基于中智KNN的齿轮箱故障诊断方法
2019-10-30王栋璀丁云飞朱晨烜
王栋璀, 丁云飞, 朱晨烜
(上海电机学院 电气学院,上海 200240)
齿轮箱作为旋转机械设备的核心部件,长期工作在恶劣的工况条件下,容易发生机械故障[1],如果不及时诊断维护,会给旋转设备造成较大的运行风险和经济损失。因此,对齿轮箱建立快速而有效的故障诊断机制,是减少设备停机时间,提高经济效益的有效途径。
目前,随着人工智能技术的发展,基于智能算法的模式识别技术被引入到故障诊断领域中。K-最近邻分类算法[2](K-Nearest Neighbor,KNN)是一种基于先验知识的监督学习算法,该算法以较为简单的结构和较强的分类性能而被广泛应用在文本分类、图像处理以及故障诊断等领域。如孙斌等[3]利用局部切空间排列提取到汽轮机转子的故障特征,并输入到KNN分类器中,取得了良好的故障识别效果。姜景升等[4]针对诊断效果受近邻参数影响较大的缺点,对基于KNN分类器的故障诊断方法做出了改进,有效地提升了轴承故障的识别率。侯平智等[5]提出了基于K近邻证据融合的故障诊断方法,在电机转子故障诊断中取得了显著的成果。王雪冬等[6]将核监督局部保留投影法与KNN分类器相结合应用在旋转机械的故障诊断中,改善了故障识别精度。陈法法等[7]利用等距映射非线性流形学习提取到故障特征,并与KNN算法相结合对齿轮箱故障进行了有效的诊断。
然而,KNN算法在分类决策时并没有考虑特征权重的分配问题,导致算法分类性能较差,进而限制了KNN算法在工程领域中的进一步推广。针对这一缺陷,Keller等[8]从算法结构出发,借助模糊理论对KNN算法进行了改进,提出了FKNN(Fuzzy-K-Nearest Neighbor,FKNN)分类算法,考虑了不同特征对分类的贡献,有效地提升了算法的分类性能。杜海莲等[9]验证了FKNN算法在故障诊断中的适用性,更好地识别出了电动执行器的故障类型。
本文受FKNN算法的启发,欲借助中智理论在处理不一致性和不确定性信息上的优势,提出基于中智KNN的齿轮箱故障诊断方法,以期提高诊断准确度,从而为齿轮箱故障的智能诊断技术提供了新的研究思路。
1 基本理论
1.1 KNN分类算法
KNN分类算法的基本思想是:假设x为待测样本,通过欧式距离找出x的k个最近邻样本,然后统计这k个最近邻样本出现的次数,采用投票机制,将出现次数最多的近邻样本的类标签赋给待测样本。
现以待分类样本xs为例简述KNN分类算法的计算步骤:首先设训练样本数据集U={(xi,ci)|i=1,2,…,N},包含M类训练样本,记类别集合为C={cl|l=1,2,…,M}, 其中训练样本xi为p维的列向量,ci为xi所对应的类别标签。
(1) 计算待分类样本xs与所有训练样本的距离,通常采用欧氏距离作为衡量标准,其计算公式为
(1)
(2) 选择最近邻参数k,依据计算出的欧氏距离寻找出xs的k个最近邻样本,记为Qs={(xsj,csj)|j=1,2,…,k}。xsj表示待分类样本xs的第j(1≤j≤k)个最近邻样本,csj为xsj所对应的类别。
(3) 根据Qs中的k个最近邻样本的类别信息进行投票,投票结果记为v=[v1,…,vl,…vM],并按投票结果进行决策,决策规则为
(2)
1.2 FKNN分类算法
如前文所述,FKNN是对一般KNN算法的扩展与改进,它解决了KNN算法在分类时会将各特征属性同等对待的问题。沿用上述KNN算法所提出的假设条件,简述FKNN算法的实现步骤。
首先,将训练样本的类别信息模糊化,得到训练样本的类隶属度;然后选定近邻参数k,计算待分类样本xs与所有训练样本的欧式距离,从而找到xs的k个最近邻样本;随后,利用距离权重构造出xs与近邻样本的相似度,并将其与这k个近邻样本的类隶属度进行加权实现对待测样本的分类决策。具体的决策计算公式如下
(3)
式中:m称为权重系数,反映样本与其k个邻居的重要程度。ul(xsj)表示xs的第j个最近邻训练样本属于第l类的隶属度,其计算公式为
(4)
式中:nl表示xs的k个最近邻中与样本xsj同属第l类的个数。
1.3 中智KNN分类算法
20世纪末,Smarandache[10-11]从哲学角度出发提出了中智理论,创造性地引入了不确定性,解决了实际应用中“非真即假”的逻辑单一性,使得很多智能学习算法得到推广。本文所提到的中智KNN分类算法,将FKNN算法中的类隶属度扩展为“真”,“假”和不确定度[12]三类,能够更好地细化样本的特征权重,突出不同特征对分类过程的贡献率。其中,“真”隶属度反映样本属于自身属性的程度,“假”隶属度通过引入参数来模拟噪声集合,从而反映出样本与噪声集的关系。而不确定度通过考察样本点与中智点[13](某两类样本重心的中点)的关系,来反映样本与中立区域(中智点附近的区域)的关系,不确定度越大说明样本距中立区域就越近,因而该样本“悬而未决”的程度就越大。利用这三种隶属度构建出基于中智KNN的决策规则,之后在不考虑噪声的情况下,输出含有不确定类(中智类)的划分结果,称为中智划分。以待分类样本xs,M类训练样本为例,说明算法流程。
(1) 确定训练集中每类训练样本的类重心。
(2) 计算训练样本xi的“真”隶属度Tij,“假”隶属度Fi和不确定度Ii。具体的计算公式如下
(5)
(6)
(7)
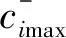
(8)
(3) 选定近邻参数k,找出待分类样本xs的k个最近邻训练样本,分别计算待分类样本xs与其k个最近邻样本间的相似度。基于曼哈顿距离的相似度量度量公式在大多数情况下具有较高的稳定性,因此本文采用曼氏距离来构造相似度计算公式
(9)
式中: 样本含有p维属性,t为样本的某个属性,di表示xs与第i个近邻样本xi间的相似度,q为相似度量的权重系数。
(4) 依据公式(10)计算xs的类隶属度,对待分类样本进行决策,分类决策公式为(11)。并通过公式(12)和(13)计算输出中智划分的结果Nc(xs)。
(10)
(11)
(12)
(13)
2 数据采集与特征提取
齿轮箱的故障诊断大致可以分为实验数据采集,故障特征提取和故障模式识别三个阶段,具体的故障诊断流程如图1所示。由于“1.3”节对中智KNN的模式识别算法进行了描述,本节将只针对实验数据采集和特征提取的关键步骤进行详细说明。
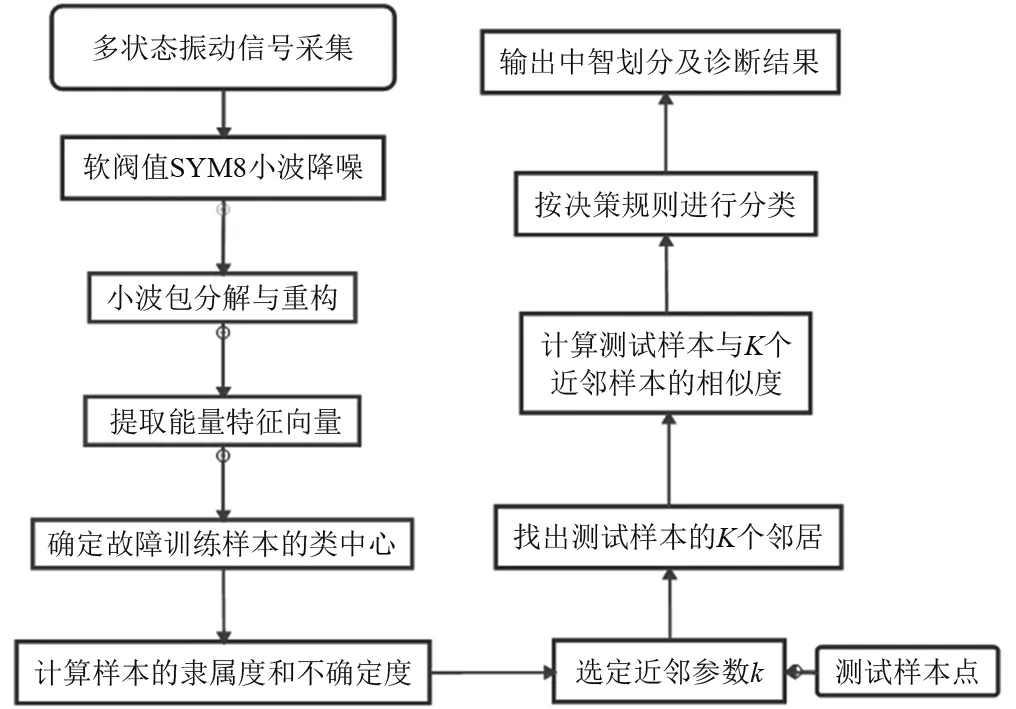
图1 基于中智KNN的故障诊断流程图Fig.1 Procedure of fault diagnosis based on NKNN
2.1 数据采集
本文所采集的齿轮箱振动信号来自江苏千鹏诊断工程有限公司的QPZZ-Ⅱ。旋转机械振动分析及故障诊断实验平台系统,实验平台由二级齿轮箱、变速驱动电机、轴承、主轴、联轴器、制动器、传感器和数据采集系统组成,实验平台如图 2所示。选择振动能量较为集中和突出的齿轮箱输出端的轴承座作为测点位置,布置压电式加速度传感器,测取振动加速度信号。为保证模拟的故障信号与实际产生的齿轮故障信号相似,实验采用电火花加工技术在不同的齿轮上分别植入损伤点,来模拟高速轴小齿轮齿面磨损和低速轴大齿轮断齿所引起的故障状态。同时为了更好地说明中智划分在故障诊断中的意义,还对大齿轮断齿、小齿轮磨损的混合故障进行了模拟,为后续的实验工作奠定了基础。在采样频率为5 120 Hz,主轴转速为1 500 r/min的情况下,采集每种状态数据各25组,共100组实验样本。

图2 齿轮箱故障诊断模拟实验平台Fig.2 The test bench of gearbox fault diagnosis
2.2 信号的特征提取
合理地提取振动信号的特征是提高诊断精度的前提。考虑到振动信号中的频带能量包含了丰富的故障信息,以能量为元素构造出的特征向量可以区分出齿轮箱的故障类型。因此,本文采用能够对非平稳信号进行有效分析的小波包[14]变换技术对信号特征进行提取。以下对小波包提取特征向量的关键步骤进行说明:
(1) 对振动信号的处理通常采用小波阈值降噪[15]手段来达到衰减噪声的目的。本文选用软阀值sym8小波对原始信号进行去噪。
(2) 利用db3小波对降噪信号进行三层小波包分解,从而得到第三层从低频到高频的八个子频带分解系数。
(3) 对第三层小波包分解系数进行重构,提取各频带范围内的信号。用S3j(j=0,1,…,7)表示第三层小波包分解系数的单支重构信号。
(4) 计算出各频带所占的相对能量,经归一化处理[16]构造出能量特征向量。设S3j对应的频带能量为E3j,则能量的计算公式为
(12)
式中:xjk(j=0,1,…,7为振动信号的采样点个数)为重构信号的离散点幅值。
随后按照各个频带能量(相对能量)的比例关系做出一系列的能量分布直方图。如图3所示,不同故障对应着不同频带能量的分布特征,因此,可以通过频带能量分布情况准确地判断出发生故障的类型。直接利用各频率成分能量的变化来表示故障的征兆,较好地保留了信号的原始特征,从而为故障模式的识别提供了全面的信息输入。
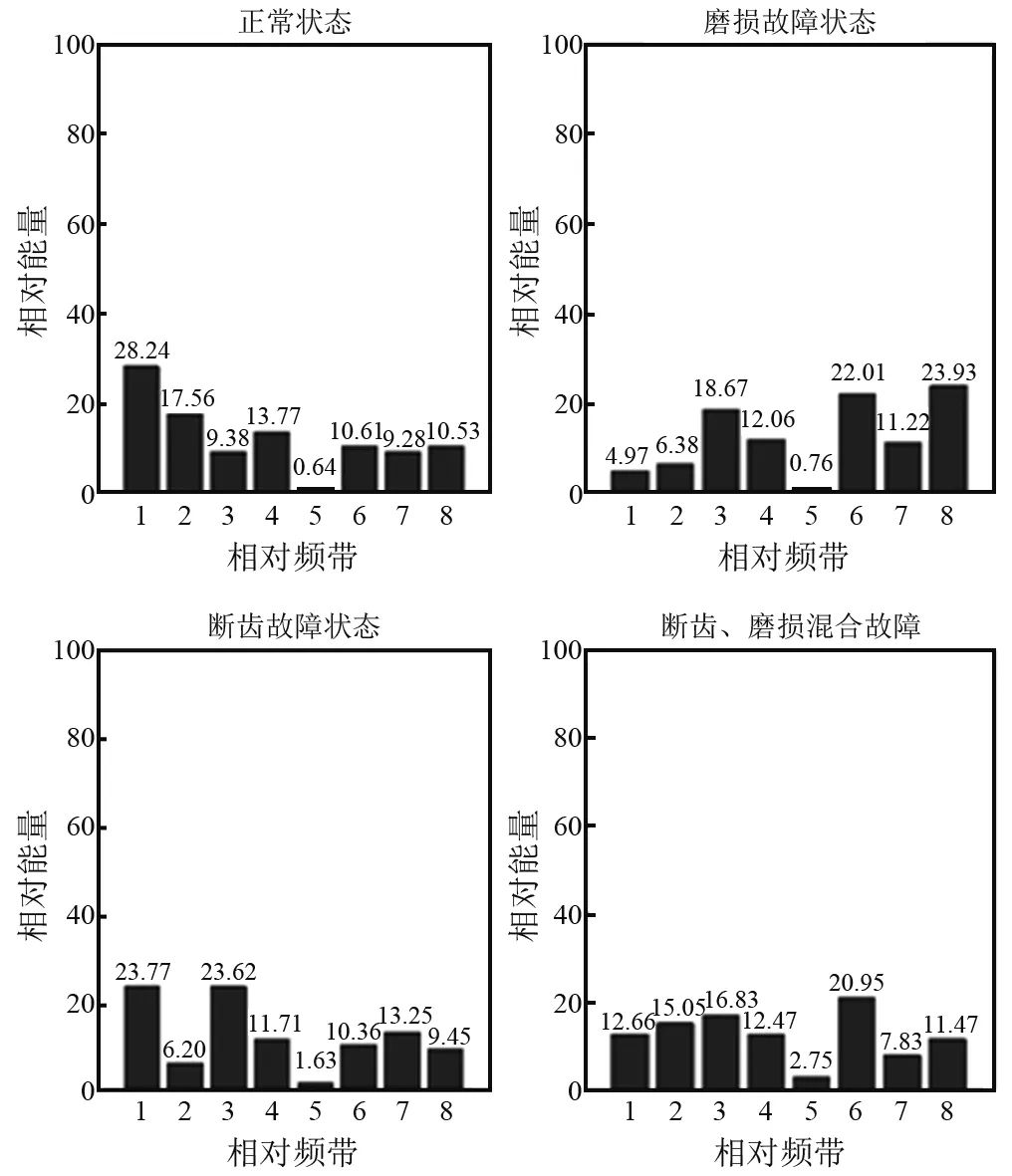
图3 不同状态的能量分布直方图(k=5)Fig.3 The histogram of energy distribution in different states(k=5)
3 实验与结果分析
3.1 诊断效果分析
为验证基于中智KNN诊断方法的分类性能,首先依次选取四种状态下的训练样本各10组,共40组数据作为训练样本集,其余60组作为测试样本集。分别利用KNN,FKNN和基于中智的KNN分类诊断方法对测试样本进行诊断识别,三种方法均选定近邻参数k为5。由图4,图5可以看出,KNN误分了9个测试样本,准确率仅为85%。FKNN的故障识别精度较KNN诊断方法,提高了6.6%,分类性能优于KNN。相比之下,基于中智KNN的诊断方法分类效果最佳,诊断准确率达到了100%,能够很好地区别出故障类型。
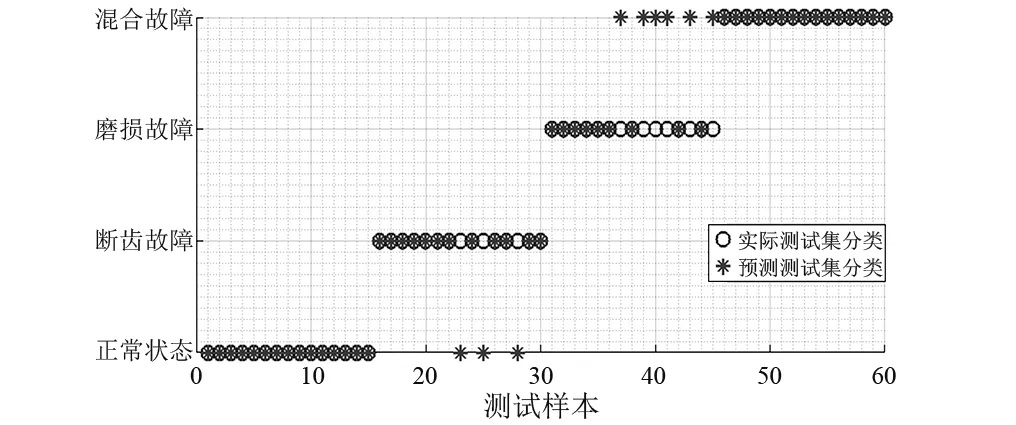
图4 基于KNN的故障分类结果图(k=5)Fig.4 KNN based fault classification results(k=5)
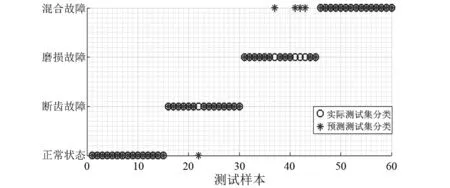
图5 基于FKNN的故障分类结果图(k=5)Fig.5 FKNN based fault classification results(k=5)
另一方面,为保证实验结果的客观性,将故障样 本按比例划分,分别选取80%,60%,40%和20%的样本作为训练样本集,相应地将剩余样本作为测试样本集。采用交叉验证[17]的方法,在近邻数为5的情况下,分别利用以上三种方法对测试样本进行分类,实验均进行N(N=10)次取平均值,得到的实验结果如表1所示,基于中智KNN的分类诊断方法所获得的平均识别率均高于其他两种方法。
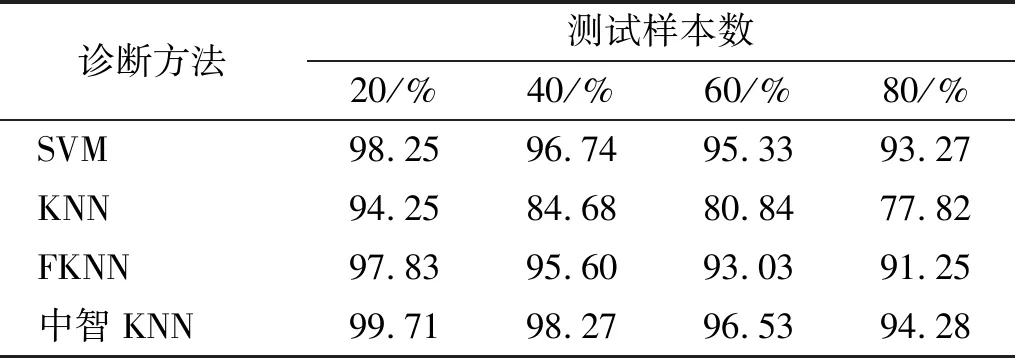
表1 不同诊断方法的故障识别率(k=5)Tab.1 Fault classification rate of the different classifiers(k=5)
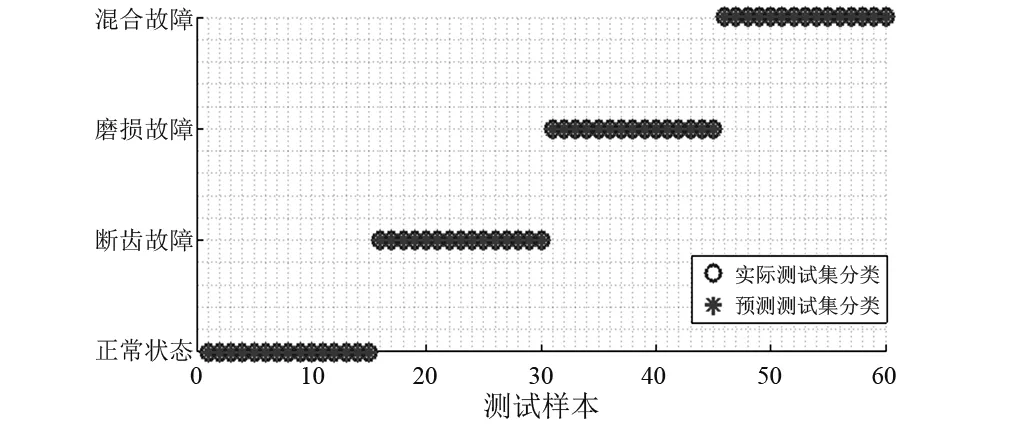
图6 基于中智KNN的故障分类结果图(k=5,δ=0.1)Fig.6 NKNN based fault classification results(k=5,δ=0.1)
正是由于中智KNN所引进的“假”隶属度和不确定度客观地考虑了中立区域和噪声集对样本分类的影响,才使得贡献权重的分配更趋于合理,得到的故障识别率更加精确。此外,为体现所提方法的有效性,还增加了基于支持向量机(Support Vector Machine,SVM)的故障诊断方法作为对比。虽然在诊断精度方面,SVM表现良好,但为了获取最佳的核函数参数和惩罚因子需要对样本模型进行训练,这样会增加计算开销,进而会影响诊断效率,不利于提高诊断性能。
3.2 基于中智划分的结果分析
依据“1.3”节对中智KNN算法的描述,在最终进行分类决策的同时,会输出中智划分的结果,现将中智划分在故障诊断中的意义进行说明。如图7所示,49号和55号测试样本在中智划分结果中被判定为中智类。根据表2(Ti1,Ti2,Ti3和Ti4分别表示属于正常、断齿、磨损和混合故障的隶属度)所列出的部分混合故障样本的隶属度信息可以发现,由于靠近两类集合的中智点,导致了这两个故障样本的不确定度Ii较大,随即被划分到了两类样本的中立区域,即中智类。进一步分析得到,由于这两个故障样本点的Ti3和Ti4的值较大,说明故障样本点更接近混合故障集和磨损故障集的中智点,而较大的Ti3反映出样本所包含的磨损故障信息较多,致使高频振动较为剧烈,由此可知在发生混合故障时,相比大齿轮断齿,小齿轮磨损的程度更深。某种意义上,当发生混合故障时,中智划分会反映出不同的单一故障的剧烈程度,对故障状态的预测起到指导性作用。
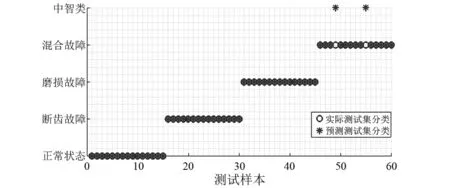
图7 中智划分结果图(k=5,δ=1)Fig.7 The result of neutrosophic partition(k=5,δ=1)
3.3 鲁棒性分析
KNN算法属于惰性学习算法,其近邻参数k的选择势必会对诊断结果产生影响。因此,本文研究了不同算法随k值变化的鲁棒性。取训练样本60组,测试样本40组进行实验。实验结果如图8所示,随近邻参数k的变化,不同方法所得到的故障识别率均有所变化。由图可知,在k=4以后,KNN诊断方法的分类性能逐渐恶化,故障识别率大幅降低,无法准确识别故障类型;FKNN诊断方法的故障识别率虽高于传统的KNN诊断方法,但随着k值的增大也呈现出了下降趋势,特别是在k=7以后,故障识别率已经低于85%。相比之下,本文提出的中智KNN诊断方法表现出了良好的适应性和稳定性,即使是k值选择较大,其故障识别率依然能够保持较高水平,并且没有出现明显的波动,具有较强的鲁棒性。
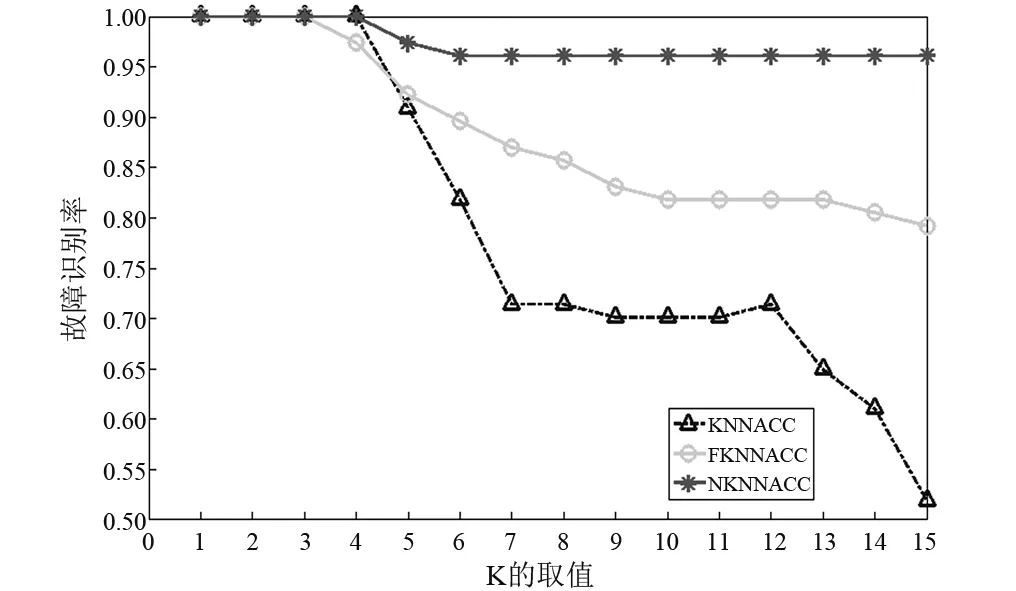
图8 不同分类器随k值变化的故障识别率Fig.8 Fault recognition rate of different classifiers based on the changing k value
3.4 抗噪性分析
前文提到基于中智KNN的故障诊断方法在引入“假”隶属度时,融入了正则化参数δ。由式(6)可知,若保持其值不变,那么Fi越大,证明样本点属于噪声集的可能性就越大。现通过改变正则化参数,来控制随机干扰噪声的数量说明算法的抗噪性,实验结果由图9所示。随着参数δ的减小,噪声数量不断增加,故障识别率有所降低,但将参数控制在一定范围内,仍然可以保持较高的诊断精度,说明该方法在一定程度上具有抗噪作用,有助于提升泛化能力,便于应用。
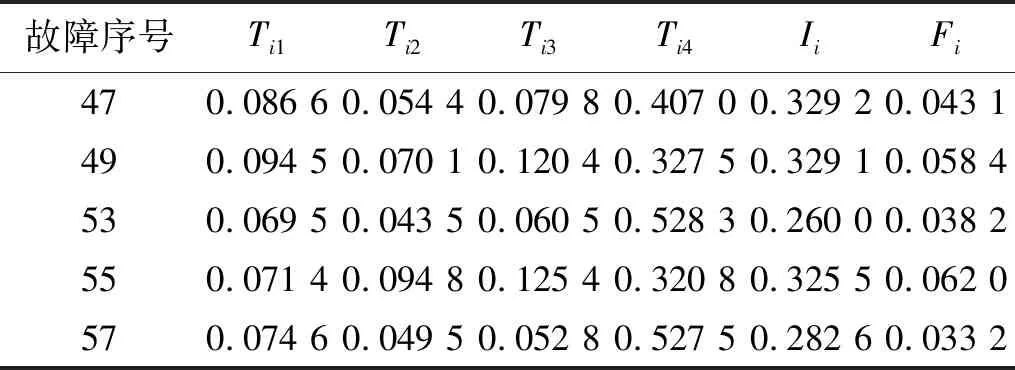
表2 部分故障样本的隶属度(δ=1)Tab.2 The membership of some fault samples(δ=1)

图9 参数δ随k值变化的故障识别率Fig.9 The fault recognition rate based on the k value with changing parameters
4 结 论
(1) 本文提出了基于中智KNN的齿轮箱故障诊断方法,利用“真”、“假”隶属度和不确定度将样本的类别信息定量地反映出来,量化自身属性的同时,还兼顾了不确定性和噪声集对分类精度的影响,使得样本分类更加灵活完善,良好地克服了传统KNN同贡献权重分配的缺陷。通过对比实验,验证了该方法可以有效地提高故障的分类精度。
(2) 在混合故障诊断方面,所提出的方法不但能够对不同类型的故障样本进行细致划分,而且通过中智划分可以反映出混合故障中单一故障发生的剧烈程度,为齿轮箱的智能诊断研究提供了参考价值。
(3) 实验还表明,基于中智KNN的故障诊断方法具有较强的鲁棒性和一定程度的抗噪性,体现出了该方法在故障诊断方面的优越性。
