基于IG-DNN混合决策算法的糖尿病预测研究
2019-10-15卢春城黄理灿刘靖雯
卢春城 黄理灿 刘靖雯

摘 要:糖尿病患者人数众多,对人的健康危害极大,尽早预测是否患有糖尿病是降低糖尿病死亡率的关键。基于IG-DNN混合决策算法进行糖尿病预测模型研究,其中糖尿病数据集来源于UCI机器学习库—PIDD。PIDD包括768个记录,每条记录包含8个属性。首先应用信息增益方法(IG)将属性减少到5个,然后将其应用于DNN作为输入。该方法分类准确度达到88.3%,效果优于之前的大部分研究成果。
关键词:糖尿病预测模型; PIDD; 信息增益(IG);深度神经网络(DNN)
DOI:10. 11907/rjdk. 182845 开放科学(资源服务)标识码(OSID):
中图分类号:TP301文献标识码:A 文章编号:1672-7800(2019)008-0021-05
Research on Diabetes Hybrid Decision Algorithm Based on IG-DNN
LU Chun-cheng, HUANG Li-can, LIU Jing-wen
(School of Information Science and Technology, Zhejiang Sci-tech University, Hangzhou 310018, China)
Abstract: A large number of patients suffer from diabetes which is extremely harmful to peoples health, and early prediction of diabetes is the key to reducing diabetes mortality. Machine learning algorithms are often used to build diabetes prediction models. In this paper, a hybrid decision algorithm based on IG-DNN is proposed. The diabetes dataset was derived from the UCI machine learning library, PIDD. The PIDD consists of 768 records, each of which contains 8 attributes. The proposed new method first applies the information gain method (IG) to reduce the attribute to 5 and then applies it to the DNN as input. The classification accuracy of the proposed new method is 88.3%, which is better than most previous research results.
Key Words: diabetes prediction model; PIDD; information gain; deep neural network
作者簡介:卢春城(1992-),男,浙江理工大学信息学院硕士研究生,研究方向为数据挖掘;黄理灿(1962-),男,浙江理工大学信息学院教授、硕士生导师,研究方向为分布式计算、下一代网络;刘靖雯(1995-),女,浙江理工大学信息学院硕士研究生,研究方向为机器学习。
0 引言
糖尿病、高血压、心脑血管疾病被称为21世纪威胁人类健康的3大杀手 [1-2]。据统计,我国是全球糖尿病人数最多的国家,2017年糖尿病人数为1.14亿,预计到2045年将达到 1.5亿左右[3]。因此,糖尿病研究对于大众身体健康具有十分重要的意义。
当前应用于糖尿病预测模型的建模方式主要有两类:一类以统计学为基础,主要包含Logistic回归、Cox回归等方法;另一类以机器学习算法为主,模型搭建方法主要有K近邻算法(KNN)、决策树、人工神经网络(ANN)等[4-7]。这些方法各有优势以及不足,如人工神经网络模型有整体性、并行性、较高的容错性等特点,但存在对随机性和波动性较大的数据预测精度差等劣势。建立糖尿病及其并发症预测模型必须考虑各个危险因素间的非线性作用,上述算法对复杂函数的表达能力有限,或多或少会受到制约[8-9]。
随着深度学习技术的发展,其强大的特征提取和学习能力越来越多地应用到疾病预测领域[10-12]。
刘飞等[13]利用MRI图像作为CNN输入,提高了I型糖尿病患者和II型糖尿病患者的分类准确率,实现了对糖尿病患者MRI图像的分类识别。
Andre Esteva等[14]利用CNN训练129 450张临床皮肤癌图像,取得了与皮肤癌专家相当的诊断性能,表明人工智能与皮肤科医生水平相当。
相对于其它浅层机器学习方法,深度学习技术能够提高疾病预测模型的准确率,而之前利用深度学习搭建的糖尿病预测模型相对较少。本文尝试将深度神经网络(DNN)应用于糖尿病诊断预测并进行相应的性能评估。
1 数据集与研究方法
1.1 实验数据集
本文研究所用糖尿病数据来源于UCI,全称皮马印第安人糖尿病数据集(简称PIDD)。该数据集由美国国立糖尿病、消化和肾脏疾病研究所(简称NIDDK)收集提供[15]。
PIDD共768个样本,有8个特征属性和一个标签变量,8个特征属性含义如下:①怀孕次数(NP);②在内服葡萄糖耐量实验中两小时以后的血浆葡萄糖浓度,本文简称为血糖值(英文简称PGC);③舒张压(mm Hg),本文简称为血压(英文简称DBP);④三头肌皮褶厚薄程度(mm),本文简称为皮脂厚度(英文简称TSFT);⑤2小时血清胰岛素(mu/ml),本文简称为胰岛素含量(英文简称Insulin);⑥体重指数(英文简称BMI);⑦糖尿病谱系功能,本文简称为遗传指数(英文简称DPF);⑧年龄(英文简称Age)。
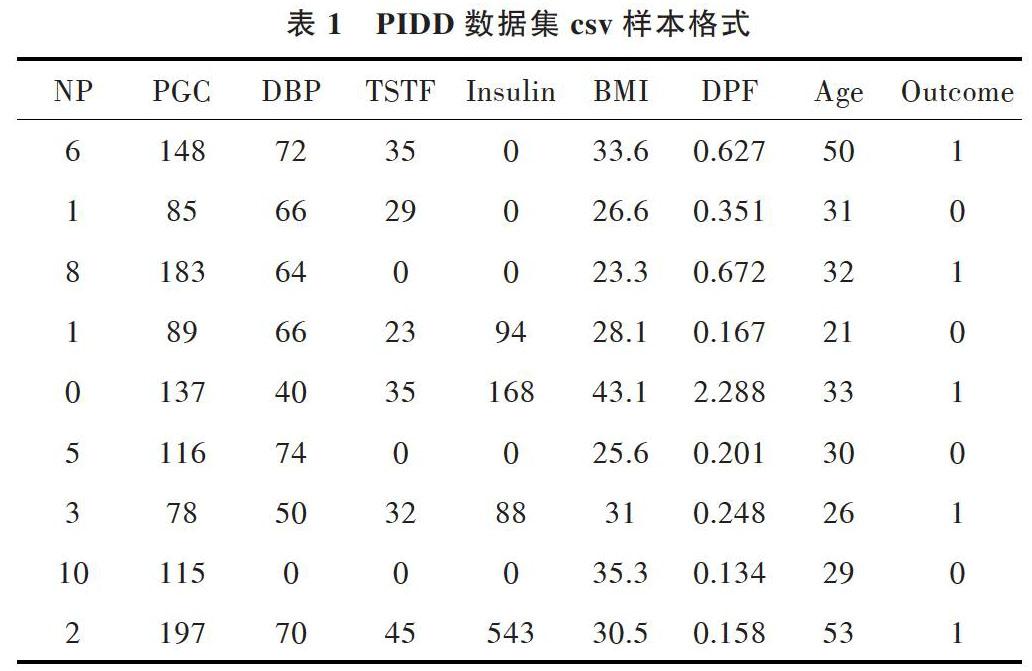
标签变量值为0和1,其中1代表患有糖尿病,0代表不患有糖尿病。整理成csv文件后数据集如表1所示。
表1 PIDD数据集csv样本格式
通过统计分析,标签值为1的样本数量是500个(占总样本65.1%),标签值为0的样本数总共268个(占总样本34.9%)。图1展示了样本标签值分布情况。
图1 PIDD数据集样本标签值分布
通过简单计算可得到PIDD数据集的特征值,如表2所示。
表2 PIDD数据集特征值
1.2 研究方法
1.2.1 系统总体架构
系统架构如图2所示。
图2 总体架构
1.2.2 信息增益(IG)
数据集中每个属性都具有特定的等级和重要性,为评估每个属性的重要性,通过衡量其相对于其它属性的增益比得到评估价值。信息增益算法通过估计经验熵和经验条件熵之间的差异获取信息增益(X,Y),算法如下:
输入:X,Y(其中X和Y被认为是离散变量);输出:信息增益InfoGain(X,Y)。
其中X的经验熵表示如下:
[Entropy(X)=-xP(X)log2P(X)] (1)
這里P(X)表示X的概率函数,或离散变量取某值的概率。Y获得的关于X的经验条件熵表示如下:
[Entropy(X|Y)=-VP(Y)Entropy(X|Y)=]
[-YP(Y)Entropy(X|Y)log2P(X|Y)] (2)
信息增益是信息熵的差,即X的经验熵和Y的后熵的差,表示在消除不确定后获得的信息量,如式(3)所示。
[InfoGain(X;Y)=Entropy(X)-Entropy(X|Y)] (3)
特征的信息增益越大说明熵的变化越大,熵变化越大越有利于分类。信息增益体现了特征的重要性,信息增益越大说明特征越重要。
1.2.3 深度神经网络(DNN)
深度神经网络(DNN)是研究深度学习的基础,而要理解DNN则先要理解DNN模型。
DNN模型是由感知机模型发展起来的,它是一个有若干输入和一个输出的模型,如图3所示。
图3 感知机模型
输入和输出之间学习到一个线性关系,得到中间输出结果如公式(4)所示。
[z=i=1mwixi+b] (4)
神经元激活函数如公式(5)所示。
[sign(z)=-1 z<01 z0] (5)
从而得到想要的输出结果1或者-1。
这个模型只能用于二元分类,且无法学习比较复杂的非线性模型,因此在工业界无法使用。而神经网络在感知机模型上作了扩展,总结主要有3点:①加入了隐藏层,隐藏层可以有多层,增强了模型的表达能力;②输出层的神经元也可以不止一个输出,可以有多个输出,这样模型可以灵活应用于分类回归以及其它机器学习领域,如降维和聚类等;③对激活函数作扩展,感知机的激活函数是[sign(z)],虽然简单但是处理能力有限,因此神经网络中一般使用其它激活函数,比如在卷积神经网络里使用的Softmax函数,如公式(6)所示。
[σ(z)j=ezjk=1Kezk] (6)
还有后来出现的[tanx、ReLU]等。
神经网络基于感知机扩展,而DNN可以理解为有很多隐藏层的神经网络。从DNN按不同层的位置划分,DNN内部神经网络层可分为3类:输入层(input layer)、隐藏层(hidden layer)和输出层(output layer),如图4所示。
图4 DNN结构
1.2.4 糖尿病预测模型评价标准
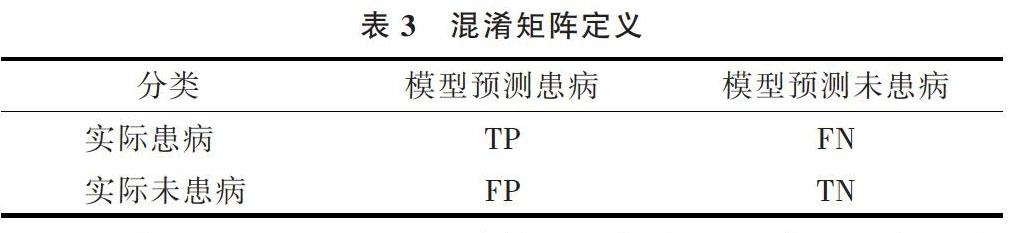
本文对糖尿病模型的性能评估主要采用准确度、灵敏度和特异度指标。评价灵敏度和特异度,要用到混淆矩阵定义,如表3所示。
表3 混淆矩阵定义
[分类\&模型预测患病\&模型预测未患病\&实际患病\&TP\&FN\&实际未患病\&FP\&TN\&]
从表3中可以得出4种情况:①在测试集中,当患有糖尿病的病人经过模型被预测为糖尿病患者时,即是真正类(TP);②若患有糖尿病的病人被诊断为未患有糖尿病,即是假正类(FN);③当未患有糖尿病的病人经过模型被诊断为未患有糖尿病时,即是真负类(FP);④若未患病的病人被诊断为患有糖尿病则为假负类(TN)[16]。
准确度通常用Acc表示,计算公式如下:
[Acc=TP+TNTP+FN+TN+FP] (7)
灵敏度通常用Sen表示,计算公式如下:
[Sen=TPTP+FN] (8)
特异度通常用Spe表示,计算公式如下:
[Spe=TNTN+FP] (9)
上面3个指标能够客观分析评估模型,在医学、数据挖掘和模型识别等领域应用广泛。
2 实验步骤
2.1 PIDD糖尿病数据集
本文的數据集来自UCI皮马印第安人糖尿病数据集(PIDD),整理为csv文件如表4所示。
表4 PIDD csv格式
2.2 特征选择及预处理
特征选择和预处理采用信息增益算法(IG),一般一个属性的熵越大,它能够给分类系统带来的信息量就越大,这样就可以选择重要性较高的属性。weka中PIDD信息增益值折线如图5所示。
从图5可以看出,糖尿病数据集的属性信息增益值在属性TSFT处出现拐点,取top5属性后的数据集如表5所示。
图5 信息增益折线
表5 新数据集csv格式
2.3 训练集和测试集划分
考虑到DNN模型训练需要大量数据集,本文划分90%作为训练集,共691个样本,剩下的10%作为测试集,共77个样本。
将训练集数据整理成csv文件格式如表6所示。
表6 训练集数据格式
表6中,691代表训练集个数,5代表经过特征选择后剩下的属性。
2.4 使用DNN构造糖尿病分类器
利用TensorFlow搭建DNN分类器,通过不断调整DNN参数,得到层数对照试验数据如表7所示(步长 3 200)。
从表7可以看出,当隐藏层为10,20,40,40,20,10时,DNN模型预测准确率最高。
3 结果分析
经过IG—DNN模型分析,得到当隐藏层为6层时,获得模型分类准确率最高,为88.31%。如图6所示。
表7 层数对比试验数据
图6 IG-DNN准确率
图7 混淆矩阵
最后,通过Python画出的混淆矩阵如图7所示。从图7可以得到:实际类型是1、预测类型是0的样本数是4,实际类型是1、预测为1的样本数是46;同时,实际类型是0预测类型是1的样本个数是5,实际类型是0预测类型是0的样本个数是22。
通过计算,相应的灵敏度(Sen)和特异度(Spe)分别是:0.92、0.81,见表8。
表8 IG-DNN算法结果评估
[准确率(%)\&灵敏度\&特异度\&88.3\&0.92\&0.81\&]
本文获得的分类准确度和PIDD数据集的其它研究最佳值对比结果见表9。
表9 IG-DNN算法结果对比
4 结语
本文主要研究了基于IG-DNN混合决策算法在糖尿病预测分类中的效果。实验结果表明:通过此方法可以获得高达88.3%准确率,而且能够获得较高的特异值和灵敏度。但本文存在的不足之处是PIDD数据集特征属性并不一定完全适用于中国人,后期需要制定中国人自己的糖尿病指标。将来可与医院合作收集更多的糖尿病病例数据,尝试利用IG-DNN训练出更好的模型,从而获得更高的准确率。
参考文献:
[1] 廖涌. 中国糖尿病的流行病学现状及展望[J]. 重庆医科大学学报,2015(7):1042-1045.
[2] 潘长玉. 中国糖尿病控制现状——指南与实践的差距,亚洲糖尿病治疗现状调查1998,2001及2003年中国区结果介绍[J]. 国际内分泌代谢杂志,2005, 25(3):174-178.
[3] 周海龙,杨晓妍,潘晓平,等. 中国人群糖尿病疾病负担的系统评价[J]. 中国循证医学杂志,2014(12):1442-1449.
[4] 徐先明,吴海龙,刘轩,等. 一种机器学习妊娠期糖尿病发病风险及病情程度预测系统[P]. 中国,CN106446595A 2017-02-22.
[5] LI Y,WANG X Z,HUA Q. Using BP-network to construct fuzzy decision tree with composite attributes[C].International Conference on Machine Learning and Cybernetics. IEEE, 2004:1791-1795.
[6] 马瑾,孙颖,刘尚辉. 决策树模型在住院2型糖尿病患者死因预测中的应用[J]. 中国卫生统计, 2013, 30(3):422-423.
[7] 李剑,吴清锋,李舒梅. 数据挖掘技术在2型糖尿病风险评估模型中的应用[J]. 赣南医学院学报,2014(6):974-977.
[8] SUDHA S. Disease prediction in data mining technique-a survey[J]. International Journal of Computer Applications & Information Technology, 2013, 2(1):189-195.
[9] SMITH J W,EVERHART J E,DICKSON W C,et al. Using the adaptive learning algorithm to forcast the onset of diabetes mellitus[J]. Proc Annu Symp Comput Appl Med Care, 1988(10):261-265.
[10] LECUN Y,BENGIO Y,HINTON G. Deep learning[J]. Nature, 2015 (7553):436-521.
[11] 吴邦华,黃海莹,姚强, 等. 大数据及人工智能方法在妊娠期糖尿病预测的应用[J]. 中国卫生信息管理杂志,2017(6):96-99.
[12] 王威,李郁,张文娟,等.深度学习技术在疾病诊断中的应用[J].第二军医大学学报,2018,39(8):852-858.
[13] 刘飞,张俊然,杨豪.基于深度学习的糖尿病患者的分类识别[J].计算机应用,2018,38(S1):39-43.
[14] ESTEVA A,KUPREL B,NOVOA R A,et al. Dermatologist-level classification of skin cancer with deep neural networks[J]. Nature,2017 (8423):214-221.
[15] 李桂花,孔祥恩,张春天. 胰岛素与辛伐他汀合用治疗早期糖尿病肾病42例临床观察[J]. 中国实用内科杂志,2007(1):154-159.
[16] 狄晓敏,谢红薇. 多疾病共同危险因素挖掘与MARS预测模型研究[J]. 计算机应用与软件,2013(10):36-40.
[17] WU J,DIAO Y B,LI M L, et al. A semi-supervised learning based method: Laplacian support vector machine used in diabetes disease diagnosis[J]. Interdisciplinary Sciences Computational Life Sciences, 2009, 1(2):151-155.
[18] TEMURTAS H,YUMUSAK N,TEMURTAS F. A comparative study on diabetes disease diagnosis using neural networks[J]. Expert Systems with Applications, 2009, 36(4):8610-8615.
[19] TOMAR D,AGARWAL S. Hybrid feature selection based weighted least squares twin support vector machine approach for diagnosing breast cancer, hepatitis, and diabetes[M]. Hindawi Publishing Corp,2015.
[20] HAYASHI Y,YUKITA S. Rule extraction using recursive-rule extraction algorithm with j48graft combined with sampling selection techniques for the diagnosis of type 2 diabetes mellitus in the Pima Indian dataset[J]. Informatics in Medicine Unlocked, 2016(2):92-100.
(责任编辑:杜能钢)
