大数据产业发展能力特征要素及提升路径
2019-10-16沈俊鑫刘雅婷
沈俊鑫 刘雅婷

摘 要:发展大数据产业是提升综合国力的重要战略布局。选取中国大陆31个省市自治区作为案例样本,基于架构理论及匹配逻辑,从产业发展基础、信息资源开发利用、技术创新能力三个维度出发,采用克服传统QCA静态特性的时差型定性比较分析(tsQCA)方法,研究因素变化及其交互作用对大数据产业发展能力提升作用机制,总结归纳大数据产业发展能力提升的核心要素及发展路径。
关键词:大数据产业;产业发展能力;要素匹配;tsQCA
中图分类号:F272.5;F224.7 文献标识码:A 文章编号:1005-6378(2019)03-0077-09
DOI:10.3969/j.issn.1005-6378.2019.03.012
引 言
发展大数据产业已是深化信息发展的核心主题,将成为提升我国综合国力的重要战略布局。随着大数据应用不断深入,大数据产业将进入快速发展阶段,战略布局大数据产业刻不容缓[1]。目前,各地区大数产业发展能力都在不断发生变化,大数据产业集群已初步形成,多数位于经济实力雄厚和产业基础良好的地区,而贵州省虽产业基础相对薄弱,但其大数据产业发展能力却不断增强,鉴于不同地区产业发展基础、信息资源开发利用水平与科技创新能力等要素的差异,找出大数据产业发展关键因素,并匹配适合区域自身发展的产业提升路径,对于推动大数据产业发展至关重要。
新兴产业发展能力是一个综合性和动态性概念,它是产业发展基础能力、科技创新能力、人才支撑能力、资源开发利用能力等一系列相关能力的集中体现[2]。大数据产业发展能力是指一个地区扩大大数据产业规模、提升大数据产业实力的潜在能力,即成长能力。从新兴产业发展动力来看,产业基础、技术创新、资源利用、科研人才等因素是典型动力源[3]。而关于大数据产业发展的研究,学者们主要关注和探讨了影响其能力提升的主要因素。Adrian[4]指出信息产业基础设施是大数据产业发展能力提升的基础保障;Erickson[5]则认为若信息基础设施薄弱,数据科学家缺乏,数据分析技术不足,大数据产业发展能力将无法得到提升;Jemal Abawajy[6]认为大数据的传输需要超宽带支持,网络基础设施水平是影响大数据产业发展的关键因素;迪莉娅[7]认为创新人才不足、创新经费短缺等问题对大数据产业发展能力提升具有明显阻碍作用;Libaque-Saenz[8]认为信息消费和两化融合水平等信息开发利用能力方面的不足及大数据创新能力滞后都会抑制大数据产业发展能力提升;张勇进等[9]总结了大数据产业发展能力关键要素包括产业发展基础、关键技术研发、人才培养、产业扶持、资金保障等。
上述大数据产业发展影响要素及其作用机理分析主要集中在信息产业基础、信息资源开发利用及技术创新能力三个方面,着重探讨的是哪些因素影响大数据产业发展能力,但对于是什么因素变化引起大数据产业发展能力提升,以及关于如何提升大数据产业发展能力的研究较为匮乏。鉴于此,本文考虑大数据产业发展能力前因条件复杂性,综合研究大数据产业发展过程中产业基础能力、信息资源开发利用能力及技术创新能力三维度因素变化及其交互作用,采用以构型理论为基础的时间序列定性比较分析方法(time-series Qualitative Comparative Analysis,tsQCA),对提升大数据产业发展能力问题进行研究。该方法有效克服传统QCA静态缺陷,可探寻因素变化及其组合对大数据产业发展能力变化的影响,寻找匹配区域发展特征的大数据产业发展能力提升路径,为制定大数据产业发展战略提供政策建议。
一、模型构建与研究方法
(一)大数据产业发展能力特征要素匹配模型构建
1.基础支撑、资源开发利用和技术创新各维度因素选取
大數据产业发展是一个综合概念,其发展能力影响因素众多。本文通过梳理物联网、云计算等信息产业发展能力评价指标,以沈俊鑫[10]所构建的大数据产业发展能力评价指标体系为基础,综合考虑大数据产业发展相关特性,从产业发展基础支撑能力、信息资源开发利用能力、信息技术创新能力三个维度进行分析。
其中产业基础是指大数据产业发展所赖以的经济水平、产业结构、基础设施环境等,主要选取经济发展水平、产业结构、信息基础设施发展水平和信息化发展水平四个因素进行分析。信息资源开发利用是指通过开发挖掘新的信息资源,同时对已有信息资源进行归并、重组和加工,使信息资源能被更好利用从而实现其价值[11]。本文主要用信息资源开发利用指数、信息消费指数、两化融合指数等指标进行测度。如果产业基础支撑能力和信息资源开发利用能力是驱动大数据产业发展的外部动力,那么技术创新能力则是推动其发展的内在核心动力。推动大数据产业发展的技术创新因素主要选取R&D经费投入强度、百亿GDP发明专利申请数、每万人中研发人数。
2.特征要素匹配模型
Venkatraman[12]提出的匹配逻辑认为:当一个结果发生受多个变量影响时,若匹配现象有统一标准,其表现形式为架构;若缺乏统一标准,其表现形式为格式塔,它们的核心均为用一系列相关构成因素组合来刻画复杂多维的社会现象。本文大数据产业发展能力提升涉及多个特征变量,且各维度变量在大数据产业发展能力研究中没有统一匹配标准。因此可以在格式塔匹配逻辑框架基础上,探究使大数据产业发展能力提升现象产生的若干相关联因素的构成与配置。
架构理论及格式塔匹配逻辑认为某一影响因素对结果产生单独作用的效果非常微弱[13]。当上述十个因素相互匹配时,大数据产业的发展能力可得以有效提升。基于此,本文创建了大数据产业发展能力特征要素匹配模型,如下图1所示:
(二)研究方法
1. 传统QCA及其演化与拓展
QCA是Ragin于1987年首次提出的一种以案例研究为导向的定性与定量相结合的研究方法。相较于传统定量研究,它主要关注社会现象多重条件并发的诱因,且假定条件与结果变量之间存在非线性和可替代关系。由于QCA在解决前因复杂性问题上具有明显优越性,如今已广泛应用于政治、管理、医疗等多个研究领域。
目前QCA主要分化出了以清晰集分析(crisp-set Qualitative Comparative Analysis, csQCA)、模糊集分析(fuzzy-set Qualitative Comparative Analysis, fsQCA)和多值集分析(multi-value Qualitative Comparison Analysis,mvQCA)为基础的三种传统类型,但均未考虑事件发生的时间顺序[14]。事实上时间因素或要素的先后顺序对结果产生的影响有时甚至处于研究的核心位置。
鉴于此,Caren Panofsky [15]提出了时序定性比较(temporal Qualitative Comparative Aanalysis,tQCA)分析技术,实现了定性比较分析在时间维度上的突破。tQCA在一定程度上弥补了传统QCA时间维度上的缺陷,但它侧重的是事件和条件发生的先后顺序,而时序只是考虑时间因素的一个方面。考虑可否用不同时间点间条件变量的变化来观测结果变量的变化情况,Hino[16]提出了时间序列定性比较分析(time-series Qualitative Comparative Analysis,tsQCA),它侧重于分析数据的跨时间变化。tsQCA通过将时间序列数据转化为QCA格式来研究跨时间维度的连续过程,不同于tQCA关注事件的顺序,tsQCA主要关注变量在一定时间内的变化对结果变化的作用机理。tsQCA可以分为汇总型、固定效应型和时间差异型三种。
2.tsQCA方法的选择
鉴于大数据产业发展能力的复杂性,相较于传统定性、定量方法,QCA能很好的处理此类问题[17],但传统QCA方法由于在分析过程中忽略了时间因素影响而饱受争议。在考虑时间因素分析中,tQCA可以观察到不同因素的组合顺序对大数据产业发展能力的影响,但对于是什么因素的变化使大数据产业发展能力发生改变的问题显得束手无策。而大数据产业本身是从无到有,从弱到强,其影响因素在不断变化,同时各地区大数据产业发展能力也在不断变化,因此运用tsQCA方法进行研究更加合适。上述三类tsQCA中,汇总型QCA易受案例样本之间异质性影响,造成结果不稳定;固定效应QCA会随时间变化集合不同形式的案例,导致结果可比性不强;因此本文选用时间差异型QCA探究是哪些因素的变化引起大数据产业发展能力发生改变。
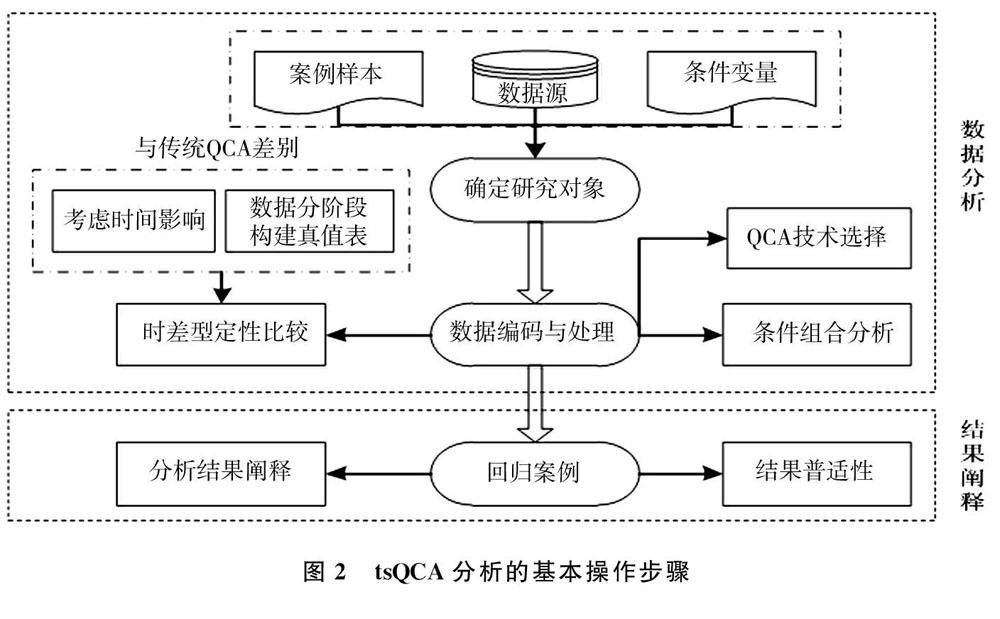
tsQCA主要分为数据分析和结果阐释两大步骤,其基本操作流程如图2所示。(1)确定研究对象。根据研究问题选取合适案例样本;结合理论基础及案例实际情况,确定结果和条件变量;根据确定的变量选择实证数据源。(2)数据编码与处理。首先根据研究确定的各变量特点,结合分析软件,选择数据处理方法。本文选择的是时差型定性比较分析技术,在数据处理过程中将变量按时间顺序分成不同阶段,以前后各阶段变量的差异变化为基础将时间因素考虑在内构建真值表。此步骤能很好的体现是哪些条件变量的改变使结果变量产生变化,这是与传统定性比较分析的区别所在。其次根据构建的真值表进行分析,得到使结果产生的条件组合。(3)回归案例。分析结果得出之后重新返回案例,根据不同的条件组合对具体案例进行阐释。最后分析条件组合的普适性,结合当前社会现象及案例实际背景分析结果能否有力地解释当前社会现状。通过案例回归及理论比对,对分析结果进一步完善。
二、时差型定性比较分析
(一) 变量选择及数据来源
本文选择中国大陆31个省市自治区组成案例样本,首先一定程度上弥补了单一案例研究的片面性;其次样本数量在10-80之间且数据具有较高可获性适用于定性比较分析的中小样本研究;此外,所选案例中既有大数据产业发展能力较高的地区,也有发展能力相对较低的地区,既有能力提升的区域也有能力不变或下降的区域,这样既使分析具有可比性,也让研究结果更有意义。
变量设计是QCA分析的关键步骤。本文将大数据产业发展能力作为唯一结果变量,鉴于目前尚不存在直接的统计方法和评估体系对大数据产业发展能力进行测度,同时考虑时差型定性比较分析特点,本文采用各省大数据产业发展能力的指数排名进行研究,数据来自百度指数。同时影响大数据产业发展能力的因素划分为产业发展基础支撑能力、信息技术创新能力和信息资源开发利用能力三个维度10个指标。其数据来源如下:(1)产业发展基础中经济发展水平和产业结构数据来源于中国统计年鉴,信息基础设施发展水平数据源于信息年鉴,信息化发展水平数据源于中国信息社会发展报告。(2)信息技术创新能力中R&D经费投入强度、百亿GDP发明专利申请数、每万人中研发人数三个因素数据来源于高新技术产业统计年鉴并通过相关计算得到。(3)信息资源开发利用能力中信息资源开发利用指数、信息消费指数、两化融合指数三个因素,数据分别来源于中国信息资源开发利用指数报告、中国统计年鉴和两化融合发展水平评估报告。本文大都采用官方公布的统计数据,这样可以确保数据信度,使分析结果更加公正合理。
(二) 数据处理
通过对案例样本比较分析发现,各案例中人均GDP、第三产业占比、基础设施发展水平等十个条件变量在不同时期的横向位置都出现了变化,与此同时,大数据产业发展能力的排名也在相对变动。因此,我们以此为出发点,运用时差型定性比较,分析是哪些因素的变化促成大数据产业发展能力发生改变。本文在搜集、整理各变量的数据后,将时间区间分为3个阶段,用各变量数据的横向位置变化反映各变量随时间的变化。第一阶段为2011-2012年数据排名的平均值记为S1,第二阶段为2013-2014年数据排名的平均值记为S2,第三阶段为2015-2016年数据排名的平均值记为S3,然后对各阶段进行差异比较。其中,△值为负表示排名上升,为正表示名次下滑,为0表示名次没有发生改变。
根据各变量位置变化情况,运用模糊集对变量进行数据校准。考虑软件性质,定位点在设置时做了相应处理,但相对位置并没有发生改变,因此并不影响数据的模糊校准。依据Coduras[18]提出的0.05、0.5和0.95锚值法,以样本数据上四分位值、中位值和下四分位值为标准,设定各变量的定位点如下所示:经济发展水平(0,4,8)、产业结构(0,13,20)、信息基础设施发展水平(0,6,10)、信息化发展水平(0,10,20)、R&D经费投入强度(0,5,8)、百亿GDP发明专利数(0,7,11)、每万人中研发人数(0,8,11)、信息资源開发利用指数(0,6,10)、信息消费指数(0,16,28)、两化融合指数(0,12,19)、大数据产业发展能力(0,11,16)。
(三) 定性比较分析结果
进行tsQCA分析首先对各个条件变量是否为结果变量的必要条件进行检测;其次,对不能构成必要条件的因素进行组合分析[19]。
1.必要条件分析
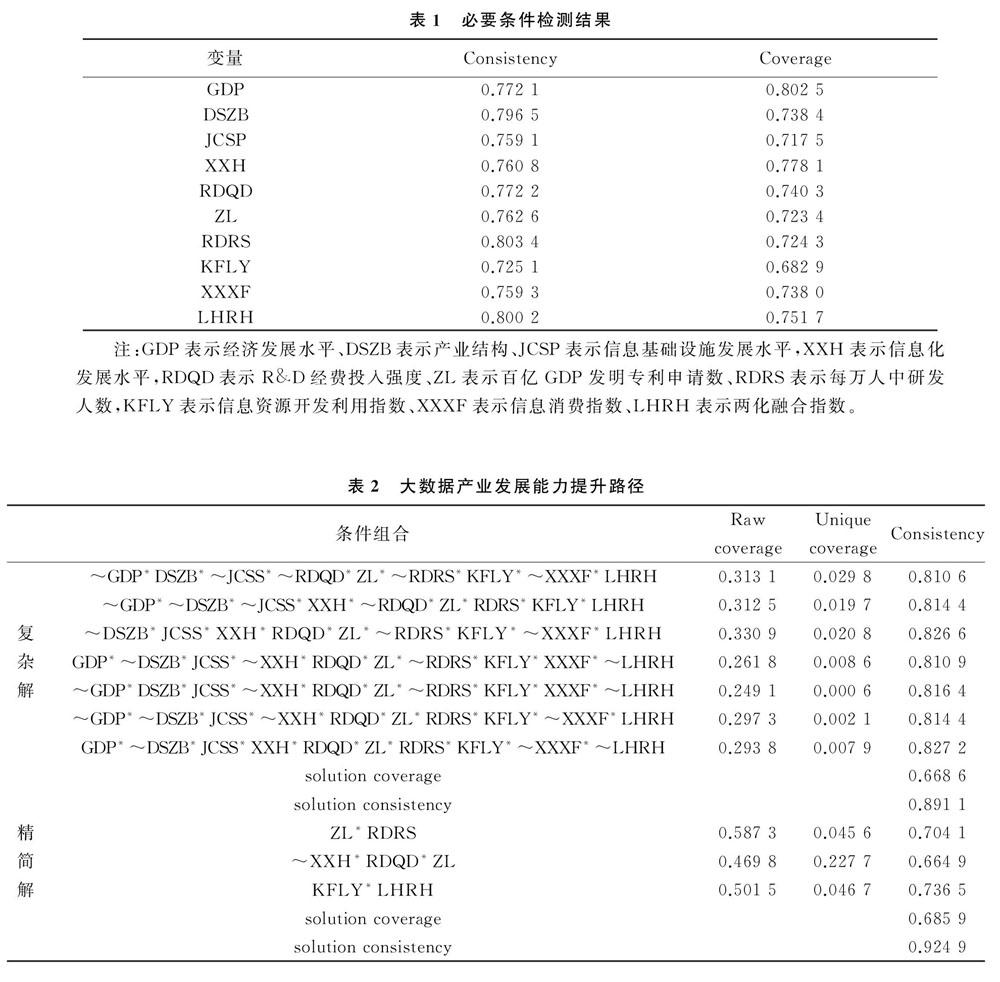
变量是否为结果的必要条件是由一致性(consistency)分值决定的,当一致性得分大于0.9时,可认为该因素是结果产生的必要条件,也即说明该因素是结果发生不可或缺的。将根据定位点校准的模糊集导入定性比较分析软件中构建出时差型定性比较分析真值表,检测各因素的一致性和覆盖率,结果如下表1所示:
2.条件组合分析
在单个条件变量不构成结果必要条件前提下,分析构成结果充分条件的因素组合方式。将构建的真值表导入软件中,选择标准分析(standard analysis),可以得到复杂、中间和精简三种解。三种解反映了各自包含多少逻辑余项,可以构成哪些反事实(Counter fact)条件组合。其中,复杂解(Complex solution)排除了所有反事实的组合,精简解(Parsimonious solution)则包含了大量的反事实组合,中间解(Intermediate solution)居于二者之间,包含一些反事实的组合,但没有精简解的数量多。事实上,使用定性比较分析的研究者都倾向于采用中间解,因为中间解在研究中既接近理论实际又不至于太过复杂[20]。因此本文也将重点分析中间解。通过构建中间解模型:out=f(gdp,dszb,jcss,xxh,rdqd,zl,rdrs,kfly,xxxf,lhrh) ,运行结果如下表2所示。
(四)因素归纳组合及结果分析
1.不同因素归纳组合
定性比较分析主要基于因果关系理论[21],为更好探究因果过程,将原因条件区分为核心要素和辅助要素,核心要素是在中间和精简解中均出现的具有本质意义的因素;而辅助要素则是只在中间解中出现,且可以被替换的因素。对表2中的中间解进行合并分析,得出核心要素和辅助要素,及大数据产业发展能力提升的前因条件构型。如下表3所示:
2.不同路径行为解释
通过QCA软件求解最大覆盖率时,各案例之间的细微差异可能会被软件放大,导致相似但不同构型来源的案例存在重复性。因此,将具有相同核心条件的组合进行归并,形成以下三种情形解释路径:
情形1:包括M1、M2、M3三种构型,它们的核心条件是资源开发利用水平及两化融合水平的提高。构型M1说明一个区域即使经济发展水平、科研经费投入力度增速相对较缓、信息产业基础设施水平及信息消费水平也没有明显提升,仍可通过提升信息资源充分开发利用能力、增加高技术产业专利申请数量以及优化产业结构来提升大数据产业发展能力。以广西省为例,虽然经济水平增速缓慢,科研经费投入力度也未有很大改善,但它却能够结合自身优势,将信息化与工业化充分融合,努力提升信息资源开发利用能力,虽然大数据产业发展未能名列前茅,但却有了一定的提升。构型M2说明一个区域若能提高信息化发展水平,增加科研人才数量及大数据发展方面的专利数量,即使其发展基础能力提升缓慢,也可在一定程度上发展大数据产业。以欠发达的贵州省为例,虽然经济发展水平相对落后且提升缓慢,产业基础薄弱,但其通过开发利用自身信息资源,同时努力提升科技创新水平,最终实现了后发赶超。目前贵州省大数据产业的发展能力已然跃居全国前十位。与M2相比,M3则显示的是基础设施水平及科研经费投入强度提升对大数据产业发展能力提升的作用。
情形2:包括M4和M5两种构型,它们的核心条件是R&D经费投入强度提高、百亿GDP发明专利申请数增多及非信息化发展水平提升。构型M4说明,经济发展水平和信息基础设施提升以及信息资源开发利用能力提升对大数据产业发展能力的正向影响作用。构型M5除强调核心条件外,也充分体现了一个地区产业结构升级及信息基础设施水平提升对大数据产业发展能力的影响。例如相较于其他经济发达省市,甘肃省虽然产业基础整体薄弱,但其通过调整产业结构,努力提升基础设施水平,也取得了提升大数据产业发展能力方面的进步。
情形3:包括M6和M7两种构型,它们的核心条件是百亿GDP专利申请数和每万人中研发人数的增加。构型M6除强调上述核心条件外,体现了信息基础设施水平,科研经费投入强度、资源开发利用等方面的改善对大数据产业发展能力的作用;相比之下构型M7还强调了经济发展水平、信息化发展水平、科研经费投入强度及信息资源开发利用的提升对大数据产业发展能力提升的影响,而此时产业结构、信息消费水平及两化融合水平的作用并不明显。以河南为例,虽然经济水平相较于发达省市有一定差距,但其注重在科技创新能力的提升,无论是经费投入还是人员投入都有明显改善;同时资源开发利用能力也明显提升,因此其大数据产业发展也取得了明显进步。
三、研究结论与启示
本文以中国31个省市自治区为研究对象,运用tsQCA方法探究大数据产业发展基础支撑能力、信息技术创新能力及信息資源开发利用能力三个维度要素变化及其配置与大数据产业发展能力提升之间的因果关系。通过构型理论及tsQCA方法,主要得出以下结论:(1)三维度要素动态变化及其交互作用形成7种条件组合,构成提升大数据产业发展能力的7个充分条件。这既回应了单一要素很难独立作用于结果,不同因素组合可以产生等结果现象的观点,也弥补了大数据产业发展中对能力提升研究的不足。(2)存在分别以提升资源开发利用及两化融合水平、促进创新发展与培育研发团队、提高R&D经费投入与促进创新发展为核心条件的3条大数据产业发展能力提升路径。(3)经济发展水平偏低地区可通过提高资源开发利用水平及两化融合水平提升大数据产业发能力;信息化发展水平偏低地区可通过提高R&D经费投入强度、增加专利研发数量提升大数据产业发展能力;第三产业占比偏低、信息消费水平偏低地区可通过加强人才引进培育、大力推进创新推动大数据产业发展。(4)采用与传统QCA构建真值表的不同手法,结合现有分析软件将时间因素融入定性比较分析,证明tsQCA不止停留在理论层面,在实践上也具有一定的可操作性,这弥补了传统定性比较分析静态特性的缺陷。
研究结论表明:不同地区可结合自身情况,选择不同情形的发展路径,但需注意的是无论选择何种路径,倘若核心关键因素一直得不到有效提升将直接导致大数据产业发展能力提升失败。因此,各地区在选择适合自身发展的路径后,应适时调整相关政策与重点关注方向,必要时应将政策调整与努力重点放在提升资源开发利用水平、两化融合水平及科技创新能力等方面;同时,在大数据产业发展过程中,某一维度要素不是单独在大数据产业发展中发挥作用,而是必须与其它要素进行配置构成条件组合才能提升其发展能力,这将有力促进各地区对大数据产业发展的科学管理;此外,七种条件组合成为大数据产业发展的七种方式,各地区可根据自身情况选择合适的发展路径,为各区域发展大数据产业提供多个备选方案,从而为实现全国范围内大数据产业发展能力的提升提供可能;最后,tsQCA 作为一种考虑时间因素的定性与定量混合研究方法,能够有效地处理影响因素的复杂性和关联性,或将成为探索变量交互效应的有力工具,本文希望为 tsQCA 方法在管理学领域的应用起到一定推广作用。
[参 考 文 献]
[1]王倩, 李天柱.大数据产业共性技术路线图研究 [J].中国科技论坛, 2018(4):73-82.
[2]张炳辉, 吕亚勃.經济新常态下我国汽车产业发展能力提升研究 [J].经济纵横, 2017(2): 88-92.
[3]ZHONG WEIJUN,HU YU,MEI SHU-E.Path and Policy of Development for Emerging Industries [M].Beijing: Science Press,2014(23).
[4]ADRIAN C, ABDULLAH R, ATAN R, et al.Factors Influencing to the Implementation Success of Big Data Analytics: A Systematic Literature Review [C]// International Conference on Research and Innovation in Information Systems.IEEE, 2017:1-6.
[5]ERICKSON K F, SAMAYA Q, WINKELMAYER W C.The Role of Big Data in the Development and Evaluation of US Dialysis Care [J].American Journal of Kidney Diseases, 2018,72(4):560-568.
[6]ABAWAJY J.Comprehensive Analysis of Big Data Variety Landscape [J].International Journal of Parallel Emergent & Distributed Systems, 2015,30 (1) : 5-14.
[7]迪莉娅.我国大数据产业发展研究 [J].科技进步与对策, 2014 (4) : 56-60.
[8]HA Y W, KIM J, LIBAQUE-SAENZ C F, et al. Use and dratifications of mobile SNSs: Facebook and kakao Talk in korea[J].Telematics, 2015,32(3):425-438.
[9]张勇进, 王璟璇.主要发达国家大数据政策比较研究 [J].中国行政管理, 2014 (12):113-117.
[10]沈俊鑫, 陈颖谦.面向欠发达地区大数据产业发展能力分析的网络化方法研究 [J].通信学报, 2017 (12):153-159.
[11]贾子娟, 马广惠.信息资源开发利用驱动的产业链研究——以图书《哈利·波特》为例 [J].情报科学, 2016, 34(7):21-24.
[12]VENKATRAMAN N.The Concept of Fit in Strategy Research: Toward Verbal and Statistical Correspondence[J].Academy of Management Review, 1989, 14(3):423-444.
[13]RIHOUX B, RAGIN C C.Configurational Comparative Methods: Qualitative Comparative Analysis (QCA) and Related Techniques [M]// Configurational comparative methods : Sage, 2009.
[14]李蔚,何海兵.定性比较分析方法的研究逻辑及其应用[J].上海行政学院学报,2015, 16(5) : 92-100.
[15]NEAL CAREN, AARON PANOFSKY.TQCA:A Technique for Adding Temporality to Qualitative Comparative Analysis[J].Sociology Methods & Research,2005,34(2):147-172.
[16]HINO A.Time-Series QCA:Studying Temporal Change through Boolean Analysis[J].Riron to Hoho, 2009, 24(2):247-265.
[17]张驰,郑晓杰,王凤彬.定性比较分析法在管理学构型研究中的应用:述评与展望 [J].外国经济与管理, 2017, 39(4):68-83.
[18]CODURASA A,CLEMENTE J A,RUIZ J.A Novel Application of Fuzzy-set Qualitative Comparative Analysis to GEM Data[J].Journal of Business Research.2015, 69 (4) : 1265-1270.
[19]王凤彬, 江鸿, 王璁.央企集团管控架构的演进:战略决定、制度引致还是路径依赖?——一项定性比较分析(QCA)尝试 [J].管理世界, 2014 (12) : 92-114.
[20]CRILLY D, ZOLLO M, HANSEN M T.Faking It or Muddling Through Understanding Decoupling in Response to Stakeholder Pressures [J].Academy of Management Journal, 2012, 55(6): 1429-1448.
[21]FISS P C.Building Better Causal Theories: A Fuzzy Set Approach to Typologies in Organization Research [J].Academy of Management Journal, 2011, 54 (54):393-420.
【责任编辑 侯翠环】
