基于Keras的分类预测应用研究
2019-11-04高云,彭炜
高 云,彭 炜
(山西大同大学计算机与网络工程学院,山西大同037009)
人工神经网络(Artificial Neural Networks,ANN),是模拟生物神经网络进行信息处理的一种数学模型。它从信息处理的角度出发,以对大脑的生理研究成果为基础,建立一种简单模型,按不同的连接方式组成不同的网络,其作用在于模拟大脑的思考机制,从而实现特定的功能[1-2]。
自从1943年, 美国心理学家McCulloch 和数学家Pitts 联合提出了形式神经元的数学模型MP模型, 神经网络就逐渐成为了一种运算模型。它由大量的节点(或称神经元)之间相互联接构成, 每个节点代表一种特定的称为激励函数的输出函数。每两个节点间的权重就相当于人工神经网络的记忆, 其输出则依据网络特征的不同而不同。而网络自身通常都是对自然界某种算法或者函数的逼近, 也可能是对一种逻辑策略的表达[3]。
经过十多年的发展, 人工神经网络已经取得了很大的进展, 其在自动控制、预测估计、生物、医学、经济等各个领域已成功地解决了许多现代计算机难以解决的实际问题, 表现出了良好的智能特性。
1 人工神经网络研究综述
人工神经元是人工神经网络操作的基本信息处理单位,它是人工神经网络的设计基础[1]。其模型如图1所示。
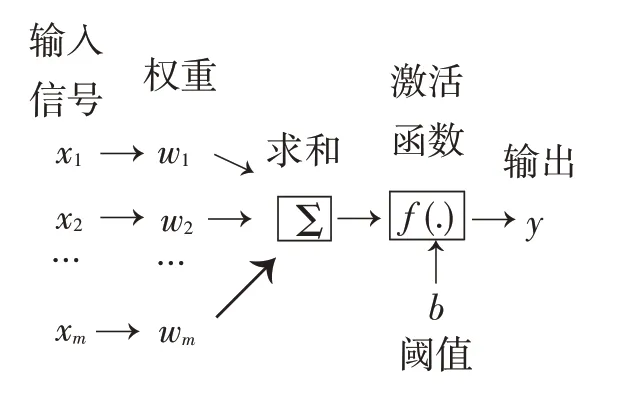
图1 人工神元模型
一个人工神经元对输入信号X=[x1,x2,…,xm]T的输出y为y=f(μ+b),其中激活函数目前使用最广泛的为Rule函数,Rule函数表达形式为:
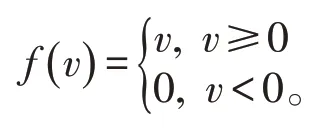
由于其计算简单, 效果更佳, 目前已取代其他激活函数成为应用最广泛的激活函数。
随着人工神经网络的发展,也提出了多种不同的学习规则,针对不同结构的网络,可以选取不同的学习算法。而用于解决分类和预测问题的网络中, 通常会选用δ学习规则(误差校正学习算法)。δ学习规则是根据神经网络的输出误差再去对神经元的连接强度(权值)进行修正,是有指导的学习[4]。
对权值的修正为Δwij=ηδjYi,其中η为学习率,δj=Tj-Yj为j的偏差,即j的实际输出值和期望值之差,是否完成神经网络的训练常使用误差函数E是否小于某一个设定的值来衡量。E为衡量实际输出向量Yk与期望值向量Tk误差大小的函数,常采用二乘误差函数来定义为:
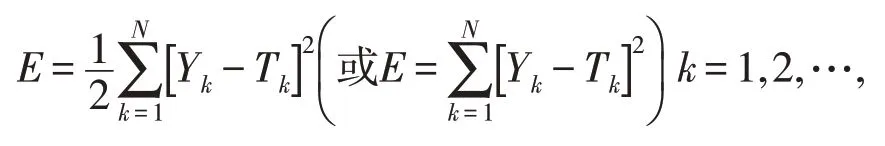
N为训练样本个数。
2 BP神经网络原理分析
BP 神经网络学习算法可以说是目前最成功的也是应用最广泛的神经网络学习算法。BP 神经网络就是一个“万能的模型+误差修正函数”,是一种按误差逆向传播算法进行训练的多层前馈网络。每次根据训练得到的结果与预想结果进行误差分析,进而修改权值和阈值,一步一步得到能输出和预想结果一致的模型。BP 神经网络模型拓扑结构包括输入层(input),隐层(hide layer)和输出层(output layer)。
如图2所示的即为3个输入节点,4个隐层节点,1个输出节点的一个三层BP神经网络。
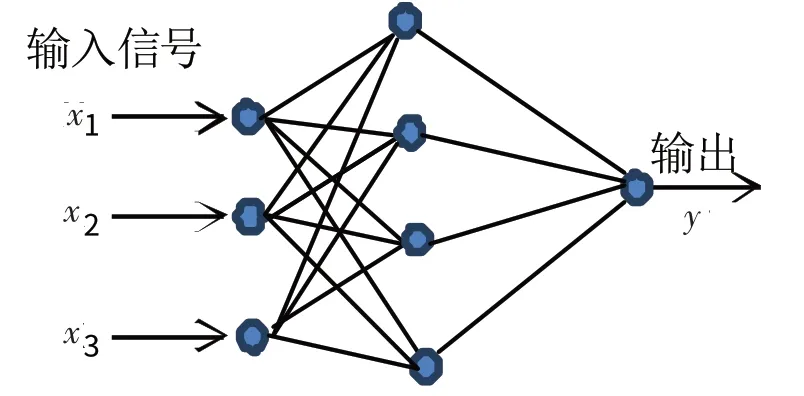
图2 三层BP神经网络
BP 算法的学习过程由信号的正向传播与误差的逆向传播两个过程组成。
2.1 BP神经元
如图3所示的为第j个基本BP神经元,它只具有三个最基本也是最重要的功能:加权、求和与转移。

图3 BP神经元
第j个神经元的净输入值Sj为:
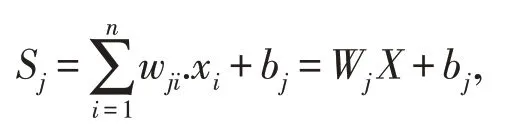
其中x1,x2,…,xn分别代表来自神经元1,2,…,n的输入;wj1,wj2,…,wjn分别表示神经元1,2,…,n与第j个神经元的权值;bj为阈值;f(.)为传递函数;yj为第j个神经元的输出。X=[x1,x2,…,xn]T,Wj=[wj,wj2,…,wjn], 如果让x0=1,wj0=bj, 则X=[x0,x1,…,xn]T,Wj=[wj,wj1,…wjn],此时节点j的净输入值Sj可表示为:
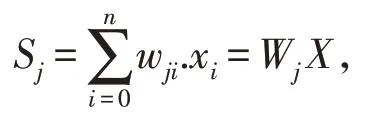
净输入值Sj通过f(.)转换后, 得到第j个神经元的输出yj:

上式中的f(.)不仅是单调上升函数,而且也一定是有界函数,因为神经细胞传递的信号不可能无限增加,一定会有一个最大值。
2.2 正向传播
设BP 网络的输入层有n个节点,隐层有q个节点, 输出层有m个节点, 输入层与隐层之间的权值为vki, 隐层与输出层之间的权值为wjk[5]。隐层的传递函数为f1(.),输出层的传递函数为f2(.),则隐层节点的输出为(将阈值写入求和项中):

输出层节点的输出为:
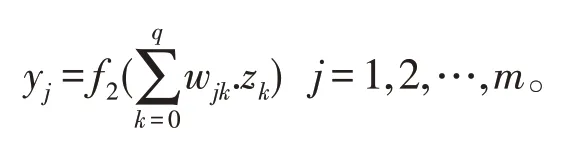
至此BP 网络就完成了n维空间向量对m维空间的近似映射[6]。
2.3 逆向传播
2.3.1 误差函数
用x1,x2,...,xP来表示输入的P个学习样本,则第p个样本输入到网络后会得到输出使用平方误差函数,对于全部的P个样本,全局误差函数表示为:

2.3.2 输出层权值的变化
采用累计误差BP 算法调整权值wjk, 使全局误差E变小,即:

式中:η-学习率。
定义误差信号为:
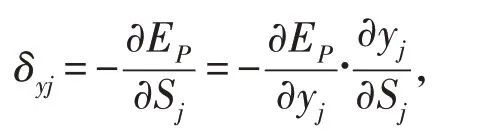
其中第一项:
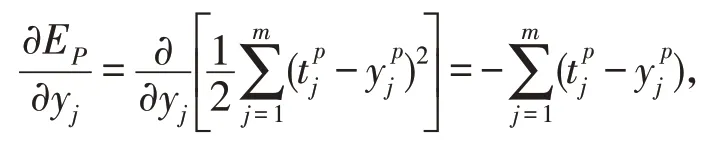
第二项:

是输出层的偏微分。
于是:

由链定理得:

于是输出层各神经元的权值调整公式为:

2.3.3 隐层权值的变化
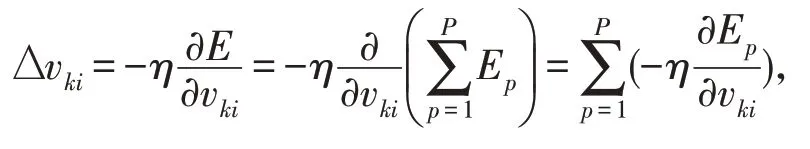
定义误差信号为:

其中第一项:

依链定理有:
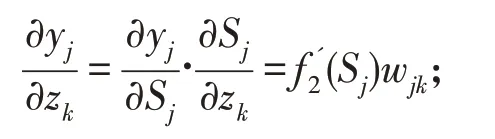
第二项:
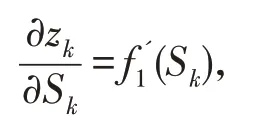
是隐层传递函数的偏微分。
于是:

由链定理得:

从而得到隐层各神经元的权值调整公式为:

3 使用Keras建立神经网络模型的设计实现
Scikit-Learn中并没有神经网络模型,我们认为Python中比较好的神经网络算法库是Keras,这是一个强大而易用的深度学习算法库。
选用了两组某餐饮业的部分营业情况数据,目的是观察数据量的多少对分类预测结果正确性的影响。根据餐饮销售量的情况和当天对应的各项指标使用Keras 算法库建立神经网络模型, 选取激活函数, 编译模型, 训练模型, 进行分类预测, 即对应天气情况,周末和促销情况不同时,销量会出现“高”、“中”、“低”的变化,最后将模型以混淆矩阵的可视化形式展示出来。
3.1 数据准备
在建立模型之前需要进行数据导入,但是导入的数据格式有时并不能满足要进行分类预测数据的格式要求, 所以还需将导入数据进行格式转换,之后才能建立模型,这一过程即为数据准备过程。这里的数据准备不同于数据清洗、数据规约等数据预处理工作。
算法中也需要导入pandas 库, pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。pandas提供了大量能使我们快速便捷地处理数据的函数和方法。它是使Python 成为强大而高效的数据分析环境的重要因素之一。
数据存放文件为csv 文件,CSV 是纯文本文件,不包含很多格式信息在里面。CSV文件的体积会更小,创建分发读取更加方便,适合存放结构化信息,比如记录的导出,流量统计等等。
利用pd.read_csv()方法读取filename 所指定的文件,并重新设置“序号”列成为index 值,由于需要处理汉字,将编码设为“gbk”。
导入数据时由于数据是类别标签,要将它转换为数据, 为了便于理解,这里对于每个类别标签只考虑两种分类情况。用 1 来表示“good”,“yes”、“hign”这3个属性,用0来表示“bad”,“no”,“low”。
原始数据格式如图4所示。
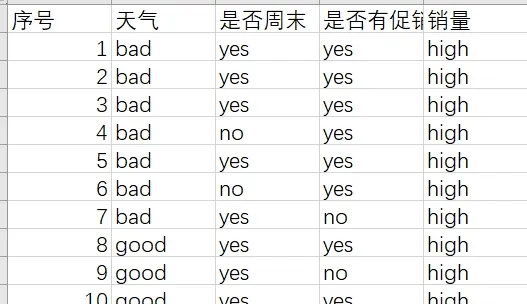
图4 原始数据模式图
将导入的数据切片处理, 取3 列即“天气”列,“是否周末”列和“是否有促销”列中所有的行数据为自变量,第4 列(“销量”)中所有行数据为因变量,按照整型识别进行数据转换。转换后的数据格式如图5所示。

图5 转换后的数据模式图
3.2 模型建立
建立并训练模型需要keras.models 和keras.layers 库, 将其导入采用的是Kera 中的序贯模型(Sequential)。
序贯模型是多个网络层的线性堆叠, 也就是“一条路走到黑”,通过.add()方法一个个的将layer加入模型中。应用神经网络算法进行建模,输入节点与隐藏节点的数目应该根据实际需要而建立,并不是越多越好。隐层节点太少会导致模型训练不够完善,太多又会导致网络出现过拟合现象。
因此神经网络采用了3 个输入节点,10 个隐藏节点和1个输出节点。激活函数也是必须考虑的问题之一,激活函数有很多种,选取时需要考虑函数两侧数据层数据的特点,即一个模型可以选取不同的激活函数。在建立输入层和隐藏层时使用relu函数作为激活函数,能够大幅度提供准确度。建立隐藏层与输出层时, 由于是0-1 输出, 所以使用sigmoid函数作为激活函数。
编译模型时,常见的损失函数有mean_squared_error、categorical_crossentropy 等。由于我们做的是二元分类, 所以指定损失函数为binary_crossentropy,模式为binary。另外, 求解方法指定用adam,还有sgd、rmsprop等。
训练模型,学习1000次之后进行分类预测。虽然神经网络的模型实现方式不同,但是其使用方式大同小异,都是构建模型,然后调用fit 方法来训练模型,调用predict方法进行预测。
通过对两组不同的数据进行分类预测,发现在数据基本正确的情况下,数据量多的一组会表现出更优的正确性。
3.3 分类预测算法过程
由上可知,Keras实现分类预测算法过程如下:
1) 参数初始化, 导入数据并将其转换为所需格式;
2)正确的选取自变量和因变量所在的数据区域,并将其切片;
3)建立模型,根据实际问题的规模选取合适的输入节点,隐层节点及输出节点的数目;
4) 根据实际问题选取适合的输入层与输出层的激活函数;
5)选取合适的损失函数并编译模型;
6)训练模型后进行分类预测,得出结果并对结果进行分析。
3.4 生成混淆矩阵
模型建立训练后的分类预测结果需要通过可视化方式最终呈现给用户,选取了混淆矩阵图作为数据可视化方式。
由于Python 自身并没有混淆矩阵可视化函数能够直接调用,所以编写了cm_plot.py 文件来实现数据的可视化。该文件包括的混淆矩阵可视化函数具有两个参数,分别为分类项与分类预测结果,将其放置在python所在位置的site-packages目录,用户可以像调用库函数那样方便的调用该函数。
混淆矩阵函数confusion_matrix 位于sklearn.metrics库中,将其导入并建立混淆矩阵。
导入作图库matplotlib.pyplot,绘制混淆矩阵图,配色风格使用cm.Greens,在官网中有更多的风格可以满足使用者的不同爱好。
绘制混淆矩阵时需设置混淆矩阵图的颜色标签、数据标签、坐标轴(x、y) 标签等一些可视化属性,最后将生成的混淆矩阵对象plt返回。
自定义函数cm_plot.py 编写完成后, 即可将其使用类库相同方式进行导入,并调用show()方法显示混淆矩阵可视化结果。
两组数据生成的混淆矩阵图分别如图6 和图7所示。

图6 34数据量混淆矩阵图

图7 102数据量混淆矩阵图
4 分析结果
在数据大多正确情况下,根据所得的混淆矩阵图看出,检测样本34个时,预测正确的个数为26个,预测准确率为76.4%, 较低, 是由于神经网络训练时需要较多样本,而这里是由于训练数据较少造成的。当检测样本增加为102 个时,预测正确的个数为80 个, 预测准确率为78.4%, 也验证了数据量的增加会使预测正确率有一定的上升。
文中数据由于比较简单,并没有考虑拟合的问题。实际上,神经网络的拟合能力很强并容易出现过拟合现象。与传统的“惩罚项”做法不同,目前神经网络(尤其是深度神经网络)中流行的防止过拟合的方法是随机地让部分神经网络节点休眠。
