涪陵焦石坝页岩气井调产分析及预测
2019-10-15夏钦锋
夏钦锋
(中石化重庆涪陵页岩气勘探开发有限公司,重庆408014)
0 引言
近年来,随着我国页岩气勘探开发的快速推进,我国已经成为继美国和加拿大之后全球第三个开展页岩气商业开发的国家[1-2]。目前国内外学者根据翁氏模型理论基础,结合多元线性回归系数求解法,对实际页岩气生产井进行产能预测,分析页岩气井产量变化规律[3];谢维杨[4]结合页岩气藏水平井压裂后产生水力压裂缝这一情况,建立水力压裂缝导流的页岩气藏水平井后期稳定开采的渗流模型;任俊杰等人[5]综合考虑页岩气解吸、扩散和渗流特征,建立页岩气藏压裂水平井产能模型。总体而言,目前国内外学者在研究页岩气井产能时,一般采用经验法、解析法和数值模拟三种方法来预测页岩气井生产规律,可靠性都不高,不能依据已有的历史生产数据进行准确的压力预测。
在调产过程中产量发生变化时,压力也随之变化。生产过程中采集的大量数据蕴含信息丰富,根据历史生产数据对气井的生产压力进行预测,对后期持续开发和利用有着促进作用。然而调产过程中产量变化梯度多、调产周期波动大、历史数据不平衡、生产数据具有强非线性[6]、强耦合等特点,导致生产压力难以预测。在调产井中,压力的递减趋势随产量的变化而发生改变,不能通过一般模型进行建模[9-10]。
针对上述问题,本文采用FCM 方法对调产井生产数据进行自适应聚类,保证数据的准确性;再运用Kendall 秩相关系数分析法对生产数据进行相关性分析,以确定用于递归神经网络建模的输入变量;最后分别对每一类数据进行建模,形成多模型库。在压力预测时,输入需要预测的产量以及历史数据,系统将自动识别并调用其对应的模型进行压力预测,实现不同产量下的压力预测。
1 相关性分析
通过对原始生产数据进行相关性分析,找出数据之间的隐藏特性,从而挖掘出有用的数据进行进一步分析。其主要相互影响的参数有:产量、压力、水。进行相关性分析主要分为以下两个部分:
(1)评价数据质量的可靠性,包含产量、压力、水等重要指标。
(2)数据相关性检验。依据典型气井的生产数据分析可知,压力、产量、水之间有较强的相关性,通过提取几组生产数据进行相关性检验,其中包括产量-压力、产量-时间和压力-时间。

图1 压力预测流程图
使用Spearman 相关性分析对生产数据进行分析[11],它是利用数据的秩进行计算,适用于有序数据或不满足正态分布假设的等间隔数据,关联值范围在[-1,1],绝对是越大,表明相关性越强。先对原始变量的数据排秩,根据秩使用Spearman 相关系数公式进行计算,相关系数符号表示相关方向。其计算公式为:

式中,αi是第i 个x 值的秩,βi是第i 个y 值的秩。αˉ、βˉ分别是αi和βi的平均值。
选取涪陵焦石坝区块的以下典型井生产数据,通过上面方法进行数据相关性,其原始生产数据如图2、图3 所示。

图2 焦页24-1HF数据图

图3 焦页37-3HF数据图

表1 焦页24-1HF 相关性分析结果
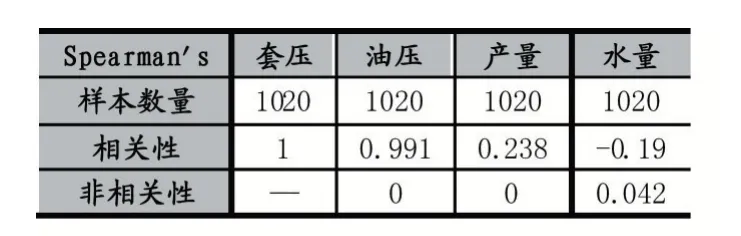
表2 焦页37-3HF 相关性分析结果
根据图2、3 和表1、2 可以说明产水量明显变化时,压力也发生变化,压力变化与产水量之间有着良好的负相关。该气井水主要由产气携液得到,其水量与得到的气体是有正相关性,说明产气越丰富,得到的水就越多。由于地层存储丰富,所以产气量较为丰富,得到的水量也较为充足,从而致使压力递减速度比较慢。
2 模糊C均值聚类算法
模糊C 均值聚类算法(FCM)是用隶属度确定每个数据点属于某个聚类的程度的一种聚类算法。FCM 把n 个向量xi(i=1,2,…,n)分为c 个模糊组,并求每组的聚类中心,使得非相似性指标的价值函数达到最小。FCM 用模糊划分,使得每个给定数据点用值在[ ]0,1间的隶属度来确定其属于各个组的程度。与引入模糊划分相适应,隶属矩阵U 允许有取值在[ ]0,1 间的元素。不过,规定一个数据集的隶属度的和总等于1。

那么,FCM 的价值函数(或目标函数)就是:

这里uij介于[0 ,1] 之间;ci为模糊组I 的聚类中心,dij=‖ ci-xj‖为第i 个聚类中心与第j 个数据点间的欧几里德距离,且m ∈[1,∞)是一个加权指数。
构造如下新的目标函数,使公式(2)达到最小值的必要条件:

这里λj( j= 1,…,n )是公式(2)的n 个约束式的拉格朗日乘子,对所有输入参量求导,使公式(3)达到最小的必要条件为:

和:

由上述两个必要条件,FCM 算法是一个简单的迭代过程。在批处理方式运行时,FCM 用下列步骤确定聚类中心ci和隶属矩阵U:
步骤1:用值在[0 ,1] 间的随机数初始化隶属矩阵U,使其满足公式(2)中的约束条件;
步 骤 2:用 公 式(5)计 算 c 个 聚 类 中心ci(i=1,2,…,c);
步骤3:根据公式(3)计算价值函数。如果它小于某个确定的阈值,或它相对上次价值,函数值的改变量小于某个阈值,则算法停止;
步骤4:用公式(6)计算新的U 矩阵。返回步骤2。
通过FCM 算法对原始数据进行聚类分析,然后把原始数据分为我们想要的几种情况,具体结果如图4、图5 所示,首先根据每口调产井产量类型大致设置需要分类的数量。

图4 焦页24-1HF分类结果图(设置为3类)

图5 焦页37-3HF分类结果图(设置为4类)
通过图4 可以看出,把焦页24-1HF 井中的产量分为三类,能够良好地显示出产量的梯度,从而更好地进行预测分析。图5 中焦页24-1HF 井的数据结构较为复杂,把它分为三类,能够良好地分出其梯度。
3 Elman神经网络多模型建模以及预测
根据不同的划分标准,神经网络可划分成不同的种类。按连接方式来分主要有两种:前向神经网络和反馈(递归)神经网络。人工神经网络以其自身的自组织、自适应和自学习的特点,被广泛应用于各个领域,在控制领域对非线性系统的建模与控制的应用也发挥越来大的作用。不过一般采用的前向网络所建立的输入/输出之间的关系式往往是静态的,而实际应用中的被控对象通常都是时变的。因此采用静态神经网络建模就不能准确地描述系统的动态性能[7]。而Elman 神经网络不仅可以反映系统动态特性而且可以存储信息。网络中存在信息的延时,并且具有延时信息的反馈。递归网络存储信息的特性来源于网络信号的反馈,信号递归使得网络在某时刻k 的出入状态不仅与k时刻的输入状态有关,而且还与k 时刻以前的信号有关,这充分的表现了网络系统的动态性能,非常适用于具有时序性的页岩气生产数据的建模与预测[8]。其各层关系式为:
输入层:

隐含层:

关联层:
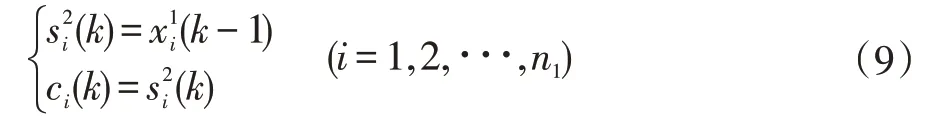
输出层:

最终采用Elman 神经网络多模型建模,考虑到每口页岩气井整体都有一个下降趋势,针对这种情况我们不仅对分类结果分别建立模型,还把所有历史数据也建立了模型,并且将建模结果保存在数组中,以便后期预测使用,如图6 所示。

图6 神经网络建立模型(37-3HF分为4和5类)
其中,Net 表示整体数据建立的模型,net 中有4个神经网络模型,分别对应于产量不同的分类结果建立的模型,最后根据需要预测的产量自动调用模型进行预测。
4 实验研究
设置需要预测的产量,以及输入当前产量下对应压力的历史数据,通过识别需要预测的产量,对应找到最符合设置的产量的模型,调用模型进行预测。首先设置自行选择预测天数功能,操作人员可根据实际情况选择需要预测的天数,并且填入哪种产量下的压力预测,导入几天历史数据方可预测。在建模时以及预测时,不仅考虑了气井压力整体下降趋势(对整体建立模型,将预测结果作为局部模型的输入)以及各生产因素之间的相互影响,而且充分考虑当天生产压力与历史生产压力的关系(历史4 天预测第五天)。当输入产量为100000 时(37-3HF),需要预测的天数设置为5,分类数设置为5 时,选取为经过训练的历史真实数据如表3。

表3 37-3HF 真实值与预测值对比表
从表3 可以看出,采用Spearman 相关性分析对历史数据之间进行相关性分析后,在运用FCM 算法分类得到的几类历史数据,分别建立Elman 模型,针对不同产量下,预测得到的值非常接近真实值,有良好的预测结果,可供工作人员在后续调产中提供可靠的依据。
从图7 可以看出,调产井37-3HF 在不同类别和不同产量的情况下,采用Elman 神经网络针对每一类的局部模型进行预测时,通过对预测输出值与当天真实数据对比可以看出,预测精度可以达到预期效果。而BP 神经网络不能通过拟合历史数据得到良好的模型进行预测,误差较大,仅适用于定产井的预测。
当输入产量为100000 时(24-1HF),需要预测的天数设置为5,分类数设置为3 时,选取为经过训练的历史真实数据如表4。

表4 24-1HF 真实值与预测值对比表
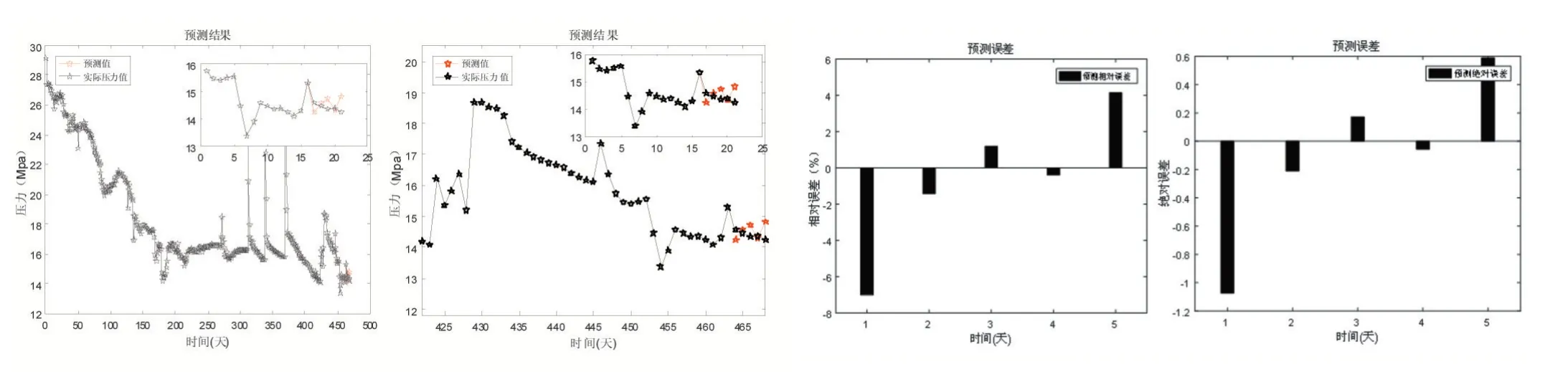
图7 Elman神经网络预测结果及误差(37-3HF)
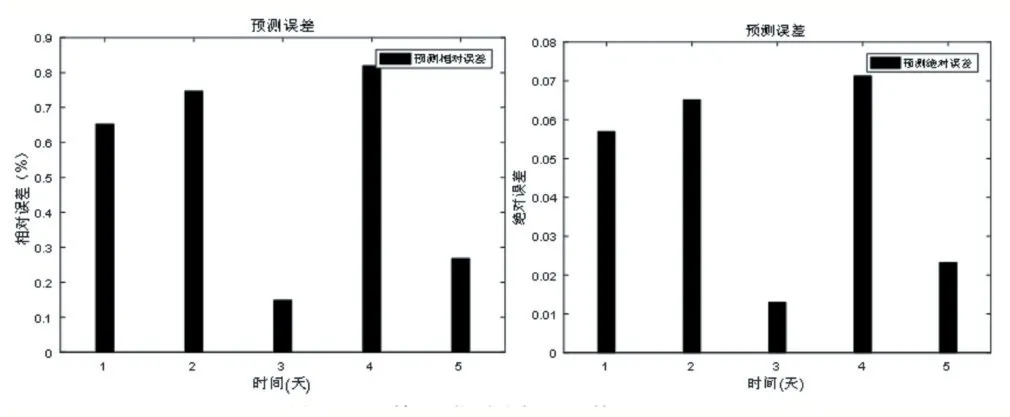
图8 Elman神经网络预测结果及误差(24-1HF)
从表4 可以看出,采用Spearman 相关性分析对历史数据之间进行相关性分析后,在运用FCM 算法分类得到的几类历史数据,分别建立Elman 模型,针对不同产量下,预测得到的值非常接近真实值,有良好的预测结果,可供工作人员在后续调产中提供可靠的依据。
从图8 可以看出,调产井24-1HF 在不同分类、产量的情况下,利用Elman 神经网络每一类的局部模型进行预测时,通过对神经网络预测输出与实际数据对比可以看出,预测精度可以达到预期的效果。而BP 神经网络不能通过拟合历史数据得到良好的模型进行预测,误差较大,仅适用于定产井的预测。
5 结语
本文提出了一种适用于页岩气调产井生产数据预处理的方法,通过FCM 算法把不同产量进行了分类,消除了异常数据对Elman 神经网络建模的影响;从而构造良好的神经网络模型进行预测,与传统BP 神经网络相比,提高了预测精度;但在网络收敛速度上仍有改进空间。
本文方法适用于涪陵焦石坝页岩气调产井,在模型精度优化上,还需要对神经网络建模做进一步改进,仍需要考虑到页岩气生产压力受多种因素影响,开发实践中,需要充分考虑产量、水、油压、套压等各方面的影响,同时尽量保证数据的准确性与真实性,这样方可建立相对准确的生产压力模型,以提高评价精度。
