化预处理。根据本文问题域的特点,采用如公式(2)所示的最大最小标准化方法,经过预处理后的时间序列值的范围在[0,1],适合进行统一的建模分析使用。

2.3 构建LSTM循环神经网络
数据集经过最大最小标准化预处理后,按时间递进关系,将前70%的数据用做训练集,后30%的数据用做测试集。需要注意的是,与传统有监督学习建模方法不同,训练集和测试集必须严格按照时间排序,不能随机抽选,以避免模型无法学习到正确的时间特征。
经过多次分析测试,本文所构建的LSTM 循环神经网络主要由LSTM 及DENSE 两个层级构成,其中LSTM 层共有16 个神经元,涉及参数1,152 个;DENSE层共有1 个神经元,涉及参数17 个,整个神经网络合计参数1,169 个。
此外,在LSTM 循环神经网络迭代训练过程中,使用的损失函数为均方误差(Mean-Square Error,MSE),优化函数使用标准的Adam 函数,整个神经网络具有较高的学习效率及较快的收敛速度。
3 实验结果分析
3.1 实验环境
本次实验所用计算机设备CPU 型号为英特尔Xeon E5-2650,8 核心16 线程,主频2.2GHz;内存16GB,DDR3 代。LSTM 网络的构建前端使用Keras 2.2.2,后端使用TensorFlow 1.11.0。
3.2 结果分析
通过使用开源框架Keras 及TensorFlow 构建LSTM 网络模型,经过100 轮的训练,用均方误差MSE表征的损失函数,已可逐步收敛稳定,且不再随训练周期的增加而减小。损失函数具体收敛情况如图2所示。
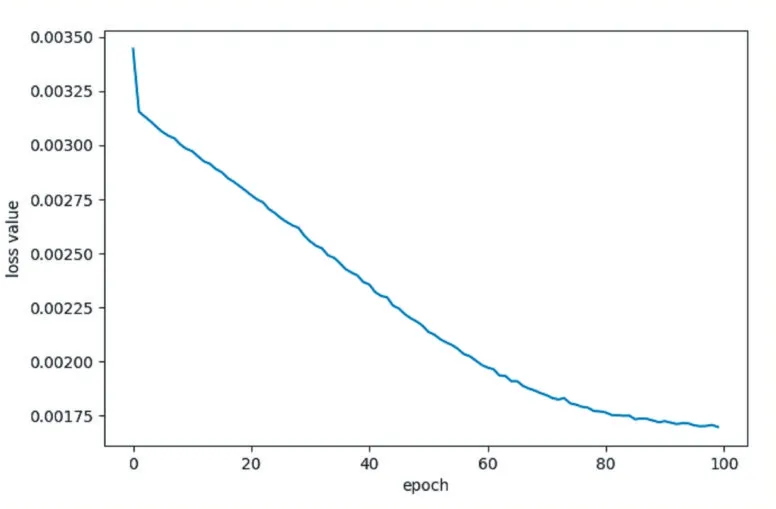
图2 损失函数收敛情况
关于所训练模型的准确性情况,以中文维基百科“3C”词条为例,经测试,训练集(前70%的数据)均方根误差RMSE 值为8.64,测试集(后30%的数据)均方根误差RMSE 值为19.45,具有较高的准确性,可用于实际生产环境。同时观察如图3 所示的曲线,网络模型可以通过学习到的第一次波峰特征,准确预测到第二次出现波峰的时间,预测数据与实际数据拟合情况良好。

图3 模型拟合情况
4 结语
互联网用户的激增和上网行为的普及,为网站的正常运维带来了挑战。如何预测未来高热度的Web页面地址,并将其内容提前存储到缓存服务器中已成为当前研究的热点之一。本文以互联网标准测试数据集“Web Traffic Time Series Forecasting”为研究对象,通过对数据进行最大最小预处理,将前70%数据作为训练样本集,后30%数据作为测试样本集,构建了含1,169 个参数的LSTM 网络,经过100 轮周期的训练,模型可逐渐收敛,最终测试集均方根误差可控制在20内,具有较高的准确性,可与Web 缓存技术进行结合,对网站性能的提升将有显著的成效。
