关联数据的发布与消费
2019-10-23李素芳


摘 要:关联数据的应用过程包括发布和消费两个环节。文章基于OCLC分别于2015年和2018年对关联数据项目实施情况调查结果的原始公开数据,总结关联数据项目的实施现状,分析关联数据的发布和消费的动机与障碍,针对存在的障碍思考提升路径,为我国的关联数据项目实施提供借鉴。
关键词:关联数据 数据发布 数据消费
中图分类号:G251文献标识码:A文章编号:1003-9082(2019)09-00-03
Tim Berners-Lee在2006年提出了关联数据的概念。关联数据是一种推荐的最佳实践,用来在语义网中使用URIs和RDF发布、分享、连接各类数据、信息和知识,发布和部署实例数据和类数据,从而可以通过HTTP协议揭示并获取这些数据,同时强调数据的相互关联、相互联系以及有益于人机理解的语境信息[1]。
本文根据OCLC[2]对关联数据项目两次调查结果的原始数据,分析关联数据项目的实施动机和遇到的障碍。被调查的机构情况见表1。总体上,图书馆机构占被调查机构的大多数(67%)。另外,2018年的最新一次调查中,首次收到服务供应商的问卷反馈,该类机构为客户提供关联数据服务。
一、关联数据的发布
指将原始数据转换为以RDF数据格式描述的结构化数据,在不同的数据之间建立RDF链接,并在Web上发布RDF文档的一个过程。发布时,可根据RDF数据集合的规模选择不同发布方式。数据量较小时,可直接发布静态的RDF文档;数据量较大时,使用RDF数据库发布关联数据;如果数据更新频繁,可采用在线转换的方式,当收到访问请求时,在线将原始数据转换为RDF文档供用户使用。
1.发布关联数据的动机
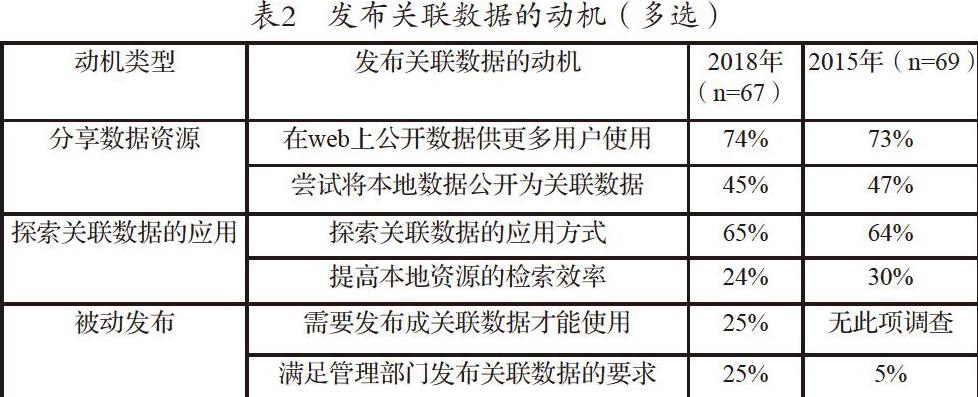
根据OCLC对关联数据项目的调查结果,关联数据的发布动机可分为三类,结果见表2。
总体上,关联数据的发布动机没有明显变化,只有为满足管理部门要求发布关联数据的回答数量有明显增加。发布关联数据的动机体现在分享数据资源、探索关联数据的应用、被动发布三个方面。
分享数据资源方面。体现在:在web上公开数据供更多用户使用、尝试将本地数据公开为关联数据。此类动机基本没有发生改变,因为发布关联数据的目的就是为了与其他数据集合关联而实现数据共享。关联数据的核心是将数据和网络融合起来,将数据以关联数据的形式发布,数据就成为网络的一部分,最终实现文档网络(the Web of Document)向数据网络(the Web of Data)的转变。
探索关联数据的应用方面。根据OCLC的2018年调查结果,目前RDF三元组数据量超过50亿的关联数据项目有3个,分别是OCLC的World Cat项目(100亿)、加利西亚数字图书馆(63亿)、欧洲数字图书馆(50亿)。数据量在1亿到10亿之间的项目有10个,数据量在1000万到1亿之间的项目有9个,数据量小于1000万的项目有33个。自从Tim Berners-Lee在2006年提出关联数据的概念以来,许多组织机构都在尝试将本地数据发布为关联数据,但是对于关联数据的应用仍处于探索阶段,大多数组织机构将本地数据发布为关联数据的目的是探索关联数据的应用方式,比如能否提高检索效率。
被动发布关联数据方面。为了满足管理部门的要求而发布关联数据的回答数较2015年有明显增加。如英国图书馆表示其关联数据项目实施,一方面是为响应英国政府的开放数据政策,另一方面是为探索关联书目数据应用的可能性。另外,在2019年1月,美国政府颁布了《开放政府数据法案》,要求联邦机构以开放的机器可读格式向公众开放非敏感政府数据。说明公共部门已经逐渐意识到关联数据的重要性,开始要求其下属部门将其数据以关联数据形式发布。
2.发布关联数据的障碍
根据OCLC对关联数据项目的调查结果,发布关联数据的主要障碍可分为资源障碍、技术障碍和其他障碍三类,调查结果如表3所示。
总体上,除了数据产权障碍和发布软件技术不成熟的障碍,发布关联数据的其他障碍没有明显变化。其中,发布关联数据最大的障碍主要是专业技术人力资源匮乏。
资源障碍方面。接近一半的组织机构认为数据格式不一致是发布关联数据的障碍。以图书馆编目数据为例,无论是MARC还是CNMARC格式的数据资源都要经历编目各元素项的拆分和转换映射两个环节,然而转换与映射的过程中存在无法对应的情况,需要对原有的编目元素项进行修改、增补或删除等操作。在2015年的调查中,有受访者在“其他障碍”里列出“缺乏资金”,因此OCLC在2018年的调查中将其单独作为一个选项,并且成为了发布关联数据的第四大障碍。根据OCLC的调查统计,有22个关联数据项目接受过国家基金资助;73个项目受到过图书馆/档案馆或上级机构的资助;6个项目受过伙伴(合作)机构的资助;5个项目受到过私人资助;1个项目获得公司基金资助;有8个项目未申请过资助,但计划申请。另外,由于数据版权问题造成的关联数据发布障碍降低。因为数据的版权属性不清晰,随意将数据发布到web上存在侵权的法律风险。说明组织机构的版权意识逐渐提高,已经基本解决数据的版权问题。
技术障碍方面。最大的障碍是专业技术人力资源匮乏,主要是因为学习关联数据的相关专业知识具有一定难度。因此在2018年的调查中,将学习关联数据知识纳入员工职责的项目数量降低(72%,2018;92%,2015),相应地,越来越多的组织机构开始聘用具备关联数据专业知识的新员工或外部顾问(20%,2018;4%,2015)。另外,如何选择合适的RDF词汇表、本体描述本地数据也是一大障碍。关联数据采用RDF三元组的主-谓-宾结构作为基本数据模型[3]。发布关联数据过程中,最关键的步骤是将组织机构内部的数据转换为RDF格式的数据。目前使用最多的RDF词汇表、本体有Schema.org(用于描述结构化数据的词表)、SKOS(用于描述分类和领域知识概念)、DC(用于描述网络资源的元数据词表)、FOAF(用于描述人的活动和人与人之间关系的词表)、DCMI(DC核心要素的扩展版本,定义了更多的元素和关系)、RDF Schema(用于描述RDF結构的词表)、Bib Frame(用于描述书目和引文的概念和关系)。另外,可能还需要根据组织机构的原始数据结构创建新的RDF词汇表/本体。在2015年和2018年的调查结果对比中,越来越多的组织机构表示缺乏成熟的关联数据发布软件,可能的原因是随着越来越多的组织机构发布关联数据,而相应的发布软件更新不及时,导致发布关联数据存在技术上的障碍。
其他障碍方面。欧洲数字图书馆表示,由于数据量过大而导致关联数据集的更新困难;美国普瑞特信息与图书馆科学学院表示,“我们无法将关联爵士项目的数据迁移到Wikibase知识库中,我们想把我们的数据转移到一个更灵活的、非特定领域的平台上”。美国史密森尼博物馆则表达了对数据安全和隐私的担忧。还有一些组织机构表示缺乏上级机构的支持、缺少员工等等。
二、关联数据的消费
涉及到数据的访问、查询、获取和利用等方面。OCLC在2018年和2015年的调查中,大多数关联数据项目在发布关联数据的同时也消费关联数据(65,2018;64,2015),只发布而不消费关联数据的项目很少(5,2018;10,2015)。本节基于OCLC的调查结果对消费关联数据的动机和障碍进行具体分析。
1.消费关联数据的动机
根据OCLC对关联数据项目的调查结果,消费关联数据的动机可分为用户服务、内部数据管理和搜索引擎优化三类,结果见表4。
总体上,用户服务方面的消费动机没有明显变化,但是内部数据管理和搜索引擎优化方面的动机均有不同程度的变化。
用户服务方面。大多数组织机构表示其消费关联数据的目的是为用户提供丰富的服务。以图书馆为例,传统的图书馆检索系统只支持用户以作者、关键词等检索条件进行检索,无法提供扩展服务。基于关联数据的检索可支持用户进行语义检索,进而提高检索质量。同时,越来越多的组织机构表示想通过尝试消费关联数据了解是否可以改善用户服务体验。
内部数据管理方面。发布关联数据的目的是消费,有的是在内部消费,用于本地资源管理、发现、重用等,如BBC的关联数据应用[4]。在2015年的调查中,有47%的组织机构表示消费关联数据是为了提升内部元数据管理的效率,但是在2018年的调查中,选择此动机的机构数量已降至30%。
搜索引擎優化方面。组织机构对于消费关联数据提升搜索引擎优化方面的期望均出现不同程度的下降。可能的原因是,目前大多数组织机构发布关联数据采取“大而全”的发布原则,用户在消费关联数据时,经常会出现不需要的数据,进而影响检索效率。
2.消费关联数据的障碍
根据OCLC对关联数据项目的调查结果,发布关联数据的主要障碍可分为数据质量障碍、数据获取障碍、数据使用障碍和其他障碍四类,调查结果如表5所示。
总体上,消费关联数据的障碍没有明显变化。其中,消费关联数据最大的障碍是原始数据与关联数据之间的匹配、消除歧义困难。
数据质量障碍方面。随着发布的关联数据集合越来越多,关联数据的可重用性越来越重要,如何向用户提供高质量的数据资源是关联数据消费的一个重要问题。在2015年和2018年的两次调查中,组织机构对于数据质量方面的障碍的回应并没有发生很大变化,数据质量障碍主要体现在关联数据可重用性差、词汇表映射不准确,缺乏权威控制等方面。这可能是关联数据发布软件不成熟、描述本地数据的本体选择困难等发布关联数据的障碍所导致的。发布关联数据的障碍导致关联数据质量不稳定,进而影响关联数据的消费。
数据获取障碍方面。越来越多的组织机构表示在关联数据访问获取方面存在障碍。比如,RDF转储文件过大、数据链接不稳定、数据集更新不及时等等。这涉及到关联数据有效性的问题,因为随着关联数据集的不断增多,不同数据集之间的链接关系将会越来越复杂。任何一个数据集的状态发生变化,哪怕是单个三元组层面上的变化,都可能导致与之相链接的其他数据集发生访问故障[5]。因此,获取关联数据的前提是保证URI的完整性、准确性和有效性。
数据使用障碍方面。在关联数据的使用方面,接近一半的组织机构表示在原始数据与关联数据之间的匹配、消除歧义过程中存在障碍。因为在消费关联数据前,需要对数据进行处理,比如对同一实体对象的识别、去重。然而不同来源的关联数据对同一个实体(如人物、地点等)可能采用了不同的URI来标识,对于作者、刊名等实体的消歧、去重的工作量巨大。另外,有一部分组织机构表示在不同关联数据源之间的词汇表映射存在障碍。因为不同来源的关联数据可能采用不同的词表,使用前则需要不同来源的关联数据转换为统一的词汇表描述。转换工作主要依据词表将数据映射成本地的数据模式,另外,还需要依据人工产生或者经过数据挖掘得到的映射规则进行转换[6]。
其他障碍方面。在2018年的调查中,受访者列出了消费关联数据的其他障碍。比如,数据转换复杂、缺乏最佳实践、安全和隐私问题、数据集太大而不能作为一个整体发布(其他人难以使用)以及缺乏机构支持等。
三、提升路径
解决关联数据项目实施过程中的发布和消费障碍,是所有关联数据项目面临的一个现实问题。实际上,关联数据的发布和消费是一个存在逻辑顺序的过程,结合上节的发布和消费障碍可以发现,关联数据项目实施的主要障碍可以概括为关联数据发布障碍导致的关联数据质量问题,进而引起关联数据消费障碍。故,关联数据的质量是关联数据项目实施的核心。
1.保证原始数据质量
关联数据是基于对原始数据的RDF描述产生的,因此,原始数据质量决定关联数据的质量。应建立原始数据选择标准,包括两个方面:一是保证原始数据自身质量,二是根据用户需求,选择适合关联数据化的数据。
保证原始数据自身质量方面。首先,应对数字资源生产者进行考察,确保原始数据来源的可信任性[7]。原始数据来源可信任性的认定一般需要延伸到数字资源生产领域。常用的手段包括:检查数字资源生产企业的资质证明,考察其数字资源生产流程是否符合标准作业流程,评估数据校验方式是否安全可靠等。其次,对原始数据的正确性和完整性进行验证,以便检测在数字保存过程中可能出现的数据丢失和损坏。
用户需求分析方面。根据OCLC的调查,大多数组织机构发布关联数据并非针对某一特定用户,为了满足不同类型用户需求而追求发布关联数据的“大而全”。实际上某些需求只是理论存在,现实几乎不可能出现。从绿色关联数据[8]的角度来看,“大而全”的关联数据发布原则会导致发布成本的增加与检索效率的降低。因此,首先应根据用户需求对本地原始数据进行筛选,保留用户需要的数据,删除用户不需要或极少需要的数据。其次,本地数据模型与用户实际需要相结合,对数据字段进行增删、修改,分析哪些字段所提供的信息是用户需要的,应予以保留,哪些字段所提供的信息用户不需要或极少用到,应予以删除。同时要厘清不同字段间的相互关系,在此基础上构建关联数据模型。
2.原始数据与关联数据的语义描述映射
关联数据模型设计方面。数据模型应准确地反映现实世界中数据之间的内在逻辑关系。基于对用户的数据需求分析结果,将概念之间的具体联系转化成相对抽象的概念数据模型。在此基础上,将概念数据模型转化为逻辑数据模型,即将概念数据模型先转化为具体的数据结构,并对数据结构内数据间的语法联系、制约和依存关系以及数据动态变化的规则进行描述,以保证数据的正确、有效和相容[9]。同时,也要注意关联数据与外部关联数据源之间的关联关系设计,主要有以下几类:与人的关联、与时间的关联、与空间的关联等,相应地,图书馆可以根据自身情况以及数据需求分析的结果,确定关联数据应包含哪些类型的关联信息,并从现有的词汇表中选择关联属性,如foaf:knows、owl:sameAs等。
RDF词汇表、本体选择方面。虽然RDF词汇表还没有统一的国际标准,但描述本地数据时,应尽可能选择在网络中已广泛应用、具备一定权威性的词汇表。一是成熟的RDF词汇表描述能够使关联数据语义更加明确,减轻本地元数据管理负担,二是增加与使用相同词表的外部资源的链接,用户更容易获取相关链接,进而能够保证关联数据的互操作性。如果现有的词汇表不能满足本地数据的描述需求而需自定义词汇表时,在保证语义描述清晰、准确的前提下,遵循易于重用和互操作的原则。例如大英图书馆,除了使用自定义的BLT本体词表,还引用了14个成熟RDF词表,目的是可以更好的与其他图书馆的关联书目数据建立链接。
3.关联数据链接维护
URI选择方面。关联数据之间的关联是通过URI来實现的。因此,为每个资源选择URI时,要保证URI稳定、持久、短小易记等要求。首先,要使用HTTP URI,这是Tim Berners-Lee提出的关联数据四项基本原则之一。其次,URI长度应尽量短,URI过长会导致用户使用不便。再次,URI应保持稳定,URI发生变化可能会导致断链的产生。最后,URI不能包含变量,每个URI必须是确定不变的。
动态链接维护方面。大多数据集合处于不断更新变化之中(包括增加、删除、移动等操作),数据集合的动态性直接决定了链接的动态性,对这些动态链接进行及时、有效的维护是发挥关联数据作用、体现关联数据价值的重要保证,包括及时修补断链、删除已消失的链接、建立新链接等。目前主要的动态链接维护技术有三种:一是基于WOD-LMP协议(web of data link maintenance protocol)的动态链接维护,这种方法要求链接双方都遵守WOD-LMP协议;二是基于更新通知的动态链接维护,适用于目标数据集合具有数据更新通知机制的情况。如Triplify更新日志方法、sparqlPuSH方法、DBPedia Live方法、PingTheSemanticWeb方法等;三是基于主动监测机制的动态链接维护,这种方法对目标数据集的要求较低,只需要提供SPARQL查询接口或支持RDF堆下载即可。如DSNotify方法。
基于OCLC在2015年和2018年的两次调查结果可以发现,关联数据项目的实施仍然处于不断的发展之中。无论是关联数据的发布还是消费,还存在许多障碍,但是依然要鼓励更多的关联数据项目实施,将越来越多的数据以关联数据的形式发布到Web网络中,最终实现数据网络。国内对于关联数据的研究起步较晚,大多数仍然处于理论研究阶段,大规模的关联数据项目少见。虽然目前缺少对我国关联数据项目实施情况的整体调查,但综合国际上关联数据项目的实施情况,情况不会乐观。在未来的实践中,应多借鉴国外较成熟的关联数据项目实施经验,促进国内外数据资源的交流融合。关联数据的发布与消费是一个连续的过程,在消费过程中遇到的障碍同时也会倒逼关联数据发布技术的提升。随着关联数据应用范围的扩大,关联数据的应用效果日益显现,其实现技术和工具也会越来越成熟和易于应用。
参考文献
[1] Berners-Lee.Linked Data-Design Issues[EB/OL].[2019-01-06].
http://www.w3.org/DesignIssues/LinkedData.html
[2]OCLC.Analysis of 2018 International Linked Data Survey for Implementers[EB/OL].[2019-01-21].
https://www.oclc.org/research/publications/all/analysis-of-2018-linked-data-survey.html
[3]刘炜.关联数据:概念、技术及应用展望[J].大学图书馆学报,2012(2):5~12
[4]夏翠娟,刘炜.关联数据的消费技术及实现[J].大学图书馆学报,2013(3):29~37
[5]郭少友.关联数据的动态链接维护研究[J].图书情报工作,2011,55(17):112~116
[6]黄永文,岳笑.关联数据应用的体系框架及构建关联数据应用的建议[J].现代图书情报技术,2011(9):7~13
[7]臧国全.基于项目生命周期的信息资源数字化建设研究[M].武汉:武汉大学出版社,2014.171~172
[8]郭少友.绿色关联数据:概念、要求与工程[J].图书情报工作,2012,56(23):113~118
作者简介:李素芳(1992-),女,研究生,研究方向:图书情报。