基于语义扩展的多关键词可搜索加密算法
2019-10-21徐光伟史春红王文涛
徐光伟 史春红 王文涛 潘 乔 李 锋
(东华大学计算机科学与技术学院 上海 201620)
现今,云存储给数据用户(个人和企业)提供了一个第三方服务平台.为了节省本地存储成本和管理成本,用户可以将自己的数据外包到云服务器[1].但是,将数据(特别是敏感数据)直接上传到云服务器中,使得数据拥有者将数据的管理权限完全给予云服务提供商,数据安全性不能得到保证[2].为了保证上传数据的隐私性,目前最常用的方法是数据拥有者将数据加密后再上传到云服务器,这带来了新的问题:传统的检索技术不再适用[3].为了能够使用户有效地获取加密数据,研究人员提出了可搜索加密技术(searchable encryption, SE)[4].首先,数据拥有者在上传数据文件之前,根据数据文件来抽取关键词,并建立索引.然后,将索引和数据文件加密并上传到云服务器.当数据使用者想要获取加密文件时,数据使用者输入相关关键词并使用相应的加密算法进行加密生成安全陷门,然后将安全陷门发送给云服务器,云服务器接收安全陷门并和索引进行匹配,最后返回相关加密文件给用户,用户在本地进行解密,获得所需文件.
最近,许多研究者提出了一系列的可搜索加密算法.Song等人[4]提出了一种实现密文搜索的可搜索加密算法,但是他的算法只支持单关键词搜索;Li等人[5]确定了有效模糊关键词搜索加密数据的问题,利用编辑距离和通配符的方法构建模糊关键词集;随后,Cao等人[6]提出了一种安全的多关键词可搜索加密算法(multi-keyword ranked search over encrypted cloud data, MRSE),利用空间向量模型和向量内积实现高效检索;Wang等人[7]将局部敏感Hash(locally sensitive Hash, LSH)和布隆过滤器结合解决了基于多关键词的模糊搜索问题;沿着这个方向,文献[8-9]研究者提出了验证返回结果正确性的算法.这些算法提出了不同的搜索功能,例如单关键词搜索、多关键词搜索和模糊搜索等;除了在功能上多样化之外,还有一些研究者[10-11]从提高检索密文文件的效率和准确性出发提出了基于TF-IDF算法的可搜索加密算法,并为了节省传输成本只返回top-k个文档.
虽然上述算法有效解决了可搜索加密问题,但它们也存在一定的局限性.1)现有工作中大多将搜索关键词视为同等重要,忽略了关键词的差异性,导致关键词扩展后返回的结果不能满足用户的搜索意图;2)现有工作没有考虑索引之间的关联性,关键词搜索必须遍历所有索引,使得搜索效率较低.
因此,为了解决上述问题,我们研究了关键词之间的关系,提出一种基于语义扩展的多关键词可搜索加密算法(multi-keyword searchable encryption algorithm based on semantic extension, SEMSE),以搜索出满足用户意图的数据文档.此外,在搜索阶段,利用凝聚层次聚类和关键词平衡二叉树的思想将相似度高的索引聚类在同一个子树下,从而构建了一个新的索引树结构,并通过引入剪枝参数和相关性得分阈值对索引树进行剪枝来过滤掉大量不相关的子树,从而大大减少了搜索时间.最后,所提算法可抵御2种不同的安全威胁.本文的主要贡献有3个方面:
1) 考虑不同搜索关键词之间的关系,提出一种关键词权重算法,以区分不同搜索关键词之间的重要性,利用关键词权重来选出需要扩展的关键词,而不是查询中的所有关键词来进行多关键词排序搜索;
2) 利用凝聚层次聚类和关键词平衡二叉树思想将相似索引聚类在同一个子树下,从而构建一种新的索引结构.然后设置剪枝参数和相关性得分阈值对索引树进行剪枝来过滤掉大量不相关的子树,从而大大减少搜索时间;
3) 应用真实数据集的实验表明,与现有算法相比,我们所提的算法在保证隐私的前提下,提高了搜索效率和准确性.
1 相关工作
近些年,可搜索加密算法获得了长足的发展,许多算法都在基于文档的可搜索加密中提供了丰富的搜索功能.此外,可搜索加密算法分为2类:1)非对称可搜索加密(asymmetric searchable encryption, ASE);2)可搜索对称加密(searchable symmetric encryption, SSE).这里,我们只关注后者.
Song等人[4]第1次提出了对称可搜索加密算法,该算法使用顺序扫描密文文档,这是首次定义了对称可搜索加密问题并给出了解决算法,对后续研究起到极大的推动作用.但是,该算法只接收固定长度的关键词且存储复杂度比较高.Goh[12]定义了一种安全索引结构,并为自适应选择攻击的语义安全性建立了一种安全模型;Curtmola等人[13]针对对称可搜索加密算法给出了安全性定义,并基于倒排索引结构提出了一种新的与文档相关联的索引结构;Cash等人[14]提出了一种新的支持大型数据库的动态SSE算法;Stefanov等人[15]首次针对动态搜索加密问题提出了一种在次线性时间进行更新和搜索的解决算法,虽然该算法搜索时间是非线性的,但是随着索引数量的增加,实际搜索时间还是非常大;通过陷门置换的方式,Bost[16]首次实现了支持前向隐私的可搜索加密算法,并推广到任意基于索引的SSE算法中;Kim等人[17]提出了一种称为双字典的数据结构,该字典是一种包含前向和倒置索引的链接字典.为了实现前向安全性,该算法采用与前向搜索令牌无关的新密钥来加密新添加的数据文件;文献[17-18]提出了一些支持前向和后向安全的SSE算法,然而这些算法都支持单关键词搜索.

Fig. 1 Keyword balanced binary tree图1 关键词平衡二叉树
另一方面,为了丰富搜索表达,大量研究工作集中在设计多关键词可搜索加密算法.文献[19-21]中提出的解决算法着重于如何在提供隐私保护的同时对加密数据进行多关键词联合搜索,这些算法的时间开销和文件集的大小成线性关系.Cash等人[22]提出了一种具有可扩展性的对称搜索加密算法,该算法将计算开销减少到子线性,并将搜索模式扩展到布尔查询.Cao等人[6]基于文献[23]提出的安全kNN技术解决了支持搜索结果排序的多关键词搜索问题,提出了基于向量空间模型和向量内积计算的可搜索加密算法,该算法支持2种安全威胁.为了解决多关键词搜索和搜索结果排序问题,Sun等人[24]提出了一种基于词频的索引和余弦相似度建立的向量空间模型,以提高搜索的准确性.为了消除预定义字典的存储开销,Wang等人[25]通过在Bloom Filter中使用局部敏感Hash构建文件索引,并实现了文件更新,Fu等人[26]提出了支持并行计算的加密云数据的多关键词排序搜索算法.Xia等人[27]在文献[6]的基础上提出了一种支持多关键词排序搜索和动态更新的加密搜索算法,该算法利用向量空间模型和TF-IDF来实现多关键词排序搜索并构建了基于树的特殊索引结构来降低搜索的时间复杂度.
在算法中,未考虑搜索关键词之间的关系和索引之间的关联性,导致搜索结果不能满足用户需求,搜索的效率还有待改善.
2 预备知识
2.1 安全kNN
为了安全高效地获得索引向量和搜索陷门之间的相关性得分,在2009年Wong等人[23]提出了一种迄今为止使用最广泛的安全kNN算法.安全kNN的目标是将数据集中的k个最近点进行安全地识别、匹配给定的点,而不需要使用服务器来获取数据集的内容.该算法通过计算2个向量之间的向量内积来获得它们之间的相关性得分.文献[6]提出了基于安全kNN算法的多关键词排序搜索加密算法,并给出了安全性证明.在安全kNN算法中,首先,需要设置一个用来加密向量的安全密钥(S,M1,M2).其中S是m位的二进制向量,由{0,1}组成,用于将向量分割成2部分,M1和M2是2个用于加密向量的可逆矩阵.
2.2 关键词平衡二叉树
2015年Xia等人[27]设计了一种基于关键词平衡二叉树索引结构(keyword balanced binary tree, KBB-Tree)的多关键词排序搜索算法,并设计了一种贪婪深度优先遍历算法,其算法的时间复杂度基本上保持为对数级,能够实现高效的多关键词排序搜索.关键词平衡二叉树的索引结构采用TF-IDF表示文档关键词的权重值,并采用向量空间模型构造一个索引向量,最后通过安全kNN算法进行加密计算相关性得分,从而返回top-k个排序结果.
如图1所示为基于关键词平衡二叉树的索引结构.KBB-Tree的节点标识为u=(ID,I,Pl,Pr,FID).其中,ID表示节点的唯一编码;I表示文档向量;Pl和Pr分别表示节点u指向左孩子的节点和指向右孩子的节点;对于FID来说,如果节点是叶子节点,则FID表示文档编号,如果节点是中间节点,则FID为空.在构建关键词平衡二叉树时,从叶子节点进行构建生成中间节点,比较2个叶子节点中的文档向量I,将向量中取值较大的值作为中间节点中I对应向量的取值.根据这一原则逐步构建中间节点,直到生成根节点为止.
其中,N表示索引树的中间节点,F表示文档所在的叶子节点,中间节点的向量值为其左右孩子节点对应位向量的最大值.在搜索过程中,通过基于KBB-Tree的索引结构和贪婪深度优先遍历算法能够极大地节省搜索的时间开销,提高搜索效率.但是当输入关键词字典中不存在关键词时,该索引结构会线性地执行遍历操作,致使搜索效率大大降低.
2.3 依存句法
依存句法(dependency grammar)的主要用途是分析句子的句法结构,从而更好地理解句子的含义[28].依存句法具有一个一般性的假设,即句法结构本质上包含词和词的关系,这种关系被称为依存关系(dependency relations)[29].在依存句法中,能够准确识别出关键词的词性以及句子中关键词之间的支配和从属的关系,其中属于支配地位的关键词称为支配词(head),处于被支配地位的关键词称为从属词(dependency)[28].句子中各关键词之间的关系是单向的,并通过语义弧链接它们之间的依赖关系.对于句子中关键词的依存关系,需符合4条公理.
1) 句子中有且仅有一个关键词是独立的;
2) 其他关键词必须依存于另一个关键词;
3) 任何关键词不能同时与2个关键词之间存在依存关系;
4) 如果2个关键词A和B之间存在依存关系,而这2个关键词之间还有其他关键词C,则该关键词C只能依存于关键词A或B,或者依存于A和B之间的其他关键词.
与短语结构句法不同,依存句法中不存在短语节点,只考虑句子各成分之间的依赖关系,如图2所示为以“Information security is very important”为例的依存句法结构依赖关系图.

Fig. 2 Dependency grammar structure图2 依存句法结构
其中,root表示根节点关系,compound表示补语关系,nsubj表示名词主语关系,cop表示系动词关系,advmod表示状语关系.
3 模型与问题描述
3.1 系统模型
如图3所示,本系统模型主要分为3个不同实体:数据拥有者、数据使用者和云服务器.
1) 数据拥有者.在数据文档F={F1,F2,…,Fn}外包给云服务器之前,首先对数据文件提取关键词W={w1,w2,…,wm} 并采用安全密钥SK加密关键词构建安全索引I={I1,I2,…,Im}.然后,采用对称加密算法加密数据文档生成加密数据集C={c1,c2,…,cn}.最后,将加密数据集C和安全索引I一同上传至云服务器并将对称密钥sk和安全密钥SK发送给数据使用者.
2) 数据使用者.首先,接收从数据拥有者发送的对称密钥和安全密钥;然后,在本地输入一定的关键词进行搜索,使用安全密钥生成安全陷门T并将安全陷门T发送给云服务器;最后,获取云服务器返回的加密数据文件,并利用对称密钥进行解密.
3) 云服务器.云服务器存储数据拥有者发送的加密数据集和安全索引,并为数据使用者提供数据搜索服务等.当数据使用者发送安全陷门给云服务器时,云服务器利用指定算法将安全陷门和安全索引进行匹配,并返回top-k个密文给数据使用者.

Fig. 3 System model图3 系统模型
为了便于描述多关键词可搜索加密算法,表1给出本文使用到的符号定义.
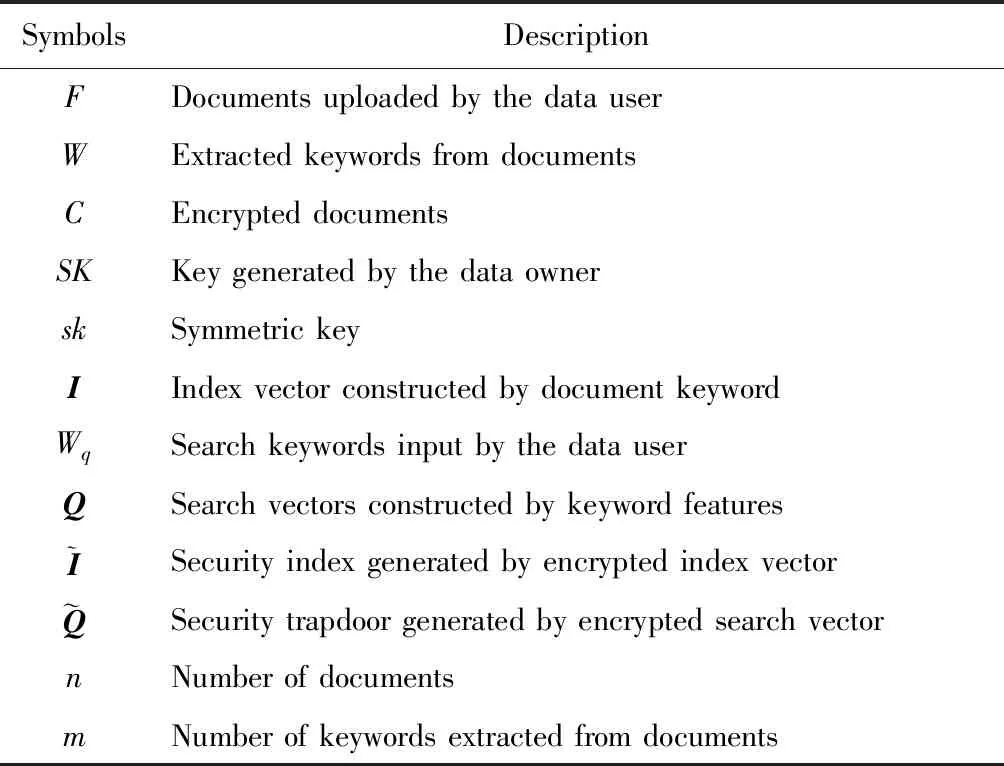
Table 1 Symbol Definition表1 符号定义
系统模型包括5个多项式时间算法SSE={KeyGen,BuildIndex,TrapdoorGen,Search,Decrypt},具体过程为:
1) 初始化KenGen(1λ)→(SK,sk).是一个由数据拥有者执行的概率密钥生成算法,该算法将安全参数λ作为输入,然后输出密钥SK={S,M1,M2}和对称密钥sk.
2) 索引构建BuildIndex(sk,SK,F)→(I,C).是一个概率算法,将密钥SK和外包文档集F作为输入,对文档集进行关键词提取,生成关键词字典W,并构建关键词索引,然后使用密钥SK加密索引向量和使用对称密钥sk加密文档集F.算法输出安全索引I和密文集C.
3) 陷门生成TrapdoorGen(Wq,SK)→T.是一个概率算法,该算法将密钥SK和搜索关键词Wq作为输入,利用密钥SK对搜索关键词进行加密生成安全陷门T,算法返回安全陷门T.
4) 搜索Search(I,T,k)→Ck.是一个由云服务器执行的确定性算法,该算法将安全索引I、安全陷门T和需要返回文档的个数k作为输入,计算安全陷门和安全索引的向量内积作为相关性得分,并对相关性得分进行排序.云服务器返回包含top-k个密文的文档集Ck给数据使用者.
5) 解密Decrypt(Ck,sk)→Fk.是一个确定性算法,该算法将密文文档Ck和密钥sk作为输入,数据使用者通过对称密钥sk对加密文档集Ck进行解密,算法返回明文数据集Fk.
3.2 安全威胁
采用文献[6,25,27]中提出的安全威胁,假设数据拥有者和数据使用者是可靠的,而云服务器是“诚实且好奇的”,即它会“诚实地”根据算法的指定协议存储数据拥有者的数据文档,但对存储的数据“感到好奇”,即云服务器想通过推断或分析加密数据和安全陷门信息来获取数据所有者的数据信息.

2) 已知背景模型.在已知背景模型中,云服务器能够获取比已知密文模型更多的数据信息,比如与安全陷门相关的信息或者数据集之间的统计信息等.因此,云服务器具有更强的攻击能力.云服务器可以根据已知的陷门信息,并借助一些统计信息来推断,分析上传的安全陷门、安全索引和搜索结果等来确定搜索中的某些关键词的明文信息.
3.3 问题描述
1) 现有的算法都是将搜索关键词彼此之间视为同等重要,忽略了关键词的重要性的不同,导致关键词扩展后搜索准确率较低.
2) 现有多关键词可搜索加密算法在构建索引的过程中没有考虑索引之间的关联性,关键词搜索必须遍历所有索引,使得搜索效率较低.
4 基于语义扩展的多关键词可搜索加密
本文提出一种多关键词陷门生成方法,以区分不同关键词权重,然后详细描述了多关键词排序搜索过程,最后给出了SEMRS算法的具体实现.
4.1 多关键词陷门生成
1) 关键词权重计算
用户进行搜索时,输入的关键词存在一定的句法关系,即关键词之间存在修饰和被修饰的关系.因此,关键词之间的句法关系一定程度上反映出关键词的重要性.此外,如果一个关键词和不止一个关键词之间具有句法关系,则该关键词具有更大的重要性.
因此,将搜索关键词之间的句法关系视为关键词重要性的表现形式.对搜索关键词之间的句法关系进行分析,如果存在句法关系,则增加关键词权重.
定义1.关键词关系.对于每个关键词来说,设初始关键词关系为1,如果该关键词和其他关键词之间具有句法关系,则其权重变为1+R,其中R表示2个关键词之间的句法关系.



(1)
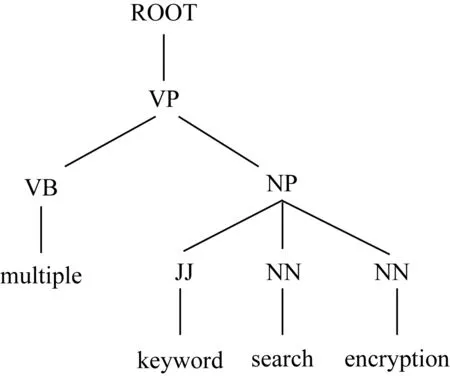
Fig. 4 Keyword phrase structure tree图4 关键词短语结构树
然后将结构树转换为依存句法结构,获取关键词之间的句法关系,如图5所示:

Fig. 5 Keyword dependence relations图5 关键词句法关系
其中,“root”表示依存句法结构的根节点关系,“amod”表示形容词修饰语,“compound”表示名词复合修饰语,“dep”表示依赖关系,“NP”表示名词短语,“NN”表示常用名词单数形式,“JJ”表示形容词、数字和序号等.我们采用关键词之间的句法关系和短语结构树中关键词之间的距离来衡量关键词的权重,例如“encryption”和“multiple”的距离为5,则它们之间的句法关系为R(amod)=1ln 5.根据上述规则,可以得出总的关键词关系为4+1ln 4+1ln 4+1ln 4+1ln 5=6.785,而“multiple”的关系为1+1ln 4+35ln 5=2.094,然后利用关键词权重式(1)可知,“multiple”的关键词权重为KW(multiple)=1.23.同理,其他关键词的权重分别为KW(search)=0.81,KW(keyword)=1.01,KW(encryption)=0.95.
2) 多关键词的语义扩展
对关键词进行扩展,不是对所有关键词进行扩展,而是通过关键词权重计算方法选出权重最大的关键词作为待扩展关键词,然后根据WordNet[31]获取关键词的同义词,这样对于每个待扩展的关键词都构建了一个同义词集,最后通过2个关键词概念之间的最大语义相似度近似2个关键词的语义相似度,即:
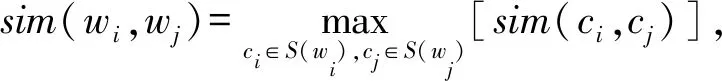
(2)
其中,S(wi),S(wj)是关键词wi和wj所包含概念的集合.这里,采用基于信息内容(IC)的David算法[32]来衡量2个概念之间的相似度.
3) 陷门生成
为了更好地反映关键词和文档的关系,在关键词权重中引入了TF-IDF技术,对于每个文档关键词w,如果其在关键词词典中,则将关键词权重设置为关键词权重值和该关键词在文档中的逆文本频率IDF的乘积,即KW×IDF,代替基于原关键词权重值,将扩展关键词的权重值设置为其语义相似度得分、对应的搜索关键词的权重和逆文本频率IDF三者的乘积,即KW×sim×IDF.
4.2 多关键词排序搜索
1) 基于凝聚层次聚类的索引构建

Fig. 6 Index tree construction process图6 索引树构建过程
在对文档加密之前,需要构建文档的索引,Xia等人[27]提出了基于KBB-Tree的索引结构,相比于线性扫描的MRSE算法[6],通过构建索引树的方式确实大幅提升了搜索效率,但是该算法没有考虑索引之间的关联性,使得相似度高的索引随机分布在索引树的各个子树中,导致多关键词搜索必须遍历所有索引才能最终确定搜索结果.因此,基于凝聚层次聚类(agglomerative hierarchical clustering)[32]的思想将相似索引进行聚类为一个平衡二叉树索引结构.凝聚层次聚类通常是指将每个对象都作为一个单独的聚类簇,然后每一次聚类最相关的2个簇,直至将所有簇聚类为一个簇为止.由于每次仅聚类2个最相关的簇,使得构成树的高度非常大,不利于遍历整棵树.因此,在每一轮的聚类操作中,根据簇集合中簇中心向量的欧几里德距离两两合并,从而构成平衡二叉树形式,其中簇中心向量指簇集合中各节点的均值,如图6所示为索引树构建过程.为了便于描述索引树的构建,先给出了索引树节点的数据结构.
定义2.索引树节点的数据结构.设索引树节点的数据结构由四元组FID,NV,NL,NR组成.其中,FID表示文档的唯一标识符,NV表示该节点的节点向量,NL表示该节点的左孩子,NR表示该节点的右孩子.如果节点u是叶子节点,则FID是文档的唯一标识,NV是文档的索引向量,NL和NR为空;如果节点u是中间节点,则FID为空,NL和NR表示节点的左孩子和右孩子,左孩子NL和右孩子NR的簇向量最大值为
NVi=max{NL.NVi,NR.NVi}.
(3)
如图6所示为索引树构建过程,索引树的构建的基本思想是:首先,根据定义4索引树节点的数据结构,创建叶子节点;然后根据凝聚层次聚类生成中间节点直至根节点,具体过程为:
假设8个文档向量{F1,F2,…,F8},根据定义4构建索引树的叶子节点{u4,1,u4,2,…,u4,8},SV表示簇中心,N表示节点u包含的节点个数,则簇中心为
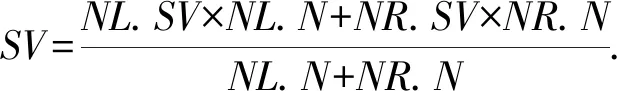
(4)
(1) 计算叶子节点簇中心之间的欧几里德距离为
(5)
将欧几里德距离最小的2个节点进行聚类生成一个簇,该节点的节点向量NV的计算如式(3),簇中心的计算如式(4).然后再计算剩余节点簇中心的欧几里德距离,并聚类最小的2个簇,直至聚类所有节点.聚类后的簇为Cu3,1={F2,F4},Cu3,2={F5,F7},Cu3,3={F1,F3}和Cu3,4={F6,F8}.
(2) 根据步骤1的过程,依次对阶段1生成的簇进行聚类,聚类之后的簇为Cu2,1={F2,F4,F5,F7}和Cu2,2={F1,F3,F6,F8}.
(3) 根据步骤2的过程,对阶段2生成的簇进行聚类,生成索引树的根节点.

2) 多关键词的排序搜索
由于通过凝聚层次聚类构建索引树使得相关的索引位于同一个子树中,在索引遍历过程中只需根据搜索关键词和索引的相关性得分找出对应的簇就能实现整个遍历过程,而无需遍历整个索引树.因此,设置一个剪枝参数PT和一个相关性得分阈值sysp来过滤不相关的子树,其中剪枝参数可以根据用户不同偏好设置,相关性得分阈值是结果集中相关性得分最小的取值.通过索引树的构建可知,中间节点的节点向量是该节点的左孩子和右孩子的节点向量的最大值,即如果中间节点的节点向量和搜索关键词的相关性得分小于剪枝参数PT和相关性得分阈值sysp,则以该节点为根节点的索引树的所有节点与搜索关键词的相关性得分都小于剪枝参数PT和相关性得分阈值sysp,对该索引树进行剪枝.
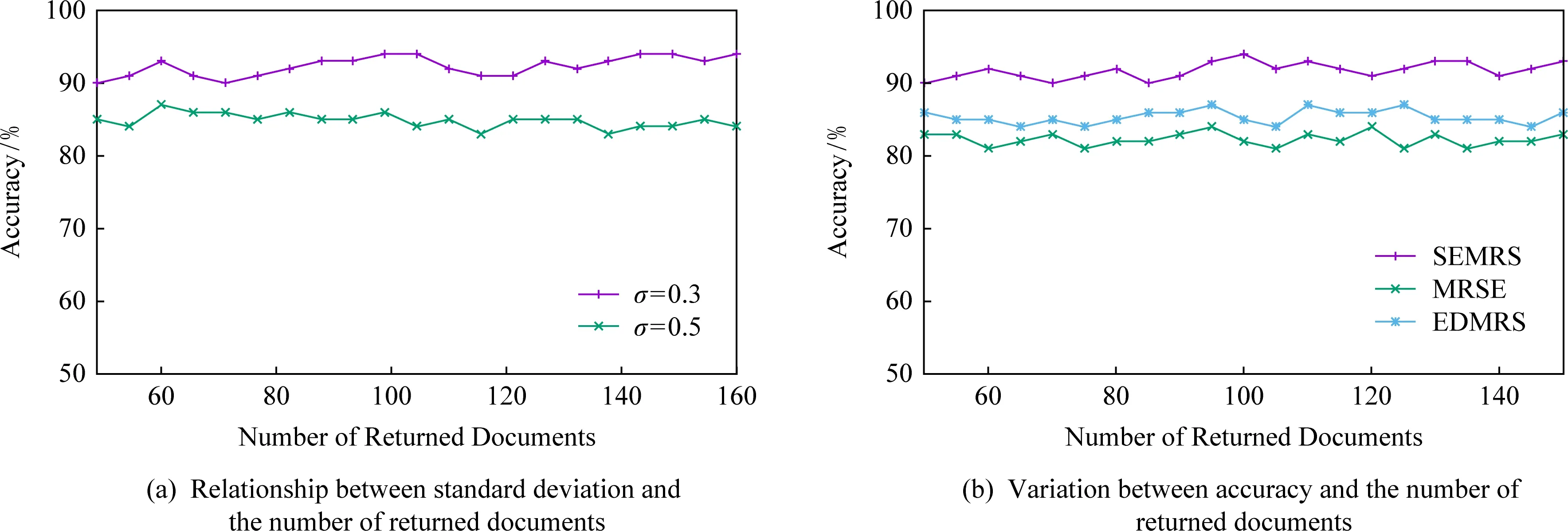
如图7所示为关键词搜索过程,设索引树包含8个文档,返回的文档个数为5,搜索向量为Q=(0.3,0.6,0,0.1),关键词搜索路径为虚线箭头所指方向.首先,搜索叶子节点u4,1,并计算搜索向量Q和叶子节点簇向量的相关性得分.然后判断相关性得分Score(Q,u4,1.NV) 是否大于剪枝参数PT,如果大于剪枝参数,则F2插入结果集中.继续遍历叶子节点u4,2,相关性得分Score(Q,u4,1.NV)>PT,将F4插入结果集Rlist中.继续遍历其他子树,当结果集Rlist={u4,1,u4,2,u4,3,u4,4}时,结果集中节点个数为4,小于需要返回的文档数,继续判断剩余节点得出Score(Q,u4,1.NV) Fig. 7 Keyword search图7 关键词搜索过程 由于剪枝参数和相关性得分阈值的设置并没有返回数据使用者想要返回的5个文档而是返回了最为相关的4个文档,且在进行关键词搜索过程中并没有遍历所有节点,而是对于中间节点的相关性得分较小的子树进行剪枝,这样极大地节省了遍历时间. 本节基于语义扩展的多关键词排序搜索算法主要包括6个部分:GenKey,BuildIndexTree,Query-Extension,GenTrapdoor,Search和Decrypt. 1) 初始化GenKey(k)→(SK,sk) 3) 关键词扩展QueryExtension→We 首先,根据关键词权重计算方法计算搜索关键词Wq的权重,并选出需要扩展的关键词.然后,根据基于语义相似度的关键词扩展算法提取关键词的同义词集,将关键词转换为概念,并构建概念层次树,计算关键词之间的语义相似度.最后,选出相似度最大的若干关键词作为扩展关键词,并将扩展关键词和搜索关键词一起作为搜索关键词We. Score=·=(MT1I′)TM-11Q′+ 6) 解密Decrypt(C,sk)→F 数据使用者接收到云服务器返回的密文文件,使用对称密钥sk对密文文件C进行解密来恢复原文件的内容. 基于语义扩展的多关键词排序搜索算法具体如算法1所示. 算法1.SEMRS算法. 输入:剪枝阈值PT、相关性得分阈值sysn、需要返回的文档个数k; 输出:明文F. ① 初始化密钥参数x; ②SK,sk←Getkey(x); ③ fori=1;i≤n;i++ do ④u←createNode(Fi,SK); ⑥ end for ⑦We←queryExtension(Q); ⑨ for the nodeudo 在算法1中,行①是生成密钥的过程,行②~⑤是构建索引的过程,行⑥~⑦是生成安全陷门,行⑧~是多关键词搜索,如果中间节点的相关性得分小于剪枝参数和得分阈值,则进行剪枝,行~是对服务器返回的结果集进行解密. 本节将分别从已知密文模型和已知背景模型来分析所提算法的安全性. 1) 已知密文模型中的安全性 (7) 其中,Ip包含2×n×|Ip|个未知数,可逆矩阵M1和M2分别包含n×n个未知数.通过式(7)可以得出方程组中仅包含2×n×|Ip|个方程式.根据行列式的性质可知,当未知数的数量大于方程式的数量时,不能计算出方程式的解,即根据式(7)得不到可逆矩阵M1和M2.同理,通过安全陷门也得不到可逆矩阵M1和M2.因此,本算法采用的拆分索引和搜索向量的加密机制能够保证数据的隐私性. 2) 已知背景模型中的安全性 在已知背景模型中,数据加密和索引及陷门的加密使用的是相同的加密方法.此外,在已知背景模型中引入了虚拟关键词.因此,SEMRS算法保证了数据的安全性与索引和陷门的安全性. 为了进一步验证算法的性能,本节分别从算法的各主要阶段:1)系统初始化;2)索引构建;3)陷门生成;4)搜索等方面进行分析.假设加密算法采用传统的对称加密算法,文档关键词的数量为n,文档集中包含文档的个数为m,搜索关键词个数为x,扩展的关键词个数为y,分析: 系统初始化阶段,仅进行密钥生成,因此该阶段的时间复杂度为O(1). 索引构建阶段,主要时间消耗为索引加密,先采用的安全kNN算法对索引进行分割,然后使用2个可逆矩阵相乘进行加密,其安全索引构建的时间复杂度为O(me2),其中e是关键词向量的长度. 陷门生成阶段,安全陷门的生成与安全索引构建过程相似,主要时间消耗都是关键词加密和关键词扩展,其时间复杂度也是O((x+y)e2). 此外,由于扩展关键词个数y应小于搜索关键词个数x,且x+y≪m.在陷门生成时,无论搜索关键词集合中有多少关键词,陷门长度始终等于所提取文档关键词字典长度.算法主要的网络通信开销是传输安全陷门T到云服务器的开销,由于在本地无论输入多少关键词,使用安全密钥生成陷门T的大小|T|始终是固定的,因此,即使面对大规模数据集合,陷门传输的通信开销始终为|T|. 实验采用Java语言编写,并在AMD5 CPU 2.0 GHz的Windows 10环境执行.数据集为联邦能源监管委员会发布的包含517 000多条邮件的Enron email dataset[33]. 为了表现扩展关键词数量的影响,设扩展关键词和原搜索关键词之间的比率参数为ρ,其中ρ∈[0,1].即最少关键词扩展数量为0,最多关键词扩展为原关键词的个数.如图8(a)所示,横坐标为扩展关键词和原搜索关键词之间的比率参数ρ,步长为0.1,纵坐标为搜索准确率.设返回的文档数为50,数据使用者搜索相关的文档数量为80,则从图8(a)中,可以得出随着比率参数ρ的增加,搜索准确率逐渐上升,直至比率参数为0.4时,准确率和召回率达到最大值,随后准确率和召回率开始逐渐降低,即在基于多关键词扩展的排序搜索算法中当比率参数为0.4时,搜索性能达到最优. Fig. 8 Accuracy and recall图8 准确率和召回率 图8(b)所示为随着搜索关键词的变化,准确率和召回率的变化趋势.随着搜索关键词的不断增加,SEMRS的准确率和召回率也不断提高,即搜索关键词的数量越多,则搜索结果越能够满足需求. Fig. 9 Precision change under standard deviation图9 在不标准差下准确率变化趋势 Fig. 10 Index building time comparison图10 索引构建时间比较 索引构建阶段主要执行索引构建和索引加密.其中索引构建的计算成本主要取决于数据集中的文档个数,而索引加密又与关键词字典包含的关键词数量有关.此外,索引构建过程是一个一次性过程,即只在初始阶段进行索引构建,除非后续对数据集进行了更新操作,才重新构建索引.图10(a)显示了本算法和EDMRS算法[27]在给定不同文档数量情况下,索引构建时间开销的变化趋势.由于关键词数量越大,则索引向量的维度也就越大,因此通过观察可以发现,随着关键词数量的增加,索引构建时间也越来越大.图10(b)为在给定关键词数量的情况下,索引构建时间随着文档数量的变化趋势.随着文档数量的不断增加,索引构建时间也在增加,但SEMRS采用将索引向量分块的方式减少计算复杂性,大大减少了索引加密时间和索引创建时间. Fig. 11 Trapdoor generation time图11 陷门生成时间 陷门生成是关键词搜索的重要步骤,如图11所示为陷门生成关键词数量的变化趋势.不难发现,陷门生成时间趋向于一个常数,不会随着搜索关键词的数量增长而增长,这是因为陷门生成时间主要取决于字典中关键词的数量,算法中陷门生成操作的主要耗时是搜索向量的加密.由于本文采用分块的方式加密搜索向量,因此总的陷门生成时间要小于MRSE算法和EDMRS算法的时间.通过图11(b)可以看出,生成陷门的时间成本主要取决于关键词字典中包含的关键词数量,并随着关键词数量的增大而变大. 搜索时间是权衡算法性能的重要指标.图12(a)所示为在给定文档关键词数量的情况下,搜索时间随文档个数的变化趋势,由于文档向量和索引向量的计算时间相同,因此,搜索时间随文档数量的增加而增加.图12(b)为给定文档数量的情况下,搜索时间随文档关键词数量的变化趋势,通过上文可知,文档关键词数量越大,则索引向量和陷门向量的维度也越大,因此,随着文档关键词数量的增加,搜索时间也越来越多.此外,SEMRS算法基于凝聚层次聚类构建索引树结构,该索引树是平衡二叉树,并设计了一种高效的索引遍历算法,因此,SEMRS的搜索时间要小于MRSE和EDMRS算法的搜索时间. Fig. 12 Search time图12 搜索时间 在分析查询关键词之间的关系基础上,提出了一种安全高效的支持语义扩展的多关键词排序搜索算法,解决可搜索加密中的语义检索问题.我们设计了一种基于语义关系的关键词权重算法,并对权重较大的关键词进行语义扩展.为提高查询效率,构造了一种关键词平衡二叉树作为文档的索引结构,并在查询时,根据查询向量和树节点的向量内积,进行“剪枝”操作.此外,为更好地表达查询关键词和文档之间的相关性,在构建索引和陷门时引入了TF-IDF算法,并在陷门中加入关键词权重值.最后,通过使用安全kNN,使得所提算法能够对抗2种不同安全威胁.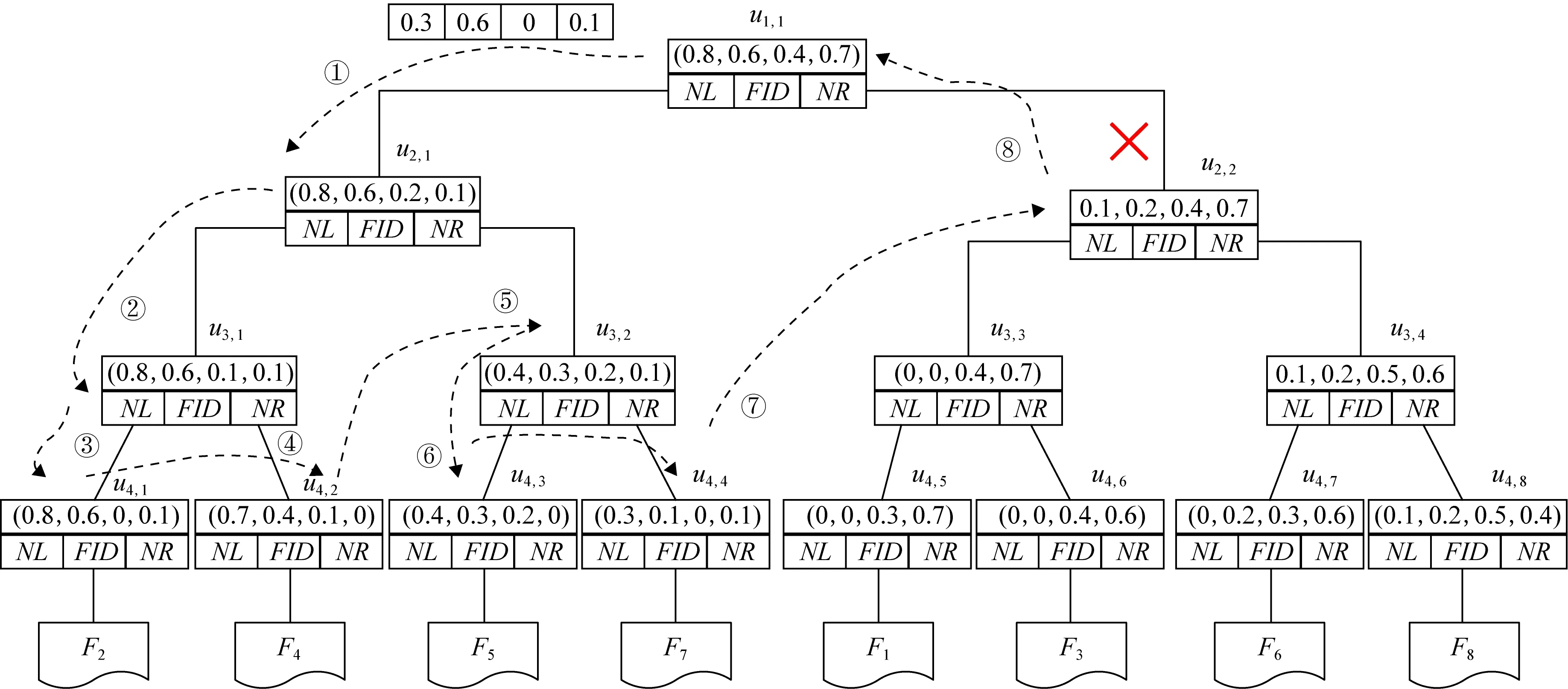
4.3 算法具体实现



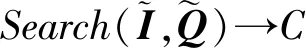
(MT2I″)TM-12Q″=I′Q′+I″Q″=
(I′,I″)(Q′,Q″)=rI·Q+Σεvi


5 安全性和性能分析
5.1 安全性分析

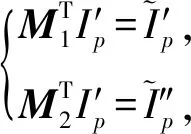
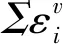
5.2 性能分析

6 实验分析
6.1 准确率和召回率


6.2 索引创建时间
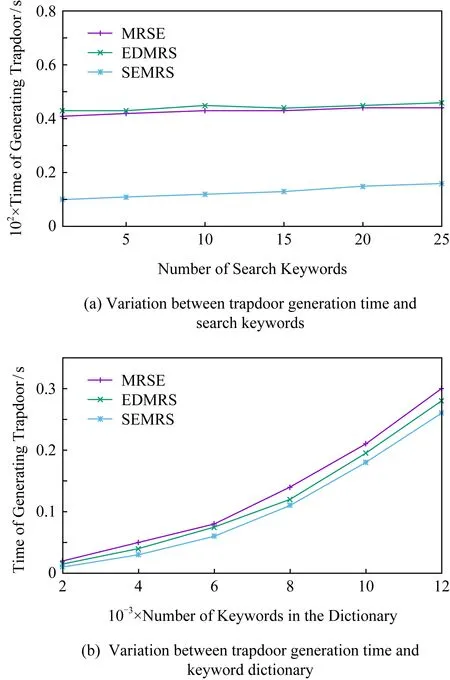
6.3 陷门生成时间
6.4 搜索时间

7 总 结
