基于Q学习算法的机场道面移动机器人路径规划研究
2019-10-21王淑玲卓丽
王淑玲 卓丽

摘 要:路径规划是移动机器人研究领域的热点问题。针对不同的规划需求,已经提出许多种路径规划的算法。本文考虑机场飞行场地环境,应用Q学习算法规划出点到点的静态安全避障路径。为进一步优化上述规划结果,提出了一种改进Q学习算法的方法,通过比较改进前后的路径规划结果,验证了改进方法的有效性。研究成果不仅给出该机场飞行场地环境中静态路径规划的方法,也为相关移动机器人的研发提供了理论依据。
关键词:移动机器人;Q学习算法;飞行场地;路径规划
1.引言
路径规划是移动机器人研究领域的热点问题,在很多方面都有应用,如无人机的避障飞行,巡航导弹躲避雷达搜索,GPS导航等,是完成复杂导航及其他任务的前提。路径规划可以描述为:移动机器人依据某些优化原则在运动空间中找到一条从起始状态到目标状态、可以避开障碍物的最优或接近最优的路径。起初,移动机器人路径规划技术主要集中在静态全局路径规划的研究,提出的算法包括栅格法、Dijkstra算法、A*算法等。后来,研究人员将重心倾向于局部路径规划上,而局部路径规划主要解决动态情况下完全未知或者局部未知工作环境的路径规划问题,这对路径规划算法的实时性有了更高的要求,已提出的算法包括人工势场法、遗传算法、蚁群算法等[1-7]。近年来,基于强化学习的路径规划在移动机器人的导航研究中变得越来越重要,成为国内外研究的热点[8-11]。
2.Q学习算法的基本原理
在机器学习范畴内,根据反馈的不同,机器学习可分为监督学习(Supervised learning)、无监督学习(Unsupervised learning)和强化学习(Reinforcement learning)三类[12],其中强化学习以环境的反馈信号作为输入,移动机器人使用这种算法可以实现从环境信息到行为映射的学习。
强化学习是一种在线的学习方法,其整体框图如图1所示。移动机器人将感知到的环境状态传递给强化学习算法,强化学习算法会选择一个动作,在完成相应的动作后移动机器人所处的环境会改变,此时根据改变后的环境状态反馈一个奖赏值给移动机器人。强化学习的基本要素有:策略、值函数、奖惩函数、环境模型。
根据问题的不同,强化学习方法主要分为两大类算法:一类是值函数估计法,如蒙特卡罗算法、Q-学习算法、瞬时差分法等;另一类是策略空间直接搜索法,如模拟退火法、遗传程序设计、遗传算法及一些改进方法等。本文重点研究Q-学习算法及其在某军用机场移动机器人路径规划中的应用。
Q-学习算法通过估计状态—动作对的值函数Q(s,a) 以寻求最优策略π* ,Q值更新规则如下:
式中,Q(st,at) 为状态st 后,所得到的累积加权奖赏。根据策略π进行状态集合与动作集合間的映射,即状态—动作对的值函数。在学习过程中通常将每个状态与所有动作的映射值建立一个查询表。α 为学习率,γ 为折扣因子。
3.移动机器人的路径规划
通过调研国内外的研究现状发现,在后勤装备保障领域,移动机器人有清扫机器人、搬运机器人、巡查机器人、车辆抢救机器人、排弹抢修机器人、自动加油机器人和医疗救助机器人等,主要遂行运输、装卸、加油、抢修技术装备、抢救病人等后勤保障任务。飞行场地是空军后勤装备保障领域机器人活动的主要场所之一。
上图是某机场的飞行场地,主要是供飞机起飞、着陆、滑行和停放的场地。由机场跑道、滑行道、联络道、拖机道、保险道、土跑道、平地区、停机坪、加油坪、校靶坪、防吹坪、平行道路等组成。 各主要组成部分的尺寸及位置关系如下:
跑道:在飞行场地的中部,长2000米,宽60米,用水泥混凝土筑成。
土跑道:在跑道旁边有一片宽阔平整的场地,它和跑道一样长,但比跑道宽一些,80米左右。
端保险道:在跑道的两头都有一片平整和密实的场地,它的长度为200米至400米,宽度为100米左右。
停机坪:在跑道一侧约100米远的地方,有一些用水泥混凝土浇筑成的地坪,供停放飞机用。
滑行道:在跑道一侧100米的地方,与跑道平行的主滑行道,用水泥混凝土筑成,其宽度为40米。
联络道:主滑行道中部与跑道相联接的部分,叫中间联络道。两头与跑道相联接的部分,叫端联络道。联络道的宽度为100米。
平地区:主滑行道与跑道之间的一块平整的地面。
下面,我们将应用Q-学习算法对移动机器人的路径进行规划。
3.1 环境建模
首先构建环境模型,在状态s下执行完动作a后依据环境模型可以得出下一个状态和奖赏值R。本文采用栅格法在坐标系中建立二维栅格地图表示环境信息,栅格地图将移动机器人所处的场地环境(包括跑道、主滑行道、平地区及联络道)分解为小栅格,每个小栅格对应于移动机器人的一个状态。每个状态对应于环境状态集合S中的一个元素,每个栅格存在两种状态值0和1。其中,0表示此栅格为安全区域,在地图中表示为白色方块;1表示此栅格为危险区域(主要指平地区),存在障碍物,在地图中表示为黑色方块。坐标系中的线段(x,0) 、(0,y) 、(xmax,0) 、(0,ymax) 表示环境的边界区域,即实际环境中的墙壁,蓝色方块区表示移动机器人的起点位置,红色方块区域则表示目标点位置。环境中的目标位置和障碍物都处于静止状态,且对于机器人而言环境中的障碍物及边界位置是未知的。若栅格的宽度为1米,则整个环境为一个2000×200 的栅格世界,共形成了2000×200=400000 个环境状态,不便于显示工作环境模型及路径规划的结果,因此本文设置栅格长度为100米,宽度为10米,则整个环境为一个20×20=400 的栅格世界。移动机器人的工作环境建模如下图所示:
3.2 动作空间的表示
移动机器人根据策略π来选择动作,π:S→A 表示状态到动作的映射。其中S 是状态集、A 是动作集,它们定义了移动机器人在状态s 下应选择哪个动作来执行。相对于机场的尺寸及面积,移动机器人的尺寸较小,为简单起见,将移动机器人视作一个质点,不考虑机器人的尺寸大小,用一个蓝色的圆圈表示。以移动机器人为中心,定义机器人的真实动作空间模型A为上、下、左、右四个离散动作,即下式的矩阵:
。
3.3 动作选择策略
常用的动作策略方法包括:ε- greedy策略、Boltzmann分布策略及模拟退火策略。本文选用基于近似动作空间模型的模拟退火策略,通过观测机器人周围的环境信息,有针对性的对真实的动作空间模型A进行简化处理,得到与之相似的动作模型 ,然后利用模拟退火策略选择 中的一个动作并执行。
3.4 奖赏函数的设计
奖赏函数是执行动作a后对产生的结果进行的一个评价性反馈。如果执行完动作a 后移动机器人达到一个有益于最终目标的状态,则R值是正数。相反的,如果是一个不理想的状态,则R值是负数。
奖赏函数在机器人学习过程中起到了导向性的作用,强化学习的目标就是使机器人最终获得的总的奖赏值达到最大,并找到最优策略使得机器人从起点无碰撞的运动到目标点。因此需要及时准确的反映机器人在不同状态下不同行为策略的好坏,设计良好的奖赏函数足以满足这一需求。本文采用如下分段函数表示立即奖赏函数:
式中,s 表示机器人所处的状态,1表示此栅格为危险区域(主要指平地区),存在障碍物,在地图中表示为黑色方块。从上式可知,当机器人到达目标点时,获得最大的立即奖赏值100;当机器人与障碍物发生冲突时,获得的奖赏值为-1;其他情形下的奖赏值为0。
3.5 结果分析
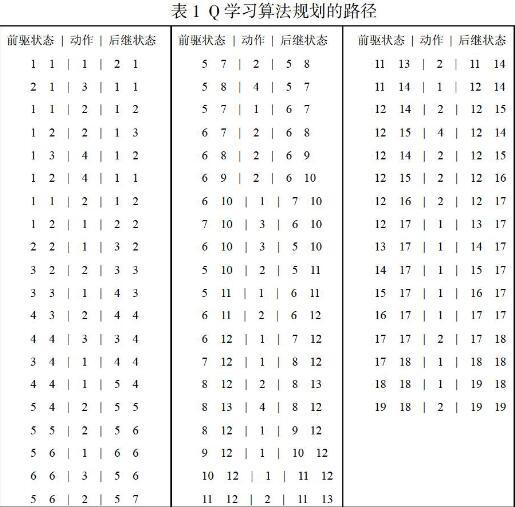
若设定机器人起始位置为(1,1) ,目标位置为(19,19) ,學习效率α=1 ,折扣因子γ=1 ,依据Q学习算法进行路径规划,所得结果如下表所示:
从规划出的路径结果可以发现,机器人在行走的过程中会在某个栅格的附近反复,也就是探索。导致这一结果发生的主要原因是,Q学习算法是一种不需要先验知识的算法,而是需要机器人在学习中不断地丰富策略知识。Q学习是从外部环境状态到动作的映射当中,找到一个最优策略,使得机器人获得最大累积奖惩值,这就需要机器人选择倾向于能够产生正的奖惩值的动作,即对动作策略的利用,而为了发掘新的动作策略,就需要机器人去尝试那些没有被选择的动作,即探索。探索是寻找最优路径的有效方法,但是过多的探索就会使得累计奖惩值无法收敛,而如果探索进行的不彻底,只利用仅有的一些动作策略,就不能够找到最优策略。
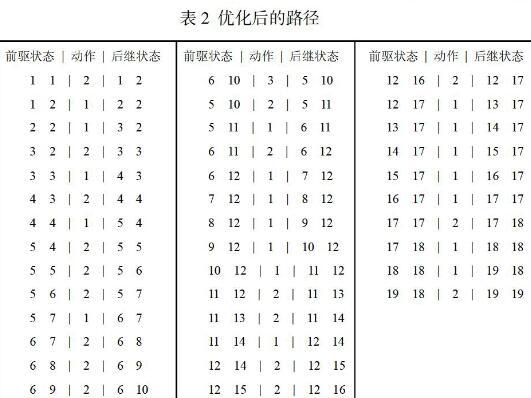
为了优化路径规划结果,找到更加短的路径,只需将表1中重复的动作删除,得到的结果如下表2所示:
通过对比表1与表2的结果,可以发现优化后的动作个数只有38个,而优化前的动作个数有56个, 探索的过程减少了,移动机器人行走的路径和转折角度也更小了。
4.结束语
本文详细介绍了Q学习算法在机场环境中的路径规划,采用Q学习算法进行移动机器人路径规划虽然能获得一条完全无碰的路径,但探索过多,导致路径的总长度和总转折角度较大。这在移动机器人实际应用中将消耗更多的能量和花费更多的时间。论文结尾提出了优化规划结果的方法。理论研究为后勤装备保障领域机器人的研发设计提供了基础。当然,实际应用中还需考虑机器人的尺寸及转弯半径。围绕该特定环境,还需在动态避障、全覆盖路径规划方面有更深入的研究。感谢空装重点项目(KJ20182A050259)及院青年科研基金(KY2018D011B)对该研究的支持。
参考文献:
[1]Fujimura K,Samet H. A hierarchical strategy for path planning among moving obstacles [mobile robot][J].IEEE Transactions on Robotics & Automation,1989,5(1):61-69.
[2]Kyriakopoulos K J,Saridis G N. Optional motion planning for collision avoidance of mobile robots in non-stationary enviroments[J]. Journal of Intelligent & Robotic Systems,1992,11(3):223-267.
[3]周婷. 基于改进蚁群算法的移动机器人路径规划及实现[D].中南大学,2010.
[4]朱大奇,颜明重. 移动机器人路径规划技术综述[J]. 控制与决策,2010,25(7):961-967.
[5]吴乙万,黄智. 基于动态虚拟障碍物的智能车辆局部路径规划方法[J]. 湖南大学学报:自然科学版,2013,40(1):33-37.
[6]柴寅,唐秋华,邓明星,胡进. 机器人路径规划的栅格模型构建与蚁群算法求解[J]. 机械设计与制造,2016,4:178-181.
[7]孙炜,吕云峰,唐宏伟,薛敏. 基于一种改进A*算法的移动机器人路径规划[J]. 湖南大学学报, 2017,44(4):94-101.
[8]高慧. 基于强化学习的移动机器人路径规划研究[D]. 西南交通大学, 2016.
[9]刘仕超. 基于强化学习的移动机器人路径规划研究[D]. 山东科技大学, 2017.
[10]冯超. 强化学习精要核心算法与TensorFlow实现[M]. 北京:电子工业出版社, 2018.
[11]郭宪,方勇纯. 深入浅出强化学习原理入门[M]. 北京电子工业出版社,2018.
[12]周志华. 机器学习[M]. 北京:清华大学出版社, 2016.
作者简介:
第一作者:王淑玲(1984-),女,汉族,安徽宿州,硕研,南京理工大,副教授,主要研究方向:机器学习算法,统计诊断
第二作者:卓丽(1980-),女,汉族,江苏徐州,硕研,中国矿业大学,讲师,主要研究方向:电工电子
