双输入流深度反卷积的插值神经网络
2019-10-23张强杨剑富丽贞
张强 杨剑 富丽贞

摘 要:在实际工作中深度学习方法通常不具备大量的训练样本,因此提出了双输入流深度反卷积生成神经网络的构架,依据给定的条件产生新的目标图像,从而扩充训练样本集。该神经网络的整体架构由双输入的卷积网络和一个反卷积网络输出构成,其中双输入卷积网络接收目标物体不同视角的两张图片并提取抽象特征,而反卷积网络则利用抽象特征和设定的参数产生新的插值目标图像。在ShapeNetCore数据集上的实验结果显示,在相同数量的训练样本空间中,与未扩展数据集的卷积网络相比,双输入流深度反卷积生成神经网络的识别率提高了20%左右。结果表明,双输入流深度反卷积生成神经网络无需输入目标物类别,可生成新参数条件下的目标图像,扩充训练样本空间,从而提高识别率,可用于少样本的目标物多角度识别。
关键词:深度学习;人工智能;生成神经网络;反卷积;双输入流
中图分类号: TP183
文献标志码:A
Two-input stream deep deconvolution neural network for interpolation and recognition
ZHANG Qiang1, YANG Jian1,2*, FU Lizhen1
1.School of Software, North University of China, Taiyuan Shanxi 030051, China ;
2.Key Laboratory of Electromagnetic Wave Information of Ministry of Education (Fudan University), Shanghai 200433, China
Abstract: It is impractical to have a large size of training dataset in real work for neural network training, so a two-input stream generative neural network which can generate a new image with the given parameters was proposed, hence to augment the training dataset. The framework of the proposed neural network consists of a two-input steam convolution network and a deconvolution network.
The two-input steam network has two convolution networks to extract features, and the deconvolution network is connected to the end. Two images with different angle were input into the convolution network to get high-level description, then an interpolation target image with a new perspectives was generated by using the deconvolution network with the above high-level description and set parameters. The experiment results on ShapeNetCore show that on the same dataset, the recognition rate of the proposed network has increased by 20% than the common network framework. This method can enlarge the size of the training dataset and is useful for multi-angle recognition.
Key words: deep learning; artificial intelligence; generative neural network; deconvolution; two-input stream
0 引言
深度學习近些年来在人工智能各个领域都取得了显著的成果,在分类识别等方面的性能表现优异。深度学习的优异性能通常依赖于巨量的训练,因此需要大量标签化的训练数据;但在实际工作中,具备大量训练样本的条件通常是少数或者是不现实的,小样本严重影响了神经网络的性能。因此,开展依据给定条件产生新的目标图像的研究具有现实意义和研究价值。
为了产生新的样本图像,现有的方法通常采用图像处理的方法,如利用缩放、旋转、平移等产生新的图像;但这类方法得到的图片通常存在质量不高、容易偏差等问题。利用生成神经网络产生图像的方法虽然较为先进,但存在需要预知其类别或高层特征的问题。
另一种方法则是利用知识迁移实现对网络参数学习的优化,但该类方法迁移较为困难,且效果难以保证。
本文在分析上述几类方法的基础上,基于深度学习方法提出了双输入流深度反卷积生成神经网络架构。该神经网络接收不同角度的两张图像,利用卷积神经网络提取出高层抽象特征,再利用反卷积神经网络并设定新角度等条件产生高质量的新图像。实验结果表明,该网络结构具有其自身的特点,能依据给定的条件产生高质量的图像,从而扩充训练集,最终影响神经网络的识别性能。
与现有的生成神经网络相比,主要区别在于:1)与文献 [10]中的方法不同,所提出的神经网络无需输入目标物类别,能够在抽象出未知目标物的高层特征后利用高层特征生成此目标物在新参数下的图像;
2)与现有网络不同,所提出的网络采用双输入图像,能提取高层抽象特征,并利用反卷积神经网络完成图像的生成;
3)该网络可设置输入参数,产生不同尺寸、大小、视角和亮度的图像;
4)其中的倒置卷积神经网络部分可作为分类器,在相同的训练集条件下,利用扩充的数据集可有效提高识别率。
1 相关工作
在少样本条件下(zero-shot or few-shot learning)的深度学习问题是当前人工智能领域的难点问题,也属于迁移学习的研究领域。在实际研究工作中,深度学习只具备少样本条件是较普遍的问题。针对该问题,现有研究工作可分为两类:数据集方法和网络参数训练优化方法。
在数据集扩充方法的研究工作中,科研人员利用传统图像变换方法扩充训练数据集,例如Ding等[1]采用图像旋转、平移和抠图等方法得到新的图像;该方法可在一定程度上提高网络识别率,但存在产生的训练样本变形、与实际图像存在偏差、存在明显的融合界线等问题,对数据集的扩展能力有限。
另外,如文献[2]所述,较为先进的方法是利用对抗或产生神经网络(Generative Adversarial Network, GAN)产生新的图像,如国内的朱俊鹏等[3]、陈文兵等[4]就是利用生成式对抗网络实现数据的增强。其中典型的网络是Hinton等[5]提出的受限玻尔兹曼机(Restricted Boltzmann Machine, RBM)和Salakhutdinov等[6]给出的深度波尔兹曼机(Depth Boltzmann Machine, DBM),它们基于能量的概率分布模型,使产生的图像外形符合该随机模型,缺点是产生图像具有随机性。
此外还有类似具有随机性参数的生成网络,如文献[7-9]。Dosovitskiy等[10]则是将常用的反卷积神经网络 (Deconvolution neural networks) 通过已知的类别在新参数条件下产生新的图像,文献中的实验结果表明该网络结构可产生新的旋转、尺寸、角度参数的高质量图像,甚至匹配图像间的特征点。
Goodfellow等[11]利用对抗生成网络实现了图像的生成。Zhu等[12]构建神经网络输入单张人脸图片,然后产生一个随机视角的人脸图像,其训练也需要大量随机视角图像。文献[12]的方法基于生成神经网络产生图像的方法通过训练抽象出高层图像特征,进而在新的参数条件下产生更逼真或接近实际环境的图像,它可产生新视角下的图像,甚至将不同环境下的图像合成一张新的图像;然而该方法也存在自身问题,如它们的网络必须见过目标物或产生的图像较难控制。
网络参数训练优化方法则利用知识迁移将已经进行过大量训练形成知识的神经网络用于识别未知的类别,也就是优化或微调网络,从而在很少的训练样本条件下完成网络参数的学习和调整。也就是说,利用前期的知识去学习识别未知的类型。Li等[13-14]通过模型参数、共享特征和相关信息等传递知识。元学习方法则是另外一个重要分支,也就是学会学习。Santoro等[15]通过增加记忆将前期的结果作为此次的输入,使得神经网络可以利用以往的知识来学习。Andrychowicz等[16]则利用以往的训练集学会预测梯度,从而学会学习,利用以往或其他的训练集训练一个注意力模型,从而面对少样本条件时,能够关注最重要的部分。Twitter的研究员Ravi等[17]则推出了基于长短期记忆(Long Short-Term Memory, LSTM)网络的元学习模型,该方法采用LSTM的结构训练出一个神经网络的更新机制,输入网络参数后能输出新的更新参数。
可以看出类似文献[17]中方法的核心就是“知识或学习的迁移”,因此此类方法受到以往或前期知识的限制,虽具有理论的先进性,但在实际工作中需要精心挑选知识或学习的方法,在理论方面还需不断完善。
不同于元学习的神经网络训练问题,本文采用较为直观的数据集扩充增加训练集的方法,提出了新的网络结构用于生成新的图像,从而达到扩充训练集、提高识别率的目的。
2 双输入流深度反卷积生成神经网络架构
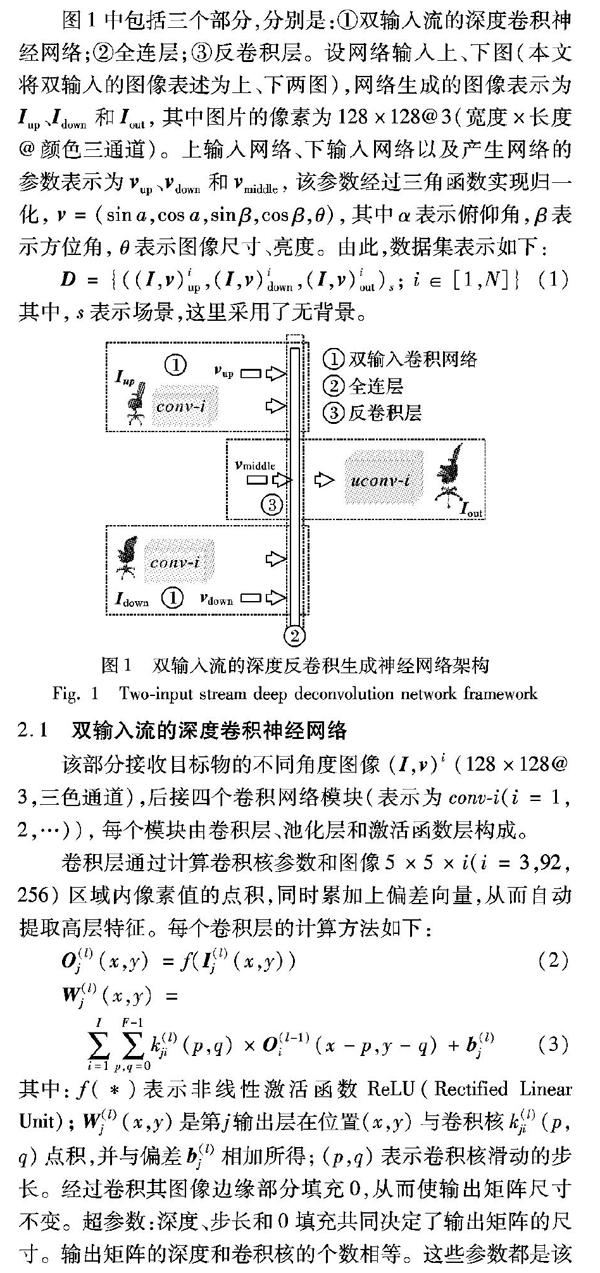
双输入流的深度反卷积生成神经网络的架构以及网络各部分的参数配置如图1所示。
该网络在训练集基础上形成了不同视角图像间如何插值的知识,从而可针对未知的图像形成新視角下的图像并扩充训练集,其本质也是一种知识迁移。不同于单输入的网络,双输入网络具有更完备的知识,能形成高质量的插图。
图1中包括三个部分,分别是:①双输入流的深度卷积神经网络;②全连层;③反卷积层。设网络输入上、下图(本文将双输入的图像表述为上、下两图),网络生成的图像表示为 I up、 I down和 I out,其中图片的像素为128×128@3(宽度×长度@颜色三通道)。上输入网络、下输入网络以及产生网络的参数表示为 v up、 v down和 v middle,该参数经过三角函数实现归一化, v =(sina,cosa,sinβ,cosβ,θ),其中α表示俯仰角,β表示方位角,θ表示图像尺寸、亮度。由此,数据集表示如下:
D ={(( I , v )iup,( I , v )idown,( I , v )iout)s; i∈[1,N]}
(1)
其中,s表示场景,这里采用了无背景。
2.1 双输入流的深度卷积神经网络
该部分接收目标物的不同角度图像( I , v )i(128×128@3,三色通道),后接四个卷积网络模块(表示为conv-i(i=1,2,…)),每个模块由卷积层、池化层和激活函数层构成。
卷积层通过计算卷积核参数和图像5×5×i(i=3,92,256)区域内像素值的点积,同时累加上偏差向量,从而自动提取高层特征。每个卷积层的计算方法如下:
O (l)j(x,y)=f( I (l)j(x,y))
(2)
W (l)j(x,y)= ∑ I i=1 ∑ F-1 p,q=0 k(l)ji(p,q)× O (l-1)i(x-p,y-q)+ b (l)j
(3)
非线性激活函数ReLU(Rectified Linear Unit)
其中: f(*)表示非线性激活函数ReLU(Rectified Linear Unit); W (l)j(x,y)是第j输出层在位置(x,y)与卷积核k(l)ji(p,q)点积,并与偏差 b (l)j相加所得;(p,q)表示卷积核滑动的步长。经过卷积其图像边缘部分填充0,从而使输出矩阵尺寸不变。超参数:深度、步长和0填充共同决定了输出矩阵的尺寸。输出矩阵的深度和卷积核的个数相等。这些参数都是该网络需要训练的对象。
ReLU层表示激活函数。最近的研究表明非饱和线性修正单元激活函数具有很好的性能,其功能可表示为:
f(x)=max(0,x)
(4)
在实际应用中,ReLU函数可以减少大量的训练时间,同时具有最佳的性能,在训练过程的收敛曲线较好[8]。
池化层起到了降维、非线性、扩大感知野的作用,也就是沿着横向和纵向维度进行下采样。池化层的操作可表示为如下公式:
O (l+1)i(x,y)=max p,q=0,1,…,G-1 O (l)i(x×s+p,y×s+q)
(5)
其中: G 表示池化的尺寸;s表示步长,它决定相邻池化窗口的间距。图1中采用的池化尺寸是2×2。
2.2 全连层FC1、FC2、FC3
图1中的全连层(②)如图2所示,共有三个全连层网络,每一层网络中的每个神经元都与下一层网络中的所有神经元相连接。在网络中,FC1将目标图像的特征进一步抽象, v up、 v down和 v middle是图像的俯仰角、方位角以及θ(尺寸、亮度)参数,这里对参数计算正余弦后构成向量,经过神经节点全连接后得到FC2、FC3。
2.3 反卷积层
反卷积层的方法类似于文献[10-11, 16]中的工作。图1中uconv-i(i=1~4)表示反卷积层,用抽象特征和参数产生新的插值目标图像。每个去卷积层由去池化和反卷积构成,其中去卷积核的尺寸为5×5×i(i=256,92,3),去池化的功能则与传统CNN的池化相反。
从图1中可以看出,将反卷积层(③),也就是uconv-i(i=1~4)的去卷积层部分以及全连层部分进行倒置,可构成CNN分类识别网络,在添加software层的条件下,可输出识别结果。
3 神经网络训练以及数据集
3.1 训练网络
双输入流的深度反卷积生成神经网络采用的损失函数由生成的目标图像和真实图像之间的偏差确定。在训练过程中,采用梯度下降方法最小化损失函数(Loss Function)调整全网络的参数。
min W ∑ N i=1 LRGB( G ( I i, v i), O ( I ireal, v i))
(6)
LRGB(*)= ( G ( I i, v i)- O ( I ireal, v i))2 2
(7)
其中:LRGB(*)表示图像的损失函数; G (Ii,vi)表示由双输入流的深度反卷积生成神经网络产生的目标图像,其外部参数设定为 v i=(sinα,cosα,sinβ,cosβ,θ)i; O (Iireal, v i)表示在场景该条件 v i下的真实图像,在本文实验中LRGB(*)表示欧氏距离。
实验采用TensorFlow框架实现该网络并进行训练。训练中,加载样本的批量为31,学习率设定为0.0005,并进行1000次循环训练,随后间隔300次循环调整学习率减半,总共进行1000次迭代。在实验中,利用高斯随机数初始化参数,采用的是NVIDIA公司的GPU,产生128×128像素的图像。
3.2 数据集
本文采用的数据集是ShapeNetCore子集,该数据集由斯坦福和普林斯頓大学的相关学者联合创建,以3D模型数据为主,涵盖了55类物体模型,共51300个3D模型,
图3中给出了部分模型的图像。
本文采用文献[10]中提供的数据集作为训练集,共有1393个椅子的模型,每个模型有62个视角,其中在每个俯仰角20°和30°下,分别有31个方位角(0°~360°,间隔11°)。同时,实验中对原图像(600×600像素)进行裁剪中心区域、去掉周边白色区域的预处理,使图像大小变为256×256,再修改尺寸为128×128像素,经过上述步骤处理后构成本文的数据集。
4 实验结果与分析
4.1 实验1:新模型在新视角下图像的生成
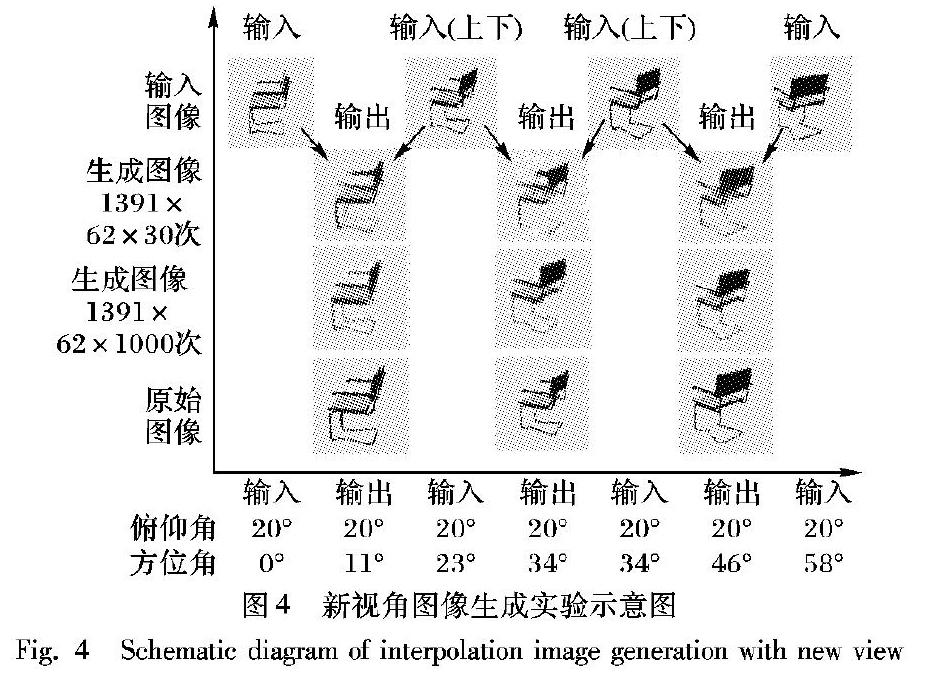
为了验证双输入流的深度反卷积生成神经网络的性能和产生新方位角和俯仰角下目标图像的能力,基于ShapeNetCore数据集展开训练工作。该网络从双输入的图像中抽象出高层的图像特征,然后通过反卷积网络产生新图像。在实验中,将ShapeNetCore数据库中的一部分样本作为测试数据集,其余的作为训练数据集,用于训练网络形成前期知识;训练完成后,输入测试集中的图像,并产生新视角图像。需要强调的是,测试集中的目标物图像从未在网络训练中出现。实验基于Google公司的tensorflow完成。
将ShapeNetCore的数据库分为训练集和测试集,其中测试集中只有如图4所示的目标物图集。
网络模型训练步骤如下:
1)将ShapeNetCore数据库进行前期处理,图像原尺寸为600×600@3,其边框包含较大的空白区域。在前期处理过程中,去除了白色边缘部分后图像尺寸为256×256@3,再修改尺寸为128×128@3。
2)建立图片和参数的对应集合,通过程序分解出图像的参数,并随机化图片的输入顺序,两个角度的图片中间间隔一个角度。每次批量31×2张图片,循环训练30次和1000次。
3)利用Tensorflow的内置函数,保留测试过程中的图像、损失函数变化数据。
网络模型测试步骤如下:
1)将测试数据进行前期处理,去除白色边框,并将图像尺寸调整为256×256@3,并缩放为128×128@3;
2)输入处理后的图像,设定新视角为11°、34°、46°产生图像,并和原始图像进行人工比对。
按照以上步骤开展实验,结果如图4所示。图4中:横轴表示输入参数,纵轴表示图像的类型;
纵轴中间两行表示生成的图像,为了比对图像的效果,最后一行是真值图像。
采用的数据库共有1392个种类,排除一个作为测试集,则共有1391个种类,每个种类共有62张图像。
图4是循环1391×62×30次和1391×62×1000次的模型生成结果,可以看出可依据输入的参数产生理想的目标图像。
实验中优化的损失函数是:
LRGB(*)= ( G ( I i, v i)- O ( I ireal, v i))2 2
(8)
利用Tensorflow的可视化工具Tensorboard可直观地看到损失函数的变化过程。图5给出了训练1000次的损失函数的趋势曲线,
其中每训练一个批次,记录损失函数式(8)的值,损失函数的取值可直接反映收敛情况。
使用Tensorboard工具保存网络各个层的图像,图6给出了双输入卷积conv-3层的特征结果,其中,conv-3提取的特征矩阵的维度为:16×16×256,也就是形成了16×16像素、深256层的特征矩阵。图6中,图(a)给出了上输入流conv-3卷积层的深度维为5、6、7层的特征切片图像,图(b)则给出了下输入流conv-3卷积层的深度维2、3、4层的特征切片图,从中可以看出,卷积层提取了目标物的特征,并形成了稀疏化的特征。
图7中给出了反卷积生成新参数条件下,各个逆卷积层的图像,利用Tensorboard保存各层逆卷积的结果。图7中的输入为测试集中的桌椅的图片和新的视角,图中具体为:
v =(sinα,cosα,sinβ,cosβ,θ)
其中:α=20π/180, β=46π/180, θ =[0,0,0,0]。
从图7可以看出,根据提取的特征,基于反卷积技术,逐渐生成了目标图像。
4.2 实验2:生成新数据提高识别能力实验
现有的神经网络在人工目标识别的方面表现优异的原因就在于其“见得多”,也就是基于一个庞大的训练集。深度学习神经网络识别率高的主要原因在于:1)训练集足够大;2)网络足够深,节点足够多。
从而,在“见得多”的情况下,将图像的特征提取函数映射为网络权值。所以,利用生成的新样本扩充训练集,将有助于提高网络的识别率。
为了进一步验证生成数据提高网络识别能力的特性,进行以下比对实验:
1)将ShapeNetCore数据库进行前期处理,图像原尺寸为600×600@3像素,其边框包含较大的空白区域。在前期处理过程中,去除了白色边缘部分后图像尺寸为256×256@3,再修改尺寸为128×128@3。
2)将ShapeNetCore数据库按照类别进行标识,该数据库共有1393种类别,每隔一个角度剔除四张作为测试数据。
3)在标识好的训练集进行迭代训练,并利用测试数据测试识别率。
4)利用本文生成神经网络生成2)中剔除的图像,扩充训练集,进行迭代训练。
5)利用测试数据比对识别率,验证识别效果。
表1给出了基于正常训练集和本文方法扩充的训练集的网络识别率,其数据集均基于ShapeNetCore。
从表1中可以看出,基于正常训练集的神经网络在面对扩充库时识别率下降;而通过扩充训练数据集,卷積神经网络针对扩充库的识别率明显得到提升。可以得出,本文神经网络的后半部分(FC4、uconv-1~uconv-4)就是卷积神经网络的后半部分,可以将网络倒置,完成对图像的分类识别。
5 结语
在深度学习人工智能领域,优异的性能通常取决于一个大样本空间的训练集,本文提出了一个双输入的神经网络架构,该网络前半部分利用卷积网络提取图像的特征,后半部分利用反卷积在新设定的条件下生成目标的图像。该网络可产生新角度、新尺寸等图像,将产生的图像用于扩充训练集,可有效提升神经网络的识别能力。
但该网络也未能克服现有神经网络理论的束缚,对同类目标物的产生效果较好,对于异类的目标物图像插值问题则无法很好地完成,与人脑产生图像的能力存在较大的差距,所以需要进一步研究具有推理生成的网络。
参考文献
[1] DING J, CHEN B, LIU H, et al. Convolutional neural network with data augmentation for SAR target recognition [J]. IEEE Geoscience and Remote Sensing Letters, 2016, 13(3):364-368.
[2] 林懿倫,戴星原,李力,等.人工智能研究的新前线:生成式对抗网络[J].自动化学报,2018,44(5):775-792. (LIN Y L, DAI X Y, LI L, et al. The new frontier of AI research: generative adversarial networks[J]. Acta Automatica Sinica, 2018, 44(5): 775-792.)
[3] 朱俊鹏, 赵洪利, 杨海涛. 基于卷积神经网络的视差图生成技术[J]. 计算机应用, 2018, 38(1):255-259. (ZHU J P, ZHAO H L, YANG H T. Disparity map generation technology based on convolutional neural network[J]. Journal of Computer Applications, 2018, 38(1):255-259.)
[4] 陈文兵,管正雄,陈允杰.基于条件生成式对抗网络的数据增强方法[J].计算机应用,2018,38(11):3305-3311. (CHEN W B, GUAN Z X, CHEN Y J. Data augmentation method based on generative adversarial network model [J]. Journal of Computer Applications, 2018, 38(11): 3305-3311.)
[5] HINTON G E, SALAKHUTDINOV R R. Reducing the dimensionality of data with neural networks [J]. Science, 2006, 313(5786): 504-507.
[6] SALAKHUTDINOV R R, HINTON G E. Deep Boltzmann machines [C/OL]// Proceedings of the 12th International Conference on Artificial Intelligence and Statistics, 2009 [2018-12-09]. http://proceedings.mlr.press/v5/salakhutdinov09a/salakhutdinov09a.pdf.
[7] BENGIO Y, THIBODEAU-LAUFER , ALAIN G, et al. Deep generative stochastic networks trainable by backprop [C/OL]// Proceedings of the 31st International Conference on Machine Learning, 2014 [2014-05-24]. https://arxiv.org/abs/1306.1091. [J]. arXiv E-print, 2014: arXiv:1306.1091.
[8] REZENDE D J, MOHAMED S, WIERSTRA D. Stochastic backpropagation and approximate inference in deep generative models [J]. arXiv E-print, 2014: arXiv:1401.4082. [J/OL]. [2014-05-30]. https://arxiv.org/abs/1401.4082.
[9] KINGMA D P, WELLING M. Auto-encoding variational Bayes [J]. arXiv E-print, 2014: arXiv:1312.6114. [J/OL]. [2014-05-01]. https://arxiv.org/abs/1312.6114.
[10] DOSOVITSKIY A, SPRINGENBERG J T, TATARCHENKO M, et al. Learning to generate chairs, tables and cars with convolutional networks [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(4): 692-705.
[11] GOODFELLOW I J, POUGET-ABADIE J, MIRZA M, et al. Generative adversarial nets [C]// Proceedings of the 27th International Conference on Neural Information Processing Systems. Cambridge, MA: MIT Press, 2014: 2672-2680.
[12] ZHU Z, LUO P, WANG X, et al. Multi-view perceptron: a deep model for learning face identity and view representations [C]// Proceedings of the 27th International Conference on Neural Information Processing Systems. Cambridge, MA: MIT Press, 2014: 217-225.
[13] LI F-F. Knowledge transfer in learning to recognize visual objects classes [C]// Proceedings of the 2006 International Conference on Development and Learning. Washington, DC: IEEE Computational Intelligence Society, 2006: 1-51. http://pdfs.semanticscholar.org/35a1/98cc4d38bd2db60cda96ea4cb7b12369fd3c.pdf
[14] LI F, ROB F, PIETRO P. One-Shot learning of object categories[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2006, 28(4): 594-611.
[15] SANTORO A, BARTUNOV S, BOTVINICK M, et al. Meta-learning with memory-augmented neural networks [C]// Proceedings of the 33rd International Conference on Machine Learning. New York: International Machine Learning Society, 2016, 48: 1842-1850. https://docplayer.net/31411874-Meta-learning-with-memory-augmented-neural-networks.html
[16] ANDRYCHOWICZ M, DENIL M, COLMENAREJO S G, et al. Learning to learn by gradient descent by gradient descent [C]// Proceedings of the 30th Conference on Neural Information Processing Systems. La Jolla, CA: Neural Information Processing Systems Foundation, 2016: 3981-3989.
[17] RAVI S, LAROCHELLE H. Optimization as a model for few-shot learning [C/OL]// Proceedings of the 5nd International Conference on Learning Representations. 2017 [2018-10-24]. https://openreview.net/pdf?id=rJY0-Kcll.
