设立国家级贫困县能提升当地农民收入水平吗
2019-10-30李泉鲁科技李梦
李泉 鲁科技 李梦


摘 要:中国自1986年实施贫困县制度以来,国家级贫困县的设立是否能够以及在多大程度上提升了当地农民实际收入水平,需要进行系统科学的实证检验。基于双重差分倾向得分匹配法(PSM-DID),利用2007~2016年全国6个省份296个县的面板数据进行实证研究发现,国家级贫困县的设立非但没能有效提升当地农民实际收入水平,反而对其有持续的负效应。进一步研究发现,贫困地区第二、三产业的发展能够有效提高当地农民实际收入水平,然而贫困县政策并未促进当地产业结构的优化;政府通过正向干预农产品价格能有效增加农民实际收入。从研究结论的政策含义讲,立足贫困户推进精准扶贫、通过招商引资带动有效投资,以及优化县域产业结构,对于提升贫困县的农民收入具有重要现实意义。
关键词:
国家级贫困县;双重差分;倾向得分匹配法;农民实际收入
文章编号:2095-5960(2019)05-0078-13;中图分类号:F406;文献标识码:A
一、引言
进入21世纪以来,减少和消除贫困、缩小收入差距依然是各国政府亟待解决的热点问题。Fosu(2010)的研究认为,收入分配在减贫方面发挥的作用比传统上公认的更为重要,尽管这一重要性在不同地区和国家之间存在很大的时空差异。[1]因此,是否能够真正促进国民收入分配更加合理化,就成为各国政府评价反贫政策实施效果的关键问题。习近平总书记在党的十九大报告中指出,十八大以来我国脱贫攻坚战取得了决定性进展,全国共有六千多万贫困人口脱贫,贫困发生率从10.2%下降到4%以下;必须确保到2020年贫困县全部摘帽并实现全面脱贫,解决区域性整体贫困问题。[2]事实上,中国政府自改革开放以来相继出台了一系列事关扶贫攻坚的政策举措。其中,国家扶贫工作重点县(又称国家级贫困县,以下简称贫困县)政策是由国务院扶贫开发领导小组办公室(以下简称扶贫办)根据各县(包括县级行政单位区、旗、县级市)贫困人口数量、农民收入水平以及农民基本生产生活条件,并适当参考人均GDP、人均财政收入等各项综合指标选取全国部分县作为贫困县,并对其进行适当财政支持及政策倾斜,以帮助各贫困县顺利实现脱贫的制度安排。该政策自1980年代中期实施以来,结合国民经济社会发展规划历经多次修改完善,在国家级贫困县的认定、贫困县标准等方面也相应进行了不断调整。在这里,我们的问题是贫困县政策设计在过去的十余年里是否真正起到了减少贫困、提升农民收入水平的作用呢?对于正在实践中的精准扶贫、精准脱贫来说,有哪些值得推广的经验或需要进一步优化的地方呢?借鉴由Heckman et al.(1997,1998)提出的双重差分倾向得分匹配法(Propensity Score Matching-Difference in Difference,PSM-DID)[3,4],本文选取2007~2016年全国6个省份296个县的面板数据进行实证研究,旨在集中回答以下三个问题:(1)贫困县的设立是否有利于增加农民收入?(2)贫困县的设立对农民收入的影响是否具有持续作用?(3)贫困县的设立是通过哪些机制对农民收入产生影响的?
二、文献综述
贫困始终是困扰人类社会发展的重大课题,消除贫困是全世界长期以来面临的重要难点障碍。实践表明,在人类经济社会发展的不同阶段,不同阶层和社会群体立足相异的思想价值体系和判断标准,对不同社会经济制度中存在的诸多贫困问题给予了不同的理解和阐释。当前,中国已经进入脱贫攻坚的最后冲刺阶段,重点围绕“三区三州”(具体指西藏、四省藏区、南疆四地州和四川凉山州、云南怒江州、甘肃临夏州)深度贫困地区,瞄准贫困县、贫困村和贫困户进行精准施策,仍然是现阶段最为重要的扶贫行为选择。系统梳理和认真检视已有的文献成果不难发现,国内关于贫困县设立的政策绩效及其贫困县政策对于当地农民增收影响的代表性文献并不多。但是,與本文研究主题相关且颇具参考价值的成果,按其研究内容大致可以分为三类:
第一类是与设立贫困县相关的其他扶贫政策变量的效果研究。其中,陈全功、程蹊(2006)认为教育是消除长期贫困的重要工具,然而由于贫困县的教育资金投入不足以及教育不公平现象仍然严重,导致教育减贫的作用正在减弱,甚至无法更好发挥。[5]在国家扶贫开发重点县投入绩效的实证分析方面,以帅传敏等人(2008)为代表的研究认为,中国国内扶贫资金使用效率低于外资扶贫资金使用效率,中央政府扶贫资金中的财政扶贫资金、以工代赈资金、贴息扶贫贷款等的使用效率依次下降。[6]赵曦等(2009)从中国扶贫资金投入成本、收益及其变动趋势的角度,揭示了剩余贫困人口减贫速度有所减缓、脱贫成本不断增加、扶贫成效也在逐渐降低的现状,从而说明之前的扶贫资金管理方式存在诸多问题。[7]张金梅、邓谨(2011)通过问卷调查和访谈相结合的方式研究发现,尽管惠农政策在实施过程中仍存在诸多阻滞因素,但惠农政策宣传基本到位,农民对政策实施的总体满意度高,农户的生产生活条件也得到较大改善。[8]张伟宾、汪三贵(2013)则认为,农村扶贫政策从缓解脆弱性、生产能力和市场参与等角度增加了贫困地区农民分享当地经济增长成果的机会,但扶贫政策在实施过程中仍存在瞄准偏差的问题,未来需在加大扶贫资金投入的同时提高贫困地区扶贫资金的瞄准效率。[9]
第二类是关于扶贫政策在不同县域的产出问题研究。例如,姜爱华(2008)通过政府开发式扶贫资金投放效果的研究认为,农村非农就业的增加有利于减少农村贫困,非农业化是农业扶贫的出路。[10]张彬斌(2013)基于重点县扶贫的人力资本形成效应研究表明,一个县的初期经济发展水平是国定扶贫重点县主要依据,并且是否为革命老区、少数民族聚居区也是重要参考;国定扶贫重点县农民收入会受到新时期扶贫政策的干预,但这种干预效应的大小会由于初期收入水平的不同而存在差异。[11]张彬斌、陈小利(2015)的研究则认为,贫困县政策对将平均受教育年限和在校学生数作为衡量标准的人力资本形成具有显著效应,而对以生师数量比为代表的教育质量影响却不明显。[12]除此之外,由于对贫困县扶贫政策效果存在诸多争议,以郑家喜、江帆(2016)为代表的学者基于中国1992个县1999~2010年面板数据的研究发现,国家扶贫开发重点县政策并未有效推动县域GDP及其人均GDP的快速增长,对缩小区域差距作用也不显著,重点县扶贫开发政策出现“失灵”[13]。然而,黄志平(2018)的研究结果却表明,贫困县的设立通过优化当地产业结构和提高固定资产投资水平,会对当地经济产生持续显著的推动作用,且这种推动作用随着时间的持续越来越明显。[14]
第三类是关于国家级贫困县政策与农民收入关系的研究。例如,张彬斌(2013)关于新时期政策扶贫的目标选择和农民增收问题研究认为,扶贫政策对新设立的贫困县农民产生增收效应,但在整体水平上农民人均纯收入受扶贫政策的冲击并不明显。[15]王小华等人(2014)通过对农户信贷减贫增收效应在贫困县与非贫困县的分层比较研究发现,相较于非贫困县,贫困县农户信贷并未能显著推动农民收入增长;另外,财政支出仅对非贫困县的中高收入及最高收入组的农民增收有积极正向影响,但对其他收入层次以及贫困县的农民增收具有显著的负向效应。[16]叶慧(2015)则在生计资本框架下对影响少数民族贫困县农民收入的因素进行分析,发现公共财政政策对农民增收的影响并不显著。[17]周敏慧、陶然(2016)的研究则发现,虽然在“八七扶贫”期间国定贫困县获得了较多的转移支付,但在与初始经济发展水平相类似的非贫困县对比后,其农民人均纯收入增长率并没有得到显著性地提高。[18]康江江等人(2017)的研究表明2000~2014年期间集中连片特困地区农村居民绝对收入差距呈现逐渐扩大的趋势且不同片区之间的差距尤为明显,而相对收入差距逐渐缩小。[19]王守坤(2018)的研究认为,国家级贫困县相较于地理发展条件相似的非国家级贫困县,具有更大的城乡收入差距,及更高的农村人口比例和农村固定资产投资完成额比例。这意味着在各类扶持优惠政策或财政资金支持影响下,凭借国家级贫困县身份能够获得更多的经济资源配置。[20]方迎风(2019)通过对国家级贫困县经济增长与减贫效应进行实证研究发现,在上级政府财政大力支持下,扶贫重点县比非贫困县的县域经济增长和农民收入增长都要更快,这表明扶贫重点县政策在促进落后地区经济发展和减贫方面依然起着较强的推动作用。[21]
通过以上三类的文献成果综述容易发现,贫困问题是基于不同类型的自然地理禀赋、文化历史传统、非正式制度约束和经济结构而存在的与历史道德因素紧密相连的概念和范畴。在不同县域的不同发展阶段,必然会存在不同的贫困群体、不同的贫困表现形式和差异化的应对途径、制度设计体系等,进而理论研究成果对于贫困问题的分析也就必然存在较大差异。虽然国内涉及贫困县、贫困地区农民增收和减贫政策效应等方面的文献较多,但很多研究都是关于贫困县扶贫政策对地区总体经济状况的影响效应,较少有文献直接聚焦贫困县制度设计对当地农民收入的影响效应研究。特别地,当前各地精准扶贫精准脱贫战略实施的核心对象主要是收入水平较低的农民,因此基于PSM-DID方法研究贫困县的设立对农民收入水平的影响效应究竟如何,这对脱贫攻坚的如期实现和扶贫政策在2020年之后是否需要适当调整,无疑具有重要的理论价值和现实意义。
三、理论框架
改革开放40年来中国大力推进扶贫开发,1986年国务院成立扶贫开发领导小组,各地方政府也相继成立相应机构负责本地区扶贫工作。同年实施的贫困县制度标志着中国扶贫思路从以往“人口瞄准”转向“区域瞄准”。隨着《国家“八七”扶贫攻坚计划》及《中国农村扶贫开发纲要》的逐步落地实施,中国在减贫方面取得了巨大成就,贫困率持续快速下降。然而,在许多方面减贫任务仍在继续,并且变得更加艰巨。[22]值得注意的是,自改革开放以来中国收入不平等迅速增加,收入差距持续扩大,进而在一定程度上阻碍了减贫进程。因此,需要更加合理的收入分配及再分配政策缩小收入差距。[23][24]从对农民实际收入的影响效应来看,贫困县的设立既可能对农民收入水平有提升作用,也可能对其没有影响甚至有负向影响。
对于可能会提升农民收入水平的情况而言,被认定为贫困县后能享受到中央及地方政府的财税支持、投资倾斜、金融服务、产业扶持及其他相应扶贫政策。[25]其中,财税支持通过加大中央及地方政府财政对当地一般性转移支付力度,对国家鼓励的内外投资优势产业项目给予税收优惠,吸引区外及外资企业来此投资兴业带动当地经济发展。投资倾斜通过加大对当地基础设施建设、民生工程及生态环境等的投入力度,改善当地农民的生产生活条件,同时也能给当地农民创造就业机会。金融服务主要通过实施扶贫贴息贷款政策,积极推动扶贫地区金融产品创新,并引导民间借贷规范发展,从而满足扶贫地区发展生产的资金需求。产业扶持要求国家新兴产业、大型项目及重点工程优先向贫困地区布局,同时引导劳动密集型产业向扶贫地区转移以带动当地农民就业。以上举措均能有效促进当地经济发展。然而,如果收入分配不合理,会形成进一步扩大收入差距的恶性循环,从而导致农民实际收入减少。而及时有效的收入分配及再分配政策是消除由于收入差距扩大进而阻碍减贫进程的有效方法之一。不仅如此,开发式扶贫政策也能通过将扶贫项目直接落户到扶贫对象,提高农民分享发展成果的能力和机会。[9]至于对农民收入水平可能不会产生影响甚至有负效应的情况,则是由于设定贫困县的政策在制定与实施过程中会遇到一系列制约因素,比如扶贫立法缺失、政策瞄准偏差、考核目标单一、政策依赖性以及其他非正式约束。[13]作为一项周期长、难度大的系统性工程,扶贫攻坚必须有规范健全的立法作为保障,但是由于目前扶贫立法缺失无法使扶贫工作走上法制化轨道,因此在扶贫实践中容易产生寻租现象和滋生腐败。同时,政策瞄准偏差也是扶贫政策可能失效的一个重要原因,贫困县政策瞄准的目标往往是县域整体经济发展水平,而这又会在很大程度上忽略处于深度贫困的贫困村及贫困户。另外,对扶贫对象直接进行政策性补贴,也会使他们形成一定程度的政策依赖性,长期而言会导致补贴效应降低甚至无效。基于以上理论,本文构建如图1所示的理论分析框架和作用机制。
四、研究方法、指标选取及数据来源
(一)研究方法
本文所研究的核心问题是贫困县的设立是否有利于提升农民收入水平。由于贫困县的设立并不能视为一个严格的外生事件,因此只能将该项政策视为一个“准实验”[26],通过研究贫困县(实验组)和非贫困县(控制组)农民收入的变化来估计贫困县政策效应。在此过程中,我们可能会遇到两个问题:(1)实验组与控制组的样本选择可能是非随机的,从而造成样本选择性偏误;(2)实验组与控制组样本之间的经济发展差异可能是由不可观测或不随时间变化的因素导致的,因此可能会产生异质性偏差。为了消除以上两个问题可能给估计结果造成的偏误,此处首先采用由Rosenbaum and Rubin(1983)提出的倾向得分匹配法,将实验组中样本与其经济发展状况类似的控制组中的样本进行匹配,以消除样本选择性偏误。[27]然而,倾向得分匹配法依然有其不足之处,该方法在计算样本的倾向得分时必须依赖可观测的变量,从而潜在地假定了那些不可观测的因素不会对各县是否被选为贫困县产生系统性影响,从而仅仅使用倾向得分匹配模型可能会得出有偏的政策平均处理效应。[28]因此,需再将倾向得分匹配法与由Ashenfelter(1978)提出的双重差分模型[29]结合起来估计贫困县的设立对农民收入的真实效应,以消除样本选择性偏误、样本之间不可观测的个体异质性差异或不随时间变化的因素对政策平均处理效应造成的影响,从而使估计结果更加真实有效。
1.双重差分法(DID)。本文中贫困县的设立作为一个外生性的政策冲击将样本县分为两组——贫困县(实验组)和非贫困县(控制组),如果设立贫困县的政策实施之前实验组与控制组中样本县的各项经济指标没有显著差异,便可以把控制组在政策实施前后农民收入的变化看作实验组未受政策冲击时的反事实结果。根据以上原理便得设立贫困县对农村居民人均可支配收入变化的平均处理效应:
其中,E表示期望值,D表示是否设立贫困县的虚拟变量(D=1为实验组,D=0为控制组),YT 0、YT1分别表示设立贫困县前后实验组农民收入水平状况值,YC0、YC1分别表示设立贫困县前后控制组农民收入水平状况值。等号右边两项分别表示实验组与控制组在设立贫困县前后的一阶差分值,能够有效消除实验组与控制组自身的发展趋势,两组之间再次求差分后便得到了设立贫困县对农民收入的变化所产生的政策效应。
2.倾向得分匹配法(PSM)。倾向得分匹配法的步骤如下:①选择样本县的协变量X,为确保满足可忽略性假设,应尽可能将影响(YC1,YT1)与D的相关变量包括进来,否则将引起偏差。②使用样本县的协变量X估计出该县是否被选为贫困县的概率值(或称倾向得分值)P(X),一般可使用参数估计法(比如,probit模型或logit模型)或非参数估计法,而最流行的方法是logit模型。③进行倾向得分匹配,将实验组和控制组在满足共同支撑假设的条件下采用不同的倾向得分匹配方法进行匹配,用匹配成功后的非贫困县作为贫困县的反事实结果。匹配后样本满足条件独立分布假设,即匹配后的贫困县和非贫困县的选取是随机的。
3.双重差分倾向得分匹配法(PSM-DID)。通过以上两种方法可知,将倾向得分匹配法与双重差分法结合起来能够结合两种方法各自的优点,有效地消除样本选择性偏误、样本之间不可观测的个体异质性差异或不随时间变化的因素对政策平均处理效应造成的影响,从而使估计出的平均处理效应更加真实有效。由双重差分倾向得分匹配法计算设立贫困县对农民收入变化的平均处理效应如下:
ATTPSM-DID=E(YT1-YT0X0,D=1)-E(YC1-YC0X0,D=0) (2)
其中,X0表示设立贫困县前的协变量,其他变量与(1)式中相同。
(二)指标选取
1.被解释变量。本文利用农民实际人均可支配收入(perinc)及农民实际总可支配收入(inc)的对数值作为衡量农民收入水平的指标。考虑到通货膨胀因素,利用对应省份历年农村CPI(CPI2007=100)转化为农民实际人均可支配收入及地区农民实际总收入再取对数。
2.核心解释变量。treat·post作为核心解释变量,表示是否设立贫困县。其中,treat表示政策虚拟变量,2012年3月新调入的贫困县treat=1,否则treat=0。post表示政策实施时间的虚拟变量,2012年及以后年份post=1,否则post=0。则交乘项treat·post的系数估计值即为贫困县的设立对农民收入水平影响的净效应。
3.控制变量。除了政策虚拟变量以外,还有其他一些经济指标会对农民实际收入水平产生影响,为了排除这些变量的影响,本文选取其中较为重要的8个变量作为控制变量。其中,lnperg表示地区实际人均GDP的对数值,该值利用各省份GDP指数将地区GDP转化为实际GDP再除以地区年末总人口最后取对数而得到;用乡村从业人员数与年末总人口之比来表示乡村从业人员比重(emp);用地区公共财政预算收入、公共财政预算支出、农产品总产值、第二产业增加值及第三产业增加值与地区GDP之比分别表示地区公共财政预算收入比重(rev)、公共财政预算支出比重(fis)、农产品总产值比重(pro)、第二产业增加值比重(sec)及第三产业增加值比重(ter);农产品相对价格(pri)用各省农产品生产价格指数与工业生产者出厂价格指数之比表示。
除了取对数的数据及政策虚拟变量外的其他变量均采用比值形式,以减小异方差的影响。另外,以上选取的控制变量(协变量)不仅是被选为贫困县的关键指标,同时也是决定农民收入的主要指标。因此,协变量的选择满足可忽略性假设。各变量的计算方法见表1。
(三)数据来源
本文所利用的2007~2016年平衡面板数据主要来自历年《中国统计年鉴》《中国区域经济统计年鉴》EPS数据库及中经网统计数据库,其他少数缺失数据来自各省、市统计年鉴。鉴于各数据库中指标的完整性及数据的可得性,此处主要选取河北、内蒙古、安徽、海南、山西及贵州6个省(自治区)296个县的样本数据。由于2012年國务院扶贫办对贫困县名单进行了调整,本文将2012年作为外部政策冲击时点,选取其中23个新调入的贫困县作为实验组,剩余的273个县(2012年前后都是非贫困县)作为控制组。考虑到如果实验组样本的数量远少于控制组,那么选择最近相邻法进行匹配能得到更好的匹配效果。[30]因此,本文采用倾向得分匹配法中的一对一无放回匹配方式给实验组中的23个贫困县匹配控制组中的非贫困县,再利用双重差分法估计出设立贫困县对农民收入的影响。各变量的描述性统计见表2。
五、结合PSM-DID方法估计设立贫困县效应
这一部分将结合PSM-DID方法估计设立贫困县对当地农民收入的平均处理效应。具体步骤如下:①使用logit模型及2007~2011年样本县的协变量的平均值(X估计出该县被选为贫困县的概率值P((X ),并根据概率值P((X )采用一对一无放回的匹配方式给实验组中的23个贫困县匹配控制组中的非贫困县;②对①中的样本匹配质量进行检验,包括平衡性检验和共同支撑检验;③根据以上匹配好的样本数据利用DID方法估计设立贫困县对当地农民收入的平均及动态处理效应;④对结果进行稳健性检验;⑤对影响机制进行检验。
(一)利用PSM方法将贫困县与非贫困县进行匹配
本文利用2012年扶贫办对贫困县进行重新调整之前的2007~2011年296个县的面板数据,构建如下logit模型预测被确定为贫困县的概率值Pr(X),并据此将贫困县与非贫困县进行匹配。
其中,treati为设立贫困县的政策虚拟变量。在该模型中,2012年新调入的贫困县treati=1,否则为treati=0;xk=15∑2011t=2007xtk(k=1,…,8)表示2007~2011年样本县的一系列协变量的平均值。
利用logit模型得到的回归结果如表3所示。从表3中各个协变量回归系数的p值可知,其中四个协变量对该县是否被确定为贫困县具有显著的影响;其中pseudo R2值为0.554,这说明模型的整体拟合度较高。
(二)样本匹配质量检验
1.平衡性檢验
在利用PSM方法将贫困县与非贫困县进行匹配后,需要进行平衡性检验,即检验实验组和控制组间的协变量和倾向得分是否存在显著差异。本文主要通过图2匹配前后各协变量的标准化偏差的变化图(见81页)及表4中的两类统计指标检验实验组和控制组间的协变量和倾向得分的平衡性。其中,第一类包括单个协变量的双t检验及匹配前后标准化偏差的变化;第二类指标是对整体平衡性的检验,包括匹配前后pseudo R2、协变量联合显著性检验(LR检验)及协变量联合分布是否有显著差异的p值等。
从图2及表4能够直观地看出,所有协变量的标准化偏差均有明显的下降。匹配后协变量的p值均较大,这表明匹配后的实验组与控制组之间没有显著性差异,协变量的分布基本是一致的,所以满足单个协变量的平衡性假设。由样本联合检验的结果可知,匹配后样本的pseudo R2值由0.527下降到0.042,LR统计量的p值由0上升为0.985,均值偏差及中位数偏差在匹配后都得到了大幅度降低,以上都表明匹配后贫困县与非贫困县间的控制变量和倾向得分的分布是一致的,满足整体平衡性假设。
2.共同支撑检验
由于只有当实验组与控制组的样本倾向得分值具有较大的共同支撑区域时,该匹配方法才满足共同支撑假设。[31]本文中的实验组与控制组的样本数分别为23个和273个,利用PSM方法进行匹配后,落在共同支撑区域外的实验组样本数为7个,所有的控制组样本都在共同支撑区域内,最后得到的实验组与控制组的样本数分别为16个和273个。由此可知,只有很少的样本量落在共同支撑区域外,在实验组和控制组中倾向得分具有较大的共同支撑区域,因此该匹配方法满足共同支撑假设。
(三)贫困县设立对农民收入的平均效应
为了回答本文引言中的第一个问题,将以上通过PSM方法匹配好的16个贫困县及16个非贫困县2007~2016年的面板数据分为四组,分别为16个贫困县2007~2011年及2012~2016年的样本数据和16个非贫困县2007~2011年及2012~2016年的样本数据,并结合如下构建的双向固定效应基准回归模型估计贫困县设立对农民收入的平均效应。不带控制变量的基准回归模型如下:
其中,被解释变量Yit表示第i(i=1,2,…,32)个县第t年农民收入水平;treatit表示第i个县第t年是否是新调入的贫困县的虚拟变量,如果是新调入的取值为1,否则为0;postit表示贫困县名单调整的政策分期变量,2012年以前取值为0,2012年及以后取值为1;λi、νt分别表示各样本县的个体固定效应与时间固定效应;εit为随机干扰项。上式中的β1为核心估计参数,表示贫困县的设立对农民收入影响的净效应,如果β1>0,说明贫困县能够提升农民收入水平,如果β1<0,说明贫困县非但不能增加农民收入还会使其减少。
以上双向固定效应基准模型还可以加入控制变量变为如下形式:
其中,xk it(k=1,2,…,8)表示第i个县第t年第k个控制变量,xit包括实际人均GDP的对数值(lnperg)、乡村从业人员比重(emp)、公共财政预算收入比重(rev)、公共财政预算支出比重(fis)、农产品总产值比重(pro)、第二产业增加值比重(sec)及第三产业增加值比重(ter)、农产品相对价格(pri),其他变量含义同模型(4)。
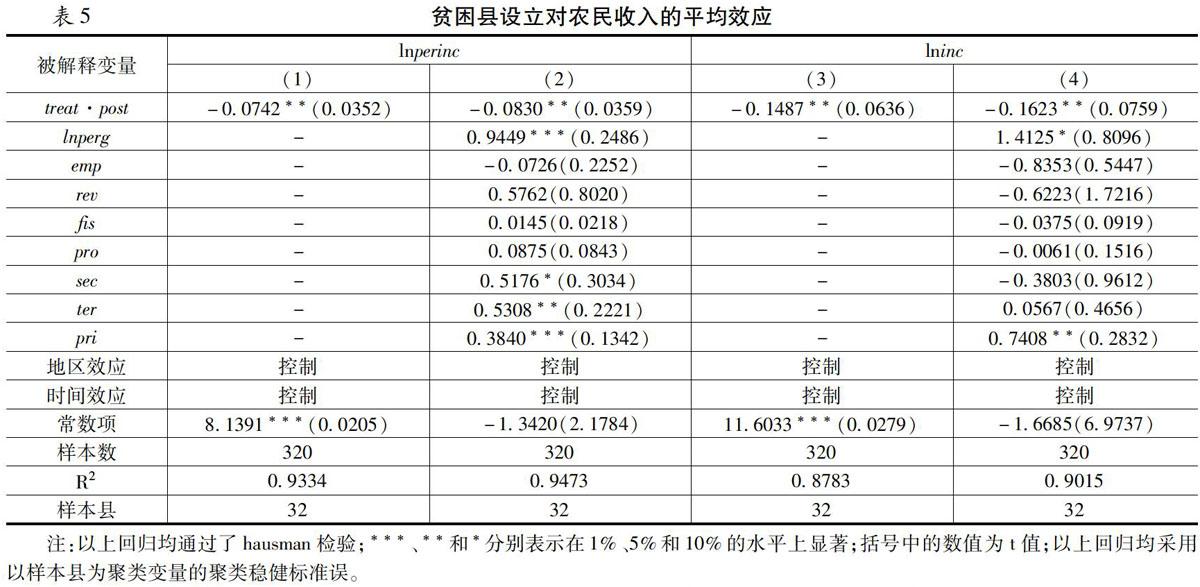
根据模型(4)和(5)所得的回归结果如表5所示。表5结果显示,贫困县非但没有增加当地农民收入反而对其有减少作用。其中,第(1)、(3)列结果未加入控制变量,第(2)、(4)列结果加入了控制变量,结果都表明贫困县对农民收入存在负向影响,且在5%的水平上显著。因此,贫困县的设立并没有起到提升农民收入的作用,并且对其有负向影响。
可以看出,表5中的第(2)、(4)列在加入其他控制变量之后,人均GDP水平越高越有利于促进农民人均可支配收入,且在1%的水平上通过了显著性检验;因此,地区农民收入水平与当地经济发展水平紧密相关。第二、三产业增加值比重的提高对农民收入有积极的正向影响,且分别在10%、5%的水平上显著,这说明地区产业结构越高级越有利于增加农民收入。农产品相对价格越高,农民越能从农产品中获得高收入,从而越有利于提升农民收入水平,且该结果在1%的水平上显著;因此,在农民丰收的年份出现“谷贱伤农”经济现象时,当地政府应该对农产品价格采取政府干预实行最低限价政策,以帮助农民增收。另外,对当地农民收入总体水平而言,人均GDP水平及农产品相对价格都对其有积极的正向影响。
(四)贫困县设立对农民收入的动态效应
为了估计贫困县对农民收入的动态效应,本文利用2007~2016年通过以上PSM方法匹配好的32个样本县的面板数据,并构建如下模型:
由于本部分估计的是贫困县对农民收入的动态效应,所以设定在2012~2016年期间,当t=j时postj it=1,否则postj it=0,其他变量含义同模型(4)和(5)。上式中的βj为核心估计参数,表示贫困县对农民收入的动态净效应。
其次,贫困县和贫困户的脱贫与收入提升问题绝不单是它们自己的问题。根据以上贫困县的设立对农民收入水平的影响机制检验,加强对贫困县第二、三产业的支持力度,通过财税支持、产业扶持及其他相应扶贫政策吸引外部投资,积极承接产业转移,并利用当地自然资源禀赋条件和生态环境优势大力发展旅游业和其他服务业,能够有效促进农民增收和推动当地产业结构优化。更为重要的是,将扶贫项目直接落户到扶贫对象,以打破原有的收入分配格局,进一步提升农民自我管理水平和发展能力,帮助农民实现可持续生计,使农民从根本上和长远受益,这对于提升农户收入水平具有重要意义。
参考文献:
[1]Fosu, A. K.. Inequality, Income, and Poverty: Comparative Global Evidence[J]. SOCIAL SCIENCE QUARTERLY, 2010, 91(5): 1432-1446.
[2]习近平. 决胜全面建成小康社会 夺取新时代中国特色社会主义伟大胜利[N]. 人民日报,2017-10-28.
[3]Heckman, J. J., H. Ichimura, and P. E. Todd. Matching As An Econometr Evaluation Estimator: Evidence from Evaluating a Job Training Programme[J]. The Review of Economic Studies, 1997, 64(4): 605-654.
[4]Heckman, J. J., H. Ichimura, and P. E. Todd. Matching as an Econometric Evaluation Estimator[J]. The Reviews of Economics Studies, 1998, 65(2): 261-294.
[5]陳全功,程蹊.长期贫困为什么难以消除?——来自扶贫重点县教育发展的证据[J].西北人口,2006(3):39-42,46-47.
[6]帅传敏,梁尚昆,刘松.国家扶贫开发重点县投入绩效的实证分析[J].经济问题,2008(6):84-86.
[7]赵曦,熊理然,肖丹.中国农村扶贫资金管理问题研究[J].农村经济,2009(1):47-50.
[8]张金梅,邓谨.惠农政策实施效果评价及对策研究——以国家级贫困县为例[J].中国农学通报,2011,27(26):218-222.
[9]张伟宾,汪三贵.扶贫政策、收入分配与中国农村减贫[J].农业经济问题,2013,34(2):66-75,111.
[10]姜爱华.我国政府开发式扶贫资金投放效果的实证分析[J].中央财经大学学报,2008(2):13-18.
[11]张彬斌.新时期政策扶贫:目标选择和农民增收[J].经济学(季刊),2013,12(3):959-982.
[12]张彬斌,陈小利.“重点县”扶贫的人力资本形成效应[J].经济科学,2015(1):40-52.
[13]郑家喜,江帆.国家扶贫开发工作重点县政策:驱动增长、缩小差距,还是政策失灵——基于PSM-DID方法的研究[J].经济问题探索,2016(12):43-52.
[14]黄志平.国家级贫困县的设立推动了当地经济发展吗?——基于PSM-DID方法的实证研究[J].中国农村经济,2018(5):98-111.
[15]张彬斌.新时期政策扶贫:目标选择和农民增收[J].经济学(季刊),2013,12(3):959-982.
[16]王小华,王定祥,温涛.中国农贷的减贫增收效应:贫困县与非贫困县的分层比较[J].数量经济技术经济研究,2014,31(9):40-55.
[17]叶慧.生计资本框架下公共财政政策对农民收入影响分析——基于重庆市两个少数民族贫困县的调查[J].中南民族大学学报(人文社会科学版),2015,35(1):114-119.
[18]周敏慧,陶然.市场还是政府:评估中国农村减贫政策[J].国际经济评论,2016(6):63-76,5-6.
[19]康江江,宁越敏,魏也华,武荣伟.中国集中连片特困地区农民收入的时空演变及影响因素[J].中国人口·资源与环境,2017,27(11):86-94.
[20]王守坤.国家级贫困县身份与县级城乡收入差距[J].人文杂志,2018(10):43-51.
[21]方迎风.国家级贫困县的经济增长与减贫效应——基于中国县级面板数据的实证分析[J].社会科学研究,2019(1):15-25.
[22]Bank W . China - From Poor Areas to Poor People : Chinas Evolving Poverty Reduction Agenda - An Assessment of Poverty and Inequality in China[J]. International Journal of Accounting Education & Research, 2009, 27(24): 333-335.
[23]Knight, J. Inequality in China: An Overview[J]. The World Bank Research Observer, 2014,29(1):1-19.
[24]李实,罗楚亮.中国收入差距究竟有多大?——对修正样本结构偏差的尝试[J].经济研究,2011,46(4):68-79.
[25]中國农村扶贫开发纲要[N]. 人民日报,2011-12-02.
[26]陈林,伍海军.国内双重差分法的研究现状与潜在问题[J].数量经济技术经济研究,2015,32(7):133-148.
[27]Rosenbaum, P. R., and D. B. Rubin. The Central Role of the Propensity Score in Observational Studies for Causal Effects[J]. 1983, 70(1): 41-55.
[28]Dehejia, Rajeev H.. Practical propensity score matching: a reply to Smith and Todd[J]. Journal of Econometrics, 2005, 125: 355-364.
[29]Ashenfelter Orley C.. Estimating the Effect of Training Program on Earnings[J]. The Review of Economics and Statistics, 1978, 60(1): 47-57.
[30]胡永远,周志凤.基于倾向得分匹配法的政策参与效应评估[J].中国行政管理,2014(1):98-101.
[31]Heckman, J. J., V. Edward. Policy-Relevant Treatment Effects[J]. American Economic Review, 2001, 91(2): 107-111.
[32]陈刚.法官异地交流与司法效率——来自高院院长的经验证据[J].经济学(季刊),2012,11(4):1171-1192.
Does the Establishment of National Poverty-stricken Counties Increase
the Income Level of Local Farmers
-An Empirical Research Based on Panel Data of 296 Counties in China from 2007 to 2016
LI Quan, LU Ke-ji, LI Meng
(Lanzhou University, Lanzhou, Gansu 730000, China)
Abstract:
Since the implementation of the poverty-stricken county system in China in 1986, whether and to what extent the establishment of national poverty-stricken counties can raise the real income level of local farmers requires an systematic and scientific empirical test. Based on propensity score matching-difference in difference (PSM-DID) methods, using the panel data of 296 counties in six provinces of China from 2007 to 2016, it is found that the establishment of national poverty-stricken counties failed to effectively improve the real income level of local farmers.On the contrary, it has a sustained negative effect. Further research has found that the development of secondary and tertiary industries in poverty-stricken areas can effectively raise the real income level of local farmers, but the policy of poverty-stricken counties has not optimized the local industrial structure; the government can effectively increase farmers' real income by intervening in the price of agricultural products. From the policy implication of the research conclusion, it is of great practical significance to promote precise poverty alleviation based on poor households, promote effective investment through attracting external investment, and optimize county industrial structure for enhancing farmers' income in poverty-stricken counties.
Key words:
national poverty-stricken county; different-in-different; propensity score matching; farmers' real income
