磨浆过程输出纤维长度随机分布预测PDF 控制
2019-11-01李明杰周平
李明杰 周平
磨浆过程主要为后续造纸过程提供满足相应物理特性的纸浆纤维,同时也是保证纸品质量的前提.但由于磨机物理结构复杂性以及磨浆运行过程中受外界不确定因素的影响,导致纤维长度具有较强的随机分布特性,而传统的均值或者方差并不足以表征整个纤维长度随机分布(Fiber length stochastic distribution,FLSD)特征,即具有非高斯分布特性[1].而事实上,FLSD 形状作为衡量磨浆过程中最主要的生产指标之一,不仅影响到纸浆脱水效率和后续造纸过程的电耗,而且直接影响到整个制浆和造纸工业的能耗和最终的纸品质量[2−6].在这种情况下,就必须寻找一种能够对磨浆过程输出FLSD进行有效控制的方法.
虽然一些学者较早地意识到FLSD 在纸浆生产过程中的重要作用,但目前仍利用离线获得的纤维长度的均值和方差作为衡量纸浆纤维质量的生产指标[3−9].如文献[3−6]采用长纤维百分含量作为评价纸浆质量的工艺指标,而事实上,这种以统计纤维束长度的均值和方差并足以有效表征整个纤维长度的分布特征,甚至会导致FLSD 信息的缺失,这主要因为木片等富含纤维的纸浆原料经过盘磨机的横向挤压和纵向帚化后,虽然使得纤维束逐渐分解成单根纤维,然而,也导致纤维长度的分布形状具有很强的随机性和不确定性.此外,加之纤维长度分布在线检测仪器缺失,使得通过离线纤维长度的均值和方差来调整过程操作变量,其检测的滞后性难以使纸浆纤维质量稳定在工艺要求范围内,致使长纤维百分含量的控制大多过度依赖操作人员的经验,然而人工调整主观性较强,常常造成工况波动大,严重影响磨浆过程生产指标的稳定性.
另一方面,现有针对随机动态系统的最小方差控制、自校正控制、随机线性二次型控制,均假设系统服从高斯分布,主要集中针对过程输出随机变量的均值和方差进行建模和控制,然而,针对输出变量服从非高斯分布的有界动态随机系统,1996 年王宏教授提出了直接设计控制器以使输出PDF 形状跟踪期望PDF 形状的控制策略,并系统地提出了多种建模和控制方法[10−18].这类控制策略包含了传统以输出均值和方差为目的随机控制方法,具有更为广泛的应用.近些年,随机分布控制理论已成功应用于各类具有随机分布动态特性的工业过程,如造纸过程的絮凝粒径分布[10,12]、燃烧过程的火焰分布[18−19],聚合过程的分子量分布[20],铜粗选过程的泡沫尺寸分布[21]等,这些过程输出随机变量均不能满足高斯分布特征,并且具有较强的随机分布动态特性.
另外,在制浆和造纸工业领域,目前已有多种用于测量纸浆纤维各种形态参数的在线自动化检测和分析仪器,这些检测仪器常采用数码CCD 摄像机获取的纤维图像经数字化后传输到计算机系统进行处理,通过实时二维图像分析软件将每根纤维从图像信号中识别出来,逐一测量纤维的形态参数,能迅速准确地获得纤维形态参数是测量结果.如加拿大Optest 公司FQA-360、芬兰Kajaani 公司FS-300、丹麦Fiber-Visions 等[8−9],这些先进测量仪器为研究基于磨浆过程输出FLSD 的建模及控制提供了技术支撑.
磨浆过程输出FLSD 具有典型的非高斯分布动态特性,采用传统纤维长度的均值和方差难以有效描述其分布特征,本文根据随机分布相关控制理论[10],利用RBF 神经网络逼近输出FLSD 的PDF,为了改善传统线性权值模型[14−19]精度不高、泛化能力不强等问题,采用随机权神经网络(Random vector functional-link networks,RVFLNs)[22−24]建立表征输入变量和权值向量之间的非线性模型,基于磨浆过程输出FLSD 模型提出了一种预测PDF 控制方法,实现了对输出FLSD 形状的跟踪控制,基于工业数据实验表明了所提方法的有效性.
1 磨浆过程描述
典型的磨浆过程工艺流程如图1 所示,磨浆过程即是将植物原料经盘磨机反复研磨后,经汽浆分离后获得造纸所需的纸浆纤维.其主要包括喂料系统,供水系统,液压伺服系统和磨盘调速系统.当磨机运行时,首先将经过将被筛选木片在蒸煮仓里进行高温预处理,经清除杂质后的木片在螺旋喂料器作用下送入磨室.磨机作为磨浆过程中的核心设备,主要有定盘、动盘、电液伺服装置和主电机等组成.当预处理后木片和稀释水注入磨区后,利用电液伺服装置可以实时调节磨盘间隙,动盘在主电机带动下通过机械摩擦、剪切、撕裂、切割等作用,最终将预处理后木片分解为单根纤维.然后,纸浆通过送入旋风分离器实现汽浆分离,最终获得满足造纸过程所需的纸浆纤维.可以看出,由于工艺流程长及现场环境恶劣等原因,若操作变量调节不当,即便通过磨机的反复研磨,也难以获得满意的FLSD 形状,这样不但导致纸浆质量无法满足工艺要求,而且也极易造成原料浪费和过程能耗过大.
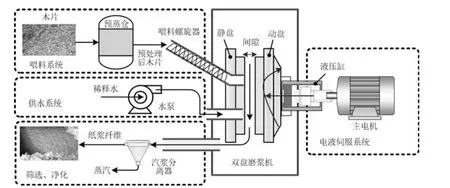
图1 典型磨浆过程工艺流程图Fig.1 Flowsheet of typical refining process
磨浆过程的主要操作变量包括磨盘间隙、稀释水流量、动盘转速和螺旋喂料量等.研究表明:长纤维百分含量作为衡量磨浆过程纤维长度均值的工艺指标,主要与注入磨区的稀释水流量和磨盘间隙密切相关[3,5−6],由于磨浆过程主要目的是对纤维进行切断、压溃、吸水膨胀,最终使纤维束分离为单根纤维,所以,磨盘间隙直接影响纸浆纤维被切断和压溃强度.同时,为使植物纤维能够较好地分离为单根纤维,需要让纤维获得足够的水份进行膨胀,纸浆纤维的吸水膨胀程度主要取决于注入磨区的稀释水流量.而植物纤维被切断、压溃强度以及吸水膨胀程度决定了最终获得的纤维长度随机分布形状.另外,结合实际工程经验,通常情况下分别通过改变喂料螺旋转速和供水泵转速来调节螺旋喂料量和稀释水流量,根据工程实践经验,当产量一定的情况下,动盘转速是固定不变的,螺旋喂料量也是恒定的.因此,稀释水流量和磨盘间隙不但可以看作影响长纤维百分含量的主要变量,同样也可以作为影响最终FLSD 形状的关键变量,对整个制浆生产流程都起着极为关键的作用.因此,本文将稀释水流量和磨盘间隙作为影响磨浆过程输出FLSD 形状的关键输入变量.
2 控制策略
根据有界动态随机分布控制相关理论[10]可知,随机分布系统模型主要由随机变量的PDF 输出部分和权值与输入变量之间的动态部分组成.为了表示输入变量和输出PDF 之间的动态关系,常引入一组基函数(如B 样条基函数[16−17,20−21]、RBF 基函数[15,18−19])来逼近输出随机变量的PDF,通过调节基函数的权值来控制输出PDF 形状,这样将随机分布系统的输出PDF 和输入变量之间的动态关系转化为权值向量和输入变量之间的动态关系,最终通过对相对应权值的控制实现对输出PDF 形状的动态调节.为此,本文针对磨浆过程输出FLSD 提出预测PDF 控制策略如图2 所示,具体如下:
1)首先,需寻找一组合适的RBF 基函数来逼近输出FLSD 的PDF.采用RBF 神经网络逼近输出PDF 的均方根,基于迭代学习方法实现RBF 基函数参数整定,并对实际输出PDF 相应权值向量进行估计.
2)其次,针对常规线性权值向量模型精度不高,泛化能力不强等缺点,本文基于随机权神经网络[22−24]方法建立输入变量和前n −1 个权值向量之间的非线性模型,进而获得磨浆过程输出FLSD模型.
3)最后,基于输出FLSD 模型设计预测PDF控制器,使得输出PDF 获得良好的目标跟踪能力.
3 纤维长度随机分布预测PDF 控制
3.1 随机分布系统模型
随着数据采集技术和检测仪器的快速发展,对随机变量的输出PDF 等已经有了较为成熟的检测方法.为了方便描述各种随机过程,假设z(k)∈[a,ζ]为描述动态随机系统输出的一致有界随机过程变量,u(k)∈Rm为k时刻控制随机系统分布形状的输入向量,这表明在任一采样时刻k,z(k)就可以通过其概率密度函数来描述,其定义式如下:

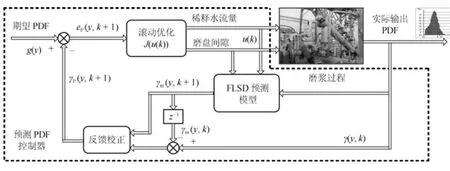
图2 输出纤维长度随机分布预测PDF 控制策略图Fig.2 Strategy diagram of the predictive PDF control for the output FLSD
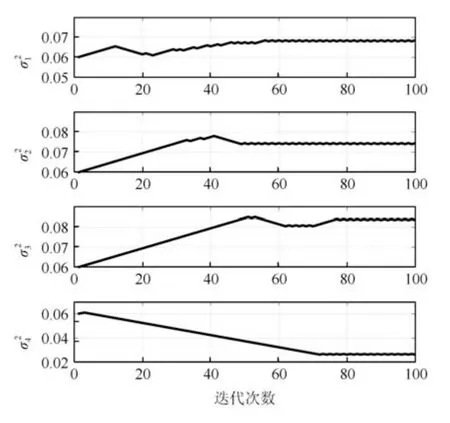
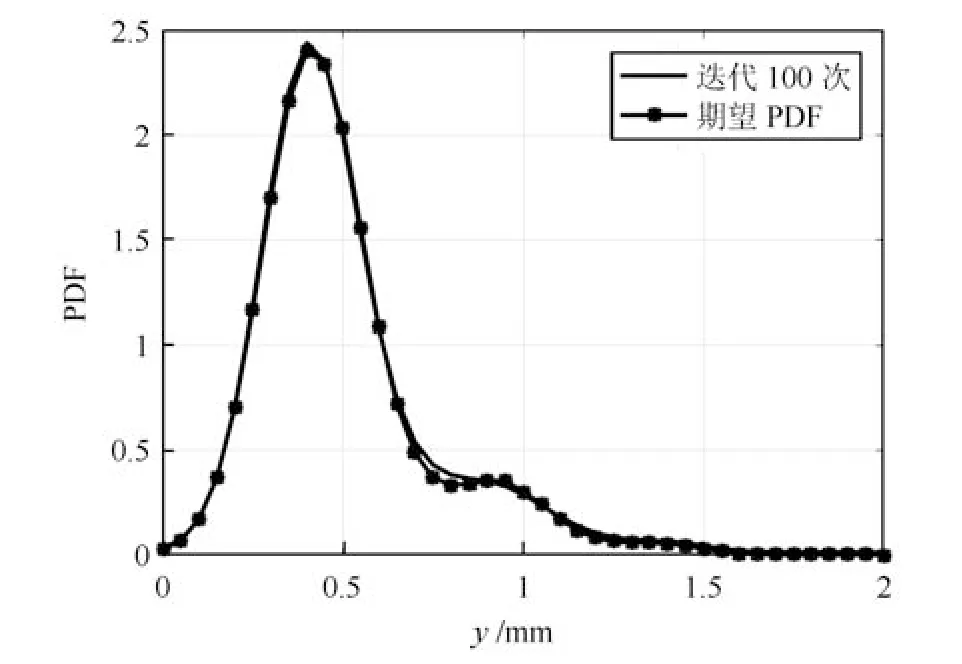
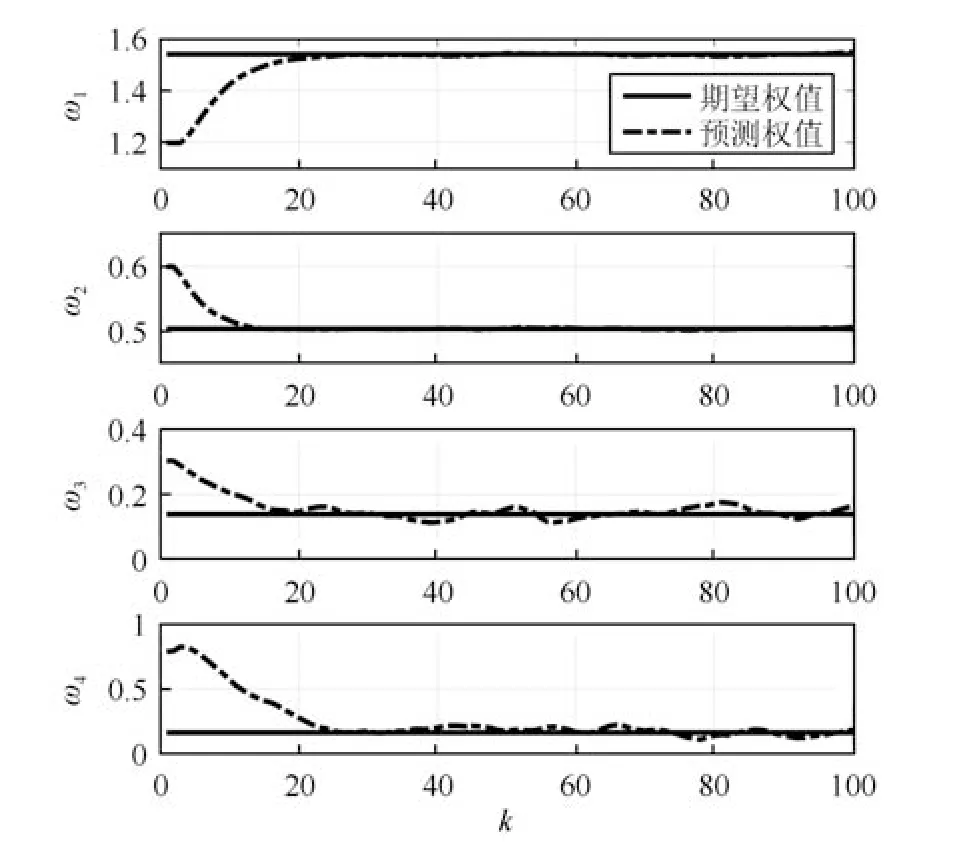
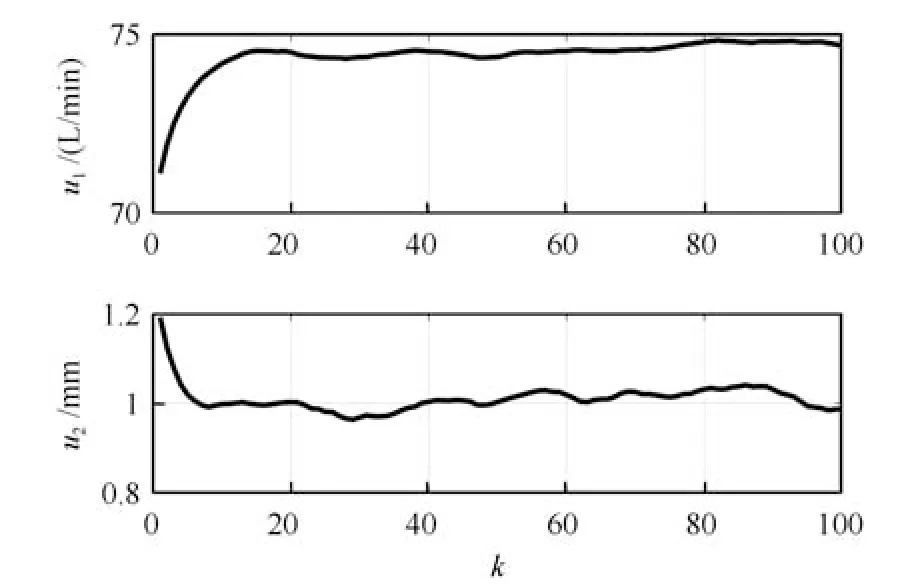
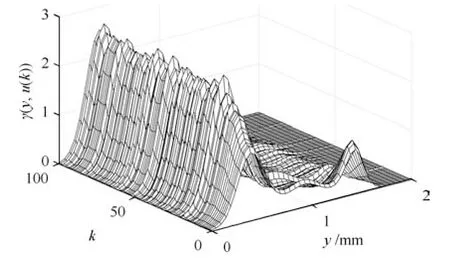
式中,P(a 式中,l表示第l个网络节点,n为网络节点总数,µl和σl分别表示第l个网络节点函数的中心值和宽度.根据RBF 神经网络逼近原理,此时输出PDFγ(y,u(k))的均方根可以表示为 式中,CCC(y)=[R1(y),R2(y),···,Rn−1(y)],VVV(k)=[ω1(k),ω2(k),···,ωn−1(k)]T,ωn(k)为第n个基函数相对应的权值,e0(y,k)为逼近误差.此外,由于输出PDF 需要满足隐含条件 为便于分析忽略逼近误差e0(y,k),则第n个权值ωn(k)可用权值向量VVV(k)的非线性函数h(VVV(k))表示为 从式(5)可以看出,若保证非线性函数h(VVV(k))存在,需满足如下约束条件: 当实际工业过程中输出随机变量的PDF 可测量时,可通过如式(7)∼(9)方法对相应的权值进行估计.结合式(3)和式(5)所示的输出PDF 的均方根可以表示为 对式(7)两边左乘[CCC(y)Rn(y)]T,并对两端在区间[a,b]上进行积分,由此可得到: 式(9)揭示了输出随机变量的PDF 与权值向量之间的关系,可以看出当RBF 基函数确定后,只要输出PDF 可测量,便可很容易获得相应的权值向量.通常情况下在获得相应的权值向量之后,采用最小二乘法或子空间辨识法获得权值和输入变量之间的线性动态模型[15,18−20].从式(9)可以看出,在RBF 基函数已知的情况下,若要获得理想的输出FLSD 模型.首先,需要对不同时刻实际输出PDF进行权值估计.其次,建立输入变量和权值向量之间动态模型.然而,由于实际工业过程高度非线性、机理复杂等原因存在,采用常规线性模型难以有效描述权值向量的动态特性.为此,必须采用有效手段,获取基于磨浆过程输出FLSD 模型,以实现FLSD形状的在线连续估计及控制. 另外,对于不能或者难以获得机理模型的复杂工业过程,基于数据驱动建模方法通常被看作一种非常有效的替代手段.目前,常见的数据驱动建模方法主要有支持向量机方法[25]、模糊推理方法[26]、案例推理方法[27]以及随机权神经网络方法[22]等.其中,随机权神经网络作为一种简单易用、有效的单隐层前馈神经网络学习算法,在保证逼近任意连续函数的前提下,采用随机给定神经元隐含层权值和偏置,通过计算隐含层输出矩阵的广义逆建立学习网络,克服了传统单隐层神经网络的缺点,由于训练速度快,模型结构简单、易于实现以及泛化能力强等鲜明特点,在很多领域获得广泛应用[23−24].本文利用随机权神经网络方法建立输出变量和前n −1 个权值向量之间非线性预测模型.因此,最终磨浆过程输出FLSD 模型可以表示为 式中,f(·)为表示过程输入和权值之间的非线性表达式,可以看出在控制输入和输出PDF 可测量情况下,同时在RBF 基函数已知时,在利用式(9)获得权值向量之后,通过随机权神经网络方法很容易获得输入变量和权值向量之间的非线性模型. 从式(10)明显发现要获得理想的输出FLSD模型,首先需要选择一组合适的RBF 基函数,若RBF 基函数的中心值和宽度选择不当,不但影响PDF 输出部分的近似精度,而且也难以获得满意的输出FLSD 模型.因此,RBF 基函数的选择对于磨浆过程输出FLSD 的模建模精度显得至关重要. 3.1.1 RBF 基函数参数整定 为了提高随机分布模型输出PDF 对实际输出PDF 逼近精度,文献[15]中提出了一种基于迭代学习控制原理的RBF 基函数参数更新算法,假设给出初始的RBF 基函数参数,结合实际输出PDF 数据,通过式(9)可以获得初始的权值向量,并将此初始向量乘以相应的初始RBF 基函数,便可获得近似的输出PDF.基于迭代学习控制原理,RBF 基函数的中心值和宽度要根据上一迭代学习周期的逼近误差来调节,通过对RBF 基函数参数的反复调节,最终使得将近似输出PDF 与实际输出PDF 之间误差最小.因此,所采用的性能指标主要考察近似输出PDF 跟踪期望的输出PDF 能力,所以所用误差来自迭代周期内的每一个采样点,采用如下性能指标 式中,Jp(i)可以表示为第p个迭代周期后第i个采样时刻RBF 神经网络近似输出PDF 的均方根与期望输出PDFg(y)的均方根之间的逼近性能指标.同时,定义在第p个迭代周期后M个采样点近似输出PDF 分别与期望输出PDF 之间构成性能指标向量可表示如下 为了实现式(10)所示的RBF 基函数参数整定,在相邻的第p次和第(p+1)次迭代学习周期内采用如下P 型迭代学习控制率 式中,学习参数αµ和βσ分别定义如下 其中,λ和分别为学习元素,参数ζµ和ζσ分别为迭代学习率.从式(13)看出所有元素均为非负,这表明迭代学习率可以为正数也可以为负数,这就意味着RBF 基函数的中心值和宽度随着迭代学习次数呈现出增加或者降低趋势. 3.1.2 基于RVFLNs 权值模型 从式(10)可以看出当前时刻输出PDF 不但与磨浆过程输入变量有关,同时与前一时刻的输出PDF 形状也密切相关,而输出PDF 通过调节RBF基函数中心值和宽度以及相应的权值,所以在获得理想RBF 基函数参数之后,通过式(9)可以获得所有时刻输出PDF 相对应权值向量,然而由于权值向量之间相互耦合,因此,权值向量模型可以看作是一个多输入多输出的回归建模问题.为此,采用基于RVFLNs[22−24]建立输入变量与前n −1 个权值向量之间的非线性模型. 假设分别有m个输入变量与权值向量组成的的样本集合 (ui,VVV i),其中ui=[ui1,ui2,···,uim]T∈Rm为磨浆过程的输入变量,VVV i=[ωi1,ωi2,···,ωi(n−1)]T∈Rn−1表示n个权值中的前n −1 个权值向量.对于一个有L个隐层节点,若以g(x)作为激活函数的RVFLNs 输出可以表示为 式-中,ui为-磨-浆-过-程-的-输-入-变-量,ωj=[ωj1,ωj2,···,ωjm]T为m个输入节点连接第j个隐含层的输入权重,βj=[βj1,βj2,···,βj(n−1)]T为第j个隐含层连接输出节点的输出权重,bj是第j个隐层单元的偏置,ωj ·uj表示ωj和ui的内积. 随机权神经网络和其他单隐层神经网络学习目标一样均是使得模型输出fR(ui)与实际输出VVV i之间误差最小,即有当存在βj,ωj和bj,使得 此时,将式(15)可以矩阵表示为 式中,H为隐含层输出矩阵,β为输出权重,Y为预测模型的权值输出.且有 从式(16)可以看出,当输入权重ωj和隐层偏置bj被随机确定后,只需调整输出层权值就可以使网络具有较好的逼近性能.为了能够较好地训练上述网络,希望获得最优的输出权重,使得 此时随机权神经网络的学习问题就转化为式(16)所示的线性系统Hβ=Y的最小二乘求解问题,为此隐层输出矩阵H就能被唯一确定,此时可以获得输出权重β可以表示为 式中,H†是矩阵H的Moore-Penrose 广义逆.可以看出此算法只需要设置网络的隐层节点个数,便可以随机初始化输入权重和偏置并得到相应的输出权重.所以该算法在执行过程中不需要调整网络的输入权值以及隐元的偏置,便可以获得唯一的最优解. 为了更好地反映磨浆过程输出FLSD 动态特性,将当前采样时刻输入变量u(k)=[u1(k),u2(k),···,um(k)],m为输出变量个数以及当前时刻相对应的权值向量VVV(k)作为非线性模型综合输入,即建立的权值动态预测模型用于实现如下的非线性动态映射关系: 式中,VVVm(k+1)为模型输出的前n−1 个权值向量.此时,在第k时刻预测输出PDF 为 由于实际工业过程中非线性、时变、模型失配和随机扰动等不确定性因素的存在,模型输出PDF难以与实际输出PDF 完全一致,然而在滚动优化过程中,需要实际输出PDF 与模型输出PDF 保持一致,因此,通常采用反馈校正来降低过程的不确定性对系统性能的影响,提高系统的控制精度和鲁棒性.假设模型在k时刻第j步预测输出PDF 为 另外,在第k时刻实际输出PDF 和预测输出PDF 之间的误差为 利用该误差对第j步预测输出 PDF进行反馈修正,补偿后预测输出PDF 为 式中,βj(0<βj <1)为校正系数.此时结合式(21)∼(23)在k时刻第j步期望输出PDF 和补偿后的预测输出PDF 之间误差为 式中,γg(y,k+j)和γp(y,k+j)分别为k时刻第j步的期望输出PDF 和预测输出PDF. 此外,预测控制作为一种优化控制算法,常通过最小化系统的性能指标函数来确定未来的最优控制序列,使得未来预测输出尽可能接近期望的目标输出.在实际工业过程中,为了保证操作的可行性等要求,普遍存在着输入变量带约束的情形,同时对控制作用的大小加以约束,避免控制作用变化过于剧烈.本文设计预测PDF 控制器目的是尽可能地使输出PDF 尽可能跟踪期望输出PDF,所以选取如下所示性能指标函数 式中,Np和Nu分别为预测时域和控制时域,λj为控制增量加权系数,umax和umin分别为输入变量的上限和下限值,∆umax和∆umin分别为输入变量变化率的上限和下限值.可以看出对输出PDF 跟踪控制最终转化为对前n −1 个权值跟踪控制. 从式(25)明显可以看出上述预测PDF 控制器的设计可以看作是一个带有约束条件的非线性优化求解问题.针对上述求解问题通常采用遗传算法、粒子群算法、序列二次规划算法(Sequence quadratic program,SQP)等优化算法获得非线性最优预测控制率,其中,SQP 算法作为一种求解约束非线性优化问题的有效方法之一,具有收敛性快、计算效率高、边界搜索能力强,在实际中受到广泛重视和应用.本文采用SQP 方法求解式(25)所示的带约束的非线性规划问题设计预测PDF 控制器,使得磨浆过程输出PDF 具有良好的目标跟踪能力. 本文利用某化机浆磨浆过程的稀释水流量、磨盘间隙以及FLSD PDF 生产数据对所提方法进行数据验证,具体如下: 为了获得磨浆过程输出FLSD 模型,首先,需要确定一组合适的RBF 基函数近似输出PDF,采用基于迭代学习方法研究RBF 神经网络对期望输出PDF 的逼近效果,并将得到RBF 基函数作为本批次近似输出PDF 的基函数,此外,通过大量FLSD 的PDF 数据分析获得期望输出PDF,本文选择4 个RBF 基函数来验证对期望输出PDF 的近似效果,这里中心值和宽度参数迭代学习率分别为αµ=0.01,βσ=0.005,另外,假设中心值和宽度的初始值如下所示 基于式(26)所示的初始RBF 基函数,首先,可以通过式(9)获得期望输出PDF 权值估计,然后利用得到的估计权值与初始RBF 基函数相乘便得到对应的逼近值,以此利用迭代学习方法通过调整中心值和宽度,直到获得理想的逼近效果.经过100 次迭代学习后,获得中心值和宽度分别为 图3 位置变化趋势Fig.3 Variation tendency of position 图4 性能指标变化趋势Fig.4 Variation tendency of the performance index 另外,图3 为在迭代学习50 次和100 次后的RBF 基函数位置变化趋势图,可以看出随着迭代次数的增加,中心值和宽度逐渐向理想位置移动.图4 为性能指标函数值随迭代学习次数的变化趋势,可以看出随着迭代次数的增加,目标性能函数逐渐减小,并在迭代学习80 次时基本不再变化.中心值和宽度随迭代次数变化趋势分别如图5 和图6 所示,从图5 和图6 看出在迭代学习100 次后,中心值和宽度均趋于平稳.图7 为在迭代学习100次后,近似输出PDF 与期望输出PDF 的逼近结果,可以看出本文方法对输出PDF 具有满意的逼近效果.同时,利用式(9)对期望输出PDF 数据进行权值估计,此时获得相对应的期望权值为VVVg=[1.5411 0.5080 0.141 0.166]T. 图5 中心值变化趋势Fig.5 Variation tendency of the center value 图6 宽度变化趋势Fig.6 Variation tendency of width 在完成RBF 基函数参数整定同时利用式(4)对不同时刻输出PDF 进行权值估计,然后利用RVFLNs 方法建立前三组权值的非线性预测模型,利用稀释水流量、磨盘间隙和输出PDF 数据,采用所提方法建立磨浆过程输出FLSD 模型,并基于SQP 算法优化式(25)设计预测PDF 控制器. 图7 输出PDF 近似效果Fig.7 Approximation effect of the output PDF 本文取预测时域Np=3,控制时域Nu=2,控制增量加权系数λj=0.05,反馈校正系数βj=0.55.另外,根据实际操作经验,输入变量稀释水流量(u1)和磨盘间隙(u2)分别满足70 L/min 图8 预测PDF 控制器下权值响应Fig.8 Weight response with the predictive PDF controller 图8 和图9 分别在预测PDF 控制器下预测权值输出响应曲线、控制输入的动态响应,从图8 可以看出预测权值输出能够实现对期望权值的跟踪,但权值动态模型由于非线性存在,在一定程度上影响到预测权值输出对期望权值跟踪控制性能.此外,图9 所示输入变量稀释水流量和磨盘间隙均能较好地稳定在可操作区间内.图10 和图11 分别为输出FLSD 的PDF3D 图以及初始时刻、目标、最终时刻输出PDF,从图10 和图11 明显能够看出在预测PDF 控制器作用下,实际输出PDF 从初始输出PDF 形状具有很明显逼近期望输出PDF 趋势,并最终实现对输出PDF 跟踪控制. 图9 预测PDF 控制器下控制输入Fig.9 Control input with the predictive PDF controller 图10 预测PDF 控制器下输出PDF 3D 响应Fig.10 3D responses of the output PDF with the predictive PDF controller 图11 初始PDF、最终PDF 和期望PDFFig.11 Initial PDF,final PDF,and desired PDF 本文从当前磨浆过程实际控制问题出发,针对具有典型非高斯分布特征的输出FLSD 形状提出了一种预测PDF 控制方法.采用迭代学习方法获得理想的RBF 基函数基础上对不同时刻输出PDF 相对应的权值进行估计,针对权值之间强耦合、非线性强等特点,采用RVFLNs 建立表征输出变量和权值向量之间关系的预测模型,最终将输出PDF 的控制转化为对权值向量的控制,基于工业数据实验结果表明了所提方法的有效性.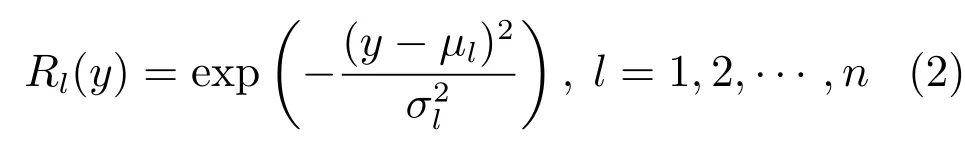
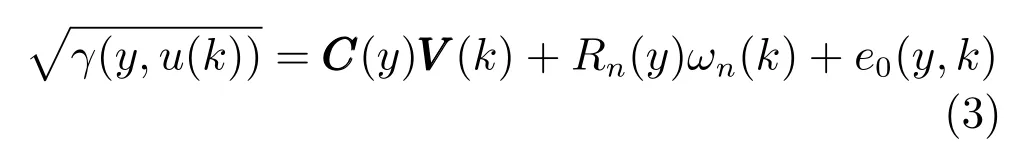
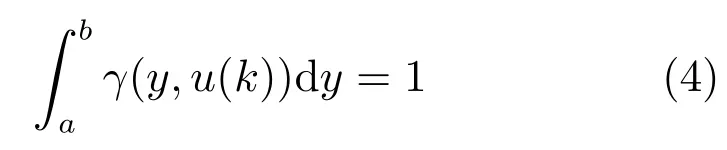
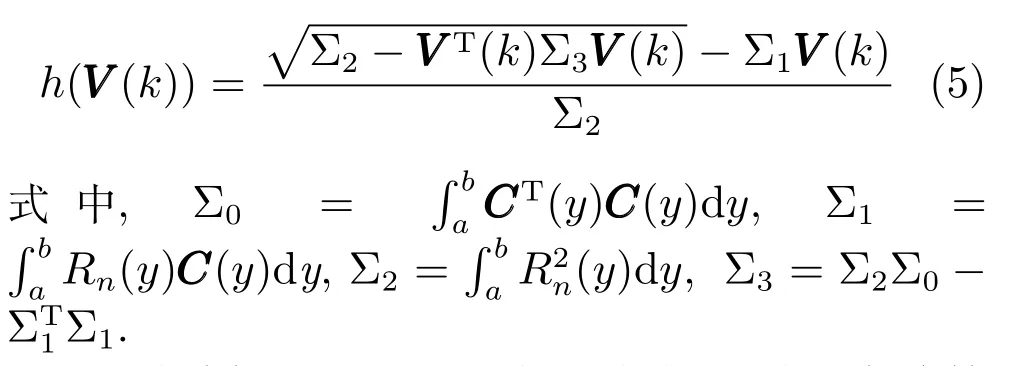
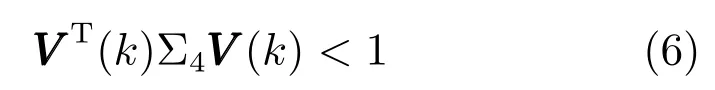
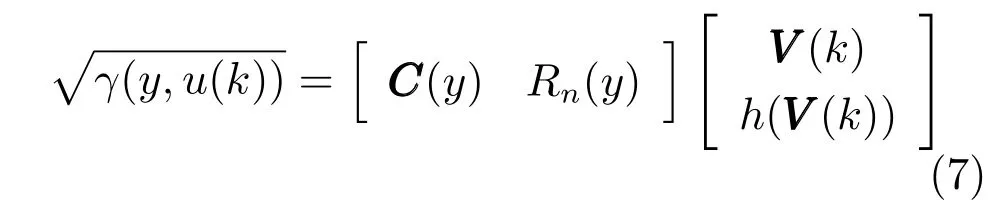


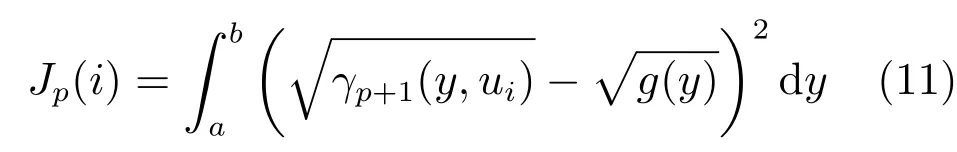

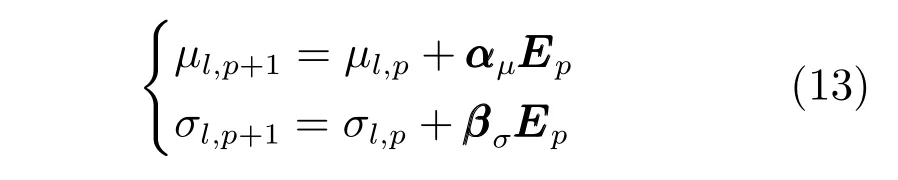


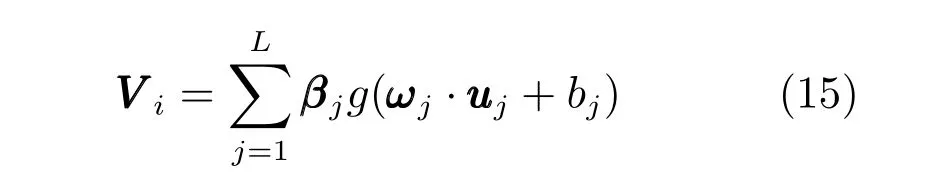

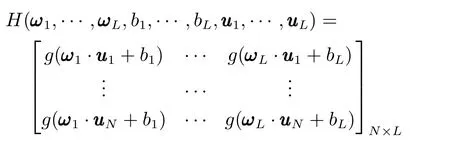
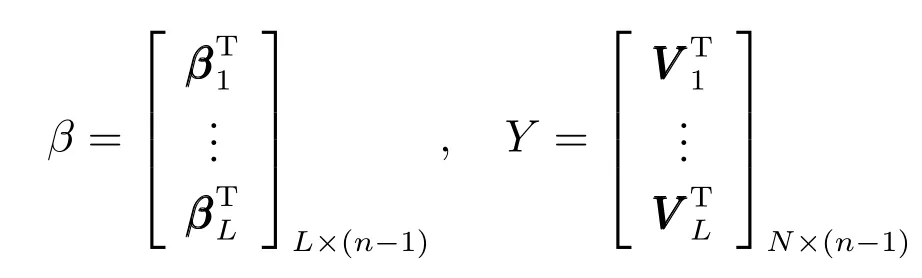
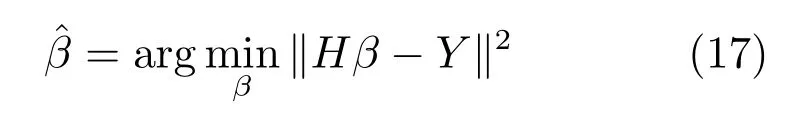



3.2 预测PDF 控制
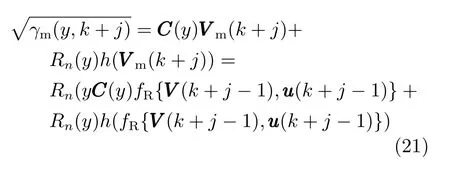


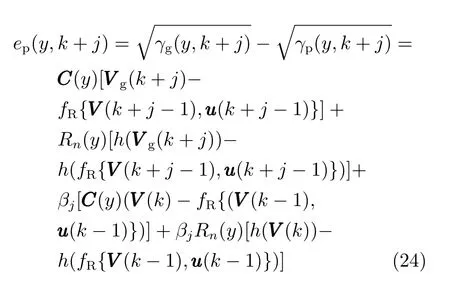

4 工业数据验证
4.1 RBF 基函数参数整定





4.2 预测PDF 控制效果

5 结论
