基于K-means 算法的入侵检测系统研究
2019-10-22鲍海燕
鲍海燕
(晋中学院信息技术与工程学院,晋中030619)
1 入侵检测的基本原理
随着互联网的发展,传统的防护手段如加密手段、认证技术以及防火墙等对保护网络安全来说越来越无能为力。入侵检测技术能够进行相应策略制定,制定出比以往防火墙更加严格的审查方案,对内部程序的实时监测,有效地进行恶意软件的隔离与删除提示。入侵检测系统(IDS)使网管人员及时的处理入侵警报,识别防火墙不能识别的攻击,在发现入侵企图后提供必要的信息。IDS 需要更多的智能,它首先对数据进行分析,并且得出结果。
入侵检测系统对于系统配置、界面以及通信方面的管理,数据源有很多种,主要有电脑主机上的信息、网络信息以及其他系统信息,这里的入侵检测系统具体如图1 所示。

图1 入侵检测系统结构图
2 入侵检测中的K-means算法
2.1 传统的K-means算法
聚类分析是数据挖掘的主要任务之一。它从样本数据出发,自动进行分类。该过程主要体现了数据的中值处理方法,首先需要进行类的划分,该类主要设定一个阈值,并且把这一阈值中的程序数据看成拥有同一个中心的数据格式,并且将这些数据进行中心化处理,得到一个类的平均值,然后对这些类再次划分,进行高一层级的类划分,如此以往,到准则函数收敛完成为止。K-means 算法描述如表1 所示。

表1 K-means 算法描述
2.2 传统的K-means算法的缺点
K-means 算法存在如下问题:首先传统K-means算法的聚类个数是假设已知的,但事实却很难得到;其次选择合理的初始聚类中心是不容易实现的;无关点的影响会导致聚类中心偏离设定的位置,从而导致聚类不准确;对非球型的数据集聚类误差较大。
3 改进的K-means算法的入侵检测系统的设计
3.1 入侵检测系统的设计
使用Snort 现有的六个模块的成熟技术,加上关联分析器、聚类分析模块和异常检测引擎,便可从所需的训练数据中提取出入侵检测所需的数据和模式[3]。系统通过嗅探器发现问题,解码器进行解码,预处理器进行规则库里特征提取,检测引擎检测网络正常行为模式,进而进行聚类分析和日志记录。
入侵检测系统的模块包括数据包嗅探器、解码器、预处理器、检测引擎、规则库、输出模块、关联分析器、聚类分析模块、异常检测引擎[4]。
3.2 入侵检测系统的数据挖掘过程
入侵检测模型的数据挖掘流程:首先进行相应网络中数据文件的收集,对正常活动集利用K-means 算法进行数据挖掘,得到的正常数据用于异常入侵检测;其次收集出现的异常入侵数据集,在正常活动数据集中过滤入侵训练数据集,用分类算法实现挖掘及区分正常网络行为和入侵行为的区别,得到误用检测规则,误用检测便利用了这个不断更新获得的数据模型。基于数据挖掘的入侵检测的主要环节设计和总体流程如图2 所示。

图2 基于数据挖掘的入侵检测总体流程图
3.3 改进的K-means算法
改进的K-means 算法的基本思想是,在原有算法的基础上,用优化初始中心位置的方法,提高运行效率和质量。获取集合中分布密度高的数据块,为了使初始位置落在不同的类中,尽可能在距离相差大的块中获取初始位置。
文献[8]提出基于最优划分的初始中心选择方法,本文亦用数据集的概率分布特点和此方法结合起来得出改进的K-means 算法的起始中心。聚类密度是指为了得到k 个初始类划分,需要估计数据集的类分布情况(依据每个数据对象附近的数据分布集估计)。此初始聚类中心采用对象位置ai表示(ai为数据集中的每一个对象),取距离ai最近的mins(mins 为类密度数量)个对象,密度参数θ为对应的最小半径范围,θ的值和ai的值是反比关系。密度阈用z(表示密度参数的规定的临界值)表示,若θ比z 小,此数据对象称为高密度点。高密度集合V 是指所有的数据集中的高密度点的集合。在V 中选取k 个分布分散的高密度点,最大的对象称为b1,距离b1最远的对象称为高密度点b2,若密度点数量mins=7,假设有三个中心点,密度参数分别为5,9,3,密度阈值z=6,则三个中心点钟有两个小于密度阈值,这两个点为高密度点,组成的集合V 为高密度集合。计算V 中每个高密度点ai到每个类中心点的距离v(ai,b1),v(ai,b2),v(ai,bf-1),则第f 个类中心点满足:max(min(v(ai,b1),v(ai,b2),v(ai,bf-1))),第k 个高密度点集合为(b1,b2,…,bk)。
如果想得到较好的K-means 初始中心,就需要运用粒子群优化算法得到k 个初始类划分靠近类中心的位置。利用文献[1]迭代POS 算法(初始化每个粒子的位置、速度、全局最优位置和历史最有位置)找出个各类的最优全局位置,最终输出聚类结果。对于数据集A,集中包含m 个对象,n 个属性。对于数据集中的数据对象ai,初始最优位置为qi,数据集所有对象中第j个属性的变化范围:

第j 个属性的初始值为:

每一个对象都利用公式得到初始化最优位置,第l个对象局部最优位置到数据集中其他对象的最大距离,取其中最小值为全局最优位置,如公式(3)所示。

若第l 个对象的当前位置al满足,则用对象当前位置al更新局部最优位置ql,可得到新的局部最优位置,更新两个最优位置后,更新数据集中的对象速度(与对象的当前速度、局部最优位置、全局最优位置线性相关)。如此的迭代寻优,会在每个类中产生一个全局最优位置(当PSO 算法达到最大迭代次数时),此位置为类心。
将这k 个全局最有位置作为改进后的K-means 算法的起始聚类位置,改进后的K-means 算法描述如表2 所示。

表2 改进的K-means 算法描述
4 基于改进的K-means算法的入侵检测系统模型
根据改进的K-means 算法,提出了新的基于聚类的网络入侵检测模型,如图3 所示。

图3 改进的K-means算法入侵检测系统模型
上述模型中的原始数据来自网络运行中产生的以服务器网络日志为主的数据,数据收集模块的数据来源于检测及网上用抓包工具采集的IP 数据包。
采用数据挖掘技术提升入侵行为的检测率,通过训练数据提取出可用于入侵检测的模式及知识,将部分数据用来分析,建立起基于数据挖掘的入侵检测系统,系统具有以下几个优点[5]:
(1)智能性好
系统具有较高的自动化运行的能力,容易扩展,不仅提高了该系统的适用范围,通过研究人员的努力,也提高了检测的正确率。
(2)检测效率高
通过数据挖掘,可以大大提高处理数据的能力,通过对样本的一次提取,在一次提取过程中,抽取其中正确的部分与数据同时进行预处理,可以大大提高信息处理量。
(3)自适应能力比较强
由于系统选择的方法是一种应用数据挖掘方法,因此具有较高的适应能力,同时又能够对于入侵对象及其变种进行检测。
(4)误警率低
数据挖掘能够有效地去除重复的多种攻击数据,所以将数据挖掘应用于入侵检测中可以达到较低的误警率。
5 基于改进的K-means算法的入侵检测仿真实验分析
5.1 K-means算法的聚类效果进行比较
入侵检测实验系统是在Windows 10 的系统下搭建的,数据集采用的UCI 官网数据,实验用对iris 数据集、4k2_far 数据集和wine 数据集在传统K-means 算法和改进的K-means 算法的聚类效果进行比较,实验采用的是聚类评估指标是聚类纯度Purity 指标(0-1 之间),N 为数据集中数据对象数,k 是聚类数,Bj 是第j个聚类结果中聚类对象个数。定义如下:

聚类结果的准确率与Purity 指标成正比。本次仿真实验聚类效果如表3 所示。

表3 聚类效果对比表
5.2 入侵检测实验
改进的K-means 算法使用的数据集是KDD CUP99 数据集中的kddcup.data_10_percent 训练数据集中的4000 条数据,其中100 条标记为DoS 攻击类型的数据(smurf 攻击、pod 攻击、back 攻击各30 条,剩余的为teardrop 攻击),其余为正常数据。
使用K-means 算法聚类时的迭代代数F2=100,类密度数Mins=100,密度阈值w=1.45,利用PSO 迭代寻优时的最大迭代次数F1=10,取聚类值为k=3 和k=4 时做分析,传统的K-means 算法和改进的K-means 算法对比试验,每种聚类进行了两次实验。如表4-表5 所示。

表4 k=3 的聚类中心变化表
当k=3 时,传统的K-means 算法第2 次聚类实验出现了一个空聚类,改进的K-means 算法没有出现空聚类。
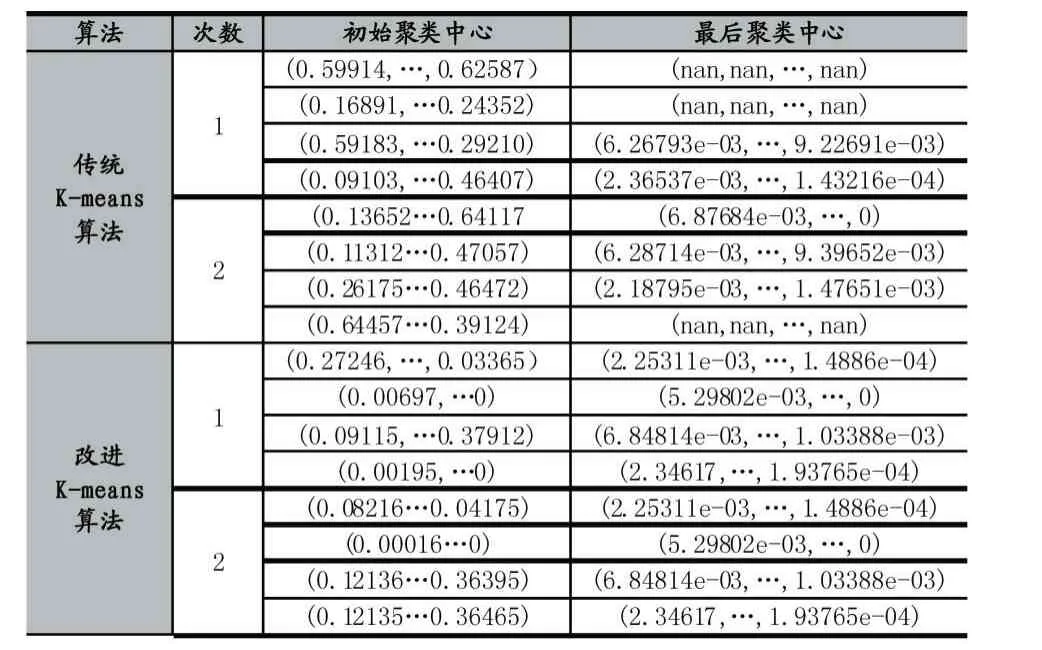
表5 k=4 的聚类中心变化表
当k=4 时,传统的K-means 算法第1 次聚类实验出现了两个空聚类,第2 次聚类实验出现了一个空聚类,改进的K-means 算法没有出现空聚类。
从上述的实验数据可以得到,在kddcup.data_10_percent 数据集进行聚类分析的过程中,K-means 算法可能出现空聚类,聚类结果波动较大。而改进的Kmeans 算法基本不会出现空聚类的现象,稳定性显著提高。
入侵检测的仿真模型有两个重要指标,检测率(JC)和误报率(WB),JC 由检测出来的异常记录数量除以测试集中总的异常记录数量。WB 由误判入侵的正常记录数除以测试集中总的正常记录数量。在k=3 和k=4 的情况下,取类标记β=2.75%,通过分析得到JC 和WB 的结果如表6 所示。

表6 入侵检测结果分析
从表中可以看出,传统K-means 算法的平均检测率为42%,改进的K-means 算法的平均检测率为74%,检测率提高了32%。传统K-means 算法的误报平均率为0.337%,改进的K-means 算法的误报平均率为0.179%,误报率下降了0.158%。
6 结语
本文主要是对K-means 算法应用于入侵检测系统做了详细的阐述。介绍了传统的K-means 算法和它的优缺点,提出了优化初始中心的K-means 算法的改进措施,改进的K-means 算法应用到入侵检测系统中,可提高入侵检测的成功率和降低误报率。
入侵检测技术和数据挖掘技术的结合,能在以前的入侵检测系统的基础上,更好地检测出入侵并加以防范。
