基于深度学习的ARM平台实时人脸识别
2019-10-23方国康李俊王垚儒
方国康 李俊 王垚儒


摘 要:针对ARM平台上人脸识别实时性不强和识别率低的问题,提出一种基于深度学习的实时人脸识别方法。首先基于MTCNN人脸检测算法设计了一种实时检测并追踪人脸的算法;然后在ARM平台上基于深度残差网络(ResNet)设计人脸特征提取网络;最后针对ARM平台的特点,使用Mali-GPU加速人脸特征提取网络的运算,分担CPU负荷,提高系统整体运行效率。算法部署在基于ARM的瑞芯微RK3399开发板上,运行速度达到22帧/s。实验结果表明,与MobileFaceNet相比,该方法在MegaFace上的识别率提升了11个百分点。
关键词:ARM平台;人脸识别;人脸追踪;残差网络;Mali-GPU
中图分类号: TP183; TP391.4
文献标志码:A
Real-time face recognition on ARM platform based on deep learning
FANG Guokang1,2, LI Jun1,2*, WANG Yaoru1,2
1.School of Computer Science and Technology, Wuhan University of Science and Technology, Wuhan Hubei 430065, China ;
2.Hubei Province Key Laboratory of Intelligent Information Processing and Real-time Industrial System (Wuhan University of Science and Technology), Wuhan Hubei 430065, China
Abstract: Aiming at the problem of low real-time performance of face recognition and low face recognition rate on ARM platform, a real-time face recognition method based on deep learning was proposed. Firstly, an algorithm for detecting and tracking faces in real time was designed based on MTCNN face detection algorithm. Then, a face feature extraction network was designed based on Residual Neural Network (ResNet) on ARM platform. Finally, according to the characteristics of ARM platform, Mali-GPU was used to accelerate the operation of face feature extraction network, sharing the CPU load and improving the overall running efficiency of the system. The algorithm was deployed on ARM-based Rockchip development board, and the running speed reaches 22 frames per second. Experimental results show that the recognition rate of this method is 11 percentage points higher than that of MobileFaceNet on MegaFace.
Key words: ARM platform; face recognition; face tracking; Residual neural Network (ResNet); Mali-GPU
0 引言
隨着计算机图像处理技术的发展,基于计算机视觉的目标识别在特征分析[1]和目标监控[2]等领域具有广泛的应用价值。人脸识别[3]是图像处理中的一个重要研究领域,作为一种身份识别手段,因其直接性和灵活性等优点,有着广阔的市场应用前景。人脸识别是通过人脸图像确定人脸身份的过程,包括人脸检测、人脸对齐、人脸特征提取和特征匹配4个过程[4]。近年来,随着视频监控的大量普及,基于视频的人脸识别技术越来越受到各界的重视。传统人脸识别算法围绕主成分分析(Principal Component Analysis,PCA)[5]、线性判别分析(Linear Discriminant Analysis,LDA)[6]和局部特征分析(Local Feature Analysis,LFA)[7]等展开,但这些算法利用到的特征为图像浅层的特征,识别效果容易受到姿态转动、光照变化、遮挡等因素的影响,存在着较大的局限性。同时,与静态图像相比,视频中包含了更加丰富的信息[8],但视频的识别难度大,实时性强,对算法和设备都有着更高的要求。
近年来,随着人工智能的快速发展,深度学习在图像识别领域取得了良好的效果[2]。卷积神经网络(Convolutional Neural Network,CNN)[9]通过模拟人的大脑结构,构建多层非线性映射关系,拥有很强的非线性特征学习能力,能够从大量样本中学习到高维语义特征和深度特征。鉴于传统人脸识别算法发展遇到了瓶颈,2014年,Taigman等[10]基于深度学习提出DeepFace,使用CNN来提取人脸深层抽象语义特征,利用特征的余弦相似度来比较人脸相似性,最终在LFW(Labeled Faces in Wild)[11]上的准确率达到了95%,取得了很好的识别效果。
2015年,针对CNN在达到一定深度后,网络梯度消失的问题,He等[12]提出了残差网络(Residual Neural Network,ResNet),与VGGNet(Visual Geometry Group Network)[13]、GoogleNet[14]等网络相比,ResNet拥有更深的网络结构,可达到150层,学习到的特征也更加深层抽象,分类能力也更强。
2016年,Zhang等[15]提出了MTCNN(Multi-Task Cascaded Convolutional Neural Network)人脸检测算法,使用三个级联CNN来检测人脸位置和关键点,检测人脸时由粗到细,不仅有很好的检测效果,而且速度很快,在Nvidia Titan X上的检测速度达到了99帧/s(Frames Per Second, FPS);同时,MTCNN算法通过将人脸图像对齐,提供了标准统一的人脸图像,促进了后续人脸识别的研究。
2017年,Liu等[16]提出了SphereFace算法,针对损失函数进行了改进,能够让特征学习到更可分的角度特性。该算法使用64层的深度网络训练,最终在LFW上的测试精度达到了99.4%,在MegaFace[17]上的准确率达到了72.4%。
而后,Wang等继续针对损失函数进行改进,相继提出了NormFace[18]以及AMSoftmax(Additive Margin Softmax)[19]算法。
2018年,Deng等[20]提出了ArcFace(Additive Angular Margin Loss)算法,更加注重在角度空间里对类别进行区分。该算法使用了50层的ResNet进行训练,在LFW上的准确率达到了99.8%,在MegaFace的准确率达到了97.6%,是目前MageFace上排名第一的人脸识别算法。
相比传统的人脸识别算法,基于深度学习的人脸识别算法在图像人脸识别任务中取得了很好的结果,其识别精度在百万级数据量的测试集上达到了97%,已经能够满足大多数场景下实际使用需求。但这些算法在实际部署时,需要使用支持大量计算的服务器,成本很高。近年来,以手机为代表的嵌入式设备得到了飞速发展,其性能日新月异,嵌入式系统以其功能齐全、安全可靠、价格低廉、体积小、功耗低等优势,以贴近生活、以实际应用为核心的特点,越来越广泛地应用到了各个领域。Mali-GPU[21]是ARM公司推出的高性能移动图形处理器,主要应用于基于ARM体系结构的移动设备上。与桌面级GPU一样,Mali-GPU专为执行复杂的数字和几何计算而设计,迎合了深度学习对大量数字计算的需求;不同的是,Mali-GPU主要针对移动设备,能耗更低,虽然计算能力相对较弱,但其移动便携性却是桌面级GPU无法比拟的。
随着MobileNet[22]、ShuffleNet[23]等轻量化网络的提出,基于嵌入式系统的深度学习研究也逐渐成为热点。轻量化网络的提出旨在精简网络参数、降低网络计算的复杂度,但这会在一定程度上损失网络的识别精度。2017年,Chen等[24]发布的深度学习编译器TVM(End to End Deep Learning Compiler Stack)是一个端到端优化堆栈,可以降低和调整深度学习工作负载,适应多种硬件后端,针对不同的硬件設备生成底层优化代码。
在ARM平台上,TVM能够同时实现CPU和GPU上的优化加速和负载均衡,这使得嵌入式设备也能在一定程度上执行复杂计算。
本文从实际的部署成本这个角度出发,针对ARM平台设计了可以实时识别人脸的算法,同时使用ResNet来提取人脸特征,其识别精度能够达到服务器级别的水平。
首先,本文在MTCNN算法的基础上进行改进,设计了一种能够实时检测并追踪人脸的算法,通过对人脸进行追踪,可以减小提取人脸特征的频率,从而达到更快的运行速度;然后,在ARM平台上使用ResNet提取人脸特征,并用Mali-GPU来对人脸特征的提取加速。实验表明,本文基于ARM平台设计的人脸识别模型能够满足实时识别需求,同时也能达到很高的识别精度。
1 基于深度学习的人脸识别框架
1.1 人脸检测
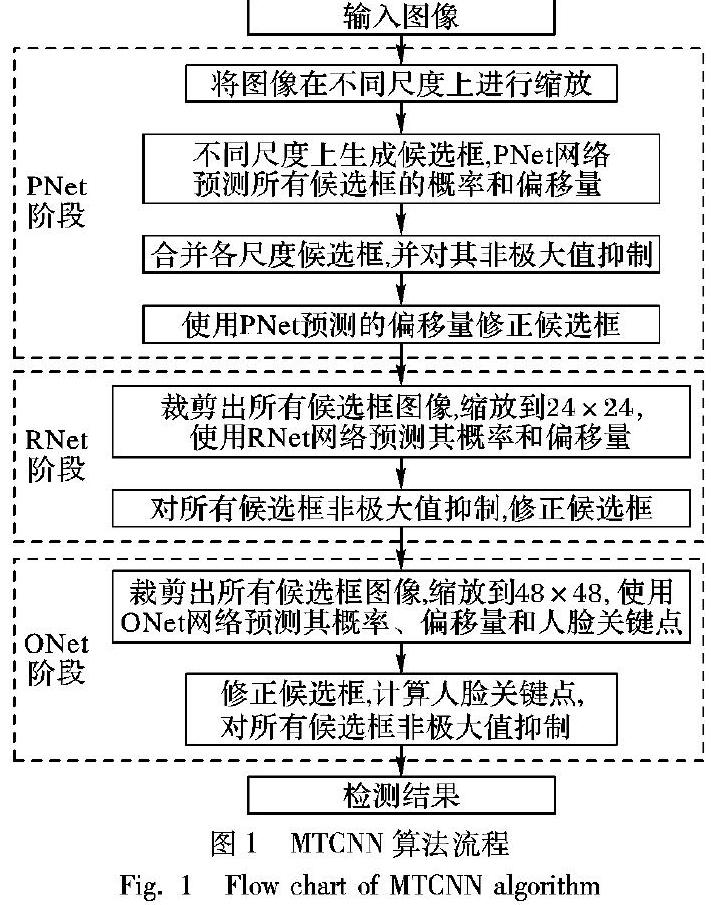
人脸检测是在图像中找到人脸并返回人脸框大小和位置坐标信息的过程。本文中使用MTCNN算法对人脸进行检测。MTCNN是一种将多任务级联卷积神经网络用于人脸检测和对齐的人脸检测算法。该算法总共分为三个阶段:
第一阶段,对图像在不同尺度上生成若干候选框,通过一个简单的CNNPNet(Proposal Net)来预测所有候选框的概率,然后对所有候选框非极大值抑制(Non-Maximum Suppression,NMS),消除多余候选框;
第二阶段,使用一个较为复杂的CNN——RNet(Refine Net)对第一阶段生成的候选框位置和大小进行回归校正并预测其概率,然后对所有候选框使用NMS方法筛选;
第三阶段,使用一个更为复杂的CNN——ONet(Output Net)对第二阶段的预测框位置和大小进行回归校正并使用NMS方法筛选,为每个预测框生成5个人脸关键点,分别为两只眼睛、鼻尖和两边嘴角。MTCNN算法流程如图1所示。
1.2 人脸对齐
人脸对齐是在图像中检测到人脸后,对人脸图像进行处理的过程,处理后的图像能够更好地被识别。本文中根据MTCNN检测到的5个人脸关键点对原始图像进行仿射变换处理,对人脸部分图像的大小和角度进行调整,调整后的图像像素大小为112×112。
1.3 特征提取
人脸特征提取的目的是为了得到人脸中的深层抽象信息,这个抽象信息能够将不同的人区分开,进而实现对人脸的判别。本文运用深度学习方法来提取人脸特征,采用了ResNet作为人脸识别网络,并使用ArcFace人脸识别算法来训练识别网络。
ArcFace Loss是一种用于人脸识别的损失函数,基于该损失函数训练得到人脸识别算法ArcFace。ArcFace的思想和AMSoftmax有一定的共同点,不同点在于:ArcFace在角度空间中最大化分类界限,而AMSoftmax是在余弦空间中最大化分类界限。ArcFace Loss基于传统的Softmax Loss修改得到,式(1)是Softmax Loss损失函数。
L1=- 1 m ∑ m i=1 lg e W Tyi x i+ b yi ∑ n j=1 e W Tj x i+ b j
(1)
将式(1)中的偏置 b j设置为0,然后权重 W 和输入 x 的内积用下面式子表示。
W Tj x i=‖ W j‖‖ x i‖cos θ j
对权重 W j使用L2正则化处理,使得‖ W j‖=1,得到公式:
L2=- 1 m ∑ m i=1 lg e‖ x i‖cos θ yi e‖ x i‖cos θ yi+∑ n j=1, j≠yi e‖ x i‖cos θ j
(2)
然后对输入 x i也用L2作正则化处理,同时再乘以一个缩放系数s;另一方面将cos θ yi用cos( θ yi+m)替换,这部分是ArcFace的核心,m为附加角。于是得到ArcFace算法的损失函数如下:
L3=- 1 m ∑ m i=1 lg es·cos( θ yi+m) es·cos( θ yi+m)+∑ n j=1, j≠yi es·cos θ j
(3)
ArcFace算法的整体流程如图2所示。
1.4 特征匹配
提取到人脸特征后,需要在特征库中匹配特征,以找到对应的身份信息。普遍的方法是计算目标人脸特征与特征库中所有特征的相似度,根据相似度找到最符合的特征。本文中使用余弦相似度来表示特征的相似性,对于特征向量 m 和特征向量 n ,其余弦相似度为两特征向量夹角α的余弦值:cosα= m · n ‖ m ‖·‖ n ‖ ,cosα越大,相似度越高。
2 针对ARM平台的人脸识别方法
2.1 总体系统结构设计
深度学习模型的训练需要大量的计算,通常需要具有强大计算能力的服务器来訓练。本文中的模型使用配备英伟达GPU的服务器来训练,模型训练完成后,应用到嵌入式系统中。ARM端系统总体设计如图3所示。
在本系统上,摄像头负责采集视频,交给CPU实时检测并追踪人脸;CPU检测到人脸后,若GPU处于空闲状态,则将检测到的人脸图像对齐后传送给GPU,在GPU上提取人脸的特征信息,CPU继续检测并跟踪人脸;GPU上人脸特征提取完成后,到数据库中与事先提取好的特征库进行相似度匹配,若匹配到相应身份信息,则交由CPU实时追踪该目标,并不再对该目标进行识别。当一个目标被正常识别后,将识别结果发送到远程服务器,进行相应的业务逻辑处理。
由于提取人脸特征需要较大的资源开销,系统无法对每帧检测到的人脸都进行识别,所以本文通过对人脸的实时追踪,对同一个目标只需要识别一次,避免识别每帧图像,进而提高系统运行的效率。同时,系统充分利用硬件设备的计算资源,使用CPU来检测追踪人脸,GPU提取人脸特征,CPU和GPU并行运行,互不干扰,系统运行起来流畅稳定。
2.2 改进MTCNN用于人脸追踪
本文中,人脸追踪是对检测到的人脸持续标记的过程,即同一个体的人脸在不同的视频帧中,具有相同的标记。本文对MTCNN算法进行了改进,使得MTCNN算法能够适用于人脸追踪。原始的MTCNN算法包含了三个级联CNN,这三个级联网络用于对人脸位置和关键点进行检测,对于视频序列,MTCNN算法不能实时追踪每个目标。在MTCNN三个级联网络的基础上,通过添加第四个CNN——FNet(Feature Net)来实时提取每个目标的特征信息,通过匹配视频帧之间目标的特征相似度,实现对每个目标的实时追踪。
FNet基于MobileFaceNet[25]进行设计。MobileFaceNet是一个轻量化的CNN,其中采用了可分离卷积(Depthwise Separable Convolution)[26]来精简网络参数,使得网络更加适用于移动设备。同时,MobileFaceNet还在MobileNetV2[27]的基础上使用可分离卷积层代替全局平均池化层(Global Average Pooling),使网络可以学习不同点的权重。FNet在MobileFaceNet的基础上精简了网络结构,并加入了通道混洗(Channel Shuffle)[23]策略,通道混洗能够加强通道之间的信息流通,增强网络的信息表达能力。FNet网络结构如表1所示。
人脸追踪算法流程:
程序前
FO R 视频中的每帧 DO
MTCNN算法检测每帧图像
取出所有检测到的人脸,resize为112×112
FNet提取每帧人脸的128维特征
FO R 每张人脸 DO
计算与上一帧图像中所有人脸特征的相
似度,并取最大值
IF 最大相似度 > 0.6 DO
匹配相应的两张人脸为同一目标
EL SE DO
将当前人脸作为新目标
程序后
2.3 ARM平台下使用ResNet提取人脸特征
标准的深度网络一般需要部署在高性能服务器或者桌面级计算机上,而对于计算能力弱的嵌入式设备,通常使用轻量化的深度网络,例如MobileNet、ShuffleNet等。轻量化的网络虽然对设备性能要求更低,但识别精度也比较低。为了使ARM平台上人脸识别精度得到更高层次的提升,本文将ResNet应用到嵌入式设备上。
本文中使用了三个具有不同网络深度的ResNet进行对比实验,其网络结构如表2所示。
2.4 使用Mali-GPU实现网络加速
Mali-GPU是ARM平台下专门用于图形和数字计算的处理器,与ARM CPU相比,Mali-GPU的数值计算能力更强。本文基于TVM进行开发,使用Mali-GPU来完成ResNet复杂的网络运算,速度比使用ARM CPU更快,同时不再占用CPU,CPU可以更好地用来检测和追踪人脸,系统整体运行速度更快。
为了利用Mali-GPU,TVM底层基开放运算语言(Open Computing Language,OpenCL)进行编译,并使用开放基础线性代数子程序库(Open Basic Linear Algebra Subprograms,OpenBLAS)进行网络运算。框架对外提供统一的Python API,方便编程开发。
3 实验结果分析
3.1 实验设置及数据
本实验训练模型的服务器运行64位的CentOS系统,版本为7.5,配备了Intel Xeon E5 2620 v4 处理器,64GB内存,4张Tesla V100显卡,每张显卡显存32GB。
本文系统最终运行在ARM平台上,设备为瑞芯微RK3399开发板,开发板配置如表3所示。
训练数据集为经过人脸对齐以及降噪处理[20]之后的微软名人数据集MS-Celeb-1M(MicroSoft One Million Celebrities in the Real World)[28],处理之后的训练集包含了85164个不同个体,共计约380万张人脸图像。
数据的校验即判断每两张人脸图像是否为同一人。本文使用的校验数据集为LFW、CFP(Celebrities in Frontal Profile)[29]和AgeDB(Age Database)[30]。其中,LFW校验集包含了6000对人脸图像;CFP使用包含正面和侧面的校验数据CFP-FP(CFP with Frontal-Profile),共计7000对人脸图像,同一人和不同人图像的分别有3500对;AgeDB使用年龄差距为30岁的数据组(AgeDB-30),分别包含3000对相同人脸和不同人脸图像,共计6000对。
测试数据集为MegaFace Challenge 1。MegeFace的测试分为干扰数据集Distractors和测试数据集FaceScrub:
干擾数据集包含了690572个不同个体约100万张人脸图像,测试数据集包含了530个不同个体约10万张人脸图像。
为了得到MegaFace最终测试结果,需要用待测试的模型提取所有干扰集和测试集人脸图像的特征,然后由MegaFace工具包根据所有测试人脸图像特征数据得到最终测试精度。
本实验参数设置如下:使用ArcFace算法训练ResNet模型,缩放系数s设置为64,附加角度m设置为0.5;ResNet输出特征维度设置为512。
3.2 结果分析
在人脸追踪当中,为了验证FNet的有效性,本文使用Softmax损失函数训练MobileFaceNet和FNet各14万次,训练过程中初始学习率设置为0.1,batch size设置为256,使用两张显卡训练。其效果对比如表4所示。
通过两个网络的对比分析可以看到,FNet在精度上要比MobileFaceNet略低,但差距较小;与MobileFaceNet相比,FNet的模型大小减小了45%,速度提升了75%,有较大提升。由于人脸追踪实时性强,对FNet速度要求高。FNet在速度上满足实时要求,同时在精度上也接近MobileFaceNet。
为了说明人脸追踪的效果,本文对算法在单目标和多目标条件下进行了测试,测试数据为网络上采集的包含人脸的视频图像,然后每隔2s抽取一张图像作为效果图,如图5、6所示。算法每检测到一个新目标,会对其从0开始编号。
从图4和图5中可以看到,在单目标和多目标条件下,同一目标的序号一直保持不变,说明算法准确地追踪到了该目标。算法在单目标和多目标的条件下具有良好的追踪效果。
本文通过实验对MobileFaceNet和具有不同深度的ResNet的识别效果进行了对比,训练中batch size统一设置为128,使用4块GPU训练,初始学习率设置为0.1。ResNet均使用ArcFace算法训练14万次。由于MobileFaceNet直接使用ArcFace算法训练难以收敛,所以MobileFaceNet先使用Softmax损失函数训练14万次,然后使用ArcFace算法训练20万次,效果对比如表5所示。
分别在Rockchip 3399 ARM CPU和Mali T860 GPU上测试四个网络模型的运行耗时,表6为2000张人脸图像下的平均耗时。
通过对四个网络模型的精度和耗时对比可以看到,得益于轻量化的网络结构,MobileFaceNet在模型大小和耗时均优于ResNet,但在识别精度上,ResNet要优于MobileFaceNet;随着网络的加深,ResNet的识别精度有明显提高;四个网络在ARM GPU上的耗时都比ARM CPU上低,说明使用ARM GPU加速人脸特征提取行之有效。
为了说明整套算法的实时性,本文在ARM平台上对不同算法组合进行了速度测试。人脸特征提取采用ResNet-50,结果如表7所示。
从表7可以看出,MTCNN算法中, 最小检测尺度min size设置为20px(pixel),本文中设置为100px,通过增大最小检测尺度后,算法速度得到了大幅提升;同时,算法过滤掉了容易被误检和不易识别的小目标,增强了算法的鲁棒性。MTCNN检测完图像后,直接使用ResNet提取人脸特征速度会很慢,原因是提取人脸特征过程比较耗时,频繁地提取人脸特征会消耗大量时间和计算资源,使算法变慢。MTCNN加上人脸追踪后,人脸被识别后会转为追踪,不需要频繁地提取人脸特征,算法的速度有很大程度的提高,特别是使用GPU加速后,特征提取在GPU上运行更快,而且不再占用CPU,CPU可以全部用来检测人脸,最终速度能接近实时水平。
4 結语
本文基于瑞芯微开发板设计和实现了实时人脸识别系统,使用深度学习的方法来检测人脸和提取人脸特征。首先,在MTCNN算法的基础上添加了一个轻量化的CNN——FNet来分辨每个目标,实现了对每个目标的实时追踪;其次,在嵌入式系统上采用ResNet进行更深层的特征提取,提高了算法的识别率;最后,在开发板上使用Mali-GPU对人脸特征提取进行加速,并实现了CPU和GPU的负载均衡。实验结果表明,本文方法在嵌入式系统上达到了较快的运行速度,并取得了比使用MobileFaceNet更高的识别率。
参考文献
[1] 刘飞,张俊然,杨豪.基于深度学习的糖尿病患者的分类识别[J].计算机应用,2018,38(S1):39-43. (LIU F, ZHANG J R, YANG H. Classification and recognition of diabetes mellitus based on deep learning [J]. Journal of Computer Applications, 2018, 38(S1): 39-43.)
[2] 熊咏平,丁胜,邓春华,等.基于深度学习的复杂气象条件下海上船只检测[J].计算机应用,2018,38(12):3631-3637. (XIONG Y P, DING S, DENG C H, et al. Ship detection under complex sea and weather conditions based on deep learning [J]. Journal of Computer Applications, 2018, 38(12): 3631-3637.)
[3] 孙劲光,孟凡宇.基于深度神经网络的特征加权融合人脸识别方法[J].计算机应用,2016,36(2):437-443. (SUN J G, MENG F Y. Face recognition based on deep neural network and weighted fusion of face features [J]. Journal of Computer Applications, 2016, 36(2):437-443.)
[4] KAZEMI V, SULLIVAN J. One millisecond face alignment with an ensemble of regression trees [C]// Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2014: 1867-1874.
[5] DASHORE G, Dr. RAJ V C. An efficient method for face recognition using Principal Component Analysis (PCA) [J]. International Journal of Advanced Technology and Engineering Research, 2012, 2(2): 23-29.
[6] CHAN L, SALLEH S, TING C. Face biometrics based on principal component analysis and linear discriminant analysis [J]. Journal of Computer Science, 2010, 6(7): 693-699.
[7] PENEV P S, ATICK J J. Local feature analysis: a general statistical theory for object representation [J]. Network Computation in Neural Systems, 1996, 7(3): 477-500.
[8] 杨天明,陈志,岳文静.基于视频深度学习的时空双流人物动作识别模型[J]. 计算机应用,2018,38(3):895-899. (YANG T M, CHEN Z, YUE W J. Spatio-temporal two-stream human action recognition model based on video deep learning [J]. Journal of Computer Applications, 2018, 38(3): 895-899.)
[9] LECUN Y L, BOTTOU L, BENGIO Y,et al. Gradient-based learning applied to document recognition [J]. Proceedings of the IEEE, 1998, 86(11): 2278-2324.
[10] TAIGMAN Y, YANG M, RANZATO M, et al. DeepFace: closing the gap to human-level performance in face verification [C]// Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2014: 1701-1708.
[11] HUANG G B, RAMESH M, BERG T, et al. Labeled faces in the wild: a database for studying face recognition in unconstrained environments [EB/OL]. [2018-12-05]. http://cs.umass.edu/~elm/papers/lfw.pdf.
[12] HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition [C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2016: 770-778.
[13] SIMONVAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition [J]. arXiv E-print, 2015: arXiv:1409.1556. [EB/OL]. [2019-01-06]. https://arxiv.org/pdf/1409.1556.pdf.
[14] SZEGEDY C, LIU W, JIA Y, et al. Going deeper with convolutions [C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2015:1-9.
[15] ZHANG K, ZHANG Z, LI Z, et al. Joint face detection and alignment using multitask cascaded convolutional networks [J]. IEEE Signal Processing Letters, 2016, 23(10): 1499-1503.
[16] LIU W, WEN Y, YU Z, et al. SphereFace: deep hypersphere embedding for face recognition [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2017:6738-6746.
[17] KEMELMACHER-SHLIZERMAN I, SEITZ S M, MILLER D,et al. The MegaFace benchmark: 1 million faces for recognition at scale [C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2016: 4873-4882.
[18] WANG F, XIANG X, CHENG J, et al. NormFace: L2 hypersphere embedding for face verification [J]. arXiv E-print, 2017: arXiv:1704.06369. [EB/OL]. [2018-11-20]. https://arxiv.org/pdf/1704.06369.pdf.
[19] WANG F, LIU W, LIU H, et al. Additive margin softmax for face verification [J]. arXiv E-print, 2018: arXiv:1801.05599. [EB/OL]. [2019-01-08]. https://arxiv.org/pdf/1801.05599.pdf.
[20] DENG J, GUO J, XUE N, et al. ArcFace: additive angular margin loss for deep face recognition [J]. arXiv E-print, 2019: arXiv:1801.07698. [EB/OL]. [2018-10-28]. https://arxiv.org/pdf/1801.07698.pdf.
[21] GRASSO I, RADOJKOVIC P, RAJOVIC N, et al. Energy efficient HPC on embedded SoCs: Optimization techniques for mali GPU [C]// Proceedings of the 2014 IEEE International Parallel and Distributed Processing Symposium. Washington, DC:IEEE Computer Society, 2014: 123-132.
[22] HOWARD A G, ZHU M, CHEN B, et al. MobileNets: efficient convolutional neural networks for mobile vision applications [J]. arXiv E-print, 2017: arXiv:1704.04861. [EB/OL]. [2019-01-15]. https://arxiv.org/pdf/1704.04861.pdf.
[23] ZHANG X, ZHOU X, LIN M, et al. ShuffleNet: an extremely efficient convolutional neural network for mobile devices [J]. arXiv E-print, 2017: arXiv:1707.01083v1. [EB/OL]. [2018-11-15]. https://arxiv.org/pdf/1707.01083v1.pdf.
[24] CHEN T, MOREAU T, JIANG Z, et al. TVM: an automated end-to-end optimizing compiler for deep learning [J]. arXiv E-print, 2018: arXiv:1802.04799. [2019-01-20]. https://arxiv.org/pdf/1802.04799.pdf.
[25] CHEN S, LIU Y, GAO X, et al. MobileFaceNets: efficient CNNs for accurate real-time face verification on mobile devices [J]. arXiv E-print, 2018: arXiv:1804.07573. [EB/OL]. [2019-01-09]. https://arxiv.org/ftp/arxiv/papers/1804/1804.07573.pdf.
[26] CHOLLET F. Xception: deep learning with depthwise separable convolutions [J]. arXiv E-print, 2016: arXiv:1610.02357v2. [EB/OL]. [2018-12-29]. https://arxiv.org/pdf/1610.02357v2.pdf.
[27] SANDLER M, HOWARD A, ZHU M, et al. MobileNetV2: inverted residuals and linear bottlenecks [J]. arXiv E-print, 2019: arXiv:1801.04381. [EB/OL]. [2019-01-20]. https://arxiv.org/pdf/1801.04381.pdf.
[28] GUO Y, ZHANG L, HU Y, et al. MS-Celeb-1M: a dataset and benchmark for large-scale face recognition [J]. arXiv E-print, 2016: arXiv:1607.08221. [EB/OL]. [2019-01-20]. https://arxiv.org/pdf/1607.08221.pdf.
[29] SENGUPTA S, CHEN J, CASTILLO C, et al. Frontal to profile face verification in the wild [C]// Proceedings of the 2016 IEEE Winter Conference on Applications of Computer Vision. Washington, DC: IEEE Computer Society, 2016: 1-9.
[30] MOSCHOGLOU S, PAPAIOANNOU A, SAGONAS C, et al. AgeDB: the first manually collected, in-the-wild age database [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops. Washington, DC: IEEE Computer Society, 2017: 1997-2005.
