基于频繁模式的套餐关联分析与推荐
2019-10-22刘芳宇李嘉豪张琳琳
刘芳宇,李嘉豪,张琳琳
(南华大学计算机学院,衡阳421000)
0 引言
大型连锁酒店每天要接待上以百次的宴席,每个宴席又包含大大小小不同的桌次,满足不同桌位的不同菜品需求是酒店需要面临的现实性问题。每个桌次都统一规定一个菜单样式是现实生活中许多酒店宴席场合的订餐方式之一,虽然这种方案能很好地区性解决酒店统一购菜上菜的业务,但是众口难调,难以满足不同客户的特定需求。
虽然大型连锁酒店菜品很多,但是菜品的组合(即套餐)稀缺,酒店原有的固定菜品套餐已经远远不能满足客户点菜多样化的需要。现如今越来越多的客户更倾向于自己选择菜系的组合与搭配,酒店一直延续的固定套餐已经不能继续吸引新老客户,客户想要的是新颖的菜系组合搭配,并且希望酒店能方便快捷地提供菜系组合的方案。客户希望酒店能在已选菜品的基础上进行合理搭配推荐其他菜品。
为了酒店的发展利益以及满足客户的多样化需求,采用哪种方式为客户推荐套餐成为了一个亟待解决的问题。
1 问题分析
大型的酒店需要快速地为客户进行套餐推荐,而且酒店又需要及时掌控业务上订餐的实时数据信息,那么一个实时的Web 在线订餐系统将为首选方案,而套餐推荐算法的选取将成为问题解决的核心模块。
首先,多年经营的酒店都存有客户订餐的历史数据,根据历史订餐数据进行分析可以很容易得到哪些菜品受欢迎哪些菜品几乎卖不出去。基于这些简单分析,菜品关联分析思路应运而生,可以很自然地想到,对酒店历史的订单数据进行套餐间菜品的关联分析,挑选出频繁项集(最受欢迎的几个菜品)然后进行菜品的组合凑出新的套餐进行推荐。那么接下来就需要对关联分析算法做进一步选取与研究。
2 算法分析
数据挖掘就是设计挖掘算法并构建相应的挖掘模型来提取相应的信息。数据挖掘的一项关键分支就是关联规则,可见其重要性之大与应用之广,Agrawal 等人[1]最早于1993 年提出关联规则的概念,为了分析不同商品之间的内外联系,通过研究购物篮问题发现该算法理论。随着电商与信息系统的不断发展,交易数据库里面不断堆叠存储着大量的交易数据(如客户购买商品种类、数量、交易金额、交易时间等),通过对这些交易信息进行计算分析,可以分析得出哪些商品在某些时段被频繁购买,或者哪些商品经常一起被购买,从而取得一些普遍性的客户购买习惯与规律。电商也可以把这些规律信息作为进货、货物摆放的合理依据,从而达到更好的经济效益。
而本文,我们把关联规则用于分析菜品之间的联系,从而用于指导酒店推荐套餐,通过对菜品的关联分析,作为某几道菜能一并出现在一个套餐被推荐给客户的理论依据,验证套餐菜品组合搭配的合理性,从而满足客户对酒店套餐推荐的需求。当我们对数据进行关联分析的时候,一般可以分为以下几步。
第一步:设定最小支持度,遍历并搜集所有的频繁项目集,这是关联分析的前提。
第二步:指定最小置信度,在频繁项集中发现关联规则,生成对应的关联规则。
只有支持度与置信度都满足最低要求的规则才是有用的、合理的强关联规则。
2.1 Apriori算法
Apriori 算法[2]是由Agrawal 等人在事务数据库挖掘的项目集格空间理论的基础上研究出来的,该算法至今都是许多新发现的频繁项集挖掘算法的理论前提[3]。在阐述该算法之前,有几个定理需要提前说明。
定理一:若某项目集Y 不是频繁项集,则由Y 构造的所有超集也都不是频繁项集。
在定理一的基础之上,利用逆向思维,可以很容易得到第二个理论。
定理二:若某项目集Y 是一个频繁的项集,则Y的所有非空子集也都是频繁项集。
在得知这几个理论的基础之上,就可以对Apriori算法的核心过程进行描述。
算法一:Apriori(TransactionDataset T,Support minSupport)
输入:已知事务数据集T、已设定的最小支持计数值minSupport
输出:频繁项集S
(1)S1={frequent 1-itemsets};//所有频繁1 项集
(2)FOR(k=2;Sk-1≠Ø;k++)
(3){
(4)Ck=apriori-generate(Sk-1);//通过频繁(k-1)项集产生频繁k 候选集
(5)FOR each transactions t ∈T
(6){
(7) Ct=subset(Ck,t);//Ct是所有包含t 的候选元素组成的集合
(8) FOR each candidates c ∈Ct
(9) {
(10) c.support++;//支持数加一
(11) }
(12) Sk={c ∈Ck|c.support>minSupport};//挑选出所有支持度大于minSupport 的候选集
(13)}
(14)}
(15)S=S ⋃Sk;
计算得出所有的频繁项集之后就可以进一步处理生成关联规则。
算法二:GeneratingRules(frequent k-itemset sk,frequent n-itemset yn)
输入:频繁k 项目集、频繁n 项目集
输出:生成的强关联规则
(1)Y={(n-1)-itemsets yn-1|yn-1in yn};//获取频繁n 项集的频繁n-1 子项集Y
(2)FOR each yn-1in Y//遍历最长子项目集里面所有的元素
(3){
(4)temp_confidence=support(sk)/support(yn-1);//计算该条关联规则的置信度
(5)IF(temp_confidence>=min_confidence) //判断该关联规则置信度是否满足最低要求
(6){//置信度满足最低要求,这是一条合理的强关联规则
(7) Print the rule”yn-1→(sk-yn-1),support=support(sk),confidence=temp_confidence”;
(8)}
(9)IF(n-1>1)//若该项目集还存在非空子集,则递归调用该算法继续生成
(10){
(11) GeneratingRules(sk,yn-1);
(12)}
(13)}
算法三:RuleGenerate(S,minConfidence)
输入:频繁项集S、最小置信度
输出:强关联规则
(1)FOR each frequent itemset skin S//遍历所有的最长子集
(2){
(3)GeneratingRules(sk,sk);//递归调用该方法不断生成关联规则
(4)}
其中关联规则的生成大致分成三中类别,第一种全部利用频繁1 项集组合出频繁k 项集,第二种利用频繁1 项集跟频繁k-1 项集组合出频繁k 项集,第三种利用频繁k 项集跟频繁k 项集拼凑组合出新的频繁k 项集,显然该算法利用的是第三种方式。该算法的主要模块是GeneratingRules 的递归(算法描述如算法二),它的作用是生成一个频繁项集中所有的强关联规则。
2.2 FP_Growth算法
FP_Growth 算法[4]是由Han Jiawei 等人于2000 年研究出来的算法,该算法采用构建FP-Tree 于内存中的方式进行实现,由于FP-Tree 可以对前缀进行共享的特性,进而可以对原始数据集进行高效的数据压缩,不仅可以减少对原数据集的扫描次数而且可以对候选频繁项集的生成过程进行剪枝,最终达到提高挖掘效率的效果。
如图1 所示,一棵FP-Tree。
FP-Tree 具有以下几个特性,可以帮助我们理解频繁项目集的发现过程。
特性一:从FP-Tree 的头表结点中的xi结点出发可以链接得到所有包含xi的路径(频繁模式)
特性二:在FP-Tree 的任意路径P 中某结点xi的频繁模式只跟结点xi的前序子路径有关,并且可以把前序子路径上每个结点的支持度看做跟xi一致。
特性三:若x 是原始数据集中的频繁项目,假如y是项目x 条件模式基中的一个频繁项目,则y ⋃x 在原始数据集中也将频繁(频繁项目增长)。
特性四:假如FP-Tree 是一个只含有一条路径的树,那么这个FP-Tree 中所有频繁项目都是可以连通的,该子路径总体的支持计数值应该取路径中最小的统计值(木桶定律中的短板效应)。
算法四:FP_Growth(FP-Tree tree,pattern x)
输入:构建好的FP-Tree、条件模式x
输出:频繁项集S
(1)IF(P ∈tree)//若树tree 中存在一条路径P
(2){
(3)FOR each y(combination of node elements in the path P)//y 是路径P 中结点元素合并而成的
(4){//生成模式y ⋃x,并且支持度赋值为y 中结点元素支持度的最小值
(5) Generate pattern y ⋃ x(pattern support=minSupport of nodes in y);
(6)}
(7)}
(8)ELSE
(9){
(10)FOR each element eiin the header of tree//遍历tree中所有头元素
(11){
(12) generate pattern c=ei⋃x(pattern support=the support of ei);//产生模式c=ei⋃x
(13) construct conditional pattern of c;//构造c 的条件模式基
(14) construct FP-Tree treecbase on conditional pattern of c;//基于c 的条件模式基构造FPtree
(15) IF(treec≠Ø)//树非空
(16) {
(17) Call FP_Growth(treec,c);//递归调用
(18) }
(19)}
(20)}
3 算法模型搭建与套餐推荐分析
3.1 算法模型搭建
假设酒店的历史交易数据如表1 所示,一行表示一条订餐记录。
遍历酒店订单交易事务数据集挑选出频繁1 项集(作为表头结点),然后根据历史菜品套餐交易事务数据集构建FP-Tree,设定最小支持计数值为3、最小置信度等于0.5。

图2 FP-Tree的构建图
在构建完FP-Tree 以后,下一步就需要利用上面描述的FP_Growth 算法对菜品的关联规则进行挖掘,得出条件模式与所有满足条件的强关联规则,以菜品“茄子肉沫”作为被推导的结果为例,根据算法运行得出的关联规则如表2 所示。

表2 关联规则minSupport≥3,minConfidence≥0.5
3.2 套餐推荐分析
得出关联规则之后,常规的套餐推荐思路是:挑出支持度跟置信度最优的关联规则,将推导条件跟推导结果合并作为新的条件再进行关联分析推导出新的菜品结果,进过多次循环往复的推导,最终实现凑出一桌的菜品套餐。虽然这样能勉强满足菜品套餐推荐的需求,但是循环往复势必导致效率低下。
由定理一定理二,集合频繁非空子集也必定频繁,子集非频繁其超集也必定不频繁。通过上面的分析,既然我们通过频繁子集不断合并拼凑出频繁套餐的方式效率低下,那我们换位逆向思考,直接找出其最大频繁项集,然后取其子集就必定保证频繁。
以上面所举的例子分析,我们反向思考,把推导结果“茄子肉末”作为客户已选菜品的推荐前提条件,而把推导条件作为我们需要得出的套餐推荐结果。这样我们可以直接从推导条件较长的关联规则中进行考虑选取,将推导条件长的、支持度大的、置信度高的优先考虑作为套餐推荐的依据。这样我们就可以一次性推荐出一套的菜品而不是一次推出一个菜品,理论上运行效率能得到很大的提升。
以上面所举的例子思考,我们的推荐策略是:客户选取“肉沫茄子”这个菜,我们给客户推荐“四季豆炒肉,小炒肉,麻婆豆腐”或“四季豆炒肉,小炒肉”这样的一套菜品,而不是:客户选取“四季豆炒肉”这个菜,我们给客户推荐“肉末茄子”。
4 系统构建与运行效果
对系统数据库结构进行设计,其E-R 图如图3所示。
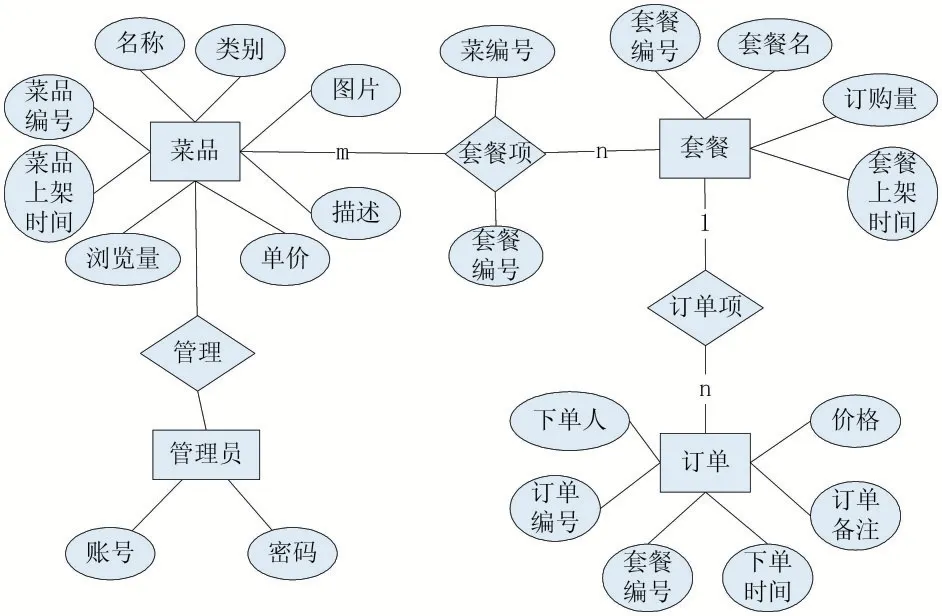
图3 系统数据库E-R图
从公开网络(例如网站:http://bj.xiaomishu.com/specials/)爬取各式的菜品数据信息,根据已爬取的菜品信息充实系统,作为系统与算法实现的基础。
用户可以先从系统中选取自己想要的菜品,用户选菜前系统状态如图4 所示。
系统根据算法推荐补全整个套餐(即套餐推荐),推荐结果如图5 所示。
5 结语
本文基于频繁模式的关联分析算法,结合实际的酒店套餐推荐需求,对原算法进行了良好的换位思考与合理应用。FP-Tree 算法巧妙地利用了树结构共用前缀的特性,结合剪枝过程从而实现了数据的压缩,原始事务数据的扫描次数得以减少,Apriori 算法的I/O瓶颈得以解决,但是FP-Tree 算法需要占用大量的内存空间,若树结构递归层次过深,内存将消耗殆尽。该算法适合重叠度较高的数据集,若套餐间菜品的关联重叠性不够,那么套餐推荐效果不佳。

图4 用户选菜前系统状态

图5 系统推荐补全用户套餐菜品
