基于随机森林的数据分类应用研究
2019-11-04崔喆森吴金冉
崔喆森,吴金冉
(1.长治学院计算机系,山西长治046000;2.昆士兰科技大学数学科学学院,澳大利亚布里斯班4001)
数据分类一直以来都是数据挖掘方向很重要的一个研究领域,其中利用分类算法进行数据预测也是近些年研究的热点,现在利用机器学习算法针对各个行业数据进行分类和预测的应用很多。在这里,通过对优秀分类算法随机森林进行分析和应用,总结出算法的性能优势和特点,为之后的进一步研究做准备。
这些年衍生出了很多数据挖掘分类算法,应用比较广泛的分类算法有:决策树[1]、贝叶斯[2]、神经网络、KNN、支持向量机[3]和基于关联规则[4]的分类等,相关的改进算法也很多。
由于随机森林算法优良的特性,应用比较广泛,其原理就是把决策树看作一个个的单元,然后将这些决策树单元集成在一起,其原理体现了机器学习领域中的集成学习[5](Ensemble Learning)的思想。随机森林中的森林指的就是将很多颗决策树集成在一起。每一颗决策树都可以作为一个分类器(假设现在针对分类问题进行处理),针对同一个输入数据,可能每颗决策树的输出分类结果都不一样,这时候就需要对多种分类结果进行统计,统计次数最多的类别就是最终的分类结果,这种解决问题的思路充分体现了集成思想。
1 随机森林基本概念
1.1 信息与熵以及信息增益
信息是用来消除变量的随机不确定性。熵用来度量变量的不确定性,熵的取值大小和变量的不确定性成正比关系。具体到使用随机森林算法进行数据分类的问题,熵越大说明输入的数据样本的分类确定性越高,反之分类确定性会越低。在随机森林中,根据信息增益[6]的取值大小选择符合条件的特征,信息增益值越大,这个特征的可选择性越好。
1.2 决策树
决策树顾名思义其形状就是树形结构,由边和节点构成。决策树的集成就可以构成随机森林,这样决策树和随机森林的关系就很明白了。决策树中的每一个分支节点表示其属性的不同取值,到达叶结点的输出就是决策树对于输入数据样本的最终分类判断。
1.3 集成学习
集成学习的核心思想就是算法集成,通过对几种算法的整合给出最终分类。具体工作原理就是由每种算法构成的分类器对输入数据样本进行预测,然后对输出预测结果进行整合,最后得出最终结果。此预测结果一般都优于只使用一种分类算法的预测。探索的随机森林算法充分体现了集成思想的精髓,通过整合多颗决策树的输出结果,给出最终预测。
2 数据处理
使用python语言实现了随机森林算法的整个流程,并且在泰坦尼克乘客数据集上验证随机森林算法的有效性,使用此算法对泰坦尼克号轮船上的乘客进行命运预测。
2.1 数据预处理
首先要导入泰坦尼克乘客数据集,并对数据集做相关的处理。
2.1.1 数据探索
在做进一步数据建模前,首先需要对数据变量名、数值分布和缺失值情况等等有初步了解。图1是针对变量age的倾斜度画出的直方图。

图1 变量age倾斜度示意图
为了更好的展现数据集中的特征的情况,可以通过箱型图的形式展示age变量的数值分布以及异常值,如图2所示。

图2 变量age箱型图
2.1.2 数据划分
通常定义分类错误的样本个数占样本总数的比例作为错误率(error rate),即如果在m个样本中有n个样本分类错误,则错误率公式为E=n/m;与之对应,精度公式1-n/m。模型在训练集上的误差称为训练误差,在新样本上的误差称为泛化误差[7](generalization error)。
2.1.3 数据填充
本模型要求数据样本完全没有缺失值。所以用中位数填充所有训练集中的数值变量。做数据填充时,无论是用统计量还是机器学习模型,都必须用训练集中的信息。在做模型测试前对测试集做数据填充时,也需要用训练集的统计量或基于训练集训练的机器学习模型。
2.1.4 类别变量处理
由于数据集中类别变量其值不是数值型,因此需要将类别型变量转换为数值型变量。采用独热编码为每个独立值创建一个哑变量[8]。
2.2 特征选择
特征选择是指在数据集中选取若干代表性强或预测能力强的变量子集,使得机器学习模型训练更高效且性能不下降。
使用特征选择器的属性得到特征的重要性,利用柱状图可视化显示特征排序如图3所示。
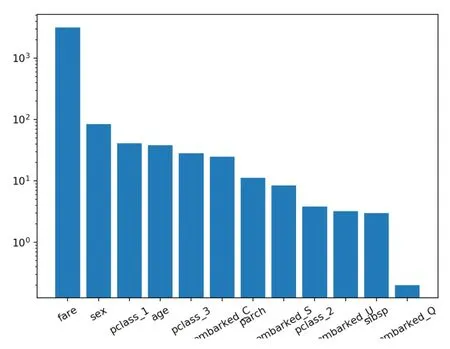
图3 特征排序柱状图
在这里,选择80%的变量即10 个重要性最高的变量作为特征。
3 建模与调优
创建随机森林模型对象,由于该模型有一系列超参数,需要在训练模型前人工指定。对于具体问题,无法事先明确知道哪一组超参数会取得最佳效果,因此需要做超参数调优得到最佳的超参数组合。超参数调优需要指定以下几个选项:超参数的搜索范围;调优算法;评估方法,即重采样策略和评估指标。调优的超参数范围为最大深度:3、4和5;最小掺杂度减少比例:0.001和0.005。重采样会将训练集按照一定比例进一步划分成训练集和验证集,在这里选择的重采样策略是交叉验证法[9],共需要搜索6组超参数组合,计算每组超参数的验证集平均精度,确定了最佳的超参数组合是最大深度和最小掺杂度减少比例。调用网格搜索[10]超参数调优器做超参数调优,得到最优超参数组合的随机森林模型。调优结果展示如图4所示。
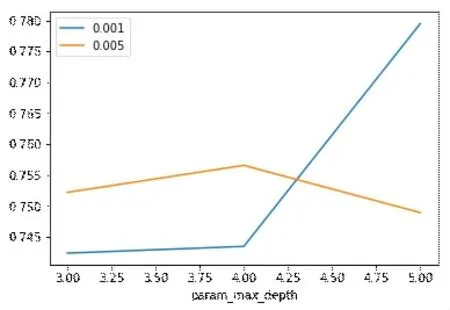
图4 超参数调优图
在选出了最优的超参数组合后,调用全部的训练集数据和确定的超参数组合训练模型,最终得到我们需要的随机森林模型。
4 测试与评估
在训练集上做完超参数调优和模型训练后,需要在测试集上对模型做一次性公正的评估。对于二分类问题,常用ROC 曲线下面积(area under curve,AUC)作为模型性能指标,在介绍该指标之前,首先需要给出下面4 种预测结果。真阳性、假阳性、真阴性、假阴性。
另外常用的还有查准率(precision)、查全率(recall)和两者都考虑的F1。受试者工作特征曲线(ROC 曲线),即假阳性率(FPR)为横轴、真阳性率(TPR)为纵轴所画出的曲线。分类阈值分别取0 到1 中的各个数,计算不同阈值对应的FPR和TPR,然后描点得到ROC曲线。
AUC会出现如下3种情况:
(1)0.5 (2)AUC=0.5,AUC=0.5时,模型无意义; (3)0<=AUC<0.5,0<=AUC<0.5 时,模型差于随机猜测,但如果总是反预测而行,反而能产生预测价值。 最终的ROC曲线图如图5所示。 图5 ROC曲线图 ROC 曲线下面积(AUC)值为0.852,表现较好,优于随机猜测,说明本模型能够起到很好的泰坦尼克乘客命运预测作用。 探索了随机森林算法在分类问题上的应用,并且针对泰坦尼克乘客数据集进行了乘客命运预测,通过实验验证证明此算法有着很好的分类作用。下一步的研究工作是针对随机森林算法的超参数调优寻找更好的方法。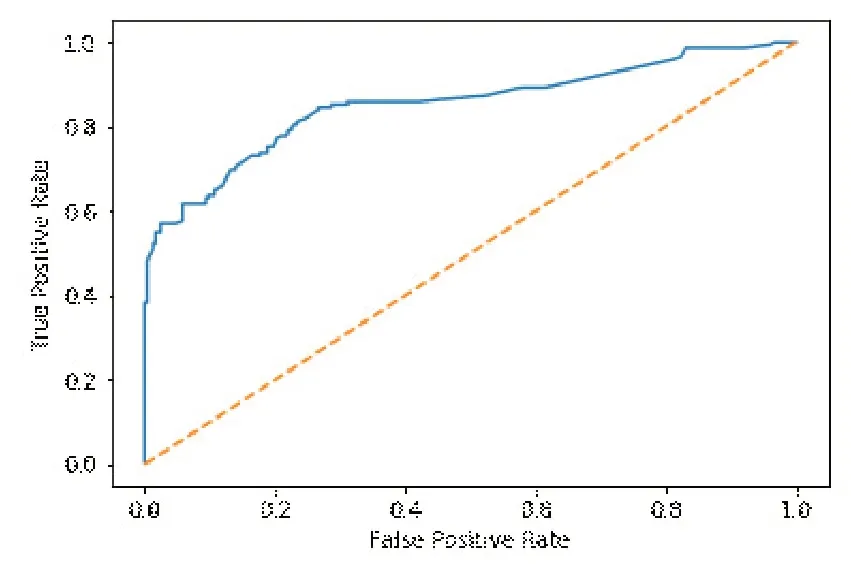
5 总结
