基于深度学习的系统日志异常检测研究
2019-10-18王易东刘培顺王彬
王易东,刘培顺,王彬
基于深度学习的系统日志异常检测研究
王易东1,刘培顺1,王彬2
(1. 中国海洋大学信息科学与工程学院,山东 青岛 266100;2. 中国海洋大学继续教育学院,山东 青岛 266100)
系统日志反映了系统运行状态,记录着系统中特定事件的活动信息, 快速准确地检测出系统异常日志,对维护系统安全稳定具有重要意义。提出了一种基于GRU神经网络的日志异常检测算法,基于log key技术实现日志解析,利用执行路径的异常检测模型和参数值的异常检测模型实现日志异常检测,具有参数少、训练快的优点,在取得较高检测精度的同时提升了运行速度,适用于大型信息系统的日志分析。
日志异常检测;深度学习;GRU神经网络
1 引言
在异常检测领域中,系统日志异常检测一直是一个研究热点。系统日志作为具有多种自由格式的非结构化数据集,和文本分析、统计学、机器学习等学科都有着较为紧密的结合。多年来,各国研究人员将不同领域的方法应用到日志异常检测,并取得了大量出色研究成果。Xu[1]等利用抽象语法树(AST,abstract syntax tree)和主成分分析(PCA,principal component analysis)方法处理解析后的日志特征集,降低了待分析特征集的复杂度,得到了有效的异常检测结果。不过该方法需要预先获取程序源代码和日志的种类,不能作为一种通用的日志异常检测方法。Yu[2]等提出基于Workflow监控的异常检测系统——CloudSeer,它可以通过检查交错日志序列中的错误信息来获取执行异常。该方法在一定程度上解决了日志的并发性问题,但它借助自动机组实现,其中某些特定的规则只适用于云基础设施中的日志异常检测。
近些年,深度学习蓬勃发展,不断开创新的应用模式,尤其在NLP(natural language processing)领域进展巨大,大量NLP相关任务的最佳模型均在其基础上建立。Du[3]等将系统日志建模为自然语言序列,提出了一种基于LSTM的深度神经网络模型——DeepLog。该模型从正常的日志数据中学习日志规则,当检测到的日志偏离正常规则时,即认定其为异常。实验结果表明,该方法在多个大型数据集上取得了较高的检测精度,总体性能优于其他基于传统数据挖掘的日志异常检测方法。然而在检测效率方面,该方法仍有一定提升空间。
本文在N-gram语言模型[4]的基础上,结合循环神经网络提出了一种基于GRU(gated recurrent unit)神经网络模型的日志异常检测算法。针对复杂的非结构化日志,首先提取log key,将日志解析为结构化序列,然后使用解析得到的序列训练GRU神经网络模型用以检测异常,具有参数少、训练快的优点,在取得较高检测精度的同时提升了运行速度。
2 基于GRU的日志异常检测算法
2.1 基于logkey的日志解析方法
系统日志数据是一种非结构化文本数据,可以直接从日志文件中获取,在对日志数据进行分析之前,通常需要先将其解析为结构化数据。每个日志条目由常量和变量两部分组成,常量是指由系统程序源码中的print语句直接打印出的消息,变量则是常量以外的部分,通常是时间戳或参数值。例如,mysql中的日志“:,256.0”,常量部分为“:,”,“256.0”则是变量,表示数据库缓冲池大小。所有相似日志条目中的公共常量消息叫作logkey,可以用来表示日志消息类型。正常日志的输出会遵从一定的流程和顺序,通常称为日志的执行路径(execution path),logkey序列能够表示日志的执行路径,因此从日志中提取logkey是一种有效的日志解析方法。参数值是日志中非常有价值的一类信息,反映了系统的健康状态和性能,某些参数值还可以作为特定执行序列的标识,如HDFS日志中的block_id,基于此能够从多线程并发任务中提取出特定模块的日志序列。
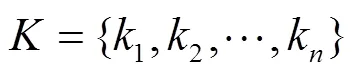
当前业内存在多种日志解析工具,Spell[5]是较为先进的一种,它基于LCS思想设计,由MIT的logPAI团队[6-7]开源实现,能够对日志进行在线解析。本文使用Spell从日志数据中解析出logkey和参数值,作为日志异常检测的基础。
2.2 基于执行路径的异常检测模型
日志异常检测和单词序列预测同属于一类序列预测问题,将日志看作一种特殊的自然语言,logkey序列相当于一个句子,序列中的每个logkey都可以看作一个单词,因此可以采用单词序列预测[4]的建模方法对日志异常检测问题进行建模。基于文献[3]的思路,本文设计并实现了一种基于GRU的神经语言模型,该模型能够通过序列的长期依赖检测异常。与文献[3]中构建的LSTM模型不同,本文模型使用GRU作为循环单元,具有参数少、训练快的优点,在取得较高检测精度的同时提升了运行速度。
基于GRU的执行路径异常检测模型分为输入层(input layer)、嵌入层(embedding layer)、隐藏层(hidden layer)和输出层(output layer)。如图1所示,模型每一个时间步(timestep)的输入为log keyw−i,它和上一个时间步的记忆状态共同计算得到当前状态。
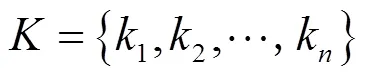

隐藏层:该层是GRU网络模型的核心部分,在隐藏层中,每个GRU节点都是一个记忆块(memory block),如图1所示,记忆块之间相互连接,构成一个完整的循环神经网络。单个GRU记忆块的构造如图2所示,其中包含两个门:更新门和重置门。更新门接收当前输入和上一时刻的隐藏层输出,决定其中有多少信息需要继续传递。通过Sigmoid激活函数处理输入信息,更新门得到1个介于0和1之间的结果,其计算公式如下。
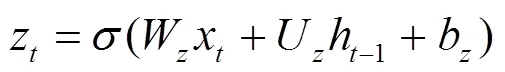
重置门则控制对历史信息的遗忘程度,其表达式形式与更新门相同,只是线性变换参数及其作用不同。
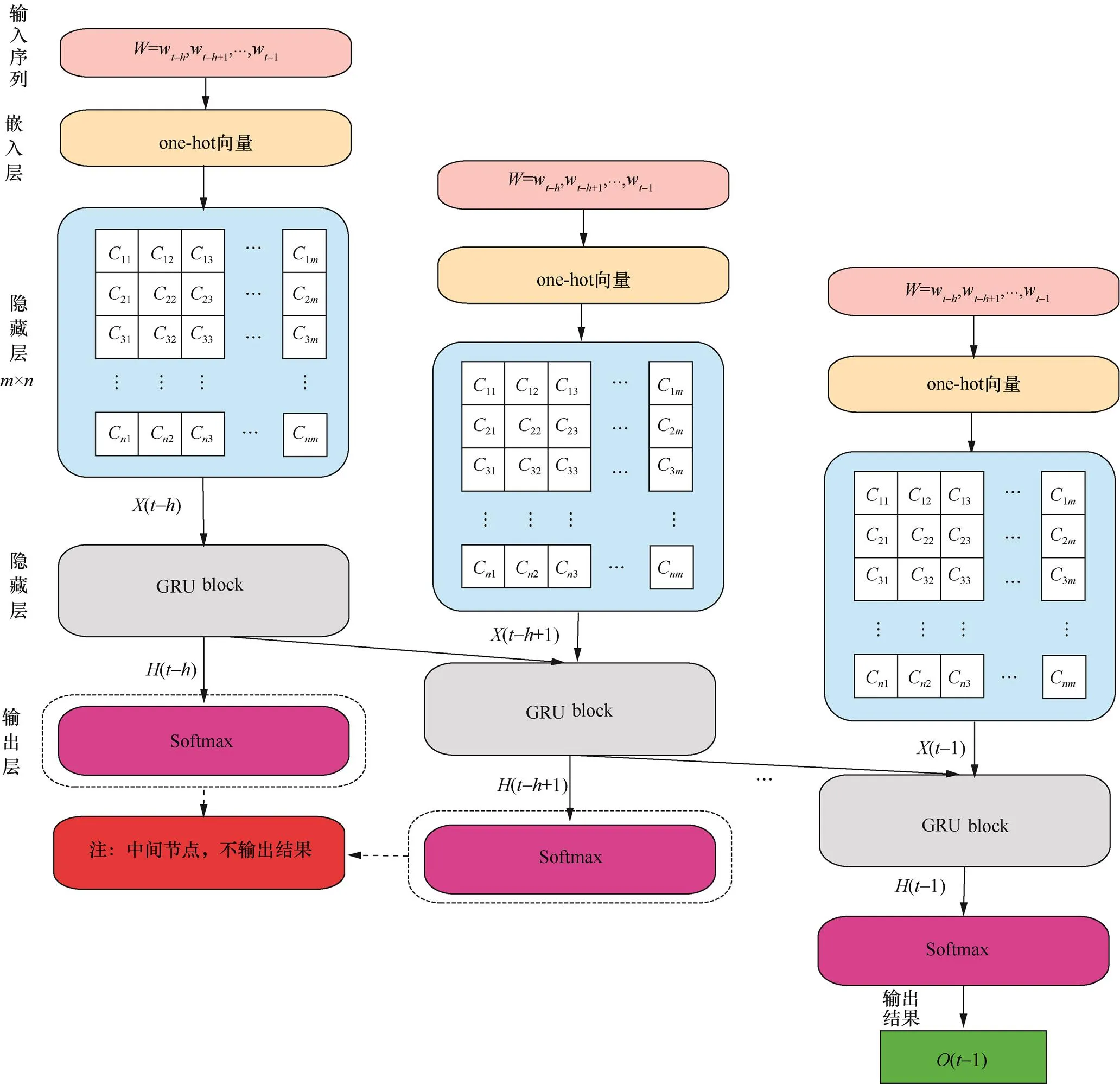
图1 执行路径异常检测模型结构
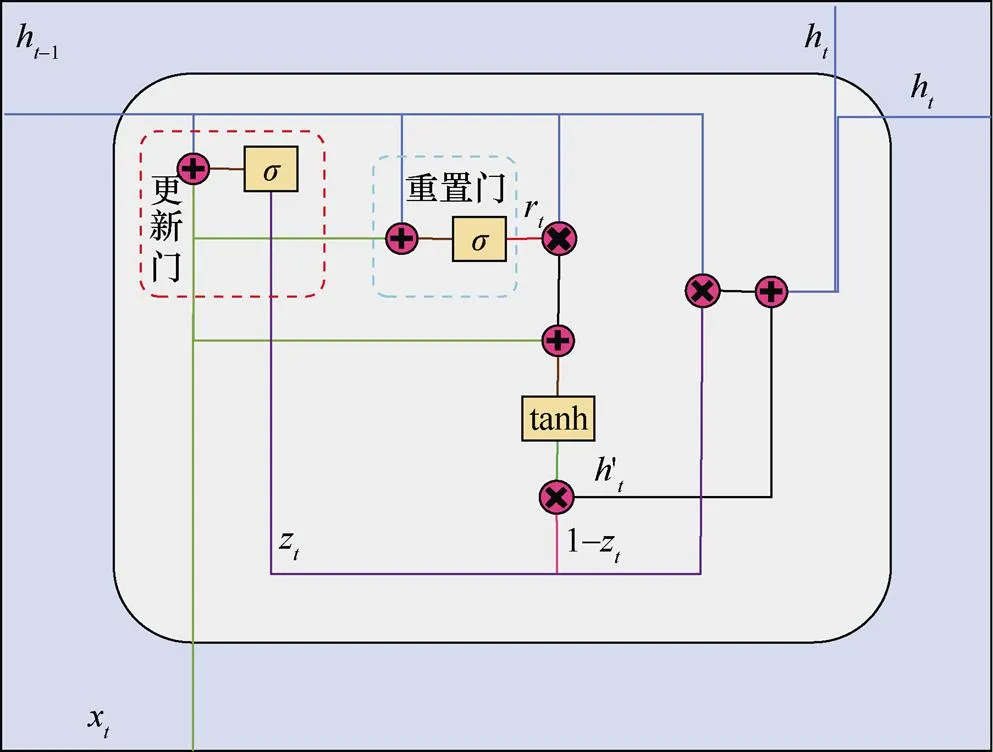
图2 单个GRU块内部结构
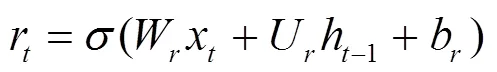
借助重置门,可以得到未被遗忘的历史记忆。将其与当前输入通过tanh激活函数计算,即可得到GRU单元的当前记忆内容。
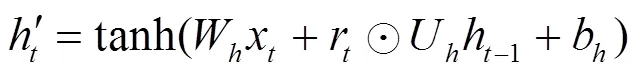
输出层:数据通过更新门,从当前记忆和历史记忆中收集信息,两者被保留的信息相加,就得到了当前GRU单元在时间序列上的输出。

当前GRU块的输出在时间序列上作为下一个GRU块的输入,而序列中最后一个GRU块的输出则作为整个模型输出层的输入。模型的输出层采用了一个Softmax多类分类器,通过Softmax函数计算得到一个维向量,每一维度的值代表logkey表中的每个元素出现在当前位置的概率,所有概率之和为1。计算过程的数学形式如下。
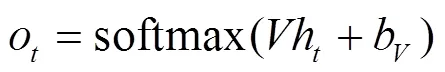
由此可得出每个logkey出现的概率。
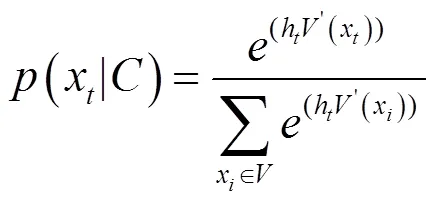
将logkey表按照输出的概率值从大到小排列,选取其中前个组成集合。若系统当前时刻输出日志的logkey存在于集合中,则认为该日志是正常的,否则视为异常。
为了提升性能,模型中的GRU网络被设计为多层的实现形式。上层GRU的隐藏层输出作为下层GRU的输入,层与层之间使用dropout方法对数据进行正则化。图3给出了一个双层GRU语言模型的结构,图中虚线箭头表示使用dropout的连接。如果应用场景需要更高的检测精度,模型的层数可以视实际情况增加。
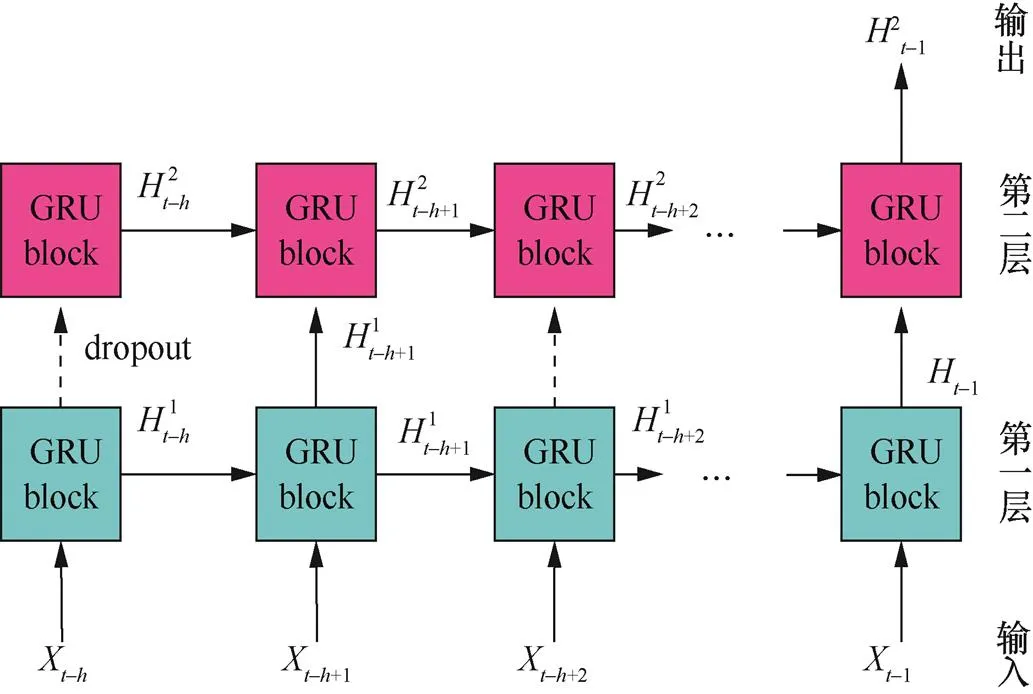
图3 双层GRU模型结构
模型共包括4个参数:、、、。其中,表示模型预测结果的可信范围,若观测值存在于前个预测值组成的集合中,则认为其正常,的默认值设为9。为滑动窗口大小,即输入序列长度,默认取10。为GRU模型的层数,默认采用两层GRU。为单个GRU块包含的存储单元数量,默认值为64。下文设置了多组对比实验,通过控制变量法测试单个参数值变化对模型性能的影响。
2.3 基于参数值的异常检测模型
在一般场景下,使用基于执行路径的日志异常检测模型可以检测出系统中大多数异常。然而,在某些场景下产生的异常,如系统遭受拒绝服务攻击(denial of service attack)导致的运行速度变慢,往往体现在系统日志参数值的变化上。本节构建了一个参数值异常检测模型,通过日志中参数值的变化趋势来检测系统异常状态。
每个日志条目由时间戳、log key和若干个参数组成,其中,相邻时间戳的差值代表两条日志生成的时间间隔,能够衡量系统的性能,也可将其看作一个日志参数。从日志条目中提取时间戳差值和参数值,构造出一个参数值向量,对于具有相同log key的日志条目,将其参数值向量按时间顺序生成一个序列,则不同的log key将生成多个参数值向量序列。每个参数值向量序列都可以看作一个单独的时间序列,因此参数异常检测问题被转化为多变量时间序列预测问题,通过预测值和实际值的对比,判断系统是否发生异常。
参数值异常检测模型由三大模块组成,分别为分类模块、预测模块和判断模块。分类模块根据log key对输入的参数值向量进行分类,结果传输到预测模块。预测模块依然采用GRU网络建模,针对每个具有不同log key的参数值向量序列,分别为其构建一个独立的GRU网络。每个GRU网络都可以看作一个–1的GRU时间序列模型,它在每个timestep输入为当前时刻的参数值向量,然后模型根据由各个时刻参数值向量组成的参数值向量序列预测出下一时刻的参数值向量。
GRU时间序列网络由输入层、隐藏层、输出层3层构成。输入层首先需要对数据进行预处理,使其适配GRU网络。预处理方式包括删除与预测无关的参数、将字符型数据编码为整数(如日志项connecting to node1,其中,node1为参数项,可将其编码为整数处理)、输入数据进行归一化(normalization)处理。数据归一化是机器学习中一项重要的预处理工作,具体做法是采用某种算法处理数据,将其限制在模型所需要的范围内。本文采用离差标准化(min-max normalization)作为模型的归一化方法,该方法基于样本数据的最大值和最小值对数据进行标准化,使处理后的数据特征分布在[0,1]范围内。其数学形式如下。

归一化后的数据输入隐藏层中参与后续处理。隐藏层的架构与2.2节描述执行路径异常检测模型类似,隐藏层节点之间相互连接形成一个完整的循环神经网络。
在隐藏层后加入一个输出层,输出结果为一个实值向量,即根据历史序列预测出的参数值向量。
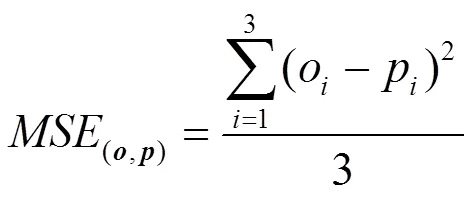
经过BPTT算法训练后的模型即可用来检测日志异常。日志的异常与否通过判断模块进行判定,判断的标准是一个基于训练样本的预测值与真实值之间的误差建模的高斯分布(Gaussian distribution),置信水平的阈值可以根据实验的实际情况调整。在检测阶段,如果预测值与观测值之间的误差处在高斯分布的置信区间内,则认为其为正常,否则视为异常。置信区间(以98%为例)用数学公式描述为
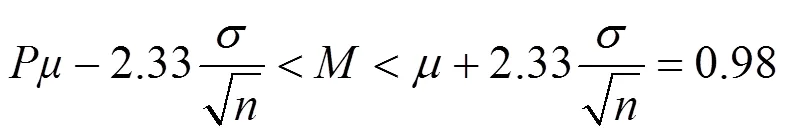
图4给出了参数值异常检测模型的整体架构以及其中GRU时间序列模型的架构。该模型能够检测系统各种性能的异常,如在一段日志时间戳的差值突然增大,可能意味着系统在这段时间中的运行速度变慢;又如日志中表示网络传输时间的参数值大幅度增加,则意味着网络延迟变大,在排除网络环境原因后,要考虑系统遭受地址解析协议(ARP,address resolution protocol)攻击的可能性。
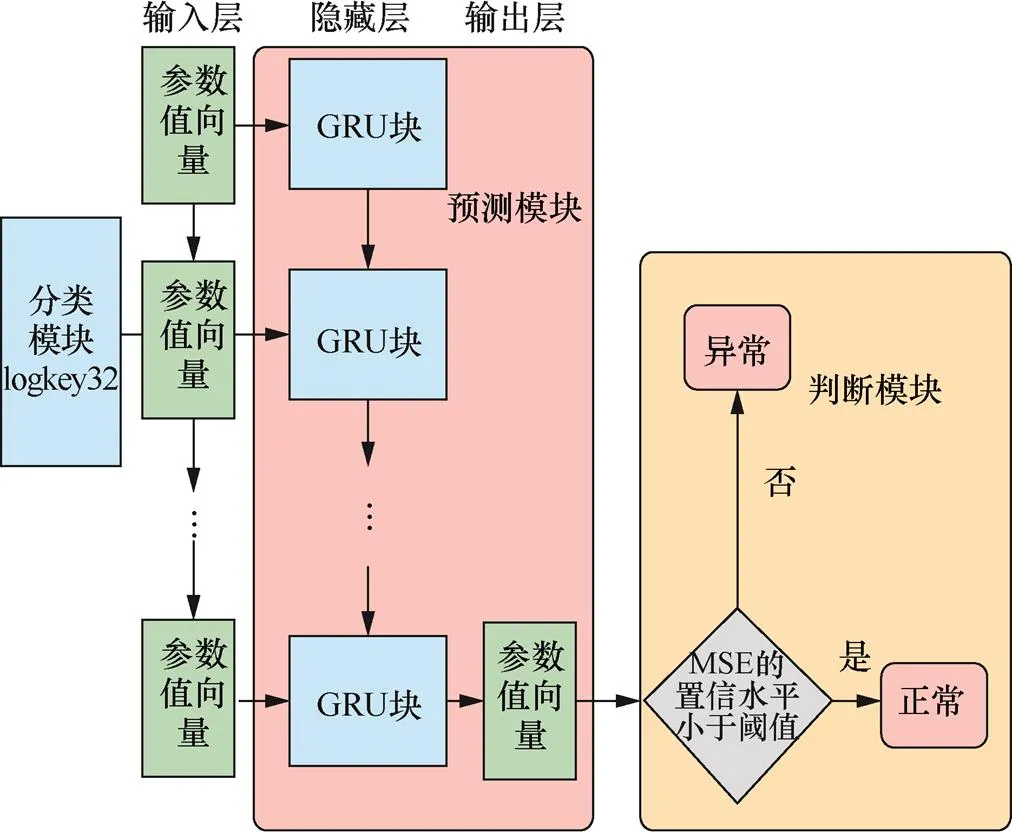
图4 参数值异常检测模型结构
2.4 模型训练
本文设计的两个GRU模型(执行路径异常检测模型、参数值异常检测模型)均采用系统正常执行产生的日志作为训练样本。首先前向计算(参见2.2节)得到每个参数的输出值和模型的最终输出,然后对比期望输出与真实输出得到待优化的目标函数,最后通过BPTT算法计算各个权重参数的梯度,通过梯度下降法对参数进行更新。
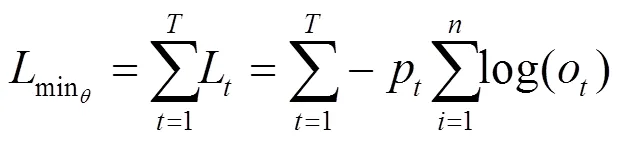
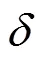
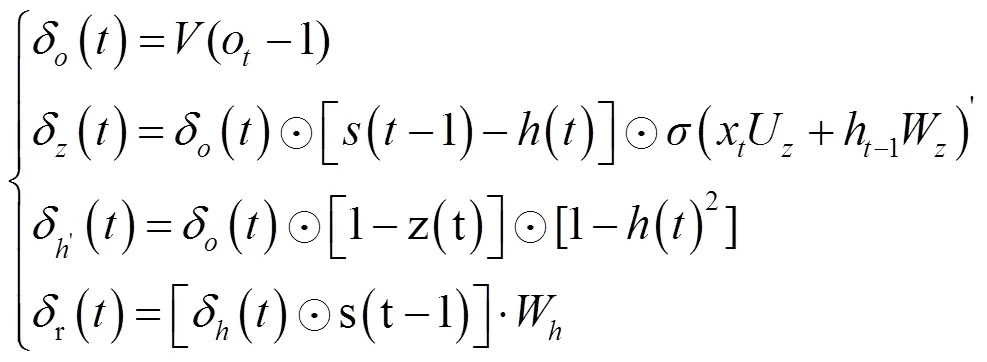
基于上述各式计算出的模型输出、重置门、当前状态以及更新门的误差信号,利用链式法则计算出各参数梯度。
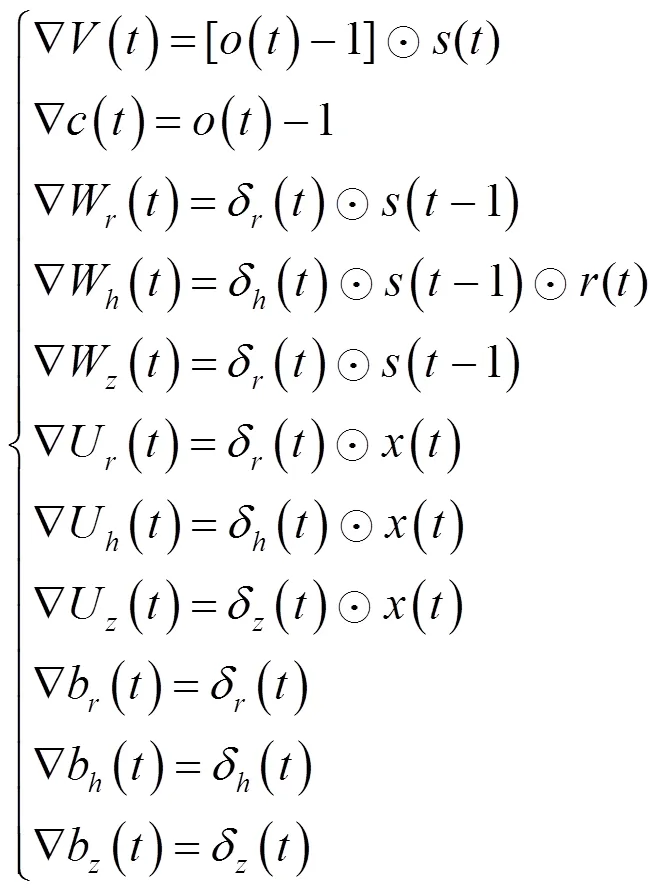
模型采用Adam[8]作为梯度下降优化算法。本文将每次更新学习的样本数量(batch size)设置为64。在此基础上,每学习一个mini-batch的样本数据,模型都会利用平均梯度更新动量。
一阶动量(梯度的均值):
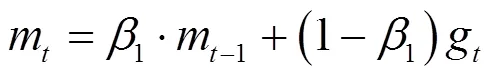
二阶动量(梯度的方差):
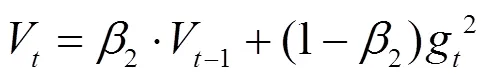

学习率(learning rate)是深度学习中另外一个重要的超参数,控制着模型中参数的更新速度,本文实验将初始学习率设为0.001。若采用固定学习率训练模型,当训练集的损失下降到一定程度时,便停止下降并在一定区间内来回震荡。针对这一问题,本文采用了学习率衰减(learning rate decay)算法,随着时间的推移逐渐减小学习率,学习率的更新方式基于文献[8]中的方法,其数学形式如下。
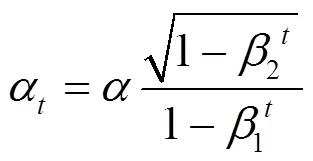
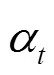
Adam借助学习率、一阶动量和二阶动量,从梯度的均值和方差两个角度出发,自适应地更新权重参数,其参数更新的数学形式如下。
使用训练集中的所有数据对模型进行一次完整训练称为1个epoch。本文模型共训练50个epoch,之后,神经网络基本收敛。
由于模型构造了多层GRU神经网络,因此模型的误差项会沿时间和空间两个方向反向传播。时间方向是指反向计算每个时刻的误差项,空间方向是指误差项向上层传播。在多层GRU中,上层的输出即为当前层输入,由此可得到上层输出的误差。
2.5 模型更新
根据设计思路,模型采用系统正常运行产生的日志进行训练。然而在实际训练中,样本数据往往无法包含所有的logkey,这样当系统生成的日志中包含不存在于样本数据集中的logkey时,就会造成误判。为此,模型构造了一个在线更新(online update)模块,基于线上反馈的假阳性结果实时调整模型的权重参数。
与离线训练不同,模型使用FTRL(followed the regularized leader)算法[9]进行模型更新。该方法针对权重参数的每一维度采用不同的学习率进行学习,且能够产生易于处理的稀疏解,其数学形式如下。
使用模型更新会大幅度降低模型对某些数据集的误报率,且模型更新和在线检测可以同步进行,保证了模型的检测效率。
3 实验评估
为验证两种基于GRU的日志异常检测算法的有效性,本节选取了几个具有典型代表性的日志数据集,在其上进行多角度对比实验并评估两种算法的性能。实验环境在个人笔记本上配置,处理器为Intel Corei7-6700HQ(2.60 GHz),NVIDIA GeForce GTX 965M GPU(2 GB),16 GB RAM(2 133 MHz),操作系统为Ubuntu 16.04(64位)。GRU网络的搭建和训练基于深度学习框架keras,tensorflow作为后端,编程环境为Python3.6.5。本节实验分为3部分。第一部分评估执行路径异常检测模型的性能,使用本文算法和当前前沿的日志异常检测算法在大型HDFS日志数据集上进行对比实验,以多种性能指标来衡量实验结果,综合评估本文算法的性能。然后对模型自身的参数进行调整,得到不同参数下的实验结果,以此研究参数变化对模型性能的影响。第二部分评估参数值异常检测算法的性能,人工构造了一个数据集,验证算法的有效性和对检测性能的提升。第三部分对模型更新模块的性能进行评估,通过对比实验研究使用模型更新和不使用模型更新对训练时间和检测结果的影响。
3.1 执行路径异常检测模型性能评估
实验选取了3种当前较为先进的日志异常检测算法:主成分分析[1](PCA,principal component analysis)、不变量挖掘[2](IM,invariant mining)和Deeplog[3]与本文GRU算法进行对比。其中,PCA和IM是离线检测算法,这两种方法均使用会话窗口(session windows)对日志进行分块(本文使用滑动窗口),从日志中提取出logkey,对logkey序列执行异常检测。He等[10]实现了这两种方法,并提供了开源源代码,相关代码可以在github上找到。DeepLog使用LSTM神经网络构建模型,能够实现对日志异常的在线检测,本文基于文献[10]中的描述实现了该方法。实验首先对比PCA、IM、DeepLog、GRU这4种方法的检测精度,然后对比Deeplog和GRU这2种在线检测方法的运行速度,从两方面综合评价本文算法。
对比实验采用的日志数据集为203个亚马逊EC2节点运行38.7 h产生的HDFS日志数据集[1]。该数据集中存在11 175 629条日志数据,包括575 062个事件跟踪(event trace),对应575 062个具有不同block_id的HDFS文件块。所有的block_id均由Hadoop领域专家标记为正常或异常(之所以能够对超过50万个事件跟踪进行标记,是因为大多数事件跟踪是相同且正常的),其中异常数据约占总数据的2.9%。文献[1]构造了这个数据集,随后在日志异常检测领域被广泛使用[2,3,11],该数据集可以在loghub获取。
由于PCA和IM均采用会话窗口,故对比实验将使用会话窗口作为异常检测的基准。将HDFS数据集按照block_id进行分组,可以分为575 062个会话,在检测过程中,只要1个会话中出现异常日志,该会话即被视为异常。由于HDFS日志的规则并不复杂,且数据集中会话存在大量重复,因此本文方法和DeepLog方法选取前1%日志数据中的正常会话作为训练集训练模型,模型参数、、、(各参数的具体含义参见2.2节)均采用默认值(=9,=10,=2,=64)。PCA和IM这两种无监督方法则不需要特定标记的训练集,均按照原文中给出的方法构建模型。HDFS日志数据中每一个会话的时间跨度都比较大,考虑到PCA和IM构建模型需要完整的会话,本实验选择整个日志数据集作为4种算法的测试集,表1给出了训练集和测试集的具体信息。
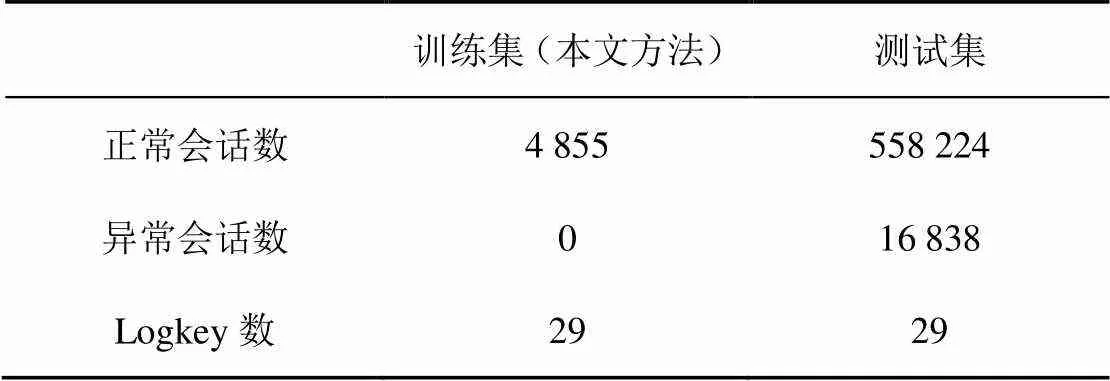
表1 训练集和测试集信息
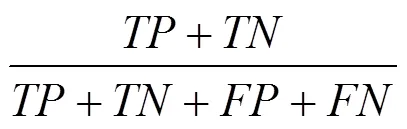

表2 PCA、IM、DeepLog、本文方法性能比较结果
图5通过精确率、召回率、值3个指标进一步对3种算法进行比较。可以看出,DeepLog方法取得了最高的召回率和值,精确率虽略低于PCA方法,但PCA方法取得较高精确率的代价是较低的召回率。本文方法的各项指标略低于DeepLog方法,但明显高于其他两者。
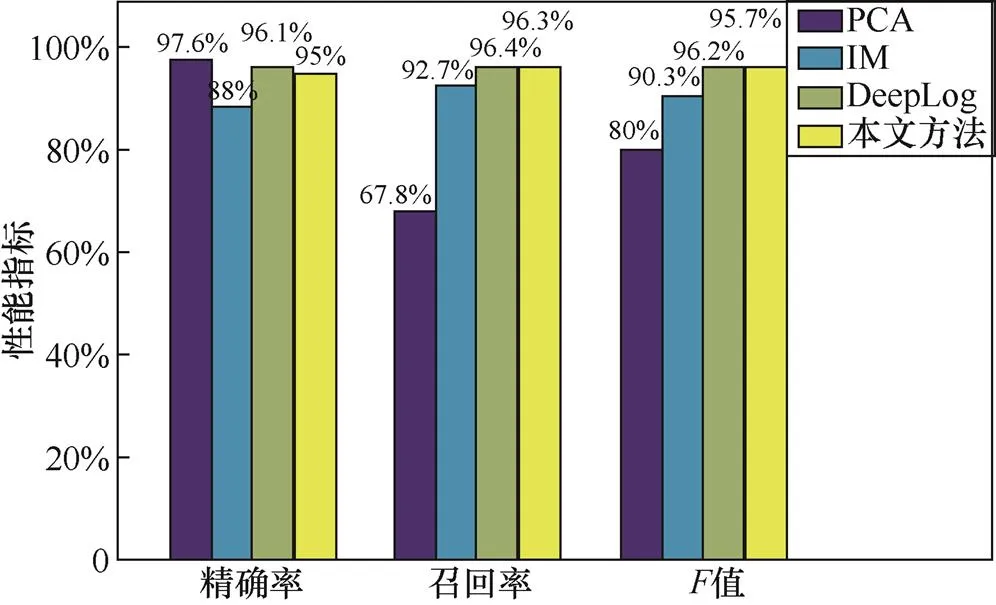
图5 PCA、IM、DeepLog、本文方法性能比较
接下来,对DeepLog和本文方法的运行速度进行单独对比,运行速度通过平均每条日志所需的检测时间来衡量。表3展示了2种方法在HDFS日志测试集上的运行速度。

表3 DeepLog和本文方法运行速度对比
可以看到,本文算法和DeepLog取得的检测精度相当,但运行速度方面本文算法有较大的领先,相比于DeepLog约提升了16.7%。
为研究模型参数变化对检测性能的影响,本文设计了基于控制变量法(control variates)的实验,当研究一个参数时,控制其余参数不变。模型的参数可以分为两种。一种是GRU层数()和GRU存储单元数()这种GRU网络本身的结构参数。图6显示了和对模型性能的影响。
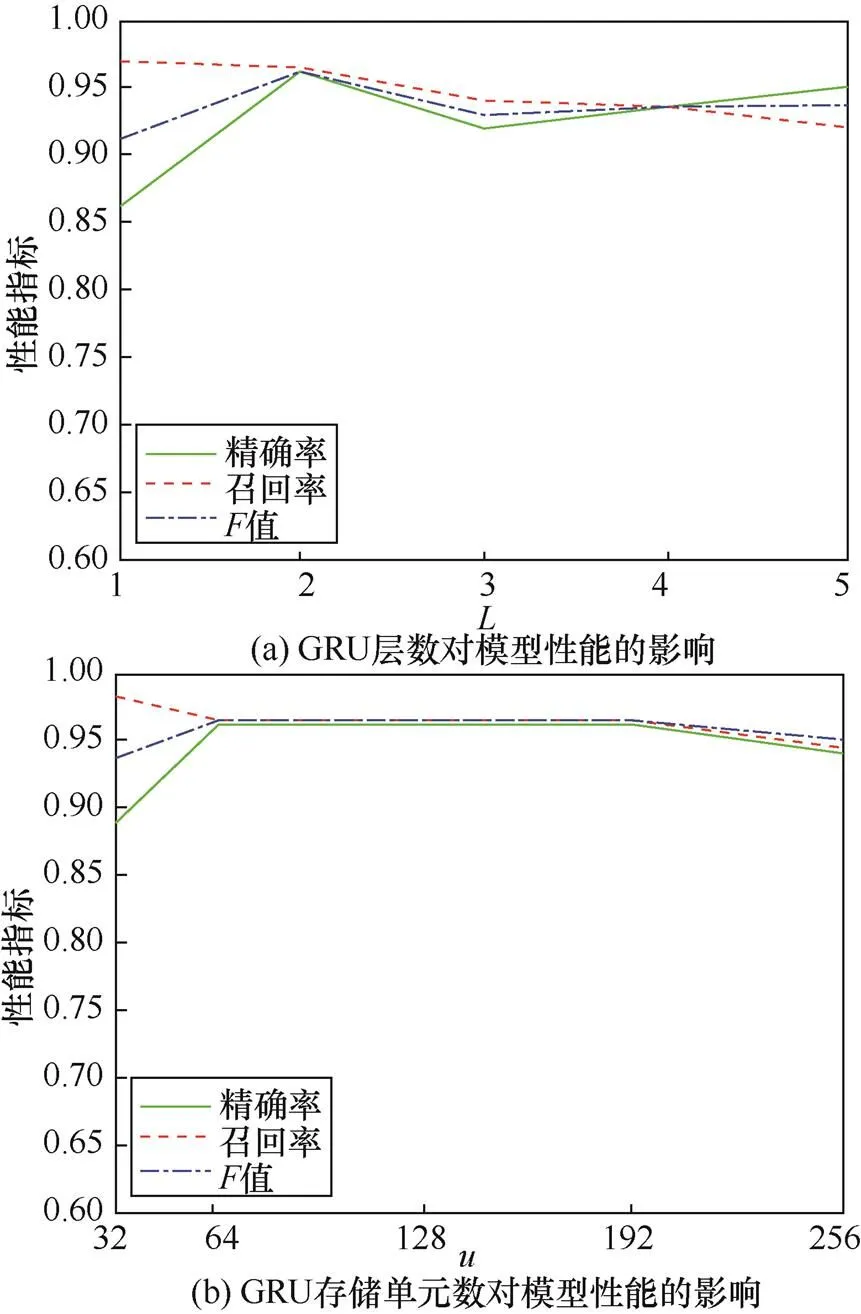
图6 GRU层数和GRU存储单元数对模型性能的影响
当=2时,模型性能达到最佳,当=3时,精确率和召回率均大幅度下降,检测精度降低,之后随着GRU层数增多,检测精度逐渐回升。由于训练样本过小,当GRU层数设置太大时,容易产生过拟合(over-fitting)现象,且过多的GRU层数会增大计算量;导致模型训练时间增加,因此GRU层数设置为2层较为合适。
表示GRU存储单元的个数,当其较小时,模型欠拟合(under-fitting)导致精确率较低;当将其增大到64时,模型性能总体上趋于稳定,随着其继续增大变化并不明显,;当其过大时,模型性能开始逐渐下降,可能是出现了过拟合。
另一种是针对样本数据的参数,包括正常值可信范围()和滑动窗口大小()。由图7可以看到随着的增大,模型的精确率不断增大,而召回率则不断减小,在极端情况下,当的值接近log key集的大小时,精确率可以达到100%,但随之而来的可能是极低的召回率。当=9时,值取得最大值,故=9可作为判断异常样本的阈值。
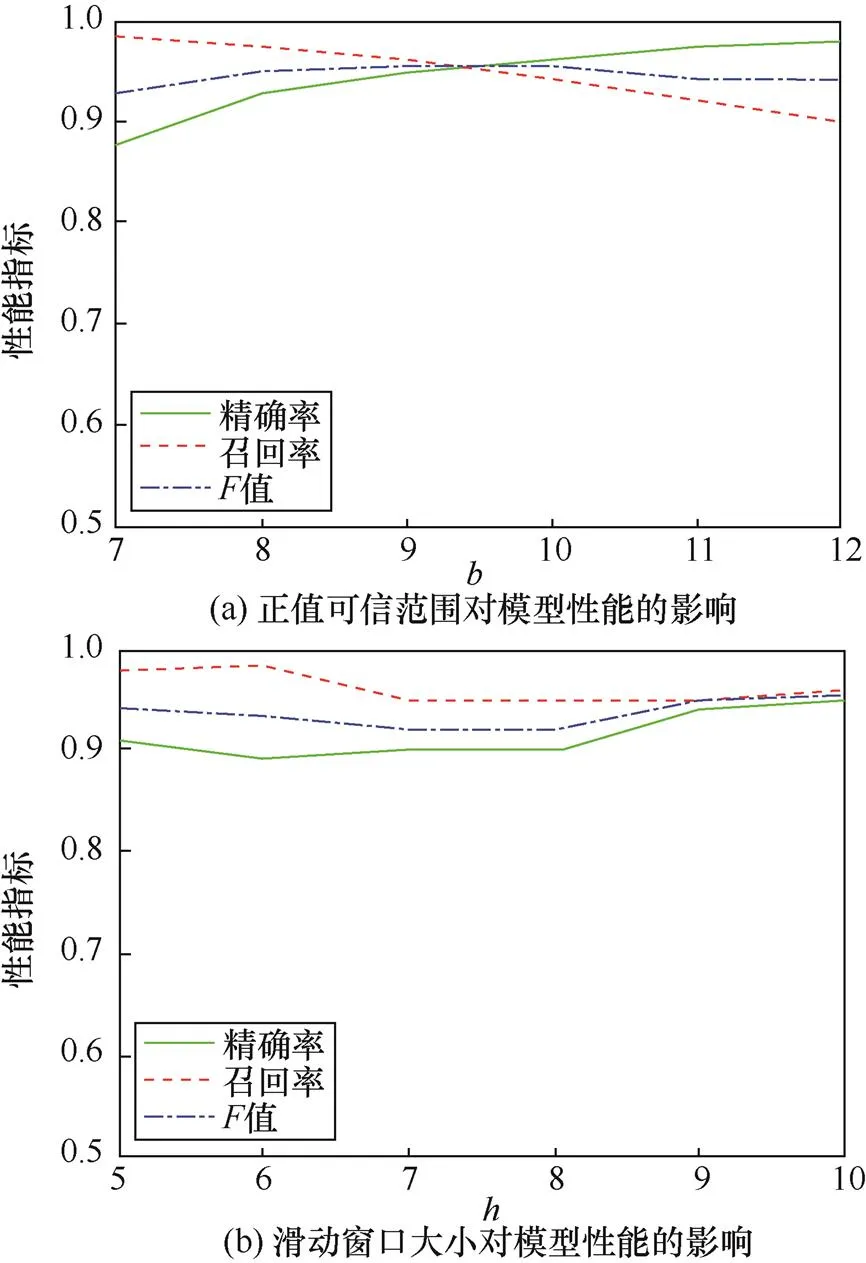
图7 正常值可信范围和滑动窗口大小对模型性能的影响
表示输入序列的长度,随着的增大,算法精确率先是逐渐增大而后趋于稳定,这说明序列长度较短时,GRU网络可能无法学习到日志样本中隐藏的规律,而序列较长时增加长度并不能显著提升模型性能,这是因为离预测值较远的数据对预测值的影响较小。
综合来看,本文算法比PCA和IM两种算法检测性能更好,比DeepLog算法检测速度更快,在处理大规模日志数据集时,可节省大量时间,目前日志异常检测对实时性的要求越来越高,更能体现出本文算法的优越性。且本文算法基于每条logkey进行检测,相比于基于会话的检测方法适用性更广。和下文中参数值异常检测算法结合使用,可以进一步提升异常检测性能。
3.2 参数值异常检测模型性能评估
对于参数值异常检测算法,选取了Smartbi(报表工具)的客户端日志作为实验数据集。Smartbi服务端安装在个人笔记本上,客户端安装在个人台式机上。当客户端执行任务时,会调用服务端数据库中的数据,服务端和客户端之间发生通信。实验在Smartbi上设置了一个重复的定时任务,通过控制网络速度模拟系统可能遭受拒绝服务攻击的场景。任务共重复了600次,最终采集到37 287条客户端日志。图8给出了Smartbi的部分日志及其解析后得到的参数值向量。
当网络波动时,日志的参数值会表现出异常。出现异常的参数值序列可分为两种:一种是相邻时间戳的差值过大,另一种是请求消耗的时间过大,这两种异常充分反映出网络的波动情况。本实验基于参数值异常检测算法构建模型,将是否能够检测出异常参数值序列作为模型有效性的评估标准。
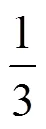
对于执行路径异常和参数值异常都存在的日志数据集,加入参数值异常检测可以大幅度提升检测精度。为证明参数值异常检测算法的优势,本文在Smartbi异常日志中人为加入了5条异常消息(Error:pleasere-excutethecommand),模拟执行路径异常,然后使用执行路径检测模型和参数值异常检测模型对Smartbi异常日志数据进行检测,与仅使用执行路径异常检测模型进行对比。表4给出了检测结果(多组logkey的总体检测结果),可以看到,单独使用执行路径异常检测模型取得的召回率仅为22.7%,而同时使用两种模型则准确地检测出了所有异常,取得了100%的召回率,相比仅使用执行路径异常检测模型有大幅度提升。实验结果表明,对于某些参数值存在异常的日志,由于logkey序列并没有发生变化,执行路径异常检测模型无法检测出这类异常,而参数值异常检测模型则可以对不同logkey进行分组,通过衡量预测值和真实值之间的均方误差准确地检测出参数值异常,从而提高检测召回率。

表4 两种异常检测模型的检测结果对比

图8 Smartbi日志及其解析结果
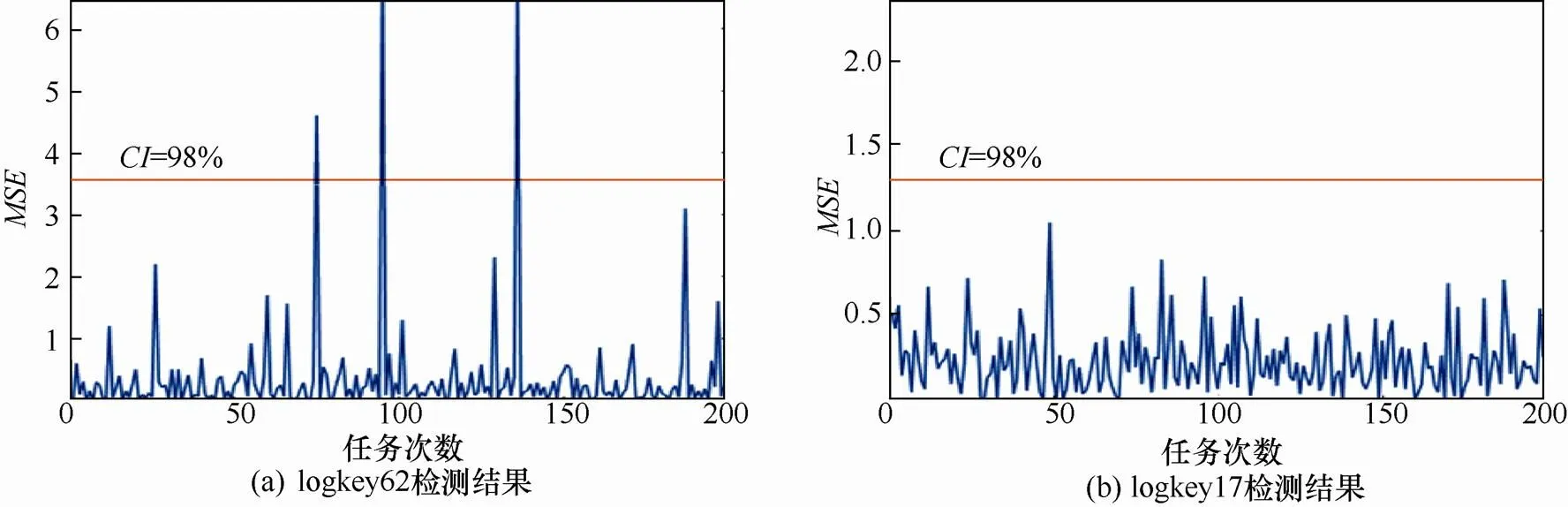
图9 不同logkey下参数值异常检测结果
3.3 基于模型更新的性能提升
本文算法虽然在HDFS日志异常检测实验中取得了较好的性能,但在处理一些更加不规则的日志(如系统日志)时,难免会发生训练集无法涵盖所有正常执行路径的情况,当检测阶段出现不包含在训练集中的执行路径时,会引起错误预测,将其识别为异常。模型更新模块可以有效解决该问题,本节设置了是否进行模型更新的对比实验,来验证其有效性。
本实验选用的日志数据集为708 M的BlueGene / L超级计算机的系统日志[12],该数据集包含4 747 963条日志,其中348 460条被标记为异常。文献[11]最早公开了该数据集,现已被广泛应用于日志解析,可从loghub下载得到。与HDFS日志不同,该数据集中很多日志只在特定时间出现,因此训练集很可能无法涵盖所有的正常执行路径和logkey,这也是该数据集被选用的原因。
对比实验分为两组,分别使用数据集中前10%和前20%的正常日志条目训练模型,其余数据作为测试集。模型更新使用训练好的模型检测异常,每当发现检测到的结果为假阳性时,使用该结果的输入输出序列更新模型;不使用模型更新的情况则只进行异常检测,不对模型做任何增量更新。由于样本数据集中正常日志数据大幅度重复且种类较少,因此本次实验使用单层GRU异常检测模型(=1),窗口大小设定为3,设定为5。为防止产生欠拟合,存储单元数量设定为256,多次实验证实该参数设置下异常检测准确率最高。
表5给出了使用和不使用模型更新两种情况下的FP、FN、TP,其中N表示不使用模型更新,Y表示使用模型更新。结合图10中的其他性能指标,可以看到在10%训练数据下,存在较多的假阳性误报,模型的精确率和值非常低;将训练数据扩大到20%,精确率和值有了一定提升,但提升幅度并不大;在经过模型更新后,检测结果的假阳性大幅度减少,精确率和值显著提升。
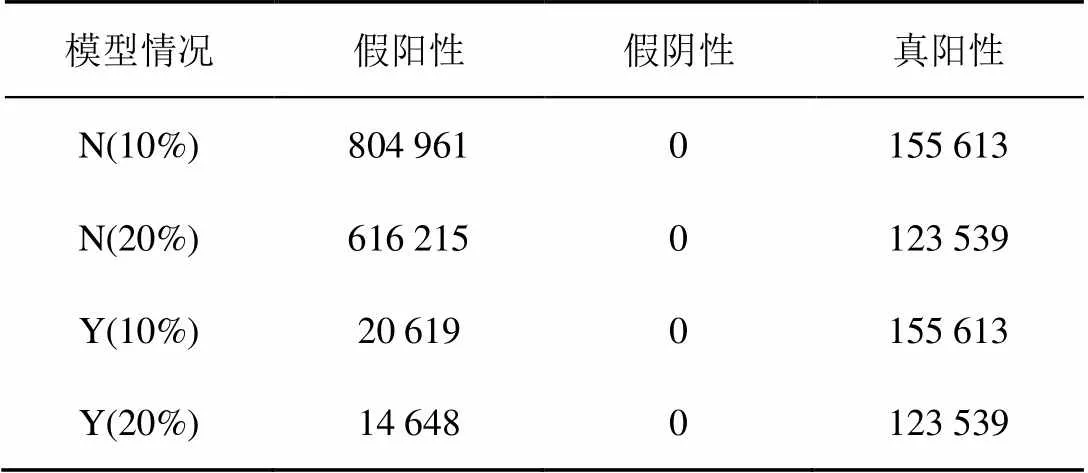
表5 使用模型更新和不使用模型更新性能对比结果
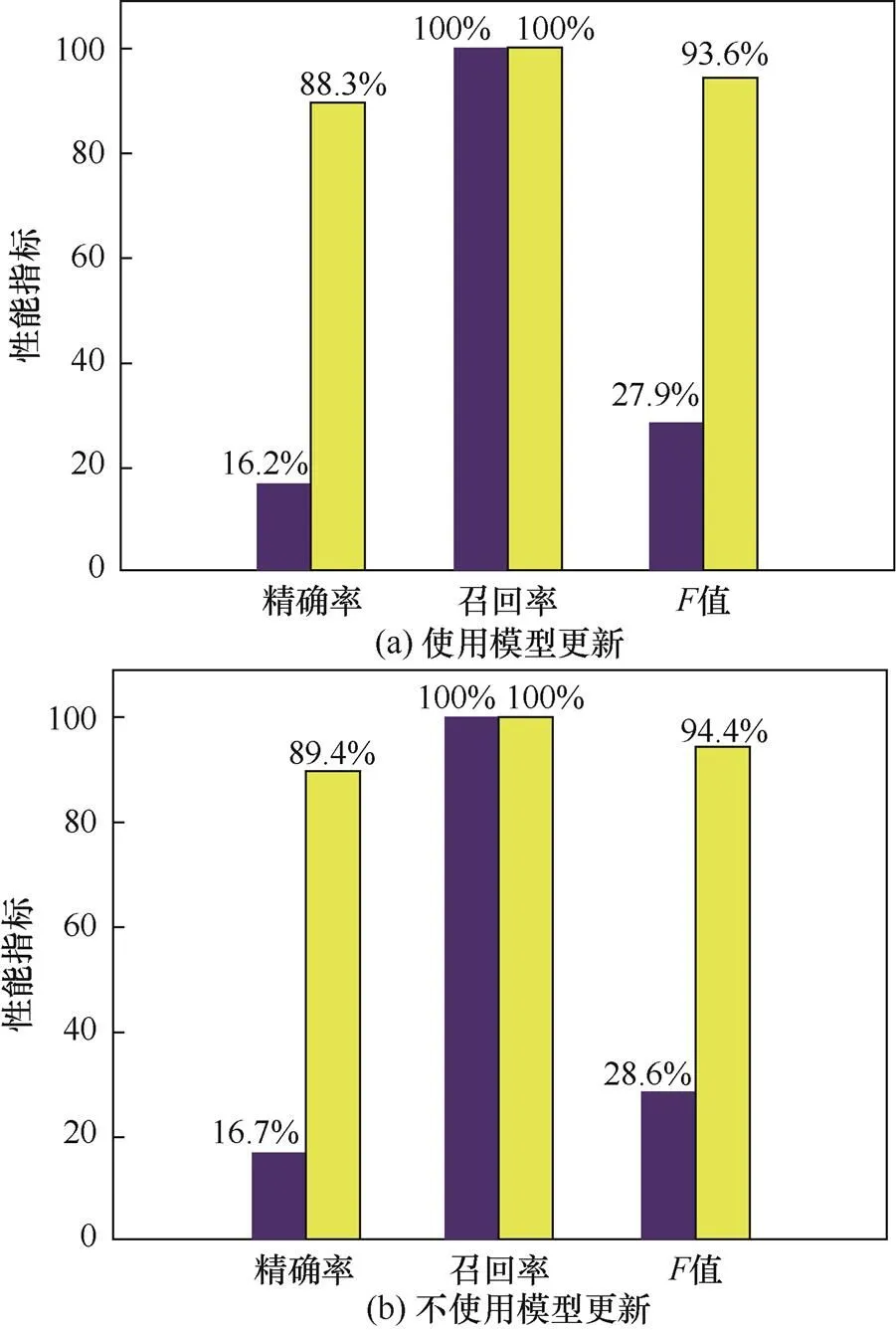
图10 模型使用模型更新和不使用模型更新性能对比
实验证明了模型更新算法的有效性,经过模型更新,模型的检测精度大大提升。在使用10%的正常日志作为训练集的情况下,模型更新将模型的精确率提高了72.1%;在使用20%的正常日志作为训练集的情况下,模型更新将模型的精确率提高了72.7%。模型更新和异常检测能够并行执行,在使用当前权重参数执行异常检测的同时,模型可以进行模型更新,因此,模型更新并不会增加过多时间成本。
4 结束语
当前日志异常检测领域中涉及深度学习的研究相对较少。本文研究针对日志异常检测领域的薄弱点,提出了一种基于GRU的日志异常检测算法,使用Spell解析日志,从log key和参数值2个角度构建了2个检测模型。模型的训练以BPTT算法为基础,使用梯度下降法更新权重参数。在模型的基础上提出一种模型更新策略,使模型可不断学习新的日志规则。实验结果表明,本文算法在HDFS大型日志数据集上表现优异,精确率和召回率优于当前前沿的日志异常检测方法。此外,本文针对参数变化对模型性能的影响进行分析,并验证了模型更新策略的有效性。本文为今后相关工作提供了算法参考和模型构建基准,具有一定理论指导意义。面对日志数量巨大,日志规则复杂的现状,本文研究有较高的应用价值。
[1] XU W, HUANG L, FOX A, et al. Detecting large-scale system problems by mining console logs[C]//ACM SIGOPS 22nd symposium on Operating systems principles. 2009: 117-132.
[2] YU X, JOSHI P, XU J, et al. CloudSeer: workflow monitoring of cloud infrastructures via interleaved logs[J]. ACM Sigarch Computer Architecture News, 2016, 44(2):489-502.
[3] DU M, LI F, ZHENG G, et al. Deeplog: anomaly detection and diagnosis from system logs through deep learning[C]//2017 ACM SIGSAC Conference on Computer and Communications Security. 2017: 1285-1298.
[4] JURAFSKY D. Speech & language processing[M]. Pearson Education India, 2000:35-61.
[5] DU M, LI F. spell: Streaming parsing of system event logs[C]//IEEE 16th International Conference on Data Mining (ICDM). 2016: 859-864.
[6] ZHU J, HE S, LIU J, et al. Tools and benchmarks for automated log parsing[J]. arXiv preprint arXiv:1811.03509, 2018.
[7] HE P, ZHU J, HE S, et al. An evaluation study on log parsing and its use in log mining[C]//46th Annual IEEE/IFIP International Conference on Dependable Systems and Networks (DSN). 2016: 654-661.
[8] KINGMA D P, BA J. Adam: a method for stochastic optimization[J]. arXiv preprint arXiv:1412.6980, 2014.
[9] MC MAHAN H B, HOLT G, SCULLEY D, et al. Ad click prediction: a view from the trenches[C]//The 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. 2013: 1222-1230.
[10] HE S, ZHU J, HE P, et al. Experience report: system log analysis for anomaly detection[C]//IEEE 27th International Symposium on Software Reliability Engineering (ISSRE). 2016: 207-218.
[11] XU W, HUANG L, FOX A, et al. Online system problem detection by mining patterns of console logs[C]//Ninth IEEE International Conference on Data Mining. 2009: 588-597.
[12] OLINER A, STEARLEY J. What supercomputers say: a study of five system logs[C]//37th Annual IEEE/IFIP International Conference on Dependable Systems and Networks (DSN'07). 2007: 575-584.
Research on system log anomaly detection based on deep learning
WANG Yidong1, LIU Peishun1, WANG bin2
1. College of Information Science and Engineering, Ocean University of China, Qingdao 266100, China 2. School of Continuing Education, Ocean University of China, Qingdao 226100, China
The system log reflects the running status of the system and records the activity information of specific events in the system. Therefore, the rapid and accurate detection of the system abnormal log is important to the security and stability of the system. A log anomaly detection algorithm based on GRU neural network is proposed. Log parsing is implemented based on log key technology. Log anomaly detection is realized by using anomaly detection model of execution path and anomaly detection model of parameter value. The system has the advantages of less parameters and faster training. It improves the running speed while achieving higher detection accuracy, and is suitable for log analysis of large information systems.
log anomaly detection, deep learning, GRU neural network
王易东(1996− ),男,山东济宁人,中国海洋大学硕士生,主要研究方向为信息安全、云计算和大数据。

刘培顺(1975− ),男,山东菏泽人,中国海洋大学讲师,主要研究方向为网络与信息安全。
王彬(1981− ),男,山东沾化人,中国海洋大学实验师,主要研究方向为计算机应用技术。

TP390
A
10.11959/j.issn.2096−109x.2019055
2019−03−12;
2019−04−30
刘培顺,liups@ouc.edu.cn
国家重点研发计划基金资助项目(No.2016YFF0806200)
The National Key Research and Development Program of China (No.2016YFF0806200)
王易东, 刘培顺, 王彬. 基于深度学习的系统日志异常检测研究[J]. 网络与信息安全学报, 2019, 5(5): 105-118.
WANG Y D, LIU P X, WANG B. Research on system log anomaly detection based on deep learning[J]. Chinese Journal of Network and Information Security, 2019, 5(5): 105-118.
