基于文本挖掘技术的铁路安监人员履职分析
2019-10-23李新琴马小宁杨连报
李新琴,马小宁,王 喆,邹 丹,杨连报
(1.中国铁道科学研究院 研究生部, 北京 100081;2.中国铁道科学研究院集团有限公司 铁路大数据研究与应用创新中心, 北京 100081)
铁路安监人员履职系统中主要包括2部分内容。(1)履职项目及计划。管理人员根据《管理人员月度安全履职考评表》,在系统中录入岗位履职项目,根据履职项目维护每月工作计划和量化指标。(2)履职写实。管理人员下现场检查或者发现问题时,在系统中选择对应的工作计划录入写实信息。系统在长期上述工作中积累了大量的人员履职文本数据,该类数据包含了人员实际工作情况,但这些数据长期靠人工进行分析,通常由于数据量大和人为原因等因素造成数据分析不及时、不可靠等问题。使用基于文本挖掘的文本相似度计算技术,自动计算计划和写实是否匹配,在以非结构化数据为主体的大数据时代[1-2]具有重要的研究和实践意义。
文本相似度计算[3-4]即计算两个文本之间的相似性,在信息检索、数据挖掘、机器翻译等领域有广泛的应用。国内外学者对文本相似度计算方法的研究取得了很多成果。主要方法有:基于词匹配的方法、基于词向量的方法[5]以及基于神经网络的计算方法[6]。但这些方法都是用于处理通用的自然语言,其数据格式及记录的关键要素都不确定。
铁路安监人员履职计划与写实数据具有相同的关键要素,都包括时间、地点、任务等关键信息。根据安监人员履职数据的特点,本文提出分阶段实现人员履职文本相似度的计算方法。首先利用命名实体识别技术抽取数据中的命名实体,然后利用概念相似度算法,计算对应实体之间的相似度,根据计算结果判断两个文本是否相似。
1 文本相似度计算流程
人员履职计划与写实相似度计算过程主要包括文本预处理、命名实体识别过程、概念相似度计算过程以及最后的综合分析过程。整体流程如图 1 所示。
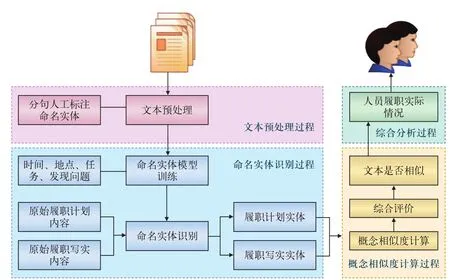
图1 文本相似度计算流程图
1.1 文本预处理过程
将原始人员履职计划和履职写实分别按换行和句号分为多个任务,每个任务加清晰的编号。根据任务记录的内容特点,将提取的命名实体定义为:时间、地点、任务。采用B(开始)、I(内部)、O(其他)、E(结束)、S(单个)的方式标注命名实体。
1.2 命名实体识别过程
命名实体识别过程分为模型训练和模型应用2个步骤。模型训练采用基于深度学习的双向长短时记忆(BiLSTM)算法和条件随机场(CRF)相结合的BiLSTM-CRF模型,将标注好的语料应用在该模型中,训练模型,使其达到较高的准确度。模型应用将原始的履职计划和履职写实内容分别放入训练好的模型中,模型自动抽取时间、地点、任务关键要素,以备概念相似度计算过程中使用。
1.3 概念相似度计算过程

图2 概念相似度计算过程示意图
如图2所示,概念相似度计算过程主要分为以下3部分。(1)分别计算履职计划的实体与履职写实对应实体之间的相似度,得出两个文本之间的实体相似度。(2)根据实体的重要程度设置实体相应的权重。例如,在时间、地点、任务这3个实体中,时间是较为不重要的实体,因为工作计划通常是月计划,而工作写实需要填报每天的工作,所以时间就较不重要;相反,任务和地点是较为重要的概念,所以任务和地点之间匹配相似度高,就基本能认定是相同任务,可以认定该条计划和写实相匹配。(3)设定相似度阈值,本文选定阈值为0.8,文本之间的相似度高于0.8就认为是这两个文本是相似的。
1.4 综合分析过程
按照上述流程得出两个文本内容是否相似后,就可以对人员履职数据进行综合分析,主要分析人员工作计划的实际执行情况。
2 命名实体识别模型
命名实体识别是指识别特定意义的文本实体,通常包括名字的人、地方、机构等[7]。
2.1 数据标注
有监督的深度学习算法一般需要大量的标注数据。所以在模型训练之前,需要标注大量的文本数据。数据标注的具体流程如下。
(1)根据分析需求、人员计划和写实记录的文本特征,定义3个命名实体,实体类别如表1所示。
(2) 为区分一个完整的实体,使用BIOES标记与命名实体定义相结合来标注数据。B、I、E分别代表一个多字符实体的开始、中间部分和结束;S表示只有一个字符实体;O表示其他字符,而不是定义的实体。例如,一个时间实体第一个字符被标注为B-TIM,其余字符被标记为I-TIM,因为最后一个字符会被程序自动标记为E-TIM。样本句子的平均长度约为30个字符。

表1 命名实体类别列表
2.2 命名实体识别模型
命名实体识别模型由字符嵌入(Word Embedding)层、BiLSTM层以及CRF层组成。整个模型的神经网络框架如图3所示。模型通过字符嵌入层来构建每个句子中中文的特征表示,并将特征表示向量放入到BiLSTM层;在BiLSTM层得到一个字符特征向量的隐藏状态;在CRF层,对输入的句子进行最后的预测标签解码。整个神经网络利用tensorflow深度学习框架来实现。

图3 命名实体识别模型框架图
2.2.1 字符嵌入层
在字符嵌入层中对词汇进行高维表示,本模型使用了2种方式来表示字符。
(1)利用基于中文wiki语料库的genism开源库来表示字符,每个字符用100维的向量表示。
(2)基于结巴分词的字典表示字符,经过分词之后的每个字符,如果是由单个字符组成的用0表示,两个字符组成的用1和3表示,3个字符用1、2、3表示。每个字符用20维向量表示。
将这2种方式的表示结果都输入到BiLSTM层。
2.2.2BiLSTM层
长短时记忆网络(LSTM)是一种特殊的循环神经网络(RNN),可以学习长期的依赖信息,特别是信息间的关联。由遗忘门、输入门和输出门保护和控制神经元。遗忘门控制哪些信息可以摒弃;输入门控制新的信息哪些需要存储;输出门控制哪些信息应该输出。LSTM网络部分流程如图4所示。LSTM单元的具体工作流程如式(1)~(5)所示。

其中:it、ft、ot分别表示t时刻输入门、遗忘门和输出门的单元状态;Ct表示t时刻的神经元;xt和ht表示输入向量和隐藏层在t时刻的向量;σ指sigmoid激活函数;Wi和bi是权重向量和偏置向量。
BiLSTM即由两个LSTM组成的网络,一个LSTM从左往右处理序列,包含了数据的过去信息,称之为前向隐藏层;另一个LSTM从右往左处理数据,包含数据的将来信息,称之为后向隐藏层。所以BiLSTM的最终隐藏状态是前后隐藏层的连接,如式(6)~(8)所示。

2.2.3 CRF层
在最后的预测序列中,考虑标签之间的相关性是十分必要的,比如在输入的序列中,I-TIM不可能在I-LOC后面,这些限制信息可以被CRF层在训练过程中自动学习到。所以,需要在模型中加入CRF层。如果采用识别模型中常用的softmax层来预测最后的标签,这些约束可能会被破坏。
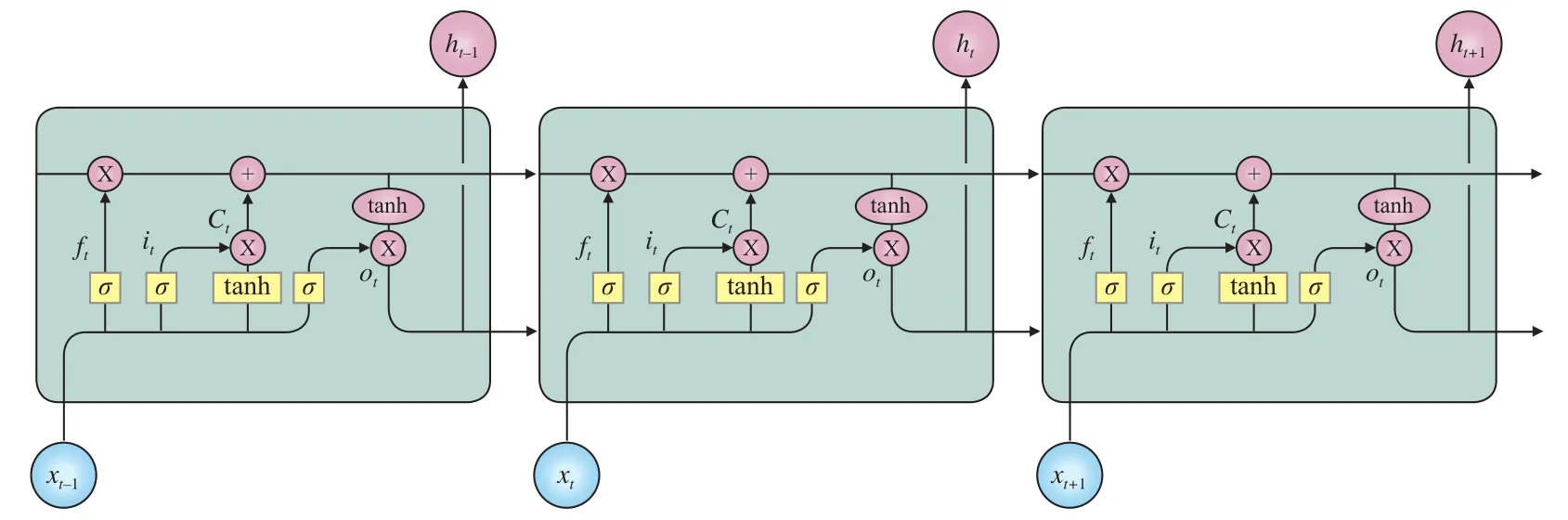
图4 长短时记忆网络部分流程图
3 概念相似度计算
本文使用基于知网的概念相似度方法计算两个对应命名实体之间的相似度。知网是一个以汉语和英语的词语所代表的概念为描述对象,以揭示概念与概念之间以及概念所具有的属性之间的关系为基本内容的常识知识库[8-10]。义原是描述一个概念的最小单位。知网中由义原组成概念,其相似度计算方法是一种基于世界知识的计算方法,是用一系列义原来对每一个概念进行描述。知网采用1500多个义原,将其分为 10 个类别,包括:事件(Event)、实体(entity)、属性(attribute)、属性值(aValue)、数量(quantity)、数量值(qValue)、次要特征(SecondaryFeature)、语法(syntax)、动态角色(EventRole)、动态属性(EventFeatures),并将这些义原分为4组,包括:基本义原,用来描述单个概念的语义特征;语法义原,用来描述语法特征;关系义原,用于描述概念与概念之间的关系;以及其他义原。
3.1 未登录词处理
经过对文本的命名实体的抽取,抽取到的时间、地点词语都属于实词,但是有些任务实体是短语,所以在知网原始语料中存在不包含该短语或词语的问题,需要对未登录词进行处理,流程如图5所示。
当计算的词语或短语不包含在知网的语料库中,则将未登录词进行概念切分,形成多个概念的线性链表,并倒排组织,如“信号机”切分完毕后存放成[机]→[信号],通常取最后3个概念,然后将概念列表中的概念按顺序合并,两个概念之间,如果第2个概念是虚词,则直接取第1个概念,否则两个概念相加。经过未登录词处理后的实体都属于实词,所以在这只考虑实词之间的相似度。
3.2 概念相似度计算过程
计算实词之间相似度的基本思想是:整体相似要建立在部分相似的基础上。把一个复杂的整体分解成几部分,通过计算部分之间的相似度得到整体的相似度。

图5 未登录词处理流程图
实词概念的语义表达式分为4个部分:独立义原描述、关系义原描述、符号义原描述以及其他独立义原描述,4部分相似度计算方法不同。
独立义原相似度计算方法如式(9)所示。

其中:Sim1表示独立义原相似度;S11、S12表示两个独立义原;l表示两个独立义原在概念层次体系中相等的距离;d1、d2是义原在概念层次体系中的路径长度。
关系义原、符号义原以及其他独立义原的相似度计算采用均值计算方法,如式(10)所示。

其中 :n=2,3,4 ;Sim2(S21,S22)、Sim3(S31,S32)、Sim3(S31,S32)分别表示两个关系义原、符号义原和其他独立义原的相似度;L2、L3、L4分别表示两个关系义原、符号义原和其他独立义原在概念层次体系中的最大长度;i=0,1,…,Ln;j=0,1,…Ln;Simi,j表示第i层的S11和第j层的S12之间的相似度。
其中:n=1,…,4;βn为各义原对应的权值,由于Sim1到Sim4对概念的重要程度不同,其中独立义原Sim1反应了一个概念最主要的特征,所以权值应设置为最大,一般在0.5以上,且有β1+β2+β3+β4=1,β1≥β2≥β3≥β4,本文取β1=0.5,β2=0.2,β3=0.17,β4=0.13。
4 方法验证
以某铁路局2017年7月到2018年1月期间的6万多条人员履职数据作为实验数据,对本文的相似度计算方法进行验证。其中,80%的数据作为训练样本,20%作为测试样本。以TensorFlow1.2和Python3.6为开发工具,采用准确度(Precision)和召回率(Recall)作为算法评价和对比的指标。
其中,Precision计算公式为:

其中:C为样本的总数;c为类别总数;TPi为被正确分到此类的样本个数,TNi为被正确识别不在此类的样本个数,FPi为被误分到此类的样本个数,FNi为属于此类但被误分到其它类的样本个数。
采用LSTM-CRF算法抽取人员履职计划与写实命名实体,试验结果如表2所示,时间、地点、任务3类实体识别准确率都在90%以上。利用概念相似度计算实体之间相似性,判断人员履职计划与写实是否匹配,其结果如表3所示,匹配结果准确度为83.45%。

表2 命名实体抽取结果

表3 人员履职计划与写实匹配结果
5 结束语
本文采用文本挖掘领域经典应用场景及技术,分步进行文本相似度计算,实现了对铁路人员履职行为的初步分析。基于命名实体识别技术将非结构化文本数据转为结构化数据,转化后的结构化数据可为该类问题的研究人员提供更多维度的信息。
