基于双重金字塔网络的视频目标分割方法
2019-10-23姜斯浩宋慧慧张开华汤润发
姜斯浩 宋慧慧 张开华 汤润发

摘 要:针对复杂视频场景中难以分割特定目标的问题,提出一种基于双重金字塔网络(DPN)的视频目标分割方法。首先,通过调制网络的单向传递让分割模型适应特定目标的外观。具体而言,从给定目标的视觉和空间信息中学习一种调制器,并通过调制器调节分割网络的中间层以适应特定目标的外观变化。然后,通过基于不同区域的上下文聚合的方法,在分割网络的最后一层中聚合全局上下文信息。最后,通过横向连接的自左而右结构,在所有尺度中构建高阶语义特征图。所提出的视频目标分割方法是一个可以端到端训练的分割网络。大量实验结果表明,所提方法在DAVIS2016数据集上的性能与较先进的使用在线微调的方法相比,可达到相竞争的结果,且在DAVIS2017数据集上性能较优。
关键词:视频目标分割;特征金字塔;卷积神经网络;深度学习;多尺度融合
中图分类号: TP391.41
文献标志码:A
Video object segmentation method based on dual pyramid network
JIANG Sihao, SONG Huihui*, ZHANG Kaihua, TANG Runfa
Jiangsu Key Laboratory of Big Data Analysis Technology (Nanjing University of Information Science and Technology), Nanjing Jiangsu 210044, China
Abstract: Focusing on the issue that it is difficult to segment a specific object in a complex video scene, a video object segmentation method based on Dual Pyramid Network (DPN) was proposed. Firstly, the one-way transmission of modulating network was used to make the segmentation model adapt to the appearance of a specific object, which means, a modulator was learned based on visual and spatial information of target object to modulate the intermediate layers of segmentation network to make the network adapt to the appearance changes of specific object. Secondly, global context information was aggregated in the last layer of segmentation network by different-region-based context aggregation method. Finally, a left-to-right architecture with lateral connections was developed for building high-level semantic feature maps at all scales. The proposed video object segmentation method is a network which is able to be trained end-to-end. Extensive experimental results show that the proposed method achieves results which can be competitive to the results of the state-of-the-art methods using online fine-tuning on DAVIS2016 dataset, and outperforms other methods on DAVIS2017 dataset.
Key words: video object segmentation; feature pyramid; Convolutional Neural Network (CNN); deep learning; multi-scale fusion
0 引言
視频目标分割是从视频序列中分离出前景目标,这是视频分析和编辑中最重要的任务之一。尽管在许多情况下目标的刻画和跟踪对人类来说似乎微不足道,但由于视频中存在运动模糊、混乱背景以及遮挡等情况,因此导致视频目标分割仍然非常具有挑战性。
近期深度网络有效解决了上述问题,主要包含无监督和半监督两类。无监督分割旨在以全自动方式分割前景目标而无需用户标注[1]。信息的主要来源包括视觉显著性和运动差异(例如光流[2]和长期轨迹[3])。本文提出的方法属于半监督视频目标分割,所以本文重点介绍半监督分割方法。
基于传播的视频目标分割[4-5]是一类常见的半监督分割算法。传统视频分割方法始于粗略地指定感兴趣目标的标注(例如分割掩码或关键帧处的涂鸦),并且通常在整个视频序列中使用图形表示[4]来传播这些稀疏标签。最近流行的方法是通过深度学习(deep learning)[6]在视频中进行标签传播;Jampani等[7]提出了一个用于时空密集滤波的时间双边网络;Perazzi等[5]只通过静态图像训练一个深度网络来细化前一帧掩码,并且在测试中使用测试视频的第一帧来记忆目标的外观(即在线微调),从而提升了性能;Khoreva等[8]通过大量数据增强策略来实现更高的分割精度。
另外一类半监督分割算法是基于检测的视频目标分割[9-11]。Caelles等[9]首先利用了一次在线微调,在测试过程中对已离线训练的模型再次进行微调,并使用微调后的网络作为测试模型,从而提高了分割性能;Maninis等[10]通过结合来自辅助实例分割网络[12]的额外信息扩展了文献[9]的想法;Voigtlaender等[13]通过采用源于框级跟踪的在线自适应机制,进一步拓展了文献[9]的想法。
在上述两类方法中大多数都采用在线微调。具体来说,让预先训练的深度网络在测试视频上进行了微调,从而让网络适应目标的外观变化来提高分割的准确性[5,8-11,13-14],但高昂的计算代价限制了它的实际使用。
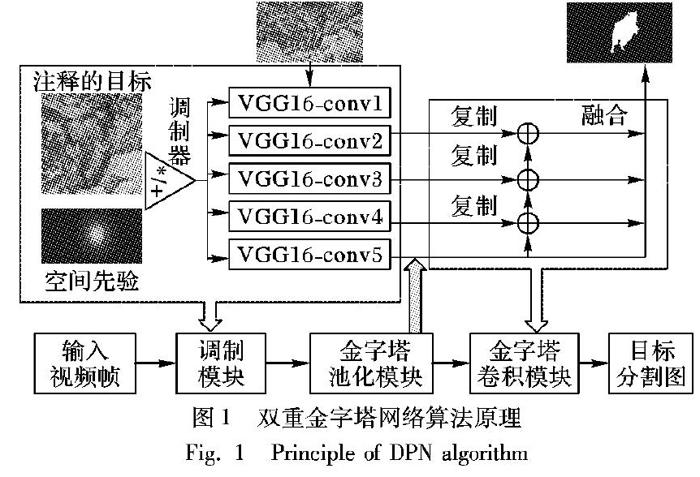
针对上述问题,本文设计了一种用于半监督视频目标分割的双重金字塔网络(Dual Pyramid Network, DPN)。如图1所示,本文首先利用调制模块生成调制参数,从而让分割网络聚焦到给定目标的位置;然后,通过金字塔池化模块聚合不同区域的上下文信息;最后,通过金字塔卷积模块将高层语义特征融入到底层特征中。大量实验结果表明,本文所提方法可以在不加入在线微调(fine-tuning)以保证效率的前提下获得相对优异的性能,同时加入在线微调可进一步提高分割精度。
1 基于双重金字塔网络的视频目标分割
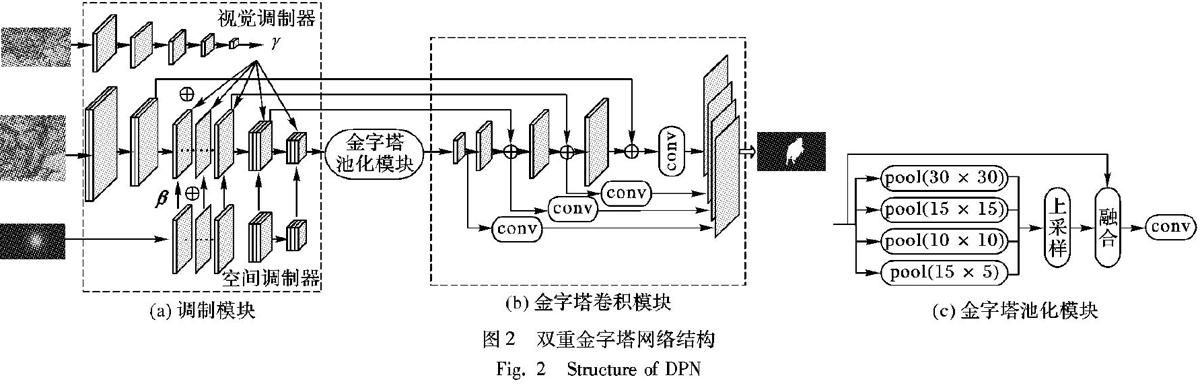
本文所提出的基于双重金字塔网络的视频目标分割方法主要包括三个部分:调制模块(Modulation Module)、金字塔池化模块(Pyramid Pooling Module)和金字塔卷积模块(Pyramid Convolution Module)。具体网络结构如图2所示。
1.1 调制模块
调制模块采用OSMN[15]的结构,主要由三个部分组成:分割网络(Segmentation Network)、视觉调制器(Visual Modulator)和空间调制器(Spatial Modulator),具体结构如图
2(a)所示。
分割网络是基于VGG16[16]的全卷积网络,且在除了VGG16的前四层外的所有卷积层中添加调制操作,具体的调制过程和参数如下:
视觉调制器用于使分割网络适应给定目标的外观,从给定注释帧中提取语义信息,例如,类别、颜色、形状和纹理,并且生成对应通道的尺度参数以调整特征图中不同通道的权重,从而在分割网络中重新定位给定目标的位置[14]。本文使用VGG16神經网络作为视觉调制器模型将第一帧图片围绕目标裁剪为224×224像素大小作为输入,并且修改最后一层用于分类的层,以匹配分割网络调制层中的参数数目。所有视觉调制参数都与特征图相乘,具体表达式如式(1)所示。
空间调制器生成像素级偏移参数,目的是为了在目标对象的位置上提供粗略的先验信息,其作用类似于空间注意机制[17]。本文先在前一帧的预测掩码上生成二维热图,从而获得目标位置的粗略估计,再将其作为空间调制器的输入。为了匹配分割网络中不同特征图的分辨率,空间调制器将二维热图下采样为不同的尺度,进而获得对应于每个卷积层的空间位移参数。空间调制参数与相应层的特征图相加,其表达式如下所示:
F c=γc⊙ f c+ β c
(1)
其中:γc和 β c分别表示视觉调制器和空间调制器生成的参数,γc是一个对应于通道权重的标量, β c是一个对应于像素偏移的两维矩阵; f c和 F c分别表示第c个通道的输入和输出特征图;⊙表示对应元素点乘。
1.2 金字塔池化模块
金字塔池化模块通过不同区域的上下文聚合来达到获取全局信息的目的,其结构如图2(c)所示。与U-Net[18]的不同之处在于,本文将分割网络的最后一层特征图作为金字塔池化模块的输入,并分别进行4种不同金字塔尺度的池化(pool)来提取不同感受野(receptive field)的信息。本文使用的池化核大小根据输入特征图的分辨率分别设置为30×30、15×15、10×10、5×5。为了保证全局特征的权重,本文在每个池化后的特征图后面使用1×1的卷积将其通道降为原来的1/4,再通过双线性插值将不同的金字塔尺度恢复到未池化前的分辨率大小,并与原输入特征图进行串联(concat)操作。由于该模块聚合了不同区域的上下文信息,有效实现了获取全局信息的目的,因此,能进一步提高网络的分割性能。
1.3 金字塔卷积模块
全卷积网络的底层特征具有高分辨率特性,而高层特征则具有大感受野和强语义的特性,两者对于准确分割目标都具有重要作用。本文通过横向连接的自左而右的结构,将高层的强语义信息与底层特征融合,从而构成金字塔卷积模块,具体结构如图2(b)所示。具体来说,本文对高层的特征图进行上采样操作,将其空间分辨率放大两倍,同时底层特征图经过1×1卷积层,让其通道数和高层特征图的通道数相同,再将两者进行像素相加操作。由于输出分割图的通道数为1,显然直接将大通道数降为1会损失很多信息从而影响网络的分割性能,所以本文通过1×1卷积层将其通道数降为16后再直接上采样到原图大小。最后,金字塔卷积模块融合第2、3、4、5层上采样到原图大小的特征图,再经过一次卷积得到最终的目标分割图。与U-Net[18]的不同之处在于,该模块的预测目标掩码需要融合4层上采样到原图大小的特征信息,而U-Net[18]只在最后一层提取特征信息,然后直接得到预测目标掩码。该模块一方面通过高分辨率特征图使得网络更加关注小目标的信息,另一方面通过融合多尺度信息使得网络能够更有效地应对目标外观的变化。
由于前景和背景像素个数的不均衡性,本文使用加权的交叉熵损失函数[9,15]来处理这种像素个数不均衡问题,其表达式如下所示:
L(θ)= -w∑ i, j∈Y+ lnP(yij=1;θ)-(1-w)∑ i, j∈Y- lnP(yij=0;θ)
2)金字塔卷积模块虽然在单目标分割的任务中效果甚微,但在多目标分割的任务中有效弥补了金字塔池化模块的不足,mIoU提高了2个百分点。这表明将高层语义信息逐步融合到底层特征中能够有效弥补底层边缘纹理信息中语义信息的缺失,从而进一步提高了多目标的分割性能。
为了证明金字塔卷积模块中如何更有效地对高层和底层特征进行融合,本文分别对U-Net[18]中的串联操作以及文献[23]中的像素相加操作进行了实验。通过在DAVIS2016数据集测试的对比结果发现,利用串联操作的方法精度只有74.9%,而利用像素相加操作的方法精度可达到77.8%,像素相加操作更能提高本文算法的分割精度。这表明在“编码 解码”(encoder-decoder)过程中,像素相加操作更能有效关联上下文的语义信息,更有利于提高小目标的检测效果。
2.5 定性结果
在图3中,本文展示了所提出的方法在外观变化(图3(a))、动态背景(图3(b))、快速运动(图3(c))、运动模糊(图3(d))、遮挡(图3(e))以及在kite-surf序列(图3(f))上测试的效果图。部分遮挡的情况下只需要分割未被遮挡目标部分,杂乱背景的情况下需要将目标与背景中相似目标分离,运动模糊的情况下需要对模糊的目标部位进行更加细致的分割。本文算法在以上情况下都能准确地分割出给定目标,尤其在kite-surf序列中,可以较为准确地分割出图中的小目标。从图3(d)中可以看到,小目标的分割图与真实标签仍存在一些差距,如何更加充分地利用局部信息(比如感興趣区域中的一些关键特征点)和全局信息(比如感兴趣区域中的类别、颜色和纹理等语义信息)将是接下来的研究方向之一。
3 结语
针对多目标分割任务以及难以分割小目标的问题,本文提出了一种基于双重金字塔网络的半监督视频目标分割方法。改进后的视频目标分割方法可以通过调制模块来适应给定目标的外观;然后,金字塔池化模块聚合不同区域的上下文从而提高获取全局信息的能力;最后,金字塔卷积模块将高层强语义信息与底层特征融合,从而进一步提高了分割的准确性。本文所提出的方法加入在线微调后可以在视频目标分割的标准数据集上获得可竞争的结果,同时也基本适用于要求快速和准确的半监督视频目标分割任务中。
参考文献
[1] 李雪君,张开华,宋慧慧.融合时空多特征表示的无监督视频分割算法[J].计算机应用,2017,37(11):3134-3138. (LI X J, ZHANG K H, SONG H H. Unsupervised video segmentation by fusing multiple spatio-temporal feature representations [J]. Journal of Computer Applications, 2017, 37(11): 3134-3138.)
[2] TOKMAKOV P, ALAHARI K, SCHMID C. Learning motion patterns in videos [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2017: 531-539.
[3] BROX T, MALIK J. Object segmentation by long term analysis of point trajectories [C]// Proceedings of the 2010 European Conference on Computer Vision, LNCS 6315. Berlin: Springer, 2010: 282-295.
[4] MARKI N, PERAZZI F, WANG O, et al. Bilateral space video segmentation [C]// Proceedings of the 2016 Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2016: 743-751.
[5] PERAZZI F, KHOREVA A, BENENSON R, et al. Learning video object segmentation from static images [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2017: 3491-3500.
[6] 周志华.机器学习[M].北京:清华大学出版社,2016:73-92. (ZHOU Z H. Machine Learning [M]. Beijing: Tsinghua University Press, 2016: 73-92.)
[7] JAMPANI V, GADDE R, GEHLER P V. Video propagation networks [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2017: 451-461.
[8] KHOREVA A, BENENSON R, ILG E, et al. Lucid data dreaming for object tracking [C/OL]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2017 [2018-10-20]. https://arxiv.org/pdf/1703.09554.pdf.
[9] CAELLES S, MANINIS K K, PONTTUSET J, et al. One-shot video object segmentation [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2017: 5320-5329.
[10] MANINIS K K, CAELLES S, CHEN Y, et al. Video object segmentation without temporal information [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019, 41(6): 1515-1530.
[11] YOON J S, RAMEAU F, KIM J, et al. Pixel-level matching for video object segmentation using convolutional neural networks [C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Washington, DC: IEEE Computer Society, 2017: 2186-2195.
[12] LI Y, QI H, DAI J, et al. Fully convolutional instance-aware semantic segmentation [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2017: 4438-4446.
[13] VOIGTLAENDER P, LEIBE B. Online adaptation of convolutional neural networks for video object segmentation [C/OL]// Proceedings of the 2017 British Machine Vision Conference. Piscataway, NJ: IEEE, 2017[2018-09-25]. https://arxiv.org/pdf/1706.09364.pdf.
[14] HU Y T, HUANG J B, SCHWING A G. MaskRNN: instance level video object segmentation [C]// Proceedings of the 2017 Neural Information Processing Systems. Berkeley, CA: USENIX, 2017: 325-334.
[15] YANG L, WANG Y, XIONG X, et al. Efficient video object segmentation via network modulation [C]// Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2018: 6499-6507.
[16] SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition [J]. arXiv E-print, 2014: 1409.1556.
[17] STOLLENGA M, MASCI J, GOMEZ F, et al. Deep networks with internal selective attention through feedback connections [C]// Proceedings of the 27th International Conference on Neural Information Processing Systems. Cambridge, MA: MIT Press, 2014: 3545-3553.
[18] RONNEBERGER O, FISCHER P, BROX T. U-Net: convolutional networks for biomedical image segmentation [C]// Proceedings of the 2015 International Conference on Medical Image Computing and Computer-Assisted Intervention, LNCS 9351. Cham: Springer, 2015: 234-241.
[19] LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft COCO: common objects in context [C]// Proceedings of the 2014 European Conference on Computer Vision, LNCS 8693. Cham: Springer, 2014: 740-755.
[20] PERAZZI F, PONT-TUSET J, McWILLIAMS B, et al. A benchmark dataset and evaluation methodology for video object segmentation [C] // Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2016: 724-732.
[21] BAO L, WU B, LIU W. CNN in MRF: video object segmentation via inference in a CNN-based higher-order spatio-temporal MRF [C]// Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2018: 5977-5986.
[22] PONT-TUSET J, PERAZZI F, CAELLES S, et al. The 2017 DAVIS challenge on video object segmentation [J]. arXiv E-print, 2017: 1704.00675.
[23] LIN T Y, DOLLáR P, GIRSHICK R, et al. Feature pyramid networks for object detection [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2017: 2117-2125.
