基于案件现实条件的法庭说话人识别系统验证
2019-10-23张翠玲
张翠玲
(1.西南政法大学刑事侦查学院, 重庆 401120; 2.重庆高校刑事科学技术重点实验室, 重庆 401120)
0 引言
法庭说话人识别通过分析比较案件录音证据中未知身份的说话人语音(检材语音)与已知身份的嫌疑人语音(样本语音),进而推断二者的同源性。随着该技术的不断发展,各国法庭科学实验室在特征提取、分析方法、识别系统以及评价体系等方面出现了多态化局面。近年来,国际上对于法庭科学的要求不断提高,在客观性、透明性、重复性等要求以外,还专门提出了验证要求:在运用任何法庭分析方法或系统之前,都应该基于被检案件实际条件进行系统验证和评价。这是保证其司法应用的前提和基础。
美国前总统奥巴马的科学技术顾问委员会在2016年9月发布的PCAST报告[1]中指出:为了确保法庭科学中特征比较方法的科学有效性,“必须明确法庭分析方法有效性和可靠性的科学标准”“必须对具体的法庭分析方法进行评估,以明确其是否已被科学地确定为有效可靠”。澳大利亚及新西兰等国的法庭科学专家联合发表声明对此予以支持[2]。Lander指出:“如果没有真正的实验证据证明,法庭特征比较方法能够在适合其预期用途的准确度水平以及与此用途合理相关的情况下得出结论,检验人员得出两个样本可能同源的结论是毫无意义的。”[3]英国也明确规定:“所有的法庭分析方法和程序都要进行验证”,并且发布了验证细则[4]。
鉴于国际上对“方法验证”的迫切要求和法庭说话人识别司法实践的需要,本文首先从国际上对于科学证据的要求出发,阐明进行法庭说话人识别方法及系统验证的重要性和必要性;其次介绍系统验证的基本原则和程序方法;最后通过一项多系统验证评价的范例,说明司法实践中应该如何进行法庭说话人识别系统的验证评测。
1 系统验证的基本原则
本文的“系统”为广义概念,是特征方法的总称,包括法庭说话人识别的全部过程,如语音前期处理、参数特征的提取和测量,特征的分析比较、统计建模、失配补偿以及识别评分等。目前,法庭说话人识别的方法主要有基于人工专家分析评价的听觉-语音学方法和基于自动技术的半自动-自动识别方法。不管基于哪种方法,从语音前期处理开始,到识别结果输出为止,任何一种组合都可以称之为一套“系统”。人工专家也是系统的一部分。
系统验证的基本原则是:基于被检案件,在反映案件实际条件下,利用结果已知的语音数据库进行系统训练和验证测试。语音具有较大的变异性,不同录音条件(讲话环境、背景噪声、设备信道、存储格式等)和不同的言语条件(情绪、心理、对象、场合、疾病等)都会使语音产生变化,进而影响系统的性能。实验室条件下的验证结果并不能代表实际案件条件下的系统性能,案件现实条件下的系统性能往往比实验室条件差,有时甚至差很多,因此,基于实际案件条件进行验证测试是必须的。此外,由于案件条件各有不同,还应该进行个案条件下的验证测试。
2 系统验证的程序方法
首先,利用训练数据进行系统训练;然后,利用测试数据进行系统测试;最后,将测试结果与真实情况进行比较,并通过相应的性能指标来评价系统识别的准确性和可靠性。
2.1 训练和测试数据
司法实践中很难采集全代表所有案件条件的语音数据,但是建立具有代表性、大规模的基础语音数据库还是必要且可行的。首先,建立一个实验室条件下的、具有代表性的、反映典型案件言语风格的高质量基础语音数据库[5]。然后,根据被检案件的实际条件进行语音信号的模拟处理。用于系统验证的所有训练数据和测试数据均要模拟实际案件的检材条件和样本条件,以代表相关人群并反映实际案件的言语风格和录音条件。至于训练数据和测试数据的规模,原则上应该越大越好。但是,考虑到现实的成本和时效要求,训练数据库和测试数据库的规模应该至少在几十人以上,才能保证合理的系统性能。当然,系统的性能能否满足要求,还要取决于法庭。
2.2 验证方法
系统验证分为训练、测试和评价3部分。训练部分是根据每个系统的实际情况,采用训练集数据进行系统训练,具体训练方法不做要求。但是对于测试部分,必须使用全部测试集数据进行测试。将测试集中的每个检材条件录音与每个样本条件录音进行全交叉比较,最后对结果进行统计分析。
国际上,法庭说话人识别正在经历新旧范式的转换。新范式以似然比(Likelihood Ratio,LR)框架为核心,基于相关数据、定量测量和统计模型计算似然比,通过LR值量化评估语音证据的价值[6]。LR框架已经成为国际法庭证据评价的标准框架,本文讨论的也是基于LR框架的法庭说话人识别系统。当然,对于主要依靠专家主观判断的“专家”系统和以“是或否”的二分性结果为输出的自动系统也可以进行同样的验证,只不过评价的性能指标略有差别而已。然而,需要指出的是,由于训练和测试的规模较大,全交叉比较耗时费力,对“专家”系统来说,进行这种验证的现实性和可操作性都很差,甚至几乎不可能。
2.3 评价指标
对系统进行识别测试,结果统一以LR数值形式输出。计算评价指标,并以数值和图示形式展示。系统的准确性和可靠性评价指标[7]主要有:对数似然比代价函数(Log likelihood ratio cost,Cllr)、95%的可靠区间(Credible Interval,CI)和等误率(Equal Error Rate,EER)。Cllr的计算公式[8]如下:
(1)
式中,Ns和Nd分别是同一话者和不同话者测试对的数量,LRs和LRd分别是同一话者和不同话者测试对比较的LR值。Cllr值小于1,说明系统有效。Cllr值越小,系统的准确性越好。
95%CI测量的是来自同一话者自身比较的多个LR值和来自不同话者之间比较的多个LR值的变化分布情况,以±log10来标度,具体计算方法见文献[9]。95%CI值越小,系统的可靠性越好。等误率则是错误接受(认定)率和错误拒绝(否定)率相等时的概率,与判别先验和阈限设定密切相关。等误率越低,系统的准确性越好。
系统评价图示主要有:Cllr-95%CI图、Tippett图(Tippett Plot)、检测错误权衡图(Detection Error Tradeoff Plot,DET plot)和期望交叉熵图(Empirical Cross Entropy plot, ECE plot)[9]。
Cllr-95%CI图是系统准确性和可靠性的综合评价。Tippett图只是准确性评价,但包含信息丰富。总体上,同一话者比较曲线与不同话者比较曲线的分开程度越大,准确性越好。DET 图只显示错误接受率和错误拒绝率之间的关系,曲线越接近原点,系统的准确性越好。而沿原点画对角线与曲线相交点对应的值,就是等误率。ECE是总体Cllr的扩展,使用指定的先验比和测试的似然比计算后验比,其计算公式[9]如下:
(2)
式中,Pss和Pds分别是同一话者假设和不同话者假设的先验概率,LRss和LRds分别是同一话者和不同话者测试对比较的LR值,Nss和Nds分别是同一话者和不同话者测试对的数量。ECE图表明系统校准的情况,交叉熵的值越小,校准优化前后的两条曲线越接近,系统的性能越好。关于这些指标和图示的详细解释见文献[9]。
3 验证范例
本文以国际上开展的一项法庭说话人识别系统验证项目(forensic_eval_01)[9]为例,说明系统验证的具体程序和方法。参与该验证项目的各个实验室基于同一个反映一起实际案件条件的语音数据库,对各自的法庭说话人识别系统进行测试评价,结果发表在国际期刊“Speech Communication”专版。目前,已经完成验证测试的法庭说话人识别系统有4个,均为自动识别系统。关于该项目的详细情况见文献[9-12]。
3.1 训练和测试数据
实际案件为一起诈骗案。检材录音为座机电话播打到呼叫中心的自动电话录音,内含办公室背景噪音,检材录音采用压缩格式。对话内容包含姓名、地址、号码和字母等信息。未知说话人语音时长为46 s。样本语音为警察讯问录音,有较大的室内混响和通风系统噪音,与检材不同的压缩格式。检材语音和样本语音均为成年男性澳大利亚英语口音。
训练和测试录音选自澳大利亚英语数据库[13]。首先,采用信号处理技术,模拟实际案件的电话传输信道、压缩格式。然后,再添加相应噪声和混响。最后,形成两组录音:一组反映案件中检材录音的言语风格和录音条件;另一组反映案件中样本录音的言语风格和录音条件。用于系统验证的语音数据库中共包含166名成年男性的非同期录音:其中,训练集105人,共423个录音(检材条件191个,样本条件232个);测试集61人,共223个录音(检材条件61个,样本条件162个)。
3.2 验证方法及评价指标
首先,采用训练数据进行系统训练(具体训练方法不做要求,使用全部数据或部分数据均可),然后统一使用测试集的全部数据进行测试。将测试集中的每个检材条件录音与每个样本条件录音进行全交叉比较,共得到111个同一话者比较对和9720个不同话者比较对。研究人员根据自己的研究问题设计方案,然后进行相应训练和测试。系统结果输出均为LR值。评价指标统一采用Cllr、95%CI和EER。图示统一采用Cllr-95%CI图、Tippett图、DET 图和ECE图[9]。
3.3 验证系统及测试内容
3.3.1 Batvox 3.1
这是AGNITI公司开发的专业法庭说话人识别系统。提取的声学特征为19个MFCC及其delta,频率范围为300~4 000 Hz。倒谱平均减法(Cepstral Mean Subtraction,CMS)、相对光谱滤波(Relative Spectral Filtering,RASTA)和特征弯折(Feature Warping,FW)技术用于特征级失配补偿。系统使用GMM-UBM模型方法计算得分。通用背景模型(UBM)和说话人模型均为高斯混合模型(GMM),说话人模型通过来自UBM的最大后验(Maximum A Posteriori,MAP)估计进行自适应训练。扰动属性投影(Nuisance Attribute Projection,NAP)作为失配补偿技术应用于GMM均值。
用户可以输入一组代表案件条件的“参考人群(reference population)”录音,也可以让系统从全部参考录音中自动筛选参考数据子集。用户还可以输入一组代表相关人群和检材条件的“伪冒者(imposter)”录音。系统首先计算检材语音与样本语音模型比较的得分,然后进行得分转换,在变换得分值处,同一话者模型概率与不同话者模型概率之比,即为LR值。
该测试关注的问题是训练数据量大小对系统性能的影响。从训练数据中随机选择25、50、75和100人等4个不同规模的数据集进行系统训练,同步使用相同数量的“伪冒者”参考数据。利用测试集分别对这4种情况进行训练和识别。
3.3.2 Batvox 4.1
该系统是Batvox 3.1的升级版本,也是目前最新版本。新版本将GMM-UBM模型方法更新为i-vector PLDA模型方法。系统通过i-vector和概率线性判别分析(Probabilistic Linear Discriminant Analysis,PLDA)进行得分计算,更好地解决了信道失配问题。
该测试关注的问题是使用“伪冒者”和系统自动筛选参考人群子集是否能够提高系统的识别效果。将训练集中105人(每人一个)的录音全部输入系统,然后分别对使用全部105人的参考数据、使用自动筛选的30人参考数据、使用“伪冒者”和不使用“伪冒者”等4种模式进行训练和识别。
3.3.3 MSR toolkit
这是微软研究院开发的说话人识别开源工具包(Microsoft Research Identity Toolbox, 1.0版本),是Matlab工具和程序的集合。它包括GMM-UBM和i-vector PLDA两种模型系统。两个系统使用的声学特征都是14个MFCC及其delta,提取的频率范围为300~3 400 Hz。用户可以自主选择工具包进行系统设计和参数选择,如使用语音活动检测(Voice Activity Detection,VAD)技术和各种失配补偿技术等。两种系统均采用逻辑回归(Logistic Regression,LR)方法进行从得分到LR值的转换校准。
该测试关注的问题是3种特征级失配补偿技术及其分别在VAD前、VAD后使用对说话人识别的有效性问题。这3种技术分别是倒谱均值减法(Global Cepstral Mean Subtraction, CMS)、倒谱均值减法及方差归一化(Global Cepstral Mean and Variance Normalization,CMVN)、特征弯折(Local Feature Warping,FW),将训练集中105人的录音(每人一个)全部输入系统,然后在VAD前和VAD后分别应用这3种补偿技术进行训练和识别。
3.4 结果及评价
3.4.1 训练样本选择对识别性能的影响
由于4种系统的评价采用的都是相同的训练数据、测试数据库和结果评价指标,故便于各系统之间的比较。现将各系统关注的问题及结果进行分析比较:
Batvox是商业集成系统,用户可以调整和选择的余地很小,因此两个版本系统测试的都是训练选择对系统性能的影响。参考人群样本的选择,特别是样本规模的大小对说话人识别的影响一直是业内关注的焦点问题。两个系统的测试均表明:使用最大数目训练样本的测试组的识别效果最好。
对3.1版本的测试结果表明,随着训练样本数量的增大,系统识别的性能逐步提高,准确性和可靠性均持续提高。其中,Cllr值从25人训练集的1.142持续下降到100人训练集的0.593,95%CI从1.779持续下降到1.130。25人训练集与50人训练集之间差别最大。而当训练集从50人(Cllr=0.740)增加到75人(Cllr=0.696),再增加到100人时,Cllr值并没有呈线性渐进。显然,25人的样本量是不够的,无法满足法庭实践的要求。但是究竟参考人群的数目达到多少可以得到合理的或者比较理想的识别性能,并且不再需要增加样本数,目前还无法下定论。
对4.1版本的测试结果表明,训练的数据量大小对系统的性能影响很大,而使用“伪冒者”模式可以提高系统的识别性能。当使用全部训练数据和等数量“伪冒者”时,Cllr值从0.456下降到0.365,95%CI从1.477下降到1.156;仅使用30人的训练子集和等数量“伪冒者”时,Cllr值从0.646下降到0.431,95%CI从1.382下降到1.148。不管是否使用“伪冒者”模式,使用全部105人训练数据的识别效果都明显好于让系统从中自动筛选30人子集的识别效果:不使用“伪冒者”模式下,Cllr值从0.604下降到0.391;使用“伪冒者”模式下,Cllr值从0.431下降到0.0.365。综合看,Batvox4.1的系统性能优于 Batvox3.1。
3.4.2 VAD及特征失配补偿技术的有效性
VAD技术主要用于检测语音信号的存在。失配补偿技术则主要用于对录音之间由于各种因素造成的声学特性不匹配情况进行补偿,使不同话者之间的差距最大化,使这些因素的影响最小化。二者都是自动说话人识别中常用的语音处理技术。特征级失配补偿主要适用于录制信道和背景噪声的补偿。
两种MSR toolkit系统测试的结果均表明:在VAD后进行特征补偿的效果普遍好于在VAD前进行特征补偿,这说明去除噪声和静音帧后进行特征失配补偿可以提高系统的识别性能。此外,在3种特征补偿技术中,效果最好的是特征弯折,最差的是倒谱均值减法。在VAD后分别使用CMS方法、CMVN方法和FW方法进行特征失配补偿,GMM-UBM系统的Cllr值分别为0.576、0.584、0.619;i-vector PLDA系统的Cllr值分别为0.449、0.478、0.469。综合看,i-vector PLDA系统的准确性指标普遍好于GMM-UBM系统,可靠性指标则恰好相反,但差别不大。
3.4.3 不同模型系统之间的比较
提取各系统中测试结果最好(Cllr值最小)的一组数据,来比较不同模型系统的性能。表1列出了4种系统最佳测试结果的主要评价指标Cllr、95%CI、ERR值及其对应的设置项。
对比4种系统的数据可以看出,识别性能最好的是Batvox 4.1,最差的是Batvox 3.1,MSR toolkit居中。而在相同设置条件下,Batvox和MSR的各自两套系统中, i-vector PLDA系统的各项性能指标都明显优于GMM-UBM系统。这说明,i-vector PLDA系统的优势更为明显。
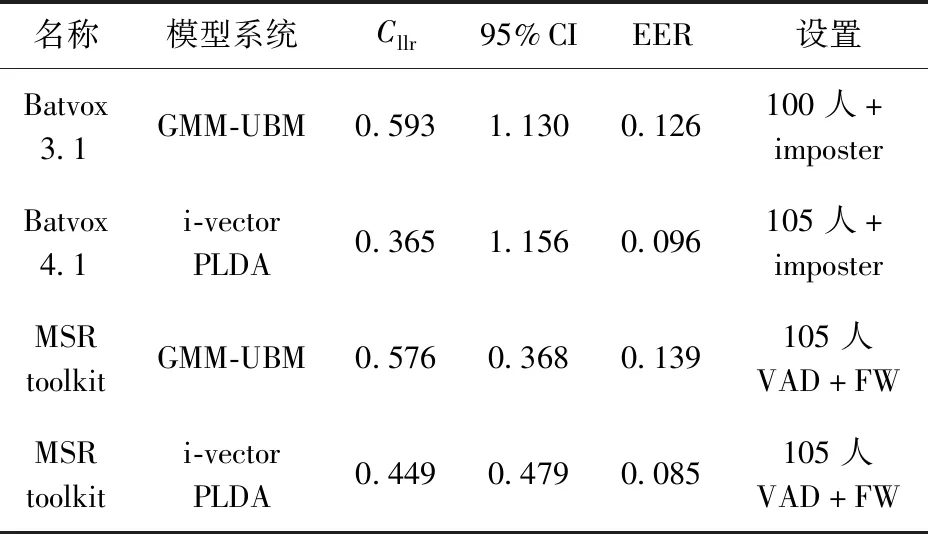
表1 4种系统最佳测试组的主要评价指标和设置项
3.5 主要结论
第一,用于系统训练的参考人群规模越大越好,但是究竟达到多大规模后无需再增,目前还不能下定论。第二,使用“伪冒者”模式进行系统训练可以提高系统的识别效果。第三,利用VAD技术去除噪声和静音帧后,再进行特征匹配补偿可以提高系统的识别性能。第四,3种特征级补偿技术中,特征弯折的效果最好。第五,i-vector PLDA系统的识别性能总体优于GMM-UBM系统。这些结论不仅可以表明和比较各系统的性能,更重要的是对后续研究如何提高系统的性能具有指导意义。
4 结语
验证目的是为了表明所使用方法或系统的准确性和可靠性,进而为司法实践中法庭证据的检验评价提供技术支持和量化依据。因此,就法庭科学的任何分支而言,进行这样的方法验证都是必要的。基于实验室条件的方法验证不能真实反映案件现实条件下的系统性能,只有基于被检案件的实际条件进行测试,才能真正验证系统在现实条件下的准确性和可靠性。此外,采用统一的训练和测试语音数据库,对不同方法系统进行验证测试和性能评价,不仅有利于系统之间的横向比较,更有利于司法实践中的重要理论和技术问题的解决。这对于提高法庭说话人识别技术的准确性和可靠性,保证其司法应用具有重要意义。
