基于Movidius神经计算棒的行人检测方法
2019-10-23张洋硕苗壮王家宝李阳
张洋硕 苗壮 王家宝 李阳

摘 要:Movidius神经计算棒是基于USB模式的深度学习推理工具和独立的人工智能加速器,为广泛的移动和嵌入式视觉设备提供专用深度神经网络加速功能。针对深度学习的嵌入式应用,实现了一种基于Movidius神经计算棒的近实时行人目标检测方法。首先,通过改进RefineDet目标检测网络结构使模型大小和计算适应嵌入式设备的要求;然后,在行人检测数据集上对模型进行重训练,并部署于搭载Movidius神经计算棒的树莓派上;最后,在实际环境中对模型进行测试,算法达到了平均每秒4帧的处理速度。实验结果表明,基于Movidius神经计算棒,在计算资源紧张的树莓派上可完成近实时的行人检测任务。
关键词:行人检测;深度学习;树莓派;Movidius;嵌入式设备
中图分类号: TP183; TP391.4
文献标志码:A
Pedestrian detection method based on Movidius neural computing stick
ZHANG Yangshuo*, MIAO Zhuang, WANG Jiabao, LI Yang
College of Command and Control Engineering, Army Engineering University, Nanjing Jiangsu 210007, China
Abstract: Movidius neural computing stick is a USB-based deep learning inference tool and a stand-alone artificial intelligence accelerator that provides dedicated deep neural network acceleration for a wide range of mobile and embedded vision devices. For the embedded application of deep learning, a near real-time pedestrian target detection method based on Movidius neural computing stick was realized. Firstly, the model size and calculation were adapted to the requirements of the embedded device by improving the RefineDet target detection network structure. Then, the model was retrained on the pedestrian detection dataset and deployed on the Raspberry Pi equipped with Movidius neural computing stick. Finally, the model was tested in the actual environment, and the algorithm achieved an average processing speed of 4 frames per second. Experimental results show that based on Movidius neural computing stick, the near real-time pedestrian detection task can be completed on the Raspberry Pi with limited computing resources.
Key words: pedestrian detection; deep learning; Raspberry Pi; Movidius; embedded device
0 引言
行人检测是目标检测的重要分支,可用于多种不同领域,如视频监控、人员识别和智能汽车驾驶系统。在现实生活中,由于视频或图像中行人姿态、物体遮挡、服装、灯光变化和复杂背景的多样性,行人检测在计算机视觉中仍是一个具有挑战性的任务。近年来,深度学习极大地推动了行人检测技术的发展,在计算机视觉领域引起了广泛的关注;但是,深度学习中的行人检测模型在面向实际应用时还存在着诸多问题亟待解决。
行人檢测根据处理过程一般可以分解为生成候选窗口、特征提取和特征分类三个步骤。经典的行人检测方法通常使用基于滑动窗口的方法生成候选窗口,使用梯度方向直方图(Histogram of Oriented Gradients, HOG)[1]或尺度不变特征变换(Scale-Invariant Feature Transform, SIFT)[2]作为特征,并使用支持向量机(Support Vector Machine, SVM)或自适应集成分类器(AdaBoost)作为特征分类方法;但这些方法大多基于手工特征,刻画的是低层次信息,缺乏对行人高层次语义信息的描述。近年来,随着深度学习技术的发展,深度神经网络已被广泛应用于行人检测任务。与传统方法不同的是,深度学习通过深层卷积网络操作抽取图像的高级语义信息来描述行人,具有更好的描述能力。与此同时,伴随计算机硬件性能的不断提高,行人检测算法也在不断优化。郭爱心等[3]在更快、更富有特征层次的卷积神经网络(Faster Regions with Convolutional Neural Network feature, Faster R-CNN)通用目标检测框架[4]的基础上,针对行人特点提出了行人区域建议网络;针对小尺度行人特征信息不足,提出了多层次特征提取和融合的方法;陈光喜等[5]通过设计一个网络与统一的实时监测目标检测YOLOv2(You Only look Once)网络[6]级联,解决了复杂环境下行人检测不能同时满足高召回率与高效率检测的问题;徐超等[7]提出一种改进的基于卷积神经网络的行人检测方法,使卷积神经网络能选择出更优模型并获得定位更准确的检测框;Hosang等[8]使用SquaresChnFtrs方法生成行人候选窗口并训练AlexNet[9]进行行人检测;Zhang等[10]使用区域提议网络(Region Proposal Network, RPN)[4]来计算行人候选区域和级联Boosted Forest[11]以执行样本重新加权来对候选区域进行分类;Li等[12]训练多个基于Fast R-CNN[13]的网络来检测不同尺度的行人,并结合所有网络的结果以产生最终结果。虽然上述工作对行人检测进行很多探索,但是在面对实际应用时,卷积网络模型还存在着模型大小、计算耗时等方面的问题。
本文将行人检测算法放在搭载Movidius神经计算棒(Neural Computational Stick, NCS) 的树莓派上,来实现行人的快速检测。树莓派是一种计算资源紧张的设备,因此本文采用深度可分卷积对高精度的RefineDet网络[14]进行改进,构建轻量级卷积神经网络。该网络在选定的嵌入式视觉设备(Raspberry PI 3板)上的平均处理速度达到4帧/s(Frames Per Second, FPS)。考虑到有限的计算能力,它符合设计目标。因此,实时行人检测任务可以通过仅执行4FPS的检测算法来完成。
本文的主要工作如下:
1)针对移动和嵌入式视觉设备的智能监控,对RefineDet检测网络进行改进,构建一种轻量级卷积神经网络;
2)使用该网络在资源受限的搭载Movidius神经计算棒的树莓派3上运行,以实现嵌入式设备的实时行人检测。
1 改进的行人检测网络
1.1 行人检测网络框架
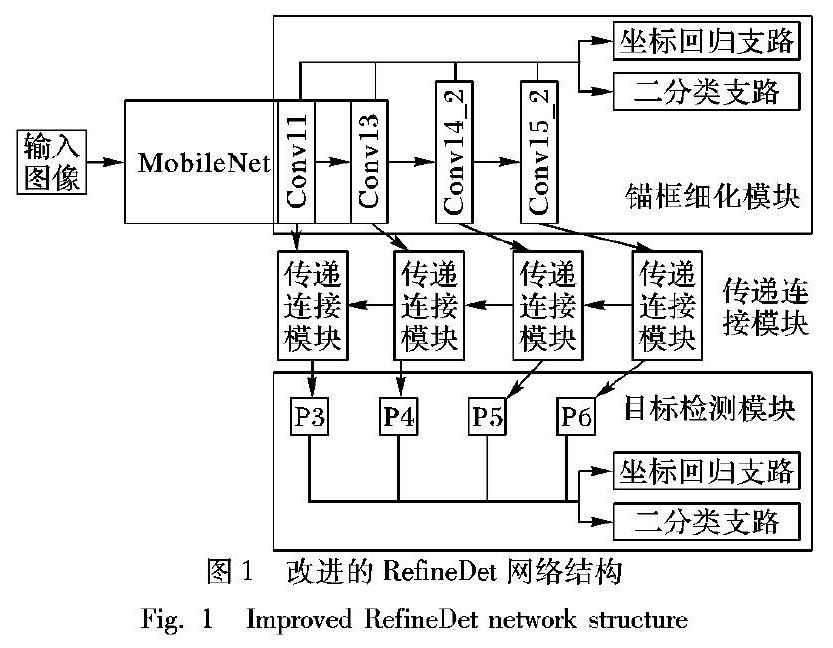
为了提高嵌入式视觉设备上运行目标检测模型的效率,本文基于高精度的RefineDet,引入高效的深度可分卷积操作,采用类似MobileNet[15]结构来构建骨干网络,改进后的L-RefineDet网络架构如图1所示。
该网络架构主要包含三个部分:锚框细化模块、传递连接模块和目标检测模块。锚框细化模块主要用来得到粗粒度的边界框信息和去除一些负样本,只对物体进行初步的分类和回归,且分类只区分前景和背景;传递连接模块是用于特征转换操作。对高层次的特征进行反卷积操作,使得特征图之间的尺寸匹配,然后与低层次的特征相加,使锚框细化模块特征转化为目标检测模块特征。目标检测模块用于将输入的多层特征进行进一步的回归和预测多分类标签。
网络架构采用MobileNet[15]中的conv11、conv13并在后面增加两个卷积层Conv14_2,Conv15_2,共4个特征层作为特征抽取层,以获得不同尺寸的特征。提取特征后进行融合操作,首先是Conv15_2特征层经过一个传递连接模块得到对应大小的矩形块(P6),接着基于Conv14_2的矩形块经过传递连接模块得到对应大小的矩形块(P5),此处的传递连接模块相比P6增加了反卷积支路,反卷积支路的输入来自于生成P6的中间层输出。P4和P3的生成与P5同理。
整体来看,一个子模块提取粗粒度的边界框信息,另一个子模块进行细粒度的分类任务,因此能有更高的准确率,而且采用了特征融合,该算法对于小目标物体的检测更有效。
1.2 网络结构
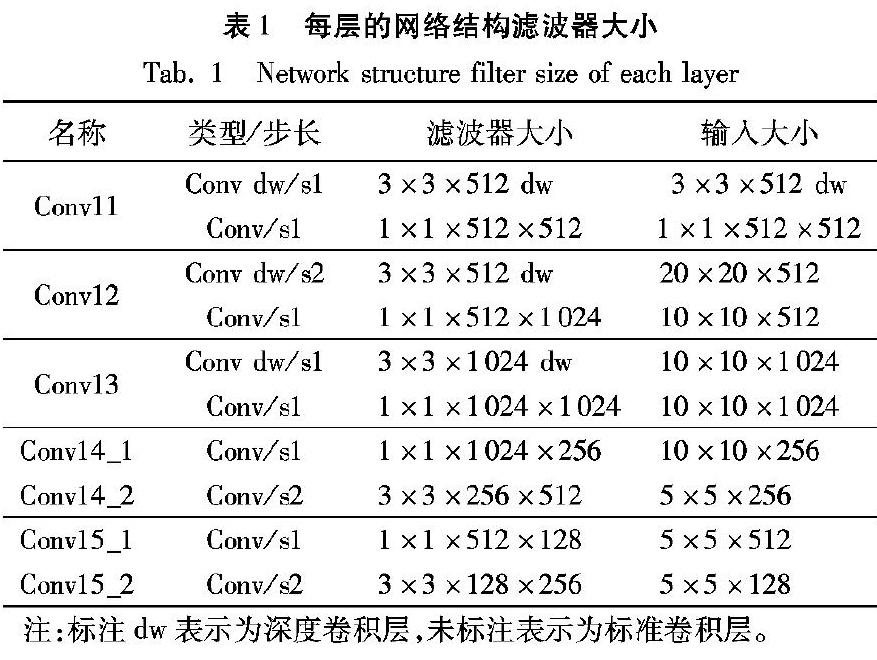
网络的输入图像尺寸为320×320,表1描绘了每层的网络结构滤波器大小,其中Conv0至Conv13与MobileNet[15]中结构相同。为了处理不同尺寸的物体,总共提取4层特征用作检测,即表1中名称为Conv11、Conv13、Conv14_2、Conv15_2的特征层,尺寸分别是20×20、10×10、5×5、3×3。每个特征层与不同尺度的锚框相匹配,其中不同层次的锚框采用
单发多框目标检测器 (Single Shot multibox Detector, SSD)[16]三种纵横比设计。
为了增强模型的鲁棒性,模型训练时采用了随机扩展、裁剪和翻转等数据增强策略。在匹配步骤后,大多数锚框是负面的,为了缓解正负样本不平衡问题,网络的正负样本界定的标准基本上和其他目标检测算法类似,和真实的标注的交并比(Intersection-over-Union, IoU)超过阈值0.5的边界框为正样本,负样本是根据边界框的分类损失来选的,对分类损失进行降序排列,按照正负样本1∶ 3的比例选择损失靠前的负样本。
1.3 深度可分卷积
改进网络架构中的关键是深度可分卷积[15],因为它极大地降低了算法的复杂度,适用于嵌入式设备的应用。深度可分卷積[2]通过将每个常规卷积层分成两部分:深度卷积层(depthwise convolution)和逐点卷积层(pointwise convolution),使计算复杂度更适合于的移动智能设备,其体系结构如图2所示。
图2比较了深度可分卷积和传统卷积。传统卷积输入 F ∈ R Df×Df×M,其中Df×Df为图像或特征图大小和M输入通道的个数;输出 G ∈ R Dg×Dg×M,其中Dg×Dg为输出特征图大小,N为输出通道的个数。计算过程涉及到滤波器 K ∈ R Dk×Dk×M×N,其中Dk×Dk为滤波器核大小,M和N分别对应输入和输出通道的个数。计算过程如式(1):
G k,l,n=∑ i, j,m K i, j,m,n⊙ F k+i-1,l+j-1,m
(1)
式(1)的计算复杂度如式(2):
O(conv)=Dk×Dk×M×N×Df×Df
(2)
深度可分卷积由两部分组成:一个是深度卷积层,该层由M个滤波器{ K m∈ R Dk×Dk×1,m=1,2,…,M}组成,输入 F ∈ R Df×Df×M,对每个通道计算输出:
G m∈ R Dg×Dg×1; m=1,2,…,M
(3)
对M个输出在第3个维度拼接:
G ′=cat ([ G 1, G 2,…, G M])∈ R Df×Df×M
(4)
另一个是逐点卷积层,该层由滤波器
Y ^
∈ R 1×1×M×N组成,输入 G ′∈ R Df×Df×M,输出N个通道的特征图结果 G ^ ∈ R Df×Df×N,计算过程如式(5):
G ^ k,l,n=∑ i, j,m
K ^ i, j,m,n
⊙ F k+i-1,l+j-1,m
(5)
深度可分卷积的计算复杂度如式(6):
O(depth)= Dk×Dk×M×N×Df×Df+N×M×Df×Df
(6)
深度可分卷积在每个卷积步骤之后,均接有一个批量标准化层和一个非线性激活的ReLU层。
基于式(2)和式(6),深度可分卷积和传统卷积计算复杂度比较如式(7):
O(conv) O(depth) = 1 N + 1 D2k
(7)
深度可分卷积使网络变得更快、更高效,非常适合移动和嵌入式视觉设备。
2 基于神经计算棒的行人检测
2.1 实验装置
2.1.1 树莓派
上述改进模型最终部署于嵌入式视觉设备上,本文选用树莓派3B+开发版,该开发板具备ARM v7 1.2 GHz处理器和1 GB RAM,计算能力一般,但其成本低、应用广。
2.1.2 英特尔神经计算棒
树莓派计算能力有限,为了提升所提深度行人检测模型的计算效率,采用Movidius神经计算棒加速计算。NCS是英特尔推出的基于USB模式的加速设备,为计算能力不足的移动和嵌入式视觉设备提供深度学习加速功能。NCS不需要连接到云端,可以直接在本地编译、部署,实现神经网络计算加速。Movidius神经计算棒内置的Myriad 2 VPU提供了强大且高效的性能,支持在Tensorflow和Caffe框架上直接运行神经网络。
2.2 开发应用流程
本文采用Caffe框架来训练模型,部署到搭载Movidius神经计算棒的树莓派上。NCS的环境分为两部分:训练端和测试端。
1) 训练端为一台带GPU加速的主机,训练Caffe模型,并编译成NCS可以执行的graph;
2) 测试端为一台搭载Movidius的树莓派开发板,运行编译好的graph格式模型以检测行人。
具体开发应用流程如图3所示,主要包括三个步骤。
步骤1 训练。收集行人数据集,并在带GPU运算能力的工作站或者服务器上进行训练,得到Caffe格式的行人检测模型。
步骤2 编译。NCS的VPU无法直接运行步骤1中训练的Caffe模型,需要将模型转化为VPU支持的专用文件格式(graph)。NCS提供了专门的工具,用于编译、优化Caffe模型。
步骤3 预测。在树莓派3B+嵌入式设备上部署graph格式行人检测模型,加载graph文件到NCS执行行人检测。
步骤1和2通常在運行在训练端,除训练Caffe模型外,还安装NCSDK编译模块mvNCCompile,用于将Caffe模型转成NCS的graph;步骤3运行在测试端,安装inference模块,用来支持graph的运行。
2.3 模型训练
标注完善、图像质量高的PASCAL VOC数据集是计算机视觉领域中著名的数据集之一,包含日常生活中常见的20个类别,person就是其中一类。本文采用的数据集是基于PASCAL VOC 2007和PASCAL VOC 2012数据集提取只有person类别的目标图片制作而成的VOC_person数据集,最终一共包含8000张训练图片和2600张验证图片,并将数据集转化为LMDB格式文件以加快读取速度。
本文使用Caffe深度学习框架来训练模型。Caffe是一个高效的深度学习框架,支持命令行、Python以及Matlab程序接口。在训练之前,通过计算每个RGB通道的平均值来对数据进行归一化。所提出的模型采用随机梯度下降法(Stochastic Gradient Descent, SGD)进行训练,动量为0.9,衰减因子为00005。初始学习率为0.005,并使用multistep学习率衰减策略。在显存为11GB的NVIDIA GTX1080Ti上训练,整个训练过程为200000次迭代。最终训练出的权重文件大小可由302.6MB减小为62.6MB。
2.4 模型测试
将训练好的caffemodel权重文件通过mvNCCompile模块编译成NCS 可执行的graph,在测试端上进行测试。将graph加载到NCSDK中,推断得到目标位置、类别、分数。
3 实验结果与分析
实验使用的检测性能评价指标是平均每幅图像误检率(False Positive Per Image, FPPI)[17],计算公式如下:
FPPI=FP/Nimg
(8)
其中: FPPI表示误检总数;Nimg表示测试图片总数。
表2显示了本文算法L-RefineDet与其他行人检测方法测试结果比较。其中包括不同算法在VOCperson数据集上的测试对比;不同算法在搭载Movidius的树莓派上平均处理速度比较。
表2是本文算法L-RefineDet与其他行人检测方法的测试结果。从实验数据可以看出,本文算法L-RefineDet在VOCperson数据集上的FPPI为0.27,在搭载Movidius的树莓派上平均处理速度达到4FPS,与其他行人检测方法相比具有更高的精度和更快的速度。
表3是本文算法L-RefineDet与其他检测模型大小的比较。与不采用深度可分卷积的RefineDet方法相比,本文算法L-RefineDet的模型更小,表明深度可分卷积能够极大地降低算法的复杂度。
图4为使用MobileNet-SSD检测实时场景中行人的效果,图5为改进的轻量级网络在搭载Movidius神经计算棒的树莓派上处理实时场景中行人的效果,其中包括不同距离和角度的行人检测、遮挡的行人检测。
由图4、5可以看出,从不同角度和距离捕捉人体对象对检测算法具有很大挑战,当角度和距离不同时,不仅特征有所不同,而且有时人体只是部分可见或以不同的姿势出现。MobileNet-SSD会对一些特殊角度的行人和小目标行人出现漏检,同时对重叠行人出现漏报,L-RefineDet对行人检测具有更好的鲁棒性。 例如图5(a)、(b)中,表明网络对于小目标行人和不同角度的行人也有很好的检测效果。图5(c)中,表明网络能够区分重叠的行人。图5(d)中,表明网络能够检测出球门遮挡的行人。
4 结语
本文在嵌入式视觉设备下进行行人检测的背景下,改进了一种轻量级的人体目标检测算法,并在搭载Movidius神经计算棒的树莓派上运行。实验结果表明该算法已经达到了设计目标,取得了令人满意的检测速度和高准确度。但是单根NCS一次只能运行一个模型,可以考虑用多根NCS、多线程做检测,以达到更高的速度。
参考文献
[1] TRIGGS B, DALAL N. Histograms of oriented gradients for human detection [C]// Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2005: 886-893.
[2] LOWE D G. Object recognition from local scale-invariant features [C]// Proceedings of the 7th IEEE International Conference on Computer Vision. Piscataway, NJ: IEEE, 1999: 1150-1157.
[3] 郭爱心,殷保群,李运.基于深度卷积神经网络的小尺度行人检测[J].信息技术与网络安全,2018,37(7):50-53, 57. (GUO A X, YIN B Q, LI Y. Small-size pedestrian detection via deep convolutional neural network [J]. Information Technology and Network Security, 2018, 37(7): 50-53, 57.)
[4] REN S, HE K, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6):1137-1149.
[5] 陳光喜,王佳鑫,黄勇,等.基于级联网络的行人检测方法[J].计算机应用,2019,39(1):186-191. (CHEN G X, WANG J X, HUANG Y, et al. Pedestrian detection method based on cascade networks [J]. Journal of Computer Applications, 2019, 39(1): 186-191.)
[6] REDMON J, FARHADI A. YOLO9000: better, faster, stronger [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2017: 6517-6525.
[7] 徐超,闫胜业.改进的卷积神经网络行人检测方法[J].计算机应用,2017,37(6):1708-1715. (XU C, YAN S Y. Improved pedestrian detection method based on convolutional neural network [J]. Journal of Computer Applications, 2017,37(6): 1708-1715.)
[8] BENENSON R, OMRAN M, HOSANG J, et al. Ten years of pedestrian detection, what have we learned? [C]// Proceedings of the 2014 European Conference on Computer Vision, LNCS 8926. Berlin: Springer, 2014: 613-627.
[9] KRIZHEVSKY A, SUTSKEVER I, HINTON G E. ImageNet classification with deep convolutional neural networks [C]// Proceedings of the 2012 International Conference on Neural Information Processing Systems. North Miami Beach, FL: Curran Associates Inc, 2012: 1097-1105.
[10] ZHANG L, LIN L, LIANG X, et al. Is Faster R-CNN doing well for pedestrian detection? [C]// Proceedings of the 2016 European Conference on Computer Vision, LNCS 9906. Cham: Springer, 2016: 443-457.
[11] APPEL R, FUCHS T, DOLLR P. Quickly boosting decision trees: pruning underachieving features early [C]// Proceedings of the 30th International Conference on Machine Learning. [S.l.]: JMLR, 2013, 28: III-594-III-602.
[12] LI J, LIANG X, SHEN S, et al. Scale-aware Fast R-CNN for pedestrian detection [J]. IEEE Transactions on Multimedia, 2018, 20(4): 985-996.
[13] GIRSHICK. R. Fast R-CNN [C]// Proceedings of the 2015 IEEE International Conference on Computer Vision. Piscataway, NJ: IEEE, 2015: 1440-1448.
[14] ZHANG S, WEN L, BIAN X, et al. Single-shot refinement neural network for object detection [C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2018: 4203-4212.
[15] HOWARD A G, ZHU M, CHEN B, et al. MobileNets: efficient convolutional neural networks for mobile vision applications [J]. arXiv E-print, 2017: arXiv:1704.04861. [2018-09-10]. https://arxiv.org/pdf/1704.04861.pdf.
[16] LIU W, ANGUELOV D, ERHAN D, et al. SSD: single shot multibox detector [C]// Proceedings of the 2016 European Conference on Computer Vision, LNCS 9905. Cham: Springer, 2016: 21-37.
[17] WOJEK C, DOLLAR P, SCHIELE B, et al. Pedestrian detection: an evaluation of the state of the art [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2012, 34(4): 743-761.
