基于混合模型的个性化阅读系统设计
2019-10-15孙承爱季胜男田刚
孙承爱 季胜男 田刚

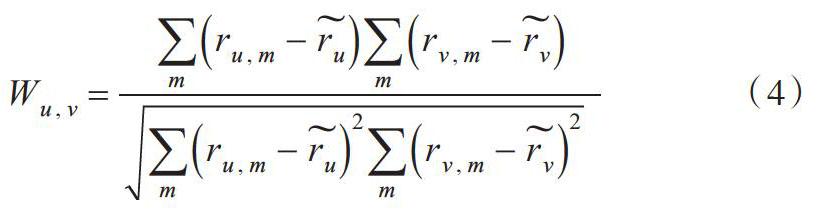

摘 要:为解决协同过滤推荐算法冷启动和数据稀缺的问题,提高个性化阅读系统推荐准确性,根据图书特点,提出一种融合协同过滤算法和兴趣标签算法的个性化阅读系统设计。通过交叉调和方法,给定一个适当的融合比将两种推荐算法的推荐结果进行融合,保证系统在解决冷启动问题的同时,能够增加推荐列表新鲜度,提高推荐准确度,保持个性化阅读系统优越性。结果表明,该方法即使没有评级也能合理推荐,在推荐准确性和图书种类方面优于传统方法。
關键词:个性化阅读;混合推荐模型;协同过滤;兴趣标签;交叉调和
DOI:10. 11907/rjdk. 191869 开放科学(资源服务)标识码(OSID):
中图分类号:TP319文献标识码:A 文章编号:1672-7800(2019)008-0080-03
Design of Personalized Reading System Based on Hybrid Model
SUN Cheng-ai,JI Sheng-nan, TIAN Gang
(College of Computer Science and Engineering, Shandong University of Science and Technology,Qingdao 266000,China)
Abstract: In order to solve the problems of cold start and data scarcity of collaborative filtering recommendation algorithm and improve the accuracy of personalized reading system recommendation,a system based on fusion collaborative filtering and interest tag algorithm for personalized reading is proposed according to the characteristics of books. By cross-harmonic method with an appropriate fusion ratio and the recommendation results of the two recommended algorithms, the system can ensure the freshness of the recommendation list, improve the accuracy of recommendation, and maintain personalization while solving the cold start problem. The superiority of the reading system is thus maintained. The results show that our method can reasonably make recommendation even without rating and thus is superior to the traditional method in terms of recommendation accuracy and book type.
Key words: personalized reading;hybrid recommendation model; collaborative filtering; interest tag; cross-harmonic
基金项目:国家自然科学基金青年项目(61602279);山东省科研项目(J16LN08)
作者简介:孙承爱(1964-),女,硕士,山东科技大学计算机科学与工程学院副教授、硕士生导师,研究方向计算机应用、软件工程、信息可视化管理;季胜男(1994-),女,山东科技大学计算机科学与工程学院硕士研究生,研究方向软件系统集成、推荐算法;田刚(1982-),男,博士,山东科技大学计算机科学与工程学院副教授、硕士生导师,研究领域为信息检索、面向服务的软件工程、深度学习、自然语言处理。
0 引言
随着网络技术的发展,大量电子图书通过在线书城等流媒体服务转向数字发行[1],个性化阅读成为热门研究领域,它既可帮助读者更快发现符合自己偏好的书籍,又可使线上书城更有效率地将图书定位到合适的读者。
在推荐系统研究中,阅读推荐由于受不同风格和类型的推荐方法以及影响读者偏好的社会和地理等因素影响,研究内容十分复杂。目前,对推荐系统的研究主要包括使用最为广泛的基于协同过滤的推荐算法[2-3],协同过滤推荐算法又分为基于用户的协同过滤和基于商品的协同过滤[4]。Pazzani等[5-6]介绍了基于内容的推荐方法;Chen等[7]通过对用户和项目标签进行主题建模,提出隐藏语义信息的推荐方法;Campos等[8]以项目内容特征和用户模型特征之间的相似性为关键内容进行推荐;Covingto等[9]通过结合两种或两种以上的的混合方法进行推荐,以解决单独使用某一基础算法存在的问题,如冷启动和数据稀疏等。此外还有基于深度学习方法的推荐,如基于深度学习网络研究的YouTube视频推荐[10]。
为了解决图书推荐系统在新用户和新图书进入时因数据稀缺造成推荐失效的问题,并考虑到图书篇幅长,难以自动提取精准内容以及推荐系统的执行效率,本文选取基于用户的协同过滤算法和基于兴趣标签的推荐方法。基于兴趣标签的推荐主要利用图书特征标签与用户偏好标签的相似度进行排名推荐,它对推荐结果有很好的解释性,但是推荐内容存在缺乏惊喜度的问题,不能推荐新类型的图书给读者;基于协同过滤推荐算法的准确性要高于标签推荐,但是存在冷启动和数据稀疏问题[11]。然而这两种推荐方法具有很好的互补特点。
因此,本文提出融合协同过滤和兴趣标签的混合推荐模型的个性化阅读系统设计,它利用兴趣标签推荐模型弥补协同过滤算法的冷启动问题并可提高推荐列表的新鲜度,进而提升推荐合理性。
1 相关工作
个性化阅读推荐系统的目的是将未被目标用户评级的图书作品进行排名。令用户和图书的索引分别为[U=u|1,?,Nu],[M=m|1,?,NM]。NU和MU指用户和图书的数量。假设U和M预先在系统中注冊,不需要额外元数据(例如,书名、作者和流派),评级数据也保留在系统中。在本文系统中,评级分数范围为0~1;令[ru,m]为用户u给m的评分。通过式(1)获得评级矩阵R。
[R=ru,m|1uNU,1mNM] (1)
当用户u没有对图书m进行评级时,为了方便起见,规定为分数0。R中大多数分数在实际数据中都是空的,因为每个用户仅在M中对少部分图书进行评级。
利用兴趣标签推荐需要内容数据。每本图书的内容表示为从图书介绍中提取的若干特征的单个矢量。令这些特征索引为[T=t|1,?,Nt],其中[Nt]是特征的数量,也是特征向量维度,令[cm,t]为图书m的第t个特征值。通过收集所有特征向量得到内容标签矩阵C,如式(2)所示。
[C=cm,t|1mNM,1tNT] (2)
1.1 基于用户的协同过滤算法
基于用户的协同过滤算法(User-based Collaborative Filtering Recommendation,User_CF)试图通过其他人对这些作品的评分预测目标用户对未被评分图书作品的评级[12]。给定目标用户u, 令[ru,m]为用户u对图书m的预测评分,由此得到式(3)为:
[ru,m=ru+kv|v≠u,v∈Uwu,vrv,m-rv] (3)
其中[ru]和[rv]分别是用户u和用户v的平均评分。[wu,v]反映用户u和v之间的偏好相似性权重,并且k是归一化因子,使得权重绝对值总和为1,即[v|Wu,v|=1]。在得到预测得分后,根据[ru,m]对图书进行排序。
在几种计算相似性的方法中,本文选择Pearson相关系数,它在许多任务中表现出了稳定的性能[13-14]。相似度计算如式(4)所示。
[Wu,v=mru,m-rumrv,m-rvmru,m-ru2mrv,m-rv2 ] (4)
1.2 基于兴趣标签的推荐
基于兴趣标签方法在个性化阅读系统中通过利用兴趣标签表示用户偏好矩阵,利用图书内容标签矩阵相似性进行推荐排名[15-16]。
使用兴趣标签推荐方法需要利用用户对图书的偏好进行用户兴趣建模。由于兴趣标签的动态性、稳定性和渐变性3个特点反映了用户时间相对长久的信息需求,比信息来源要求更稳定[17],在个性化阅读系统中兴趣标签信息来源主要集中于用户的收藏与订阅、评级、运行搜索和阅读时长,这些个性化信息对于个性化阅读系统而言价值量高,可通过对它们进行正确分析得到用户兴趣标签及兴趣偏好程度。本文系统针对新用户设计了注册页面,在设定好的若干个标签中选取用户初始兴趣标签,这样新入用户也能根据其选择的兴趣领域得到合理的推荐列表。
不同用户的兴趣及喜好程度各异。本文系统利用兴趣权重衡量某一用户对特定兴趣的偏好程度,权重值越大,用户对特定兴趣的偏好程度越高[18],设定兴趣权重也有利于更新替换用户兴趣标签,有效避免标签冗余。计算兴趣标签权重需要获取用户历史浏览数据、用户与图书之间的交互数据。用户与图书之间、用户与兴趣之间、图书与标签之间都是一对多的关系(见图1),并且兴趣权重与特定兴趣对应的图书交互次数及用户总交互频率有关。定义[Ii,p]为用户[ui]对兴趣[ip]的兴趣权重,计算公式为:
[Ii,p=NijuiFui] (5)
其中,[Nijui]表示用户[ui]与兴趣[ip]对应图书的交互次数,[Fui]表示用户[ui]交互总次数。由此根据[Ii,p]排序用户的兴趣标签限制用户兴趣标签数量在10个以内,进行更新替换,避免标签噪声和标签冗余。
图1 用户与图书、图书与标签间的关系
因此,给定目标用户[u∈U], 令[Lu,t]为用户u的第t个兴趣标签,由此得到用户兴趣标签矩阵L。
[L=Lu,t|1uNU,1t10] (6)
该模块通过计算式(2)、式(6)的夹角余弦值评估用户偏好和图书内容相似度,对相似度排名进行推荐[5]。
在三角形中边a和b的夹角余弦计算公式为:
[cos(θ)=a2+b2-c22ab] (7)
在向量中,假设a向量是([x1,y1]),b向量是([x2,y2]),则余弦计算公式为:
[cos(θ)=ab||a||×||b||=(x1,y1)(x2,y2)x21+y21×x22+y22=x1x2+y1y2x21+y21×x22+y22] (8)
进而推至n维,则a与b的夹角余弦等于:
[cos(θ)=i=1n(xi×yi)i=1n(xi)2×i=1n(yi)2=ab||a||×||b||] (9)
若余弦值接近1,表明夹角越接近0°,即两个向量越相近,则可根据相似度推荐排名前5的图书。
2 基于混合模型的推荐系统整体框架
为构建混合推荐系统,本文提出模型整体框架设计,如图2所示。
图2 混合推荐模型系统框架
本文系统在进行推荐时,从数据库中提取相关用户的历史阅读数据,将数据分别进行User_CF和兴趣标签算法推荐,并将两种推荐结果输入到融合算法模块中 ,得到最终的推荐列表。推荐结果反馈给数据库,经由数据库传送给用户。用户最新的浏览信息也及时反馈给数据库,更新相关数据,以实现推荐目录实时刷新。
根据相关两种推荐方法的特点和效果,本文系统在融合模块中利用交叉调和方法[20],即对不同推荐算法产生的结果,按照一定的融合比例形成最终推荐结果,使该系统在比例合适的情况下既保证推荐结果准确性又保证结果多样性;同时利用用户信息的记录,调整不同方法推荐结果在整个系统中的比重以实现结果合理性,如新用户或本用户历史记录较少时,系统给予兴趣标签模块较大的权重。一般情况下,由于User_CF效果较好,因此比重会高于兴趣标签的推荐。
3 系统实验结果分析
3.1 实验结果1
为了验证系统有效性,收集30位用户对300本图书的评分及相对的标签数据。从实验数据集中抽取80%的数据作为训练集,另外20%的数据作为测试集。在训练集上分别进行User_CF、基于兴趣标签的推荐和混合推荐3个推荐实验。本文系统通过推荐的准确度衡量系统有效性,推荐准确度计算公式[20]为:
[推荐准确度=用户感兴趣的图书数推荐列表图书数]
根据图3的实验结果可以看出,当用户数据稀缺、User_CF不能产生效果时,基于兴趣标签的推荐方法具有很好的弥补性,它融合了两种推荐方法的混合推荐通过调节交叉调和比,提高了推荐准确度。
图3 推荐准确度对比
3.2 实验结果2
为了更加直观地展示系统功能,利用个性化阅读系统收集的数据进行系统训练,每种推荐算法为每个用户推荐排名前5的图书。
通过User_CF和兴趣标签的推荐分别得到推荐列表,进行融合比为7∶3的交叉融合推荐,推荐结果见表1,表1还给出了用户权重较高的兴趣标签。
表1 部分用户最终推荐结果
4 结语
本文利用交叉融合方法将协同过滤推荐算法和基于兴趣标签的推荐方法进行融合,弥补了单独使用协同过滤算法冷启动等不足,以及单独使用兴趣标签推荐的准确度不高、没有新鲜度的缺陷,由此得到了一个高效运行的个性化阅读系统,并得到了比较合理的推荐结果。未来还可考虑神经网络对图书进行标签自动提取的功能,以达到更便利、更准确的图书内容标签定位。
参考文献:
[1] 中国数字出版产业年度报告课题组. 步入新时代的中国数字出版——2017—2018中国数字出版产业年度报告(摘要)[J]. 出版发行研究,2018,322(9):10+31-35.
[2] MNIH A,SALAKHUTDINOV R R. Probabilistic matrix factorization[C]. Advances in Neural Information Processing Systems,2008:1257-1264.
[3] 魏欢,陈建斌,张虎. 一种改进的协同过滤推荐算法[J]. 软件导刊,2015,14(11):57-60.
[4] 王国霞,刘贺平. 个性化推荐系统综述[J]. 计算机工程与应用, 2012, 48(7):66-76.
[5] PAZZANI M J, BILLSUS D. Content-based recommendation systems[M]. Berlin:Springer Berlin Heidelberg, 2007.
[6] 閆东东,李红强. 一种改进的基于内容的个性化推荐模型[J]. 软件导刊,2016,15(4):11-13.
[7] CHEN C C, ZHENG XL,WANG Y, et al. Capturing semantic correlation for item recommendation in tagging systems[C]. Proceedings of the 30th Conference on ArtificialIntelligence,2016: 108-114.
[8] CAMPOS L M, FERNANDEZ-LUNA J M, HUETE J F, et al. Combining content-based and collaborative recommendations: a hybrid approach based on Bayesian networks [J]. International Journal of Approximate Reasoning, 2010, 51 (7): 785-799.
[9] COVINGTO P,ADAM S. Deep neural networks for YouTube recommendations[C]. ACM Conference on Recommender Systems, 2016:191-198.
[10] BOBADILLA J,ORTEGA F,HERNANDO A,et al. Recommender systems survey[J]. Knowledge-based Systems,2013(46):109-132.
[11] 刘庆鹏,陈明锐. 优化稀疏数据集提高协同过滤推荐系统质量的方法[J]. 计算机应用, 2012, 32(4):1082-1085.
[12] 荣辉桂,火生旭,胡春华,等. 基于用户相似度的协同过滤推荐算法[J]. 通信学报, 2014, 35(2):16-24.
[13] YOSHII K, GOTO M, KOMATANI K, et al. Hybrid collaborative and content-based music recommendation using probabilistic model with latent user preferences[C]. Vancouver: 7th International Conference on Music Information Retrieval,2006.
[14] 陈功平,王红. 改进Pearson相关系数的个性化推荐算法[J]. 山东农业大学学报:自然科学版, 2016,47(6):940-944.
[15] 胡伟健,陈俊,李灵芳,等. 结合用户特征和兴趣变化的组推荐系统算法研究[J]. 软件导刊,2016,15(6):60-62.
[16] 陈洁敏,李建国,汤非易,等. 融合“用户-项目-用户兴趣标签图”的协同好友推荐算法[J]. 计算机科学与探索,2018(1):92-100.
[17] 杨军,武秀川,郭艳燕. 基于跨系统的个性化搜素系统模型设计[J]. 微处理机,2013(3):41-44.
[18] 李兴华, 陈冬林, 杨爱民, 等. 基于用户兴趣-标签的混合推荐方法研究[J]. 情报学报, 2015(5):466-470.
[19] 张滨,基于混合模型的推荐系统的研究[D]. 长春:吉林大学,2018:21-22.
[20] 陈天昊,帅建梅,朱明. 一种基于协作过滤的电影推荐方法[J]. 计算机工程,2014,40(1):55-58+62.
(责任编辑:江 艳)
